当前位置:网站首页>Summary of innovative ideas of transformer model in CV
Summary of innovative ideas of transformer model in CV
2022-06-13 02:33:00 【Prodigal son's private dishes】
Preface : This article reviews ViT Structure , This paper summarizes the of computer vision transformer The main improvement ideas : Improved blocking , Improved location coding , improvement Encoder, increase Decoder. Relevant papers are introduced under each idea , This paper introduces the starting point and improvement ideas of these papers .
The purpose of this article is not to introduce transformer What models are there now , Instead, learn from others' ideas of finding problems and improving them , So as to put forward appropriate and reasonable improvements in their own direction .
VIT review
In talking about computer vision transformer Before the summary of model innovation , First, it is necessary to review its overall model . In this paper, the most commonly used ViT.

As shown in the figure , For an image , First divide it into NxN individual patches, hold patches Conduct Flatten, Then through a full connection layer ( Or use conv operation ) mapping tokens, For each tokens Add location code (position embedding), Will randomly initialize a tokens,concate To... Generated by image tokens after , after transformer Of Encoder modular , Through many layers Encoder after , Take out the last tokens( That is, randomly initialized tokens), Then the whole connection layer is used as the classification network for classification .
There is much room for improvement in this process , Let's take a look at how other papers think and improve . The following contents are sorted according to the improvement of each step in the above implementation process .
Improve your thinking
1. Block improvement
Progressive style vision transformer
Raise questions : ViT A simple tokenization (tokenization) programme , This scheme divides an image into a series of regular intervals patches, these patches Is linearly projected onto tokens in . In this way , Images are converted into hundreds of visual images tokens. However , such tokens The limitations of the localization scheme are obvious .

First , Hard segmentation may separate some highly related regions , These areas should be modeled with the same set of parameters , This destroys the inherent object structure , And make the input patches The amount of information becomes less . The picture shows that the cat's head is divided into several parts , Leading to a recognition challenge based on only one part . secondly ,tokens Placed on a regular grid , It has nothing to do with the content of the underlying image . The picture shows , Most meshes focus on backgrounds that are not of interest , This may cause the foreground object of interest to be submerged in the interference signal .
Improve your thinking : The human visual system organizes visual information in a completely different way , Instead of dealing with the whole scene indiscriminately at once . In its place , It gradually 、 Selectively focus on interesting parts of visual space , Whenever and wherever you need it , And ignore the uninterested part , as time goes on , Combine information from different fixations to understand the scene . Inspired by the above process , This paper proposes a new method based on transformer Progressive sampling (Progressive Sampling) modular , This module can learn where to look at images , To relieve ViT Simple tokens The problems brought about by the standardization scheme .

