当前位置:网站首页>Hands on deep learning 18 -- model selection + over fitting and under fitting and code implementation
Hands on deep learning 18 -- model selection + over fitting and under fitting and code implementation
2022-06-12 08:14:00 【Orange acridine 21】
One 、 Model selection
1、 How to select a super parameter
example : Predict who will repay the loan
The bank hired you to investigate who would repay the loan , You got it. 100 Information about applicants , Five of them defaulted within three years ( Bad loan ), You find all 5 Everyone wore blue shirts during the interview , Your model also finds this strong signal , What's the problem with this ?
2、 Training error and generalization error
- Training error : The error of the model in the training data .
- The generalization error : Model error on new data .
Example : Predict future test scores based on model test scores .
Did well in the past exam ( Training error ) It doesn't mean you will do well in the exam in the future ( The generalization error )
3、 Validation data sets and test data sets
- Validation data set : A data set used to evaluate the quality of the model .
for example : take out 50% Training data ; Don't mix with training data sets .
- Test data set : A data set used only once
for example : Future exams ; The actual transaction price of the house I bid ; Use in Kaggle Data sets in private leaderboards .
4、k- Crossover verification
Use when there is not enough data ( This is the norm ), The algorithm is to divide the training data set into k block ,for i=1,.....,K; Use the i Block as validation data set , The rest are used as training data sets , The report k The average of the errors of the verification sets .( Commonly used k=5 or 10)
5、 summary
Training data set : Training model parameters .
Validation data set : Select model superparameters .
Usually used on non large data sets k- Crossover verification
Two 、 Over fitting and under fitting
1、 Model capacity
Model capacity : Is the ability to fit various functions . Low volume models are difficult to fit training data ; The high-capacity model can remember all the training data .
Impact of model capacity :
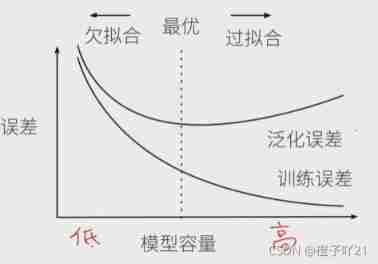
Estimate model capacity
It is difficult to compare different kinds of algorithms , For example, tree model and neural model ;
Given a model type , There will be two main factors : The number of parameters and the selection range of parameter values .
2、VC dimension
VC dimension : A core idea of statistical learning theory ; For a classification model ,VC Equal to the size of a maximum data set , No matter how the label is given , There is a model to classify it perfectly .
Linear classifier's VC dimension :2 Perceptron of dimension input ,VC dimension =3, Be able to classify any three points , But not four .
Support N Dimension input of the perceptron VC Weishi N+1; Some multi-layer perceptron VC dimension O(N* log2 N)
VC Use of dimension :
Provide a theoretical basis for why a model is good , It can measure the interval between training error and generalization error , But it is rarely used in deep learning , The measurement is not very accurate , Calculate the depth of learning model VC It's difficult .
3、 Data complexity
Several important factors :
- Number of samples ;
- Number of elements per sample ;
- Time 、 Spatial structure ;
- Diversity of data ;
4、 summary
- The model capacity needs to match the data complexity , Otherwise, it may lead to under fitting and over fitting ;
- Statistical machine learning provides mathematical tools to measure model complexity ;
- In practice, observation training error and verification error are generally considered ;
3、 ... and 、 Code implementation
import matplotlib.pyplot as plt
import torch
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
"""
1、 Generate data set
"""
n_train, n_test, true_w, true_b = 100, 100, [1.2, -3.4, 5.6], 5
# The number of samples in both the training data set and the test data set is set to 100,true_w Weight. ,true_b It's a deviation ;
features = torch.randn((n_train + n_test, 1))
poly_features = torch.cat((features, torch.pow(features, 2),torch.pow(features, 3)), 1)
labels = (true_w[0] * poly_features[:, 0] + true_w[1] * poly_features[:, 1]+ true_w[2] * poly_features[:, 2] + true_b)
labels += torch.tensor(np.random.normal(0, 0.01,size=labels.size()), dtype=torch.float)
print(features[:2], poly_features[:2], labels[:2])
# The first two samples of the output dataset
"""
2、 Definition 、 Training and testing models
"""
# Define mapping functions semilogy, among y Axis make ⽤ Logarithmic scale .
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None,y2_vals=None,legend=None, figsize=(3.5, 2.5)):
d2l.set_figsize(figsize)
d2l.plt.xlabel(x_label)
d2l.plt.ylabel(y_label)
d2l.plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
d2l.plt.semilogy(x2_vals, y2_vals, linestyle=':')
d2l.plt.legend(legend)
# And linear regression ⼀ sample , Polynomial function fitting also makes ⽤ flat ⽅ Loss function .
num_epochs,loss=100,torch.nn.MSELoss()
def fit_and_plot(train_features,test_features,train_labels,test_labels):
net =torch.nn.Linear(train_features.shape[-1],1)
batch_size=min(10,train_labels.shape[0])
dataset=torch.utils.data.TensorDataset(train_features,train_labels)
train_iter=torch.utils.data.DataLoader(dataset,batch_size,shuffle=True)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y.view(-1, 1))
optimizer.zero_grad()
l.backward()
optimizer.step()
train_labels = train_labels.view(-1, 1)
test_labels = test_labels.view(-1, 1)
train_ls.append(loss(net(train_features),train_labels).item())
test_ls.append(loss(net(test_features),test_labels).item())
print('final epoch: train loss', train_ls[-1], 'test loss',test_ls[-1])
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss', range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('weight:', net.weight.data,'\nbias:', net.bias.