当前位置:网站首页>[recommendation system learning] recommendation system architecture
[recommendation system learning] recommendation system architecture
2022-06-26 17:06:00 【CC‘s World】
One 、 System architecture
Recommend system architecture , First, from a data-driven perspective , For data , The easiest way is to save it , Reserved for subsequent offline processing , The offline layer is part of the architecture we use to manage offline jobs . The online layer can respond more quickly to recent events and user interactions , But it must be done in real time . This limits the complexity of the algorithm used and the amount of data processed . Offline computing has fewer restrictions on the amount of data and algorithm complexity , Because it is done in batches , There is no strong time requirement . however , Because the latest data is not added in time , So it's easy to be out of date .
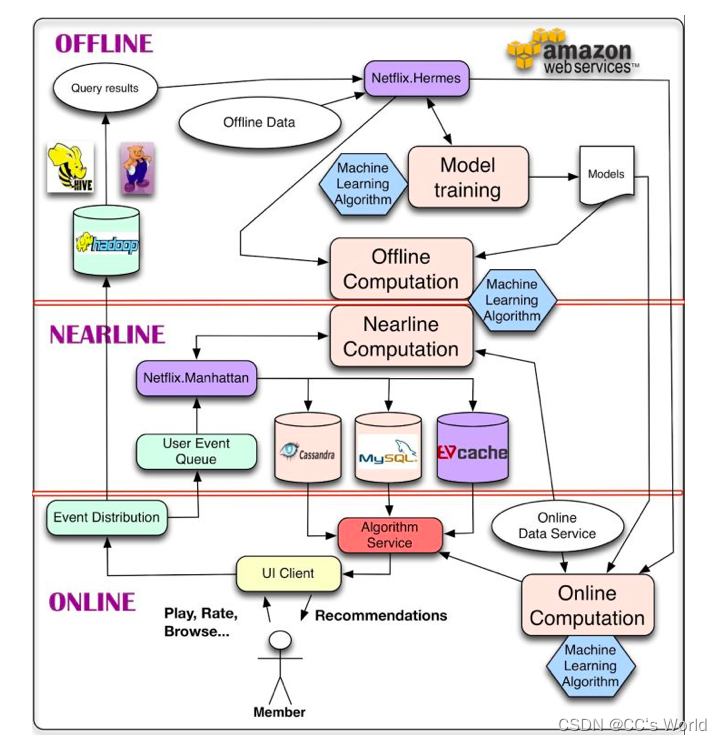
The whole data part is actually a whole link , It's mainly three pieces , They are client and server real-time data processing 、 Stream processing platform, quasi real-time data processing and big data platform, offline data processing .
The first is the real-time data processing of client and server . It's easy to understand , The job of this step is to record . Record the real behavior of users on the platform , For example, what users see , With which content , And what didn't interact . If it's a little more elaborate , It also records the time the user stays , Devices used by users, etc . In addition, it also records the time when the behavior occurred , The act of taking place session Other contextual information .
This part is mainly completed by the back-end and client , The industry term is "burying point" . The so-called burying point is actually a recording point , Because data needs engineers to actively record , No record, no data , Data is only available after recording . Since we are going to build a recommendation system , To analyze user behavior , And training models , Obviously you need data . Data needed , You need to record .
The second step is the quasi real-time data processing of the stream processing platform , What is this step for , In fact, it also records data , It's just recording some quasi real-time data . Quasi real time means real time , It's just not that instant , For example, there may be a few minutes of error . Such real-time data with errors , The industry term is quasi real time . So what kind of quasi real-time data needs to be recorded ? There is basically only one category in the recommendation field , User behavior data . That is, what users have seen before viewing this content , What has interacted with . Ideally, this part of the data also needs to be made real-time , However, due to the large amount of data in this part , And the logic is relatively complex , So it's hard to be very real-time , Generally, it is made quasi real-time by means of message queue and online cache .
Finally, let's look at the third step , It is called offline data processing , Offline means offline processing , Basically, there is no time limit .
Generally speaking , Offline processing is the main part of data processing . all “ Dirty work is tiring ” Complex operations are done offline , For example, some join operation . The back end only records the products that users interact with id, We need the detailed information of the goods ? You need to query the table associated with the commodity table . Obviously, data association is a very time-consuming operation , So we can only do it offline .
1.1 Offline layer
The offline layer is the most computationally intensive part , Its characteristic is that it does not rely on real-time data , There is no need to provide services in real time . The main functional modules to be implemented are :
- Data processing 、 data storage ;
- Feature Engineering 、 Offline feature calculation ;
- Training of offline model ;
Here we can see that the task of the offline layer is closest to the data we process in the school 、 Training models for this task , The difference may be that we need to face a larger scale of data . Offline tasks generally run by days or longer , For example, regularly update the data of this day every night , And then retrain the model , The next day, the new model was launched .
Advantages and disadvantages of offline layer
The offline layer faces the largest amount of data , The main problem is massive data storage 、 Large scale feature engineering 、 Multi machine distributed machine learning model training . The current mainstream approach is HDFS, Collect all our business data , adopt HIVE Tools such as , Extract the data we need from the total data , Carry out corresponding processing , The mainstream distributed Book framework used in the offline phase is generally Spark. So the offline layer has the following advantages :
- It can handle a lot of data , Carry out large-scale feature engineering ;
- Batch processing and calculation ;
- No response time requirements ;
But again , If we only use user offline data , The biggest disadvantage is that it can not reflect the real-time interest changes of users , This led to the generation of the nearline layer .
1.2 Near line layer
The main feature of the near line layer is quasi real time , It can get real-time data , And then quickly calculate and provide services , However, it is not required to achieve the delay of tens of milliseconds like the online layer . The generation of near line layer is to make up for the shortage of offline layer and online layer at the same time , The product of compromise .
It is suitable for some tasks that are sensitive to delay , such as :
- Fact update calculation of features : For example, the statistics of different users type Of ctr, A common problem in recommendation systems is how to deal with inconsistent feature distribution , This problem is easy to occur if you use the features calculated offline . The near line layer can obtain real-time data , This problem can be avoided by calculating users' real-time interests .