The module proposed in this paper is not sampling from a fixed position , Instead, the sampling location is updated iteratively . As shown in the figure , In each iteration , Of the current sampling step tokens Be fed to transformer Coding layer , And predict a set of sampling offsets to update the sampling position in the next step . The mechanism utilizes transformer The ability to capture global information , By combining the local context with the current tokens To estimate the offset of the region of interest . such , Attention will be like human vision , Focus step by step on the recognizable area of the image .
2. Reflection and improvement of relative position coding
Raise questions
transformer There are two kinds of coding methods for position representation . One is absolute , The other is relative .
The absolute method will enter tokens The absolute position of is from 1 Encode to maximum sequence length . in other words , Each position has a separate coding vector . Then match the coding vector with the input Tokens Combine , To input location information into the model .
Relative position method for input tokens Encode the relative distance between , And learn tokens The pairing relationship between . Relative position coding (relative position encoding, RPE) Usually with self-attention Module query and key Interactive query table with learnable parameters to calculate . Such a scheme allows the module to capture Tokens Very long dependencies between .
Relative position coding has been proved to be effective in natural language processing . However , In computer vision , This effect is still unclear . Recently, there is little literature on it , But in Vision Transformer But it has come to a controversial conclusion .for example ,Dosovitski Et al. Observed that relative position coding did not bring any gain compared with absolute position coding . contrary ,Srinivaset They found that relative position coding can induce significant gain , Better than absolute position coding . Besides , Recent work claims that relative position coding cannot be as easy to use as absolute position coding . These works draw different conclusions on the effectiveness of relative position coding in the model , This urges us to re-examine and reflect on the relative position coding in Vision
Transformer Application in .
On the other hand , The language modeling adopts the original relative position coding , The input data is a one-dimensional word sequence . But for visual tasks , The input is usually 2D Image or video sequence , The pixels have a high spatial structure . It's not clear : Whether the extension from one dimension to two dimensions is suitable for visual model ; Whether direction information is important in visual tasks ?
Improve your thinking
1. This paper analyzes several key factors in relative position coding , Including relative direction 、 The importance of context 、query、key、value And relative position embedding, as well as the computational cost . This analysis has a comprehensive understanding of relative position coding , It also provides empirical guidance for the design of the new method .
2. An efficient implementation method of relative coding is proposed , Calculate the cost from the original O() Down to O(nkd)( among k<<n), Suitable for high resolution input images , Such as target detection 、 Semantic segmentation, etc Tokens A number of occasions that can be very large .
3. Consider efficiency and versatility , Four new vision transformer Relative position coding method , be called image RPE(IRPE). These methods are simple , You can easily insert self-attention layer . Experiments show that , Without adjusting any super parameters and settings , The method in ImageNet and COCO Compared with its original model DeiTS and DETR-ResNet50 Improved 1.5%(top-1ACC) and 1.3%(MAP).
4. Experimental proof , In the image classification task , Relative position coding can replace absolute coding . meanwhile , Absolute coding is necessary for target detection , The pixel position is important for target location .
3. Encoder Improvement
About Encoder Improvement , Most of them are putting transformer When used for specific tasks , Improve according to the characteristics or problems of each task . Although not necessarily a general model , However, the improvement ideas embodied in the improvement process are still worthy of learning and reference .
Raise questions
Expression recognition has little intra class similarity 、 The characteristics of great similarity between classes . meanwhile , Different local representations need to be extracted to classify different expressions . Even some local blocks (patches) invisible , More diverse local blocks can also play a role . meanwhile , Different local blocks can complement each other .

for example , As shown in the figure , Only according to the mouth area ( Column 2) It's hard to distinguish between surprise ( The first 1 That's ok ) And anger ( The first 2 That's ok ). What we proposed TransFER The model explores different relationships between perception of facial parts , Like the eyes ( The first 3 Column , The first 1 That's ok ) And the area between the eyebrows ( The first 3 Column , The first 2 That's ok ), This helps to distinguish these different expressions .
therefore , Different local blocks should be explored globally (patches) The relationship between , Highlight important blocks (patches), Suppress useless blocks (patches).
Improve your thinking
The paper proposes that TransFER Model to learn about different relationship perceptions FER Part means .
First , A multiple attention discarding algorithm for randomly discarding attention graphs is proposed (Multi-Attention Dropping,
MAD). In this way , Push the model to explore comprehensive local patches other than the most differentiated local patches , Adaptively focus on different local patches . When some parts are invisible due to posture change or occlusion , This method is particularly useful .
secondly ,VisionTransformer(VIT) Apply to FER, be called VIT-FER, Used to model the connection between multiple local blocks . Since each local block is enhanced with global scope , The complementarity between multiple local blocks is fully exploited , Improved recognition performance .
Third , Bulls pay attention to themselves (multi-head self-attention) send VIT Be able to focus on features from different information subspaces in different locations . However , Without clear guidance , Redundant relationships may be established . To solve this problem , This paper proposes a multi head self attention discarding method that randomly discards a self attention (Multi-head
Self-Attention Dropping,MSAD) Method . under these circumstances , If you give up self-attention, The model is forced to learn useful relationships from elsewhere . therefore , The rich relationships between different local blocks are mined , So that FER benefit .
Combine new MAD and MSAD modular , The final architecture is proposed , be called TransFER. As shown in the figure , And VIT-FER The baseline ( Column 2) comparison ,TransFER Locate more diverse local representations of relationships ( Column 3), To distinguish these different expressions . It's in a few FER On the benchmark SOTA performance , It shows its effectiveness .
4.SOTR
Raise questions
transformer There are still some deficiencies in semantic segmentation . One side ,transformer Poor performance in extracting low-level features , Lead to misprediction of small targets . On the other hand , Due to the universality of feature mapping , Requires a lot of memory and time , Especially in the training phase .
Improve your thinking
To overcome these shortcomings , This paper proposes an innovative bottom-up model SOTR, The model cleverly combines CNN and transformer The advantages of .
SOTR The focus is on how to make better use of transformer Semantic extraction of information . In order to reduce the traditional self-attention The storage and computational complexity of the mechanism , This paper puts forward double attention , It adopts the sparse representation of the traditional attention matrix .
1. This paper puts forward an innovative CNN-Transformer-hybrid Instance segmentation framework , be called SOTR. It can effectively model local connections and remote dependencies , Use... In the input field CNN The trunk and transformer Encoder , Make them highly expressive . what's more ,SOTR By directly splitting object instances without relying on box testing , It greatly simplifies the whole pipeline .

