当前位置:网站首页>A real-time target detection model Yolo
A real-time target detection model Yolo
2022-06-13 02:24:00 【Shameful child】
Y ou Only Look Once:Unified, Real-Time Object Detection
YOLO, A new kind of object detection Method .
YOLO and MultiBox Convolution network is used to predict the boundary box in the image , but YOLO Is a complete detection system .
Take object detection as a The return question , The boundary boxes are separated by space and the related class probabilities are given .
A single neural network in One assessment The boundary box and class probability are predicted directly from the complete image .
Because the whole detection pipeline is a single network , Therefore, the detection performance can be directly evaluated End to end optimization .
yolo Model recognition is fast , The accuracy is low
YOLO The model runs in seconds 45 Frame speed, real-time processing of images .
Fast YOLO Processing shocking... Per second 155 frame , At the same time, it still realizes the double mapping of other real-time detectors .
Compared with the most advanced detection system ,YOLO There will be more positioning errors , But it is unlikely to predict false positives on the background .
**YOLO A general representation of the learning object .** When it goes from natural images to other fields like art , Its performance is superior to other detection methods
application : Fast 、 Accurate target detection algorithm Will enable the computer to Driving a car without special sensors , Enable the auxiliary equipment to transmit real-time scene information to human users , And release general 、 The potential of responsive robotic systems .
Re detect the target It is defined as a single regression problem , Directly from image Pixel to bounding box coordinates and class probabilities . Just watch it once (YOLO) The image can predict the position of the object .
Other research programs
R-CNN:
- Firstly, the boundary box is generated in the image by using the region suggestion method
- Then run the classifier on these boxes
- After the classification , Use post-processing to refine the bounding box , Eliminate duplicate detection , And re - edit the box based on other objects in the scene Sort
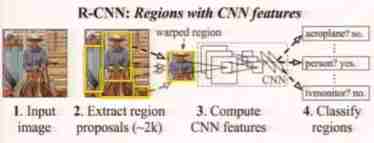
Deformable part model (DPM) Such a system uses Sliding window method , The classifier is on the whole image Run at evenly spaced positions
- To detect an object , System Use a classifier for this object , And evaluate it in different positions and proportions in the test image .
The problem : These complex pipelines slow , Difficult to optimize , Because each individual component must be trained separately .
yolo Structure

A single convolution network predicts multiple bounding boxes and the class probabilities of these boxes at the same time .YOLO Train the complete image , And directly optimize the detection performance .
- yolo Very fast . Because we treat detection as a regression problem , So there is no need for complex pipelines .
- Can be in less than 25 Real time processing of streaming video within millisecond delay time . Besides ,YOLO The average accuracy of other real-time systems is more than twice .
- Different from the technology based on sliding window and region suggestions ,YOLO See the whole image during training and testing , So it implicitly Encode context information about the class and its appearance .
- YOLO A generalizable representation of a learning object . because YOLO It has a high degree of versatility , So when applied to a new domain or unexpected input , It's unlikely to collapse .
- When training on natural images and testing on works of art ,YOLO Is far better than DPM and R-CNN Top level detection methods .
- YOLO It still lags behind the most advanced detection systems in terms of accuracy . Though it Can quickly identify Objects in the image , But it It is difficult to precisely locate certain objects , Especially small objects .
- yolo Very fast . Because we treat detection as a regression problem , So there is no need for complex pipelines .
yolo Prediction formula

Classification specific confidence scores in each box . These scores encode the probability that the category appears in the box and the matching degree between the prediction box and the object .

