当前位置:网站首页>Apprentissage comparatif non supervisé des caractéristiques visuelles par les assignations de groupes de contrôle
Apprentissage comparatif non supervisé des caractéristiques visuelles par les assignations de groupes de contrôle
2022-07-07 11:15:00 【InfoQ】

- L'étude comparative des dieux au crépuscule
- “La course aux armements”L'étude comparative de la période est bonne.
- ToutimagenetFaire un dictionnaire,En extraire unmini batchComme échantillon positif. Ensuite, nous choisissons au hasard 4096 Barre comme échantillon négatif .
- Extraire un mini batch Pour l'agrandir , En utilisant un réseau jumeau , Mettre l'image originale sur un réseau , Placez le graphique amélioré dans un autre réseau , Les deux s'entraînent en même temps , Utilisez un NCE lossOuinfoNCE loss. Une image et son élargissement comme échantillon positif , Les images restantes et leur agrandissement en tant qu'échantillons négatifs .
- Extraire un mini batch Il a été agrandi deux fois , En utilisant un réseau jumeau , Mettre un ensemble d'améliorations d'image sur un réseau , Mettre un autre ensemble d'améliorations d'image sur un autre réseau , Les deux s'entraînent en même temps , Utilisez un NCE lossOuinfoNCE loss.
- Il peut être extrait à plusieurs reprises dans les mêmes données . Bien que votre ensemble de données ait beaucoup d'images , Mais vous pouvez en tirer la même image .Dans des cas extrêmes, Si vous prenez un ensemble d'images comme échantillon positif , Ensuite, vous prenez le même ensemble d'images répétées comme échantillon négatif . Ça pourrait avoir un impact sur l'entraînement. .
- Ou peut ne pas être représentatif de l'ensemble des données . Par exemple, il y a beaucoup d'animaux dans ces données , Mais tu fumes des chiens , De cette façon, les données ne sont pas représentatives .
- Bien sûr, plus la sélection est complète, mieux c'est. , Mais si vous choisissez trop d'échantillons négatifs, vous risquez de gaspiller des ressources informatiques .
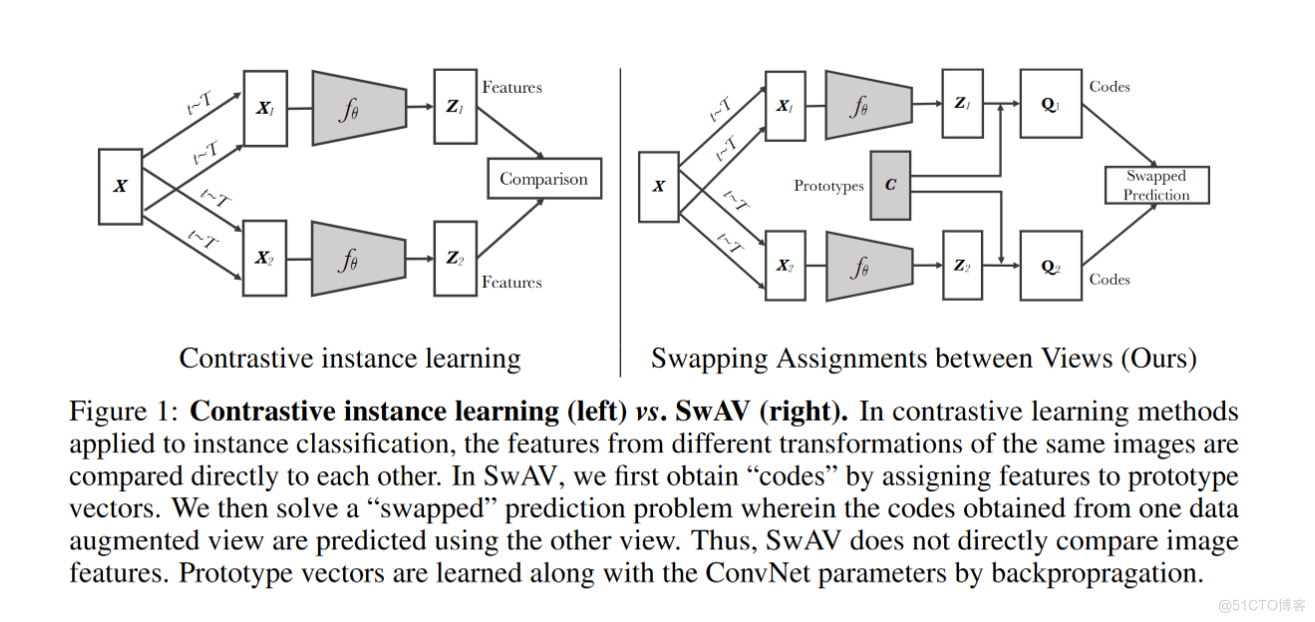
- Commençons par les questions répétitives : Parce que vous utilisez des centres de regroupement pour comparer . Bien que différents centres de regroupement , Il n'y a donc aucune chance qu'il se répète .
