当前位置:网站首页>14. Bridge-Based Active Domain Adaptation for Aspect Term Extraction 阅读笔记
14. Bridge-Based Active Domain Adaptation for Aspect Term Extraction 阅读笔记
2022-07-26 14:25:00 【薰珞婷紫小亭子】
目录
3.3 Bridge-based Sequence Tagging
5.5 Analysis on Computational Cost
Author Information:
Institutions Information:
本文的核心思想:
为了缓解标注数据带来的巨大压力,有学者尝试使用跨领域传输知识的域适应方法解决该问题.但大多数属性词都是基于某些特定领域,它们之间并不能直接传递.本文提出一种新颖的主动域适应方法*(novel active domain adaptation),目标是通过积极补充可传输的知识来传递属性词.具体地,为所有单词构建可以帮助跨域传输相关信息的句法桥和语义桥.在自然语言中,语言表达丰富而灵活.相比之下,句法结构是有限的.句法桥旨在识别跨域单词可传递的句法角色,没有语义相关性的两个单词,也可在解析树中扮演类似的作用.鉴于此,可将某个单词所涉及的句法角色(包括词性标注和依存关系分析)拼接作为句法桥,补充跨领域识别属性词的信息.语义桥是源属性词和目标属性词之间的另一“桥梁”,其依据源领域和目标域,检索出目标域中与原属性词具有同类句法结构的句子,实现源属性词到目标属性词的信息传递.通过门控操作融合语义桥和句法桥的信息,将融合后的嵌入向量输入特征取器,最后,将其过一个Token级的softmax分类器,实现属性抽取任务.
Abstract
作为一个细粒度的任务,属性抽取标记的花费是十分高的。最近的一些尝试,通过使用跨领域转移公共知识的领域自适应来缓解这个问题。(Recent attempts alleviate this issue using domain adaptation that transfers common knowledge cross domains.)由于大多数属性词都是特定于领域的,因此它们不能直接传输。现有的方法通过将属性词与指示词 (pivot words )关联起来来解决这个问题(我们称之为被动域适应,因为属性词的转移依赖于到pivot的链接)。然而,所有这些方法都需要人工标注指示词或昂贵的计算资源去建立联系。
本文,我们提出一个新颖的主动域自适应方法(a novel activate domain adaptation method)。我们的目标是通过积极地补充可转移的知识来转移各个属性词。为此,我们通过将语法角色识别为pivot而不是作为pivot的链接来构建语法桥梁 (construct syntactic bridges)。我们还通过检索可转移的语义原型来构建语义桥梁 (semantic bridges)。大量的实验表明,我们的方法明显优于以往的方法。
1 Introduction
ATE是ABSA的一个子任务,其旨在识别句子中的属性词。由于token-level标注的高花费,缺乏大量已标注数据成为了主要的问题。
为了减缓数据不足问题(data deficiency issue),提出了无监督领域自适应方法。将知识从标记源领域 (labeled source domain)转移到未标记目标域 ( unlabeled target domain)。