- Divide the input image into one S×S The grid of . If the center of the object falls into the mesh cell , The grid cell is responsible for detecting the object .
- Each grid cell predicts the bounding boxes and the confidence scores of these boxes .
- These confidence scores reflect the model's confidence in the objects contained in the cell grid , And how accurate it thinks the box forecast is
- The confidence is defined as

- If there is no object in the cell , The confidence score should be zero . otherwise , We want the confidence score to be equal to the joint intersection between the prediction frame and the basic facts (IOU).
- Each bounding box consists of 5 A prediction consists of :x、y、w、h And confidence
- (x,y) The coordinates represent the center of the cell grid relative to the cell boundary of the grid .
- w,h Predict width and height relative to the entire image .
- The confidence prediction represents the difference between the prediction box and any ground truth box IOU.
- Each grid cell also predicts conditional class probabilities , These probabilities depend on the mesh cell containing the object . A set of class probabilities for each grid element , It has nothing to do with the number of frames .
- and Predict the bounding box for each grid cell 、 The confidence level and category probability of these boxes . These predictions are encoded as S×S×(B∗5+C) tensor .
- S Number of grid copies divided into ,S*S
- B Number of box types required
- C Is the number of tags
Network structure design
The initial convolution layer of the network extracts features from the image , The full connection layer predicts the probability and coordinates of the output .
The Internet has 24 Convolution layers , And then there was 2 A fully connected layer . Not used GoogLeNet Initial module used , It's just using 1×1 Restore layer and 3×3 Convolution layer , Alternate 1×1 The convolution layer reduces the feature space of the previous layer .

Use Darknet frame Do all the training and reasoning
The last layer predicts the class probability and boundary box coordinates . Normalize the width and height of the bounding box by image width and height , Make it between 0 and 1 Between . We will the bounding box X and Y The coordinates are parameterized to the offset of a specific grid cell location , So they are also 0 and 1 There is a boundary between .
Loss Function definition
YOLO Use Mean square sum error As loss Function to optimize model parameters , That is, the output of the network S*S*(B*5 + C) Correspondence between dimension vector and real image S*S*(B*5 + C) Mean square sum error of dimensional vector .
l o s s = ∑ i = 0 s 2 ( c o o r d E r r o r + i o u E r r o r + c l a s s E r r o r ) loss = \sum_{i=0}^{s^2}(coordError+iouError+classError) loss=i=0∑s2(coordError+iouError+classError)
among ,coordError、iouError and classError Respectively represent the coordinate error between the predicted data and the calibration data 、IOU Error and classification error .
YOLO Yes loss Some adjustments have been made to the calculation of
Position dependent error ( coordinate 、IOU) And classification error on the network loss Of Contribution values are different , therefore YOLO In the calculation loss when , Use [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-EWzEsrDs-1639708493727)(https://www.zhihu.com/equation?tex=%5Clambda+_%7Bcoord%7D+%3D5)] correct [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-M60NGVjv-1639708493729)(https://www.zhihu.com/equation?tex=coordError)].
In the calculation IOU When error occurs , A lattice with objects and a lattice without objects , Of the two IOU The effect of error on the network loss The contribution value of is different . If we use the same weight , So the lattice that doesn't contain objects confidence The value is approximately 0, In a disguised form, it enlarges the lattice containing objects confidence The influence of error on the calculation of network parameter gradient . To solve this problem ,YOLO Use [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-yESGeY4c-1639708493730)(https://www.zhihu.com/equation?tex=%5Clambda+_%7Bnoobj%7D+%3D0.5)] correct [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-o90QO23h-1639708493731)(https://www.zhihu.com/equation?tex=iouError)].( Note here ‘ contain ’ It means there is an object , Its center coordinates fall into the grid ).
For equal error values , The influence of large object error on detection should be less than that of small object error . This is because , The proportion of the same position deviation in large objects is far less than that of the same deviation in small objects .YOLO Put the size of the object into the information item (w and h) To improve the problem by finding the square root .( notes : This method does not completely solve this problem ).

