当前位置:网站首页>字典特征提取,文本特征提取。
字典特征提取,文本特征提取。
2022-08-04 05:28:00 【我很好请走开谢谢】
1 定义
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
注:特征值化是为了计算机更好的去理解数据
- 特征提取分类:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取
2. 字典特征提取API
sklearn.feature_extraction
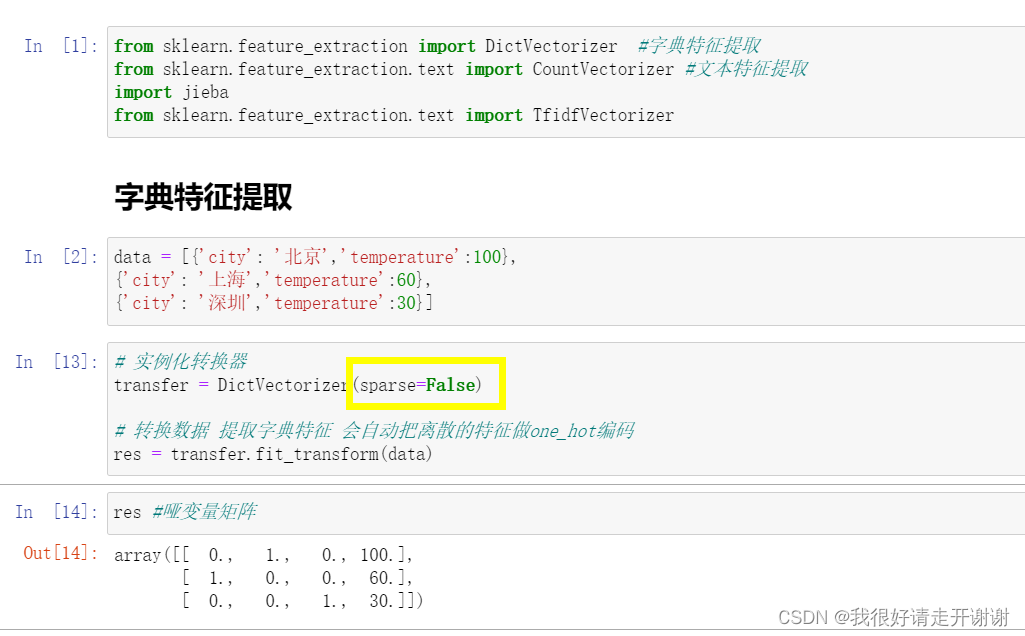
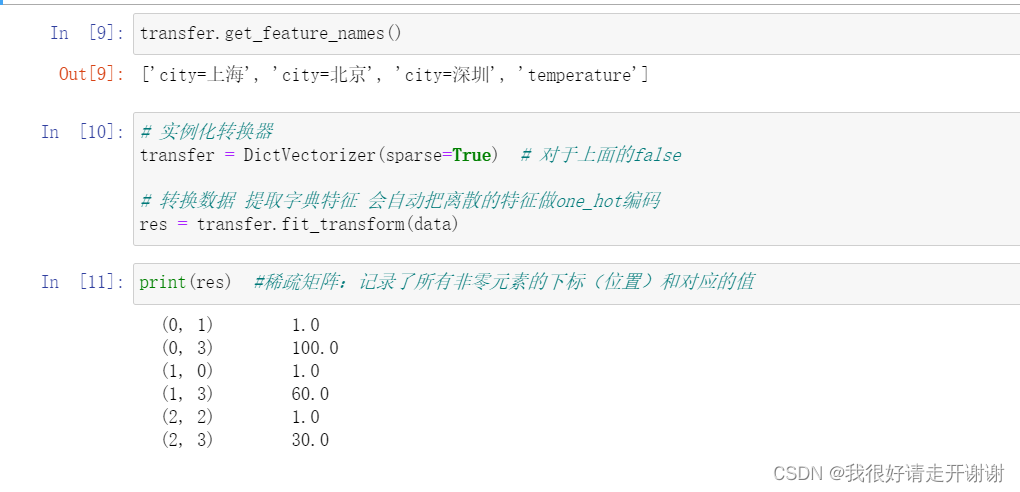
3. 字典特征提取案例:
1.实现效果:

2.实现代码
4. 文本特征提取
1. 方法

2. 英文案例
1. 实现效果
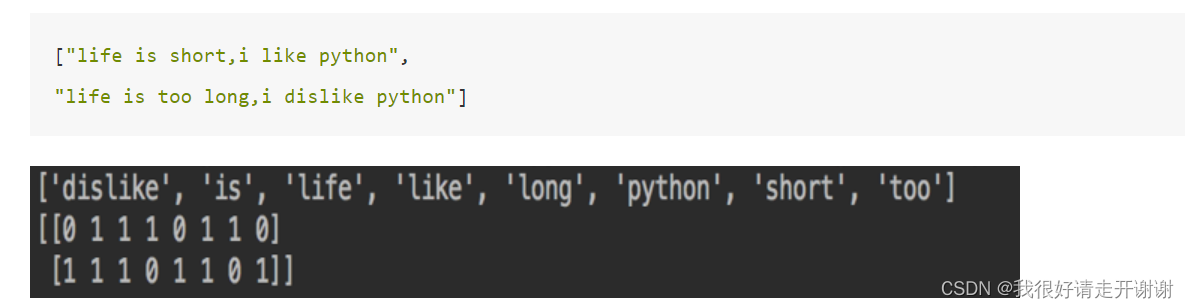
2.流程
from sklearn.feature_extraction.text import CountVectorizer
def text_count_demo():
""" 对文本进行特征抽取,countvetorizer :return: None """
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
# transfer = CountVectorizer(sparse=False) # 注意,没有sparse这个参数
transfer = CountVectorizer()
# 2、调用fit_transform
data = transfer.fit_transform(data)
print("文本特征抽取的结果:\n", data.toarray())
print("返回特征名字:\n", transfer.get_feature_names())
return None
运行结果:
文本特征抽取的结果:
[[0 1 1 2 0 1 1 0]
[1 1 1 0 1 1 0 1]]
返回特征名字:
[‘dislike’, ‘is’, ‘life’, ‘like’, ‘long’, ‘python’, ‘short’, ‘too’]
3. 中文案例
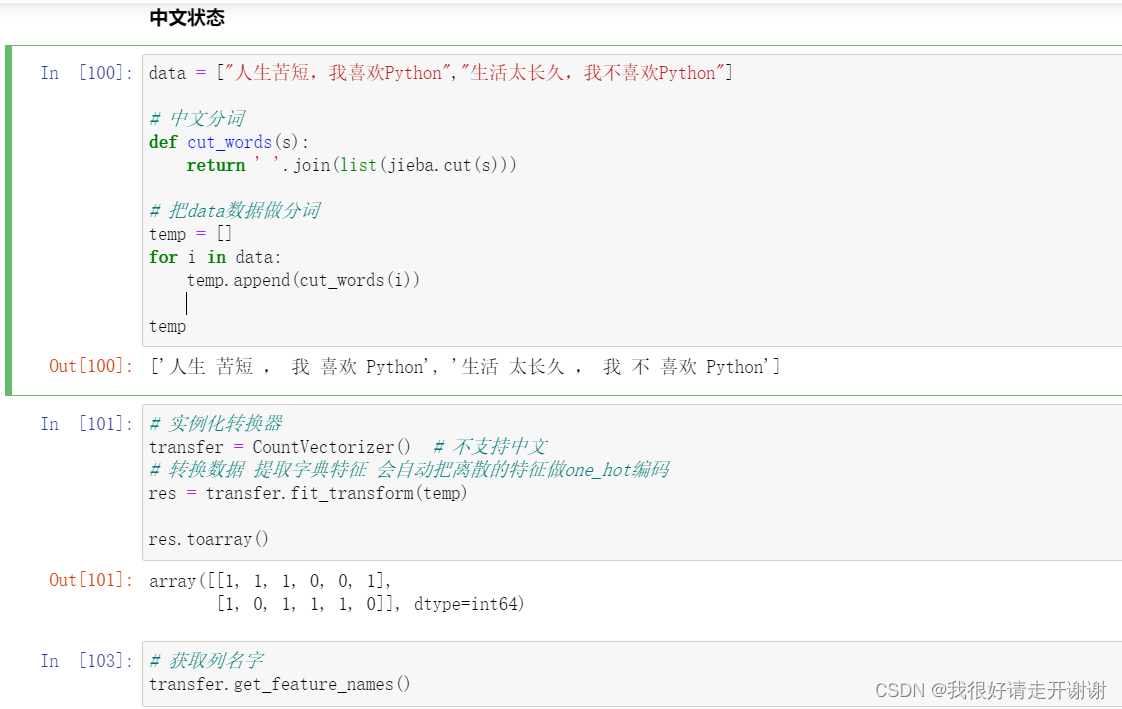

使用到的包
from sklearn.feature_extraction import DictVectorizer #字典特征提取
from sklearn.feature_extraction.text import CountVectorizer #文本特征提取
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
边栏推荐
猜你喜欢


随机推荐
编程Go:return、break、continue
Shell(3)条件控制语句
flink-sql大量使用案例
k3s-轻量级Kubernetes
Kubernetes基本入门-元数据资源(四)
使用express-jwt第三方包报错TypeError: expressJWT is not a function
Set集合与Map集合
MySql--存储引擎以及索引
lmxcms1.4
SQL练习 2022/7/2
原型对象及原型链的理解
PostgreSQL模式(Schema)
flink-sql所有数据类型
flink自定义轮询分区产生的问题
二月、三月校招面试复盘总结(一)
剑指 Offer 2022/7/11
自动化运维工具Ansible(7)roles
攻防世界MISC—MISCall
双重指针的使用
记录获取参赛选手信息过程