当前位置:网站首页>Re23:读论文 How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence
Re23:读论文 How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence
2022-08-02 09:16:00 【诸神缄默不语】
论文名称:How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence
论文ArXiv下载地址:https://arxiv.org/abs/2004.12158
论文ACL官方下载地址:https://aclanthology.org/2020.acl-main.466/
实现SOTA模型的GitHub项目:thunlp/CLAIM
领域数据集和论文总结的GitHub项目:thunlp/LegalPapers: Must-read Papers on Legal Intelligence
本文是2020年ACL论文,是legalAI领域的综述,主要关注近年(2018年以来)的数据驱动、基于表征学习的NLP方法(有缺乏可解释性、有性别偏见和种族歧视等道德隐患的问题),并对要素识别、案例判决、相似案例匹配和legalQA任务的SOTA方法进行了实现和分析(实现代码和数据集都可以在GitHub项目中找到)。
作者来自清华。
我感觉这篇文章写得不错,但是总结还是不够全面,而且也不够新。但是作者的思维非常深刻,对领域的理解比我好,学习了!
文章目录
1. Background
legalAI可以将法律从业者从海量的文书工作中解放出来,传统legalAI方法是基于规则(结构化预测方法)或者符号(手工抽取可解释的符号,应用可解释的法律知识在事件、关系等法律文书的符号间推理)的。
legalAI所采用的文本材料有判决文书、合同、法律意见书(legal opinion)等。legalAI对可解释性天然有高要求。
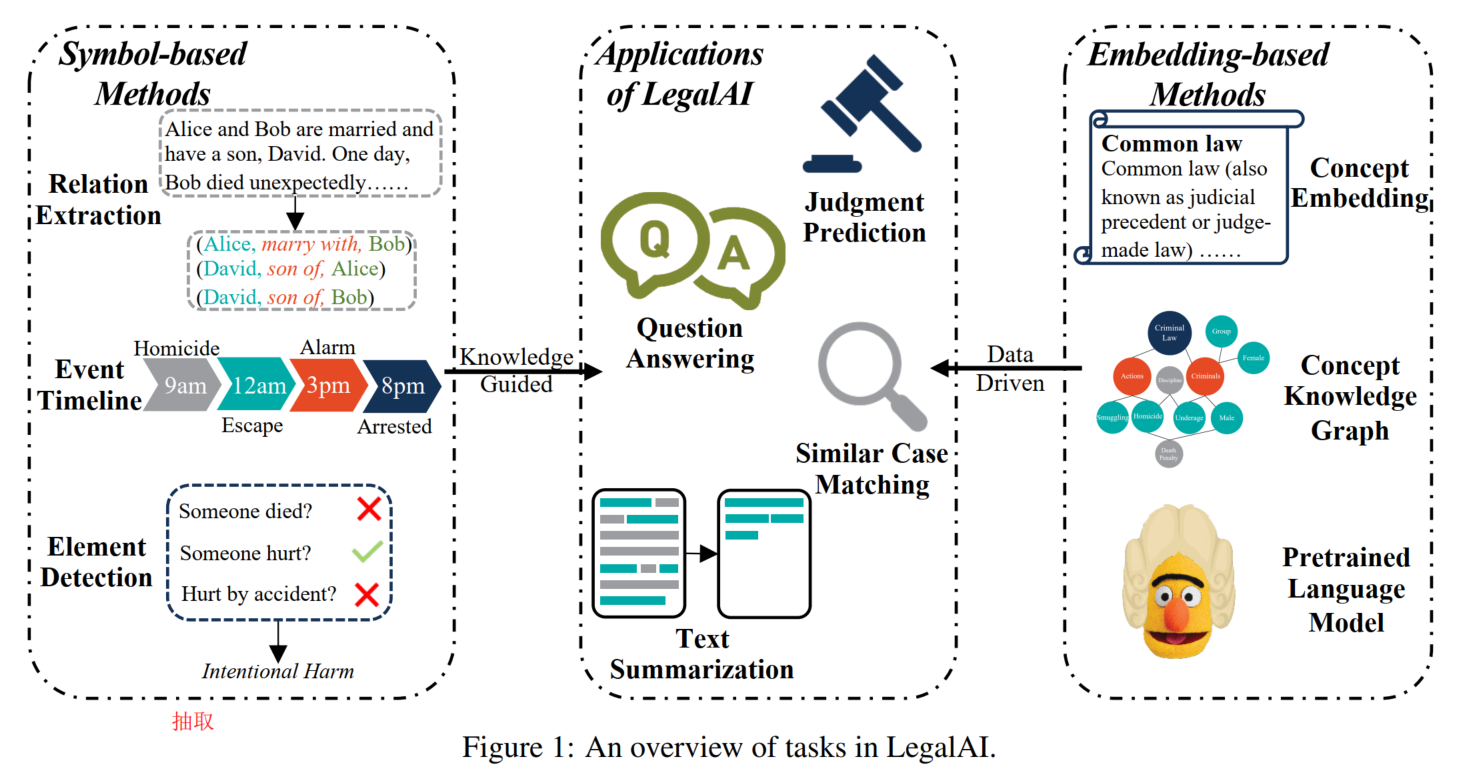
当前基于表征和基于符号的方法有三大共同挑战:
- 知识建模
- 法律推理:结合预定义的规则和人工智能技术。复杂的案例场景和法律规定
- 可解释性:为了公平性
2. 基于表征的方法
2.1 字、词、概念嵌入
很难直接从法律事实描述中学习专业术语,当前工作12主要关注法律专业领域应用现存嵌入方法(如word2vec)。
知识图谱方法有两大挑战:第一,构建法律领域知识图谱很复杂,很多场景下没有可用的知识图谱,所以要从0开始构建。而且不同法律概念可能在不同国家的法律体系下有不同的表示和意义,因此很难构建通用的法律知识图谱。有些工作尝试嵌入法律词典3。第二,通用法律知识图谱可能会和NLP中通用的形式不同,因为通用知识图谱关注实体和概念之间的关系,但legalAI更关注对法律概念的解释。
2.2 预训练语言模型
由于法律文本中存在特有的术语和知识,因此不宜直接使用通用预训练模型。4提出了中文民法和刑法文档上训练得到的预训练模型。
未来研究者可以考虑在PLMs中加入知识,这有助于法律概念之间的推理能力。
3. 基于符号的方法
利用法律领域符号和知识(事件和关系,能提供可解释性)解决legalAI任务。可以使用深度学习方法来提高表现效果
3.1 信息抽取
命名实体识别
关系抽取
事件抽取
在legalAI领域:
- 使用本体论的:Named entity recognition in the legal domain for ontology population Legal NERC with ontologies, Wikipedia and curriculum learning Ontology learning from Italian legal texts An ontological chinese legal consultation system
- 使用global consistency的
- 抽取法律文档中的关系和事件
- 使用手工设计的规则:Semantic mark-up of Italian legal texts through NLP-based techniques Legal aspects of text mining
- 使用CRF:A sequence approach to case outcome detection
- 使用SVM、CNN、GRU等joint model5:Litigation Analytics: Case Outcomes Extracted from US Federal Court Dockets
- 使用scale-free identifier network:Event Identification as a Decision Process with Non-linear Representation of Text
抽取出来的符号具有legal basis,可以为司法应用提供可解释性,因此我们不能只关注方法的表现效果。
应用举例:
- 关系抽取和遗产纠纷
- 事件时间线抽取和刑事案件判决预测
3.2 法律要素抽取
除了上述在通用NLP中也存在的符号外,legalAI还有其独有的符号:法律要素。如是否某人被杀或某物被盗,这些要素被称为犯罪构成要素constitutive elements of crime。
这些要素可以提供法律判决预测的中间监督信息和预测结果的可解释性。