- among ,[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-2m4671z8-1639708493733)(https://www.zhihu.com/equation?tex=x%2Cy%2Cw%2CC%2Cp)] Forecast value for the network ,[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-Da1mmuov-1639708493739)(https://www.zhihu.com/equation?tex=x%2Cy%2Cw%2CC%2Cp)] hat by ** Dimension value **.[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-83JSCfyt-1639708493745)(https://www.zhihu.com/equation?tex=%5CPi+_%7Bi%7D%5E%7Bobj%7D+)] It means that the object falls into the lattice i in ,[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-nf72cdEA-1639708493751)(https://www.zhihu.com/equation?tex=%5CPi+_%7Bij%7D%5E%7Bobj%7D+)] and [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-jrFazmbw-1639708493755)(https://www.zhihu.com/equation?tex=%5CPi+_%7Bij%7D%5E%7Bnoobj%7D+)] Indicates whether the object falls into the grid or not i Of the j individual bounding box Inside . - Formula No 1 Xing He 2 That's ok . > - All carry [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-wzqlpIDB-1639708493757)(https://math.jianshu.com/math?formula=1_%7Bij%7D%5E%7Bobj%7D)] signify ** Only " be responsible for "(IOU The larger ) The one predicted bounding box The data of ** Will be included in the error . > - The first 2 The row width and height take the square root first , Because if you take the difference directly , Large objects are less sensitive to differences , Small objects are more sensitive to the difference , therefore ** Taking the square root can reduce the difference in sensitivity , So that larger objects and smaller objects have similar weight in size error **. > - multiply [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-sQo8aXmY-1639708493760)(https://math.jianshu.com/math?formula=%5Clambda_%7Bcoord%7D)] ** Adjust the bounding box Weight of position error **( Confidence and relative classification error ).YOLO Set up [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-3bYbqtqf-1639708493762)(https://math.jianshu.com/math?formula=%5Clambda_%7Bcoord%7D%20%3D%205)], That is, increase the weight of position error . - Formula No 3 Xing He 4 That's ok . > - The first 3 Rows are objects that exist bounding box Confidence error . with [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-GkRpE3Gq-1639708493764)(https://math.jianshu.com/math?formula=1_%7Bij%7D%5E%7Bobj%7D)] signify ** Only " be responsible for "(IOU The larger ) The one predicted bounding box The degree of confidence ** Will be included in the error . > - The first 4 Rows are objects that do not exist bounding box Confidence error .** Because there is no object bounding box You should honestly say " I have no object here ", That is, output as low confidence as possible .** If it is not appropriate, the output has a high degree of confidence , Will be with the real " be responsible for " The one predicted by the object bounding box Create confusion . In fact, it's like object classification , The correct object probability is 1, The probability of all other objects is better 0. > - The first 4 Guild times [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-xyr30UZF-1639708493767)(https://math.jianshu.com/math?formula=%5Clambda_%7Bnoobj%7D)] ** Adjust for objects that do not exist bounding box The weight of confidence ( Relative to other errors )**.YOLO Set up [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-duG5pPko-1639708493769)(https://math.jianshu.com/math?formula=%5Clambda_%7Bnoobj%7D%20%3D%200.5)], That is, lower the of non-existent objects bounding box The weight of the confidence error . - Formula No 5 That's ok , Be careful [ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-TnJweZia-1639708493771)(https://math.jianshu.com/math?formula=1_i%5E%7Bobj%7D)] This means that only meshes with objects are included in the error . - ```python link :https://www.jianshu.com/p/cad68ca85e27 ```- YOLO Methods model training Rely on object recognition annotation data , therefore , For unconventional shapes or proportions ,YOLO The detection effect of this method is not ideal .
- YOLO Multiple subsampling layers are used , The features of objects learned on the Internet are not precise , Therefore, it will also affect the detection effect .
- YOLO loss Function , A large object IOU Errors and small objects IOU Error in network training loss Contribution value is close to ( Although we use the square root method , But there is no fundamental solution ). therefore , For small objects , Small IOU The error will also have a great impact on the network optimization process , Thus, the positioning accuracy of object detection is reduced .
https://zhuanlan.zhihu.com/p/25236464
yolo Training
- Preliminary training . Use ImageNet-1000 Class data training YOLO The front of the Internet 20 Convolution layers +1 individual average Pooling layer +1 All connection layers . Training image resolution resize To 224x224.
- Use steps 1) Got front 20 Initialization is performed with a convolution layer network parameter YOLO Before the model 20 The network parameters of a convolution layer , And then use VOC 20 Class annotation data YOLO model training . To improve image accuracy , When training the detection model , The input image resolution resize To 448x448.
Two stage model comparison
Non maximum suppression
Referred to as NMS Algorithm , English is Non-Maximum Suppression. The idea is to search the local maximum of the element , Suppress the maximum .