2. Designed a double attention , This is a new position-sensitive self-attention Mechanism , Is for transformer tailor-made . Original transformer comparison ,SOTR This well-designed structure saves a lot of computation and memory , Especially for the large input of dense prediction such as instance segmentation .
3. Except purely based on transformer Outside the model , Proposed SOTR There is no need for pre training on large data sets , It can well popularize inductive bias . therefore ,SOTR It is easier to apply to the situation of insufficient data .
4. stay MS Coco On the benchmark ,SOTR The performance has reached the use ResNet-101-FPN The trunk AP Of 40.2%, More accurate than most of the most SOTA Method . Besides , because twin
transformer Extraction of global information ,SOTR In medium objects (59.0%) And large objects (73.0%) Show significantly better performance on .
PnP-DETR
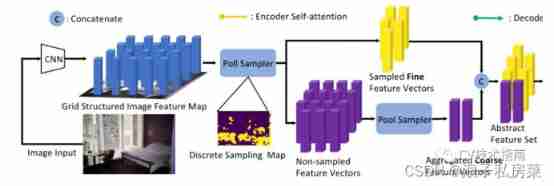
Raise questions
take transformer The application of network to image feature mapping may be computationally expensive , This is mainly due to the attention operation of long flattened eigenvectors . These features may be redundant : In addition to the objects of interest , Natural images usually contain large background areas , These background regions may occupy a large part of the corresponding feature representation ; and , Some distinguishing feature vectors may be sufficient to detect objects .
Existing improvements transformer The work of efficiency mainly focuses on accelerating attention operation , The spatial redundancy discussed above is rarely considered .
Improve your thinking
To address the above limitations , This paper develops a learnable polling and pooling system (Poll and Pool,
PnP) Sampling module . Its purpose is to compress the image feature map into an abstract feature set composed of fine feature vectors and a small number of rough feature vectors .
The fine feature vector is deterministically sampled from the input feature map , To capture fine foreground information , This is crucial for detecting targets . Rough feature vectors aggregate information from the location of the background , The generated context information helps to better identify and locate objects . then ,transformer The information interaction in fine and coarse feature space is modeled , And get the final result .
Because the abstract set is much shorter than the directly flattened image feature map , therefore transformer The amount of computation is greatly reduced , And mainly distributed in the foreground . This method is related to improving transformer The method of efficiency is orthogonal , It can be further combined with them to get a more effective model .
PiT
Raise questions
CNN Start with the characteristics of large space size and small channel size , And gradually increase the channel size , At the same time, reduce the space size . Because of the layer called spatial pooling , This dimensional transformation is essential . modern
CNN framework , Include AlexNet、ResNet and EfficientNet, All follow this design principle .Pool layer is closely related to the size of receptive field in each layer . Some research shows that , The pooling layer contributes to the expressiveness and generalization performance of the network . However , And CNN The difference is ,ViT No pooling layer is used , Instead, use the same size of space in all layers .
Improve your thinking
First , The paper verifies CNN Advantages of upper pool layer . Experiments show that , The pool layer proves ResNet Model capability and generalization performance . In order to extend the advantages of the pooling layer to ViT, This paper proposes a vision system based on pooling transformers (PiT).