图中提及的论文:6
中文数据集:CAIL2019-fe(多标签分类任务)
(图中BERT-MS是把BERT换成了4,体现了domain-specific预训练模型的优势)
4. legalAI应用
4.1 legal judgment prediction (LJP)
在民法法系中,使用案例事实描述信息和法条文本来预测结果。
早期方法在特定条件下用数学或统计学方法分析现存的法律案例,数学方法和法律规则的结合提供了可解释性:Predicting supreme court decisions mathematically: A quantitative analysis of the “right to counsel” cases. Quantitative analysis of judicial processes: Some practical and theoretical applications Applying correlation analysis to case prediction Mathematical models for legal prediction Predicting supreme court cases probabilistically: The search and seizure cases The Supreme Court’s many median justices
使用深度学习方法:
- 使用新模型来提升表现能力
- Charge-Based Prison Term Prediction with Deep Gating Network:用门机制提升刑期预测的效果
- Charge Prediction for Multi-defendant Cases with Multi-scale Attention:提出multi-scale attention解决多被告场景
- 探索如何利用法律知识或LJP任务特性
- Re7:读论文 FLA/MLAC/FactLaw Learning to Predict Charges for Criminal Cases with Legal Basis:用事实和法条之间的attention机制来帮助预测合适的罪名
- 7提出topological graph来利用LJP子任务之间的关系
- 8引入10个有识别力的legal attributes来帮助预测低频罪名。

