1.环境建立
1.使用xmapp安装php, mysql ,phpmyadmin
2.安装python3,pip
3.安装pymysql
3.(windows 略)我这边是mac,安装brew,用brew 安装scrapy
2.整个流程
1. 创建数据库和数据库表,准备保存
2.write crawler targetURL,进行网络请求
3.Process the crawl return data,得到具体数据
4.For specific data saved to the database
2.1.创建数据库
First create a database called scrapy,然后创建一个表article,我们这里给body加了唯一索引,防止重复插入数据
--
-- Database: `scrapy`
--
-- --------------------------------------------------------
--
-- 表的结构 `article`
--
CREATE
TABLE `article`
(
`id`
int
(
11
)
NOT
NULL
,
`body`
varchar
(
200
) CHARACTER
SET utf8 COLLATE utf8_bin
NOT
NULL
,
`author`
varchar
(
50
) CHARACTER
SET utf8 COLLATE utf8_bin
NOT
NULL
,
`createDate`
datetime
NOT
NULL
) ENGINE
=InnoDB DEFAULT CHARSET
=latin1
;
--
-- Indexes for table `article`
--
ALTER
TABLE `article`
ADD PRIMARY KEY
(`id`
)
,
ADD UNIQUE KEY `uk_body`
(`body`
)
;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
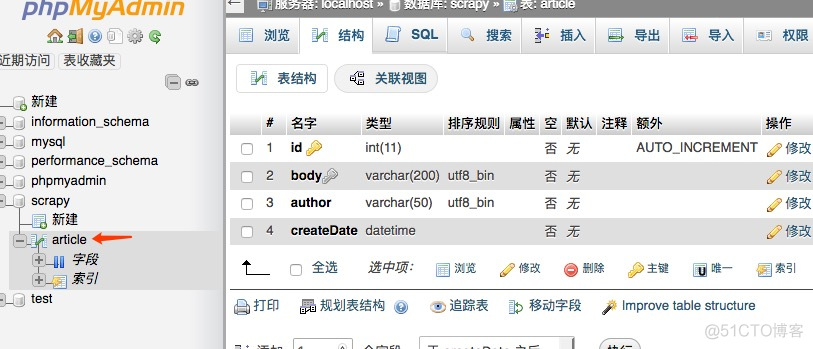
It's like this after it's done.
2.2 Let's first look at the structure of the entire crawler project
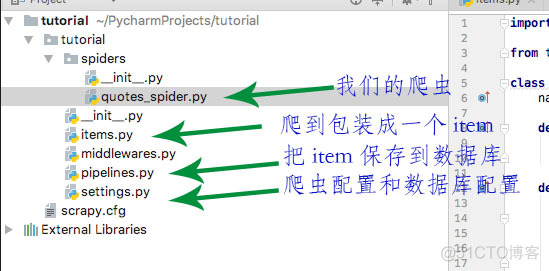
quotes_spider.py是核心,Responsible for processing network requests and content,Then throw the sorted contentpipelines进行具体处理,保存到数据库中,This will not affect the speed.
其他的看 图说明
2.2 write crawler targetURL,进行网络请求
import
scrapy
from
tutorial.
items
import
TutorialItem
class
QuotesSpider(
scrapy.
Spider):
name
=
"quotes"
def
start_requests(
self):
url
=
'http://quotes.toscrape.com/tag/humor/'
yield
scrapy.
Request(
url)
def
parse(
self,
response):
item
=
TutorialItem()
for
quote
in
response.
css(
'div.quote'):
item[
'body']
=
quote.
css(
'span.text::text').
extract_first()
item[
'author']
=
quote.
css(
'small.author::text').
extract_first()
yield
item
next_page
=
response.
css(
'li.next a::attr("href")').
extract_first()
if
next_page
is
not
None:
yield
response.
follow(
next_page,
self.
parse)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
start_requests Is to write the specific to climbURL
parseIt is the core where the returned data is processed,然后以item的形式抛出,Next, define the next content to crawl
2.3 items
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import
scrapy
class
TutorialItem(
scrapy.
Item):
body
=
scrapy.
Field()
author
=
scrapy.
Field()
pass
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
2.4 pipelines
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import
pymysql
import
datetime
from
tutorial
import
settings
import
logging
class
TutorialPipeline(
object):
def
__init__(
self):
self.
connect
=
pymysql.
connect(
host
=
settings.
MYSQL_HOST,
db
=
settings.
MYSQL_DBNAME,
user
=
settings.
MYSQL_USER,
passwd
=
settings.
MYSQL_PASSWD,
charset
=
'utf8',
use_unicode
=
True
)
self.
cursor
=
self.
connect.
cursor();
def
process_item(
self,
item,
spider):
try:
self.
cursor.
execute(
"insert into article (body, author, createDate) value(%s, %s, %s) on duplicate key update author=(author)",
(
item[
'body'],
item[
'author'],
datetime.
datetime.
now()
))
self.
connect.
commit()
except
Exception
as
error:
logging.
log(
error)
return
item
def
close_spider(
self,
spider):
self.
connect.
close();
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
2.5 配置
ITEM_PIPELINES
= {
'tutorial.pipelines.TutorialPipeline':
300
}
MYSQL_HOST
=
'localhost'
MYSQL_DBNAME
=
'scrapy'
MYSQL_USER
=
'root'
MYSQL_PASSWD
=
'123456'
MYSQL_PORT
=
3306
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
http://www.waitingfy.com/archives/1989
原网站版权声明
本文为[51CTO]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/214/202208020913327925.html