- Encore une fois, il n'y a pas de représentation : Le regroupement consiste à regrouper de nombreuses images dans différentes catégories . Comparaison avec le Centre de chaque catégorie , Est absolument représentatif .
- Encore une fois, il y a eu trop d'échantillons négatifs dans le passé, ce qui a entraîné un gaspillage de ressources . Si vous voulez faire une analogie avec beaucoup d'échantillons négatifs , Il faudrait des milliers d'échantillons négatifs , Et même ainsi, ce n'est qu'une approximation , Et si on le compare au centre de regroupement , Vous pouvez utiliser des centaines ou un maximum de 3,000Centres de regroupement, Ça suffit pour dire . Réduction significative de la consommation de ressources informatiques .
边栏推荐
- 从色情直播到直播电商
- 毕业季|与青春作伴,一起向未来!
- Unity script generates configurable files and loads
- JS array delete the specified element
- Add a self incrementing sequence number to the antd table component
- 对比学习之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
- Seata 1.3.0 four modes to solve distributed transactions (at, TCC, Saga, XA)
- 普通测试年薪15w,测试开发年薪30w+,二者差距在哪?
- Wallhaven wallpaper desktop version
- 2021 summary and 2022 outlook
猜你喜欢
Input type= "password" how to solve the problem of password automatically brought in
![[untitled]](/img/c7/b6abe0e13e669278aea0113ca694e0.jpg)
[untitled]
Activity生命周期
数据库同步工具 DBSync 新增对MongoDB、ES的支持
基于华为云IOT设计智能称重系统(STM32)
![[untitled]](/img/f9/18b85ad17d4c560f2b9d95a53ee72a.jpg)
[untitled]
The post-90s resigned and started a business, saying they would kill cloud database
Static semantic check of clang tidy in cicd

Web端自动化测试失败的原因
electron添加SQLite数据库
随机推荐
通过 Play Integrity API 的 nonce 字段提高应用安全性
Basic knowledge of process (orphan, zombie process)
[untitled]
基于DE2 115开发板驱动HC_SR04超声波测距模块【附源码】
Bookmarking - common website navigation for programmers
Activity生命周期
Deeply understand the characteristics of database transaction isolation
Realize ray detection, drag the mouse to move the object and use the pulley to scale the object
PostgreSQL中的表复制
Verilog 实现数码管显视驱动【附源码】
electron添加SQLite数据库
Add a self incrementing sequence number to the antd table component
mif 文件格式记录
[untitled]
软件设计之——“高内聚低耦合”
vim 的各种用法,很实用哦,都是本人是在工作中学习和总结的
Interprocess communication (IPC)
The sixth training assignment
shardingsphere分库分表示例(逻辑表,真实表,绑定表,广播表,单表)
基于Retrofit框架的金山API翻译功能案例