- Acquisition of real-time training data : Like in use DIN、DSIN This network will depend on real-time changes in users' interests , The user can get the feature input model through the near line layer by clicking a few minutes ago .
- Model real-time training : The model can be updated through online learning , Real time push to online ;
The development of the near line layer benefits from the development of big data technology in recent years , Many stream processing frameworks have greatly promoted the progress of near line layer . Now Flink、Storm And other tools dominate the world .
1.3 Online layer
Online layer , It is the layer directly facing users . The biggest feature is the requirement for response delay , Because it is directly facing the user community , You can imagine that you can open the interfaces such as Tiktok Taobao , Almost all of them are recommended to you in seconds , I won't say it will take you a few more seconds . All user requests are sent to the online layer , The online layer needs to return results quickly , Its main tasks are :
- Model online services ; Including quick recall and sorting ;
- Online feature fast processing and splicing : Based on the incoming users ID And scene , Quickly read features and process ;
- AB Experiment or shunt : Different models are used according to different users , Such as cold start user and normal service model ;
- Operational research optimization and business intervention : For example, we should support the traffic of special businesses 、 Limit the flow of certain content ;
The typical online service is used RESTful/RPC And so on , Generally, the background service department of the company calls our service , Back to the front end . The specific way to deploy applications is to use Docker stay K8S Deploy . The data source of online services is the characteristics of each user and product calculated at the offline layer , We store it in the database in advance , The online layer only needs real-time splicing , No complex feature operation , Then input the model that has been trained in the near line layer or the off-line layer , Sort according to the reasoning results , Finally, it is returned to the background server , The back-end server scores each user according to our scores , And back to the user .
Two 、 Algorithm architecture
A general algorithm architecture , The design idea is to model the data layer by layer , Layer by layer screening , Help users find out what they are really interested in from the massive data .
2.1 Recall
The main goal of the recall layer is to select tens of thousands of... From the recommendation pool item, Send it to the subsequent sorting module . Because the candidate set faced by the recall is very large , And generally need online output , Therefore, the recall module must be light, fast and low delay . Since there is a sorting module as a guarantee in the follow-up , Recall does not need to be very accurate , But don't miss ( Especially the recall module in the search system ).
If there is no recall layer , Every User And everyone Item Go to the online sorting stage to predict the target probability , In theory, the effect is the best , But it is unrealistic , Online no delay allowed , Therefore, in the recall and rough sorting stage, we need to do some candidate set screening , Ensure that in the limited time that can be given to the sorting layer to do fine sorting of candidate sets , Maximize the effect . The other aspect is through this model cascade , It can reduce the pressure of fitting multi-objective with sorting stage , For example, in the recall phase, we are mainly ensuring that Item Focus on coverage diversity based on quality , In the rough sorting stage, a simple model is mainly used to solve the problems of different recalls and the relevance of current users , Finally, it is truncated to 1k No more than candidate sets , This candidate set conforms to a certain personalized relevance 、 Guarantee of video quality and diversity , Then I do ranking To make complex models predict.
At present, the multi-channel recall solution paradigm is basically adopted , It is divided into non personalized recall and personalized recall . Personalized recall has content-based、behavior-based、feature-based And so on .
The main considerations of the recall are :
- Consider the user level : Diversification of user interests , Diversification of user needs and scenarios : for example : News needs , Important news , Immersive reading of relevant contents, etc
- Consider the system level : Enhance the robustness of the system ; Partial recall is invalid , The rest of the recall queue will not lead to the failure of the entire recall layer ; The sorting layer is invalid , The recall queue will not invalidate the entire recommendation system
- System diversity content distribution : Image & Text 、 video 、 Small video ; accurate 、 Probe 、 A certain proportion of time ; Diversification of recall targets , for example : The correlation , Immersion duration , timeliness , Special content, etc
- Explicability recommends that some recalls have clear reasons for recommendation : Well solve the introduction of product data ;
2.2 Rough row
The reason for rough sorting is that sometimes there are too many recall results , The speed of fine arrangement layer still can't keep up , So add rough row . Coarse discharge can be understood as a round of filtration mechanism before fine discharge , Reduce the pressure of fine discharge module . Rough row is between recall and fine row , Take into account both accuracy and low latency . At present, rough layout is generally modeled , The training sample is similar to fine rehearsal , Select exposure and click positive sample , Exposure without clicking is a negative sample . However, rough sorting is generally oriented to tens of thousands of candidate sets , While the fine discharge is only hundreds or thousands , Its solution space is much larger .