(图中论文为7)
中文数据集:CAIL(本文中叫C-LJP,将刑期预测建模为回归任务)9
英文数据集:Neural Legal Judgment Prediction in English
在CAIL上的实验结果: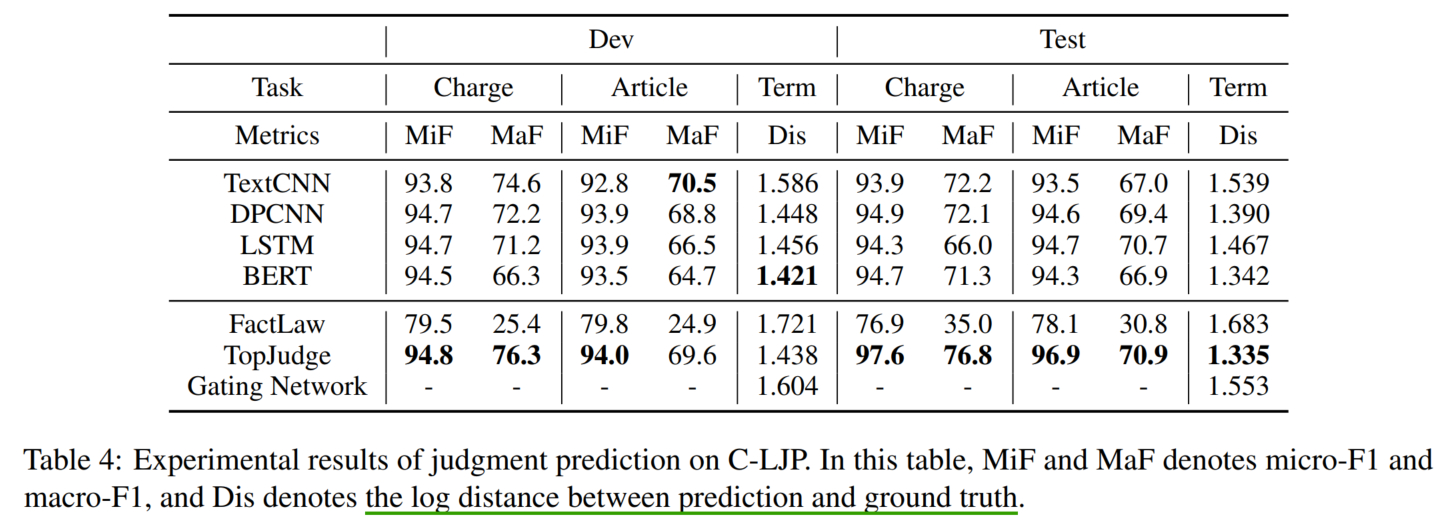
micro-F1和macro-F1之间的差距证明模型在低频标签上表现不好。8探索了LJP的few-shot learning,但是需要额外手工标注attribute信息,耗时太久,且难以泛化到其他数据集上。
BERT表现不好的主要原因在法律文本偏长,但BERT的最长输入长度仅为512。话说现在可以用lawformer这个长文本预训练模型了,不知道效果会不会有提升。
TopJudge模型可证明结合基于符号的方法有效果提升。
LJP任务的挑战:
- 文档理解和推理:长文本获取全局信息
- few-shot learning
- 可解释性
4.2 相似案例匹配Similar Case Matching (SCM)
在普通法系中很重要。
从事实、时间和要素级别以不同粒度建模案例关系,属于语义匹配任务10。
传统IR方法使用统计学方法,关注术语级别的相似性:TF-IDF和BM25
结合元信息捕获语义相似性11
使用机器学习方法,如SVD或因式分解
使用神经网络模型,如多层感知机、CNN、RNN
- 构建易用法律搜索引擎:Better Search Engines for Law Text retrieval in the legal world
- 利用更多信息
- 引用信息:Link analysis for representing and retrieving legal information Using citation analysis techniques for computer-assisted legal research in continental jurisdictions Analyzing the Extraction of Relevant Legal Judgments using Paragraph-level and Citation Information
- 法律概念:Concept and context in legal information retrieval On the Concept of Relevance in Legal Information Retrieval
- 使用深度学习方法:Building legal case retrieval systems with lexical matching and summarization using a pre-trained phrase scoring model提出基于文档和句子级别池化的CNN模型,在COLIEE上达到了SOTA结果。Extending Full Text Search for Legal Document Collections Using Word Embeddings和Legal document retrieval using document vector embeddings and deep learning使用更好的嵌入方法来做legalIR任务。
legalIR数据集:
COLIEE12
CaseLaw13
CM10
本文在CM上用如下baseline做实验:
- 术语匹配方法TF-IDF
- 有2个共享参数encoder的孪生网络:TextCNN、BiDAF、BERT和distance function
- 句子级别的语义匹配模型:ABCNN
文档级别:SMASH-RNN