Take target detection as an example : In the process of target detection, a large number of candidate boxes will be generated in the same target position , These candidate boxes may have... Between them overlap , At this time, we need to use non maximum suppression to find the best target bounding box , Eliminate redundant bounding boxes .
- IoU:intersection-over-union, That is, the intersection of two bounding boxes is divided by their union .
Do not use non maximum suppression , Multiple candidate boxes will appear . Suppress elements that are not maxima , It can be understood as local maximum search .
The process of non maximum suppression is as follows :
- Sort by confidence score
- Select the ratio bounding box with the highest confidence to add to the final output list , Remove it from the bounding box list
- Calculate the area of all bounding boxes
- Calculate the difference between the bounding box with the highest confidence and other candidate boxes IoU.
- Delete IoU Bounding boxes larger than the threshold ( It means that the same object is detected with the box with the highest confidence )
- Repeat the process , Until the bounding box list is empty .
YOLO The limitation of
- YOLO Strong spatial constraints are imposed on bounding box prediction , Because each grid cell can only predict two boxes , And there can only be one class .
- This spatial constraint It limits the number of nearby objects that our model can predict . It is not conducive to detecting small objects
- Model from Learning prediction bounding box from data , it It's hard to promote To objects with new or unusual aspect ratios or configurations .
- When training a loss function that approximates detection performance , The loss function handles the same errors in the small and large bounding boxes , Small mistakes in large boxes are usually benign , But the small mistake in the small box is right IOU The impact is much greater . The main source of error is incorrect positioning .
Robust feature
Haar
Haar-like The feature is in the field of computer vision A common feature description operator
And will be Haar-like Expand to three dimensions ( be called 3DHaar-Like) Used to describe dynamic features in video .
Haar Development history of
Haar-like There are only white and black rectangles in the feature template , The characteristic values of the template are defined as white rectangle pixels and subtracting black rectangle pixels and .Haar The eigenvalue It reflects the gray level change of the image .
Haar-like Feature classification
- Linear characteristics 、
- Edge features 、
- Point feature ( Central features )、
- Diagonal features ;
SIFT
SIFT That is, scale invariant feature transformation , It is a description used in the field of image processing . This description has scale invariance , Key points can be detected in the image , It's a kind of Local feature descriptor .
SIFT Algorithm characteristics :
- Have a better stability and invariance , Able to adapt to rotation 、 Scaling 、 Change in brightness , To a certain extent, it is not affected by the change of perspective 、 Affine transformation 、 Noise interference .
- Distinctiveness good , It can quickly and accurately distinguish information and match in massive feature database
- Multiplicity , Even if there is only a single object , It can also produce a large number of eigenvectors
- Recommend suite , Can quickly carry out feature vector matching
- Extensibility , It can be combined with other forms of eigenvectors
stay Find key points on different scale spaces , And calculate the direction of the key point .
SIFT The algorithm realizes feature matching mainly in the following three processes :
- Extract keys : The key points are Very prominent will not be caused by light 、 scale 、 Points that disappear due to factors such as rotation , Like corners 、 Edge point 、 Bright spots in dark areas and dark spots in bright areas . This step is to search the image position in all scale spaces . The potential points of interest with scale and rotation invariance are identified by Gaussian differential function .
- ** Locate keys and orient features :** At each candidate position , Through a fine fitting model to determine the location and scale . The selection of key points depends on their stability . Then, based on the local gradient direction of the image , One or more directions assigned to each key location . All subsequent operations on image data are relative to the direction of key points 、 Scale and position are transformed , So as to provide invariance to these transformations .
- Through the eigenvector of each key point , Make pairwise comparison to find out several pairs of matching feature points , Establish the corresponding relationship between scenes .
- Link to the original text :https://blog.csdn.net/qq_37374643/article/details/88606351