The architecture design in the rough layout stage mainly considers three aspects , One is based on the important features in the fine - tuning model , To truncate the candidate set , The other part is that there are some recall designs , Such as heat or semantically related results , Only considered item Side features , You can use the rough sort model to sort with the current User The correlation between , Cut off accordingly , This is better than following alone item More personalized results can be obtained by truncating the inverted score on the side , Finally, the selection of algorithm should ensure the performance of online service , Because this stage is in pipeline Complete the cut-off work from recall to fine discharge , The ability to process more recall candidate sets within the allowable delay is theoretically positively related to the fine-tuning effect .
2.3 Fine discharge
Fine arrangement layer , It is also the layer we most often contact when learning to recommend , A large part of the algorithms we are familiar with come from the fine arrangement layer . The task of this layer is to obtain the results of rough sorting modules , Score and sort candidate sets . Fine scheduling is required when the maximum delay is allowed , Ensure the accuracy of scoring , It is a crucial module in the whole system , It's also the most complicated , The most studied module .
Fine tuning is the purest layer in the recommendation system , His goal is single and focused , Just focus on the tuning of the goal . In the beginning, the common goal of fine-tuning model is ctr, Later, it gradually developed cvr And so on . The basic goals of fine and coarse rows are the same , It is to sort the product collection , But different from the rough row , Fine sorting requires only a small amount of goods ( That is, the product set of rough output topN) Just sort it out . therefore , More features can be used in fine sorting than in coarse sorting , More complex models and more sophisticated strategies ( This is also the reason why users' characteristics and behaviors are widely used and participated in this layer ).
The fine arrangement layer model is the most research direction covered in the recommendation system , There are many sub fields worth studying and exploring , This is also the most technical part of the recommendation system , After all, it is directly facing the user , The layer that produces the most impact on users . At present, the deep learning of fine arrangement layer has dominated the world , The scheme adopted in the fine arrangement stage is relatively general , First of all, the sample size of a day is several billion , What we need to solve is the problem of sample size , Feed the model as much as possible to remember , On the other hand, timeliness , When user feedback is generated , How to give new feedback to the model as soon as possible , Learn the latest knowledge .
2.4 rearrangement
There are three common optimization objectives :Point Wise、Pair Wise and List Wise. The reordering stage produces a Top-N Reorder the sequence of items , Generate a Top-K A sequence of items , As the final result of the sorting system , Directly present to the user . The reason for reordering is that multiple items often interact with each other , Fine sorting is based on PointWise score , It is easy to cause serious homogenization of recommendation results , There's a lot of redundant information . The challenge of reordering is how to solve the massive state space , Generally, we use in the fine arrangement layer AUC As an indicator , But in reordering more attention NDCG Equal index .
Reorder in business , Get the sorting result of fine sorting , According to some strategies 、 Operation rules participate in sorting , Such as forced weight removal 、 Interval sort 、 Traffic support, etc 、 Operational strategy 、 diversity 、context Context, etc , Make a fine adjustment again . Reordering is more about List Wise As an optimization target , It focuses on the order of items in the list to optimize the model , But in general List Wise Because the state space is large , The training speed is slow .
Due to the complexity of the fine layout model , Considering the system delay , It is generally used point-wise The way , In parallel for each item scores . This makes the scoring lack of context awareness . Whether the user will finally click to buy a product , Besides having something to do with itself , And others around it item Also closely related . Rearrangement is generally light , You can add context awareness , Improve the overall recommended algorithm efficiency . For example, the right of beauty products was raised in March 8th , Break up the categories 、 Break up with the picture 、 Break up with the seller and other measures to ensure the user experience . There are many rules in rearrangement , But at present, there are many schemes based on models to improve the rearrangement effect .
2.5 Mixed platoon
Multiple business lines want to Feeds Get exposure from stream , You need to mix their results . For example, insert advertisements into the recommendation stream 、 Insert graphics and text into the video stream banner etc. . Policy can be based on rules ( Such as advertising ) And reinforcement learning to achieve .
Reference material
边栏推荐
- Romance of the Three Kingdoms: responsibility chain model
- Science | giant bacteria found in mangroves challenge the traditional concept of nuclear free membrane
- Platform management background and merchant menu resource management: access control design of platform management background
- Teach you to learn dapr - 9 Observability
- 对NFT市场前景的7个看法
- Today, I met a "migrant worker" who took out 38K from Tencent, which let me see the ceiling of the foundation
- STM32F103C8T6实现呼吸灯代码
- 玩转Linux,轻松安装配置MySQL
- r329(MAIX-II-A(M2A)资料汇总
- Deployment and operation of mongodb partitioned cluster
猜你喜欢