Figure 1表示的是源域中的属性词在目标域中也出现的占比。从图1可以看出,在像R→L这样的远距离转移对中,只有不到10%的源属性词出现在目标数据中。即使在一对接近的L→D中,这个比例也不超过40%。换句话说,来自不同领域的数据之间存在着很大的差异,许多属性词必须在适当的参考文献的指导下进行转移。
本文贡献:
1) 我们为所有的单词构建了两种类型的桥。这两种桥可以帮助属性词的跨域传递。
实例:
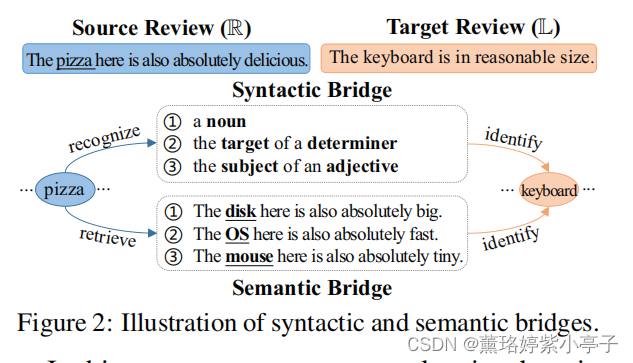
图2展示了如何基于源句属性词Pizza抽取目标句的属性词keyboard.
具体的:
句法桥 (syntactic bridge)旨在识别跨域的单词的可转移的句法角色。
虽然Pizza和keyboard几乎没有语义相关性,但它们通常在解析树 (parse tree)中扮演类似的角色。鉴于此,我们将某个词所涉及的句法角色(包括POS标签和依赖关系)作为其句法桥梁。以前的研究也利用了依赖性信息。然而,我们的方法与现有的方法的不同之处在于,我们不使用依赖关系来将pivot words 与属性词关联起来。相反,我们将语法角色本身视为pivot features,而不需要任何手动注释的pivot words。
语义桥(semantic bridegs)通过检索可转移的原型来更进一步。
直观地说,如果我们将Pizza与一些原型目标术语联系起来,如{disk、OS、mouse},训练和测试评论之间的领域差异可以大大减少。与以前的观点和基于上下文术语的方法相比,构建一个语义桥直接跨域连接属性词,并且只需要未标记的源数据和目标数据。
基于语法/语义桥,我们开发了一个端到端标记器来将评论与这些可转移的桥融合。我们对三个数据集进行了广泛的实验。结果表明,该方法以较低的计算成本获得了一种新的计算性能。
2 Related Work
2.1 Aspect Term Extraction
2.2 Domain Adaptation
许多领域自适应方法已经被提出来解决粗粒度的任务,如文本分类。粗粒度任务的基本思想是传输提示词,这不能很好地适合ATE,因为大多数属性词都是领域特定的非提示词。
3 Methodology
在本节中,我们首先介绍跨域ATE任务。然后,我们将说明如何构造语法桥和语义桥。最后,我们提出了基于桥接的序列标记。
3.1 Problem Statement
ATE是一个序列标记任务,即预测每一个词元的BIO标签。
本文,我们采用无监督的领域自适应方法解决ATE问题,即在目标域中没有带标记的训练数据。具体来说,给定源域中的一组标记数据 和一组目标域中的未标记数据
和一组目标域中的未标记数据 。我们的目标是预测测试数据集
。我们的目标是预测测试数据集 中的标签
中的标签 。
。
3.2 Bridge Construction
给定一个来自两个域的评论句子x,我们用一个查找表 (lookup table) 来映射它,并生成单词嵌入
来映射它,并生成单词嵌入 ,其中|V|是词汇量大小,
,其中|V|是词汇量大小, 是嵌入维度。对于跨域ATE,我们构建了用于评审的桥梁,以帮助跨两个域直接转移属性词。
是嵌入维度。对于跨域ATE,我们构建了用于评审的桥梁,以帮助跨两个域直接转移属性词。
Syntactic Bridge
在自然语言中,语言的表达方式是丰富而灵活的。相比之下,句法结构是有限的,并且是跨域通用的。基于此,我们提出基于源词和目标词的句法角色(POS标签和依赖关系)而不是词汇项,在源词之间建立连接。

P: 参考图3左侧的POS集合,如果存在,则对应位置标为P。
D:参考图3右侧的Dependency集合,如果存在,不论方向,均在对应位置标记为D。
如图3, 对每一个单词 ,我们使用one-hot 向量
,我们使用one-hot 向量 和multi-hot向量
和multi-hot向量 来表示它的POS 标签和依赖关系。其中,
来表示它的POS 标签和依赖关系。其中, 和
和 分别表示标签和关系类型的数量。对
分别表示标签和关系类型的数量。对 ,我们合并所有与有关的关系,而不管方向。
,我们合并所有与有关的关系,而不管方向。
为了扩大学习能力,我们将 和投影到具有可学习的权重矩阵的相同维数上,并将它们连接起来形成语法桥
和投影到具有可学习的权重矩阵的相同维数上,并将它们连接起来形成语法桥 :
:

Semantic Bridge
与以往通过情感词或上下文构建属性词之间联系的方式不同,我们旨在建立源域和目标域属性词之间的直接联系。
实例:
例如,为了将知识从 中的Pizza转移到
中的Pizza转移到 中的keyboard,我们打算在
中的keyboard,我们打算在 中引入一些补充的属性词,如{disk、OS、mouse},并直接提高其与keyboard的语义相关性。我们称这些补充术语为原型 (prototypes),并将检索它们来构建语义桥。
中引入一些补充的属性词,如{disk、OS、mouse},并直接提高其与keyboard的语义相关性。我们称这些补充术语为原型 (prototypes),并将检索它们来构建语义桥。
诸如BERT这样的预训练语言模型,可以找到一组语义上相似的术语,比如为pizza找到 { hamburger, salad},它们也可以作为原型。由于不同领域之间的属性词,差异比较大,因此,这些原型未必能够给适应领域自适应任务。为了解决这个问题,我们设计了一个语法增强的相似性度量来检索可转移的语义原型 (To address this problem, we design a syntax-enhanced similarity metric to retrieve transferable semantic prototypes. )。
在开始之前,我们通过词频,过滤中 的单词。仅保留出现次数大于r的单词。我们将这些未标注的单词作为原型候选集 (candidate prototypes)并且构造一个原型库  .
.

对于一个query word (来自),我们想找到一个在目标域中扮演类似句法角色的原型术语 。具体来说,我们首先总结了v的全局用法,通过合并它在中的POS和依赖嵌入,在所有出现v的评论中:
。具体来说,我们首先总结了v的全局用法,通过合并它在中的POS和依赖嵌入,在所有出现v的评论中:

对和,采取同样的方式。这样,具有相同原型的源词和目标词就可以直接相互关联。
3.3 Bridge-based Sequence Tagging
基于上述构建的句法桥和语义桥,我们提出一种端到端的序列标注方法。用于ATE任务。
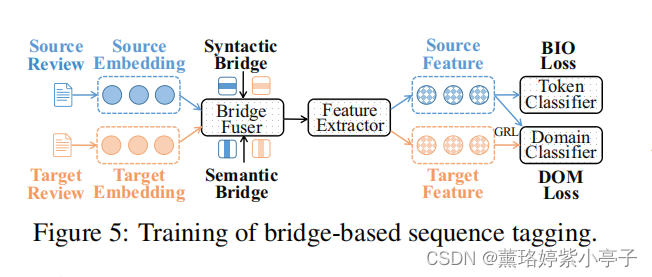
Bridge Fuser
本文构建的桥,有两个属性:
1)桥梁是域不变的,应该被保留下来。
2)桥梁可以帮助从 中提取域不变信息。
中提取域不变信息。
因此,我们提出使用可传输桥  和
和 增强单词的词嵌入 。我们使用一个门控操作来融合桥梁。以句法桥为例,我们首先计算一个有维度的门
增强单词的词嵌入 。我们使用一个门控操作来融合桥梁。以句法桥为例,我们首先计算一个有维度的门

Feature Extractor
因此,我们使用一个包含L个堆叠卷积层的ReLU激活的CNN编码器来提取高级特征 .
.
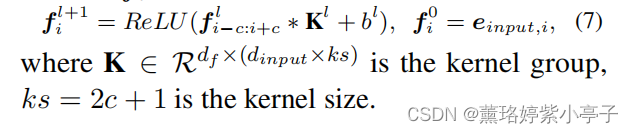
Token Classifier
为了识别属性词和情感词,我们将最后一层的特征表示 输入分类器:
输入分类器:

Domain Classifier
除了BIO标记外,我们还通过域对抗训练进一步增强了基于桥的特征的域不变性。具体来说,我们首先将聚合为一个全局表示法 :
:

Training Procedure
对源领域数据集,目标是最小化属性抽取的loss:

另一方面,利用和中的样本对域分类器进行训练,并最小化loss:

4 Experiment
4.1 Experimental Setup
数据集来源:
R和L来源于SemEval 2014和2015. D来自于Hu and Liu(2004)

4.2 Compared Methods
Type-I : 表示基于情感词的方法。
Type-II : 表示基于上下文的方法。
Type-III: 本文的领域自适应方法,BaseTagger是没有桥的标记器,而SynBridge和SemBridge分别使用语法桥和语义桥。
4.3 Main Results