PiT It is a combination with Pool layer transformer framework . It can be like in ResNet Reduce... As in ViT The size of space in the structure .
Last , To analyze ViT Effect of pool layer in , The paper measured ViT Spatial interaction ratio , Receptive field size similar to convolution Architecture . This paper shows that the pool layer can control the size of spatial interaction in the self attention layer , This is similar to the receptive field control of convolution architecture .
Swin Transformer
Raise questions
The paper attempts to expand Transformer The applicability of , It can be used as a general backbone of computer vision , It's like it's in NLP As we did in , It can also be like CNNs What you do in vision .
Papers mentioned , take transformer The major challenge of high-performance transformation from language to vision can be explained by the difference between the two models . One of these differences relates to scale .
And as language transformer The words of the basic elements processed in tokens Different , Visual elements can vary greatly in scale , This is a concern in tasks such as target detection . In the existing based on transformer In the model of ,tokens All in a fixed proportion , This feature is not suitable for these visual applications .
Another difference is , Compared with the text in the text paragraph , The resolution of pixels in the image is much higher . There are many visual tasks , Such as semantic segmentation , Intensive prediction is required at the pixel level , This is for high resolution images Transformer It's hard for me , Because of its self-attention The computational complexity is the quadratic of the image size .
Improve your thinking
In order to overcome these problems , The paper proposes one General purpose Transformer backbone network , be called Swin Transformer, It constructs a hierarchical feature mapping , The computational complexity is linear with the image size .
Pictured 1(A) Shown ,Swin Transformer By starting from small pieces ( Gray outline ) Start , Gradually merge deeper Transformer The hierarchical representation is constructed by adjacent blocks in the layer .
With these layered characteristic diagrams ,Swin Transformer The model can easily use advanced technology for intensive prediction , Such as feature pyramid network (FPN) or U-Net. The linear computational complexity is obtained by segmenting the image ( Red outline ) Local calculation in non overlapping windows self-attention To achieve . In each window patches The quantity is fixed , Therefore, the complexity is linear with the image size .
These advantages make Swin Transformer Suitable as a general backbone for various visual tasks , Not based on Transformer The architecture of , The latter generates a single resolution feature map , And it has quadratic complexity .
Swin Transformer A key design element is window partitioning in continuous self-attention Movement between layers , Pictured 2 Shown . The moving window bridges the window of the previous layer , Provides a connection between them , Significantly enhance the modeling ability .
This strategy is also effective in terms of actual delay : All in one window query patch All share the same key Set , This facilitates memory access in hardware . contrary , Earlier sliding window based self-attention Due to different methods query Different pixels key It is affected by low latency on general hardware .
Experiments show that , The proposed shift window method has lower delay than the sliding window method , But it is similar in modeling ability . The fact proved that , The shift window method is suitable for all MLP Architecture is also beneficial .
边栏推荐
- Paper reading - group normalization
- Is space time attention all you need for video understanding?
- Resource arrangement
- Deep learning the principle of armv8/armv9 cache
- Thinking back from the eight queens' question
- For loop instead of while loop - for loop instead of while loop
- [keras] generator for 3D u-net source code analysis py
- 03 recognize the first view component
- Thesis reading - autovc: zero shot voice style transfer with only autoencoder loss
- [reading papers] transformer miscellaneous notes, especially miscellaneous
猜你喜欢

An image is word 16x16 words: transformers for image recognition at scale
![[learning notes] xr872 GUI littlevgl 8.0 migration (file system)](/img/9b/0bf88354e8cfdbcc1ea91311c9a823.jpg)
[learning notes] xr872 GUI littlevgl 8.0 migration (file system)

Understanding and thinking about multi-core consistency

Flow chart of interrupt process
![Leetcode 473. 火柴拼正方形 [暴力+剪枝]](/img/3a/975b91dd785e341c561804175b6439.png)
Leetcode 473. 火柴拼正方形 [暴力+剪枝]

regular expression

Matlab: find the inner angle of n-sided concave polygon

Fast Color Segementation

05 tabBar导航栏功能

Armv8-m learning notes - getting started
随机推荐
[reading papers] deep learning face representation by joint identification verification, deep learning applied to optimization problems, deepid2
A real-time target detection model Yolo
Solution of depth learning for 3D anisotropic images
[work with notes] MFC solves the problem that pressing ESC and enter will automatically exit
Laravel 权限导出
Bai ruikai Electronic sprint Scientific Innovation Board: proposed to raise 360 million Funds, Mr. And Mrs. Wang binhua as the main Shareholder
About the fact that I gave up the course of "Guyue private room course ROS manipulator development from introduction to actual combat" halfway
Paper reading - jukebox: a generic model for music
Chapter7-11_ Deep Learning for Question Answering (2/2)
Leetcode 93 recovery IP address
redis.conf总配置详解
在IDEA使用C3P0连接池连接SQL数据库后却不能显示数据库内容
How to do Internet for small enterprises
Rough understanding of wechat cloud development
redis. Conf general configuration details
03 认识第一个view组件
[open source] libinimini: a minimalist ini parsing library for single chip computers
Resource arrangement
Opencv 17 face recognition
I didn't expect that the index occupies several times as much space as the data MySQL queries the space occupied by each table in the database, and the space occupied by data and indexes. It is used i