HOG
Direction gradient histogram (Histogram of Oriented Gradient, HOG), It is a feature descriptor used for object detection in computer vision and image processing .
HOG The feature is formed by calculating and counting the gradient direction histogram of the local area of the image .
thought : In an image , The image and shape of the local target can be well described by the gradient or the directional density distribution of the edge . Its essence is : Gradient Statistics , And the gradient is mainly at the edge .
HOG Feature extraction and calculation steps
Color and gamma normalization
- In order to reduce the influence of light , First, we need to normalize the whole image ( normalization ). In the texture intensity of the image , Local surface exposure contributes a large proportion , therefore , This kind of compression can effectively reduce the shadow and illumination changes in the image .
Calculate the image gradient
- Calculate the gradient in the abscissa and ordinate directions of the image , According to this, the gradient direction value of each pixel position is calculated ; Derivative operations can not only capture contours , Human shadow and some texture information , It can further weaken the influence of light . The most common method is : Simply use a one-dimensional discrete differential template to process the image in one direction or both horizontal and vertical directions , To be more exact , This method requires the use of filter kernels to filter out the color or data with drastic changes in the image
Construct a histogram of the direction
- Each pixel in the cell cell votes for a direction based histogram channel . Voting is a way of weighted voting , That is, each vote is weighted , This weight is calculated according to the gradient amplitude of the pixel . This weight can be expressed by the amplitude itself or its function .
Combine cell units into large intervals
- because Change of local illumination and foreground - Changes in background contrast , It makes the gradient intensity change in a very large range . So we need to normalize the gradient intensity . Normalization can be further applied to light 、 Shadows and edges are compressed .. Combine the cell units into large ones 、 Connected intervals in space . such ,HOG The descriptor becomes a vector composed of histogram components of all cell units in each interval . These intervals overlap each other , That means : The output of each cell unit acts on the final descriptor many times .
Convolution features
DPM
- Use disjoint pipes to extract static features 、 Classification area 、 Predict the bounding box of the high score area
- YOLO Perform feature extraction at the same time 、 Bounding box prediction 、 Non maximum suppression and contextual reasoning . Instead of static features , Network online training features , And optimize the detection task .
R-CNN
- Selective search generates potential bounding boxes , Convolution network to extract features ,SVM score , Linear model adjustment bounding box , Non maximum suppression de duplication detection .
- Each stage of a complex pipeline must be accurately tuned independently , As a result, the system is very slow , Each image needs to be tested 40 More than seconds
fast and faster R_CNN
- Focus on accelerating through shared computing and using neural networks to propose regions rather than selective search R-CNN frame
- Their ratio R-CNN Provides improvements in speed and accuracy , But their real-time performance is still insufficient .
VGG-16 Training YOLO. This model is more accurate , But it's also better than YOLO Much slower .
Preliminary training
- First , Random initialization parameters are required , And then start training the network , Keep adjusting until the loss of the network is getting smaller and smaller .
- During the training , The initial initialization parameters are constantly changing . When the results are satisfactory , You can save the parameters of the training model , So that the trained model can get better results in the next similar task . This process is pre−training.
- Directly use the parameters of the saved model as the initialization parameters of this task , And then in the process of training , Make constant changes based on the results . Now , You're using a pre−trained Model , And the process is finetuning.
- Preliminary training It refers to a model of pre training or the process of pre training model ; fine-tuning It means to apply the pre trained model to one's own data set , And adapt the parameters to the process of your own data set .
- such as VGG,Inception And other models provide their own training parameters , So that people can fine tune . This saves time and computing resources , And can quickly achieve better results .
YOLO Training data
fast R_CNN and yolo Comparison of training data :

YOLO Try to position the object correctly . Relative to the sum of all other sources , Positioning errors account for YOLO The proportion of errors is even greater .
Fast R-CNN There are far fewer positioning errors , But there are far more background errors .





tips:
- Because the output layer is full connection layer , So when it comes to testing ,YOLO Training models Only the same input resolution as the training image is supported
- Although each lattice can be predicted B individual bounding box, But in the end, only IOU The highest bounding box As object detection output , That is, only one object can be predicted for each lattice . When the proportion of objects in the picture is small , If the image contains herds or birds , Each lattice contains more than one object , But only one of them can be detected . This is a YOLO A defect of the method .
object detection MAP value
Each picture in the target detection problem may contain some different types of objects .
Evaluation indicators need to know ground truth( Real label ) data .ground truth It includes the categories of objects in the image and the real bounding box of each object in the image .
Precision rate (precision) And recall (recall):
For dichotomies , Examples can be divided into real examples according to the combination of their real categories and learner prediction categories (true positive)、 False positive example (false positive)、 True counter example (true negative)、 False counter example (false negative) Four situations , Make TP、FP、TN、FN Respectively represent the corresponding number of samples , There is obviously TP+FP+TN+FN= Total number of samples . Classification results “ Confusion matrix ”(confusion matrix) As shown in the table :
real | forecast Example Counter example Example TP( Real examples ), Correctly marked as positive FN( False counter example ), Incorrectly marked negative Counter example FP( False positive example ), Incorrectly marked as positive TN( True counter example ), Correctly marked as negative Precision rate P And recall R
P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
R = T P T P + F N R = \frac{TP}{TP+FN} R=TP+FNTP
Precision: Measure how many of the selected samples match the expected proportion of samples .
recall: Measure how many of the matching samples are selected .
Generally speaking, when the accuracy is high , The recall rate is often low ; When the recall rate is high , Precision is often low .
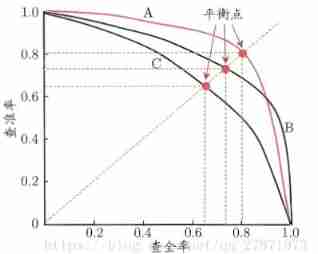
Take the precision as the vertical axis , Recall is plotted on the horizontal axis , You get the accuracy - Recall curve , abbreviation "P-R curve ".
Balance point (BER): Precision rate = The value of recall , To compare the model .
AP value :PR Approximation of the area under the curve , It's a 0~1 Value between , It can also be used to measure the performance
- AP It's a number , Model AP Big , The model is better , It is convenient to compare different models

MAP(mean Average Precision, That is, each category AP Average value )
- For each category , Calculate as above AP, Take all categories of AP The average is mAP.
https://blog.csdn.net/bestrivern/article/details/98482493
Build your own target detection database
First of all, we have to mark the data , That is, first tell the machine what objects are in the image 、 Where is the object , With this information, we can train the model .
At present, the popular data annotation file formats mainly include VOC_2007、VOC_2012, This text format comes from Pascal VOC Standard data set , This is one of the important benchmarks to measure the ability of image classification and recognition . Such as VOC_2007 Data format file , With xml Format store