结论:
1)本文的方法取得了最优的F1值。
2)本文的BaseTagger也比很多的基线模型高。造成这个原因可能是因为我们设计了CNN 特征提取器和领域自适应对抗训练(Domain Adversarial Training)。CNN关注的是N-gram特性,而不是一个单词,并减少了non-pivot aspect terms的副作用。DAT应用于句子级特征,这样它们就不会被同时标记为0和1的普通n-grams所误导。
3) SynBridge 和SemBridge进一步提高了BaseTagger的性能,分别是1.80%和2.68%。此外,SemBridge要比 SynBridge更优.
原因:
(1)语义桥来自于具有先验嵌入知识并包含语法信息的原型词,而语法桥仅仅是从头开始训练的。
(2)检索到的前k项使SemBridge的补充信息比SynBridge更加多样化和丰富。
5 Analysis
5.2 Ablation study

结论:
结果1∼2符合我们之前关于BaseTagger的讨论,即CNN和领域对抗性训练都有助于整体良好的表现。结果3∼6显示了POS和依赖嵌入的有效性。具体来说,在5∼6中,我们用经常使用的Tree-LSTM和GCN取代了我们提出的依赖结构,以对依赖树进行建模,并发现性能显著下降。结果7∼9显示了所有三种相似性在SemBridge中检索原型的重要性。
5.5 Analysis on Computational Cost
在实践中,对于任何传输对,语法桥和语义桥的一次性构建都可以在30秒内完成。因此,我们主要关注SynBridge/SemBridge.的端到端训练成本。我们在传输对R→L上运行了五种性能最好的方法,并在表7中给出了每种方法的每个epoch的可训练参数数和运行时间。我们可以得出结论,我们提出的方法保持了一个相当低的计算成本。

6 Conclusion
本文提出了一种新的主动域自适应方法。与以往的研究通过将属性词与pivot关联起来来进行被动域适应的研究不同,我们通过构建语法和语义桥梁来积极增强术语的可转移性。然后,我们设计了一个轻量级的基于桥的序列标记器。在6对传输对上的实验表明,该方法以较低的计算成本获得了一种新的最先进的性能。
边栏推荐
- .net6 encounter with the League of heroes - create a game assistant according to the official LCU API
- Leetcode question type priority queue (TOPK question)
- 【干货】MySQL索引背后的数据结构及算法原理
- 基于SPO语义三元组的疾病知识发现
- 网络图片转本地导致内核退出
- Mysql-03 database operation
- 基于专利多属性融合的技术主题划分方法研究
- Sequence traversal of binary tree (implemented in C language)
- 注解和反射
- Flink SQL(三) 连接到外部系统System和JDBC
猜你喜欢

Install dexdump on win10 and remove the shell

1-to-1 live broadcast source code - 1-to-1 voice chat source code

C language_ Structure pointer variable introduction

全校软硬件基础设施一站式监控 ,苏州大学以时序数据库替换 PostgreSQL
First knowledge of opencv4.x --- image perspective transformation

Plato farm is expected to further expand its ecosystem through elephant swap
保证接口数据安全的10种方案

Leetcode215 the kth largest element (derivation of quick sort partition function)

手持振弦采集仪VH03各种接口使用说明
![[paper reading] raw+:a two view graph propagation method with word coupling for readability assessment](/img/14/1a02d564c59724d04fce340b6b227d.png)
[paper reading] raw+:a two view graph propagation method with word coupling for readability assessment
随机推荐
The development of smart home industry pays close attention to edge computing and applet container technology
我的创作纪念日-从心出发
填问卷,领奖品 | 诚邀您填写 Google Play Academy 活动调研问卷
『SignalR』.NET使用 SignalR 进行实时通信初体验
OLAP (business) - transaction analysis (query)
Fill in the questionnaire and receive the prize | we sincerely invite you to fill in the Google play academy activity survey questionnaire
Redis data operation
什么是Restful风格以及它的四种具体实现形式
GOM登录器配置免费版生成图文教程
MLX90640 红外热成像仪测温传感器模块开发笔记(六)
My creation Anniversary - from the heart
Seata deployment and microservice integration
PHP uses sqlserver
【整数规划】
UDP multithreaded online chat
c# 用移位 >> 和运算与 &判断两个 二进制数 是否发生过改变
Iscc2021 lock problem solution
Use of URL download resources
Multi task text classification model based on tag embedded attention mechanism
[Yugong series] July 2022 go teaching course 017 - if of branch structure