防火 疏散 自救…这场安全生产暨消防培训干货满满!

Community ownership of NFT trading market is unstoppable

Inspirational. In one year, from Xiaobai to entering the core Department of Alibaba, his counter attack
7 views on NFT market prospect

Gui+sqlserver examination system

Platform management background and merchant menu resource management: merchant registration management design

玩轉Linux,輕松安裝配置MySQL

Summary of all knowledge points of C language

Discussion: the next generation of stable coins
玩转Linux,轻松安装配置MySQL
随机推荐
Detailed contract quantification system development scheme and technical description of quantitative contract system development
Constructors and Destructors
分布式架构概述
Environment setup mongodb
What is the difference between digital collections and NFT
20:第三章:开发通行证服务:3:在程序中,打通redis服务器;(仅仅是打通redis服务器,不涉及具体的业务开发)
Kubecon China 2021 Alibaba cloud special session is coming! These first day highlights should not be missed
宝藏又小众的CTA动画素材素材网站分享
7 views on NFT market prospect
When I was in the library, I thought of the yuan sharing mode
proxy
Teach you to learn dapr - 4 Service invocation
SIGIR 2022 | 港大等提出超图对比学习在推荐系统中的应用
Greenplum database fault analysis - semop (id=2000421076, num=11) failed: invalid argument
The texstudio official website cannot be opened
Several forms of buffer in circuit
Alibaba's "high concurrency" tutorial "basic + actual combat + source code + interview + Architecture" is a god class
探讨:下一代稳定币
Day10 daily 3 questions (1): sum gradually to get the minimum value of positive numbers
Count the number of words in a line of string and take it as the return value of the function