The important information is :filename: The filename of the picture ;name: Marked object name ;xmin、ymin、xmax、ymax: The upper left corner of the object's position 、 Lower right coordinates
Dimensioning tools :
- Data tagging tools labelImg, You can mark the frame through the visual operation interface , You can automatically generate VOC Format xml The file .
- By visiting labelImg Of github page (https://github.com/tzutalin/labelImg), Download source code .
Annotation data :
Create folder
- Annotations: Used to store marked xml file
- ImageSets/Main: Used to store training sets 、 Test set 、 List of documents for acceptance set
- JPEGImages: Used to store the original image
Annotation data :
- Put the picture set in JPEGImages In the folder , Note that the format of the picture must be jpg Format .
- open labelImg Dimensioning tools , Then click the toolbar on the left “Open Dir” Button , Select the picture you just put JPEGImages Folder .
- Click... On the left toolbar “Create RectBox” Button , Then click and pull a rectangle on the main interface , Circle the goal . After delineation , A dialog box will pop up , Used to enter the name of the labeled object .
- Then click... On the left toolbar “Save” Button , Choose the Annotations As a save Directory , The system will automatically generate voc_2007 Format xml Keep the file .
Divide the training set 、 Test set 、 Verification set
- stay github Download an automatic partition script from (https://github.com/EddyGao/make_VOC2007/blob/master/make_main_txt.py)
https://my.oschina.net/u/876354/blog/1927351?tdsourcetag=s_pcqq_aiomsg
Click to pull a rectangle , Circle the goal . After delineation , A dialog box will pop up , Used to enter the name of the labeled object .
> > - Then click... On the left toolbar “Save” Button , Choose the Annotations As a save Directory , The system will automatically generate voc_2007 Format xml Keep the file .
>
> - Divide the training set 、 Test set 、 Verification set
>
> > - stay github Download an automatic partition script from (https://github.com/EddyGao/make_VOC2007/blob/master/make_main_txt.py)
https://my.oschina.net/u/876354/blog/1927351?tdsourcetag=s_pcqq_aiomsg
边栏推荐
- Barrykay electronics rushes to the scientific innovation board: it is planned to raise 360million yuan. Mr. and Mrs. Wang Binhua are the major shareholders
- Microsoft Pinyin opens U / V input mode
- Image table solid line and dashed line detection
- Leetcode 473. Match to square [violence + pruning]
- too old resource version,Code:410
- [open source] libinimini: a minimalist ini parsing library for single chip computers
- redis
- 4.11 introduction to firmware image package
- Basic exercises of test questions Fibonacci series
- Paper reading - joint beat and downbeat tracking with recurrent neural networks
猜你喜欢

L1 regularization and its sparsity

regular expression

Basic principle of bilateral filtering

Application circuit and understanding of BAT54C as power supply protection

Superficial understanding of conditional random fields

Common web page status return code crawler

Priority queue with dynamically changing priority

Fast Color Segementation
![[pytorch]fixmatch code explanation (super detailed)](/img/22/66703bea0f8ee40eceb0687fcb3ad2.jpg)
[pytorch]fixmatch code explanation (super detailed)
![[reading point paper] deeplobv3 rethinking atlas revolution for semantic image segmentation ASPP](/img/4e/a5c6b1a8880209f89d6bf252ff889a.jpg)
[reading point paper] deeplobv3 rethinking atlas revolution for semantic image segmentation ASPP
随机推荐
Basic exercise of test questions decimal to hexadecimal
Leetcode 473. Match to square [violence + pruning]
Build MySQL environment under mac
Solution of depth learning for 3D anisotropic images
Mac使用Docker安装Oracle
在IDEA使用C3P0连接池连接SQL数据库后却不能显示数据库内容
STM32 steering gear controller
Graph theory, tree based concept
1000粉丝啦~
[pytorch] kaggle large image dataset data analysis + visualization
Configuring virtual private network FRR for Huawei equipment
C # illustrated tutorial (Fourth Edition) chapter7-7.2 accessing inherited members
ROS learning-7 error in custom message or service reference header file
Chapter7-10_ Deep Learning for Question Answering (1/2)
[keras learning]fit_ Generator analysis and complete examples
STM32 timer interrupt learning notes
Basic exercises of test questions letter graphics ※
[keras] train py
Huawei equipment is configured with dual reflectors to optimize the backbone layer of the virtual private network
Uniapp preview function