当前位置:网站首页>with torch.no_grad():的使用原因
with torch.no_grad():的使用原因
2022-06-28 20:04:00 【seven_不是赛文】
for e in range(100): #epoch==e
train_main_loss, train_aux_loss = 0, 0
# 训练集
for batch_x, batch_y, batch_y_aux in tqdm_notebook(train_loader):# tqdm_notebook显示进展效果
'''
先将梯度值归零,:optimizer.zero_grad();
然后反向传播计算得到每个参数的梯度值:loss.backward();
最后通过梯度下降执行一步参数更新:optimizer.step();
'''
# 原因是不清零梯度会累加,梯度会在前一次的基础上无限下降,而不是对其进行覆盖。
opt.zero_grad() # 为下次训练清空梯度
batch_x = batch_x.cuda() # A.cuda()就说利用GPU运算
batch_y = batch_y.cuda()
batch_y_aux = batch_y_aux.cuda()
main_output, aux_output = model(batch_x) # X_train_t ==》batch_x
# 放入model:SelfBoostedNet 进行训练,得到两个输出。下面计算他们的loss
main_loss = loss(main_output, batch_y)
aux_loss = loss(aux_output, batch_y_aux)
total_loss = main_loss + alpha * aux_loss
total_loss.backward() # 通过反向传播过程来实现可训练参数的更新
opt.step() # 更新权重参数
train_main_loss += main_loss.item() * batch_x.shape[0]
train_aux_loss += aux_loss.item() * batch_x.shape[0]
'''
不使用with torch.no_grad():此时有grad_fn=属性,表示,计算的结果在一计算图当中,可以进行梯度反传等操作。
只是想要网络结果的话就不需要后向传播 ,如果你想通过网络输出的结果去进一步优化网络的话 就需要后向传播了。
'''
# 所以我们的我们不进行后向传播
with torch.no_grad():
val_main_loss, val_aux_loss = 0, 0
# 验证集
for batch_x, batch_y, batch_y_aux in val_loader:
batch_x = batch_x.cuda()
batch_y = batch_y.cuda()
batch_y_aux = batch_y_aux.cuda()
main_output, aux_output = model(batch_x)
main_loss = loss(main_output, batch_y)
aux_loss = loss(aux_output, batch_y_aux)
val_main_loss += main_loss.item() * batch_x.shape[0]
val_aux_loss += aux_loss.item() * batch_x.shape[0]
train_main_loss /= X_train_t.shape[0]
train_aux_loss /= X_train_t.shape[0]
val_main_loss /= X_val_t.shape[0]
val_aux_loss /= X_val_t.shape[0]
'''
他在训练验证集的时候,只是想看一下训练的效果,
并不是想通过验证集来更新网络时,所以使用with torch.no_grad()。
最终,torch.save就保存的训练集的训练模型。
'''
if val_loss > val_main_loss:
val_loss = val_main_loss
torch.save(model.state_dict(), 'self_boost_air_quality.pt')
print("Iter: ", e,
"train main loss: ", train_main_loss,
"train aux loss: ", train_aux_loss,
"val main loss: ", val_main_loss,
"val aux loss: ", val_aux_loss)
model.load_state_dict(torch.load('self_boost_air_quality.pt'))

他在训练验证集的时候,只是想看一下训练的效果,并不是想通过验证集来更新网络时,所以使用with torch.no_grad()。
最终,torch.save就保存的训练集的训练模型。
如果我们是with torch.no_grad() 就说明我们的数据不需要计算梯度也不进行后向传播
在这里插入代码片
边栏推荐
猜你喜欢

Software supply chain security risk guide for enterprise digitalization and it executives
![[324. swing sequence II]](/img/4f/dbbc28c7c13ff94bd0956f2ccf9603.png)
[324. swing sequence II]

2022茶艺师(中级)考试模拟100题及模拟考试

Analysis of all knowledge points of TCP protocol in network planning

《数据安全法》出台一周年,看哪四大变化来袭?

【毕业季·进击的技术er】努力只能及格,拼命才能优秀!

Lecture 30 linear algebra Lecture 4 linear equations
![return new int[]{i + 1, mid + 1}; return {i + 1, mid + 1};](/img/6a/45a4494276deba72ef9833818229f5.png)
return new int[]{i + 1, mid + 1}; return {i + 1, mid + 1};

2022 P cylinder filling test exercises and online simulation test
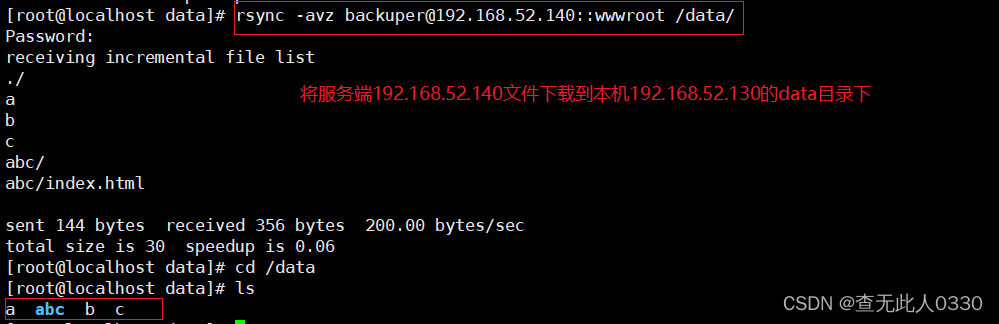
Rsync remote synchronization
随机推荐
odoo15 Module operations are not possible at this time, please try again later or contact your syste
关键字long
How to obtain the coordinates of the aircraft passing through both ends of the radar
JVM memory structure
100人成绩的平均
odoo15 Module operations are not possible at this time, please try again later or contact your syste
《数据安全法》出台一周年,看哪四大变化来袭?
jsp中获取session中的值
internship:术语了解及着手写接口
Huawei cloud onemeeting tells you that the whole scene meeting is held like this!
2342
Lecture 30 linear algebra Lecture 4 linear equations
Class loading mechanism and object creation
Concours de segmentation des images gastro - intestinales de kaggle Baseline
各种类型长
Jenkins pipeline's handling of job parameters
ArrayList of collection
R language GLM generalized linear model: logistic regression, Poisson regression fitting mouse clinical trial data (dose and response) examples and self-test questions
Troubleshooting of pyinstaller failed to pack pikepdf
核芯物联蓝牙aoa定位系统服务器配置估算