10声称,法律专家认为数据集中的要素定义了案例相似性,仅考虑术语和语义相似性是不够的。
可研究的方向:
- Elemental-based representation
- Knowledge incorporation
4.3 legalQA (LQA)
有的问题关注法律概念的解释,有的关注特定案例的分析。可能由专业人员或非专业人员提出(尤其在描述领域术语上会有差异)。
数据集:
CJRC14:与SQUAD 2.0形式相同,包含span extraction、判断题和没有回答的问题。
COLIEE12:包含500道判断题。
美国法考:Passing a USA National Bar Exam: a First Corpus for Experimentation
中国法考:JEC-QA15,多选题,包含knowledge-driven questions (KD-Questions) and case-analysis questions (CA-Questions)两种问题

(图中论文:15)
- 基于规则的方法:Answering questions with an n-gram based passage retrieval engine Answering yes/no questions in legal bar exams Two-step cascaded textual entailment for legal bar exam question answering
- 利用其他信息
- 机器学习方法

LegalQA任务的挑战:
- Legal multi-hop reasoning
- Legal concepts understanding
5. 其他
- 各种任务都可以结合两种方法来解决。
- 对于没有数据集或数据集较小的任务,可以通过构建大且高质量的数据集,或使用few-shot/zero-shot方法来解决。
- 需要考虑legalAI中的道德问题。legalAI不可能代替专家工作,只能作为辅助。
6. 代码复现
先放个坑在这里,等我服务器好了再说。
Deep learning in law: early adaptation and legal word embeddings trained on large corpora︎
Gov2Vec: Learning Distributed Representations of Institutions and Their Legal Text︎
Open chinese language pretrained model zoo 事实上是这个GitHub项目:thunlp/OpenCLaP: Open Chinese Language Pre-trained Model Zoo︎︎
End-to-end relation extraction (端到端的信息抽取) 旨在抽取实体和实体之间的关系;
Joint Model 同时处理这两个任务,即对一句话同时抽取出实体和关系;而联合模型又分为2类:
结构化预测框架
共享参数的多任务学习
参考资料:[PAPER]Joint Model的挑战 - 知乎︎Iteratively Questioning and Answering for Interpretable Legal Judgment Prediction︎
Few-Shot Charge Prediction with Discriminative Legal Attributes︎︎
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction︎
CAIL2019-SCM: A Dataset of Similar Case Matching in Legal Domain︎︎︎
我也不知道什么是元信息 ︎
COLIEE-2018: Evaluation of the Competition on Legal Information Extraction and Entailment︎︎
Cjrc: A reliable human-annotated benchmark dataset for chinese judicial reading comprehension︎
边栏推荐
- UVM之sequence机制
- 你有了解过这些架构设计,架构知识体系吗?(架构书籍推荐)
- 让电商运营10倍提效的自动化工具,你get了吗?
- PyQt5 (a) PyQt5 installation and configuration, read from the folder and display images, simulation to generate the sketch image
- Overview of Edge Computing Open Source Projects
- RestTemlate源码分析及工具类设计
- 天地图给多边形加标注
- location对象,navigator对象,history对象学习
- PyCharm usage tutorial (more detailed, picture + text)
- 堪称神级的阿里巴巴“高并发”教程《基础+实战+源码+面试+架构》
猜你喜欢
location对象,navigator对象,history对象学习

It's time for bank data people who are driven crazy by reporting requirements to give up using Excel for reporting

ORBSLAM代码阅读

百战RHCE(第四十七战:运维工程师必会技-Ansible学习2-Ansible安装配置练习环境)
二分类和多分类
Postman download localization of installation and use

RPA助你玩转抖音,开启电商运营新引擎

Jenkins--基础--5.4--系统配置--全局工具配置
瑞吉外卖项目剩余功能补充
postman下载安装汉化及使用
随机推荐
pnpm: Introduction
线程池的使用及ThreadPoolExecutor源码分析
pnpm:简介
AutoJs学习-实现科赫雪花
Detailed explanation of calculation commands in shell (expr, (()), $[], let, bc )
postman使用方法
记某社区问答
spark:商品热门品类TOP10统计(案例)
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network
HCIA动态主机配置协议实验(dhcp)
LeetCode第三题(Longest Substring Without Repeating Characters)三部曲之一:解题思路
PyQt5安装配置(PyCharm) 亲测可用
在 QT Creator 上配置 opencv 环境的一些认识和注意点
谈谈对Volatile的理解
Fiddler(七) - Composer(组合器)克隆或者修改请求
Redis数据结构
tf中tensor的大小输出
主流监控系统工具选型及落地场景参考
spark:热门品类中每个品类活跃的SessionID统计TOP10(案例)
RPA助你玩转抖音,开启电商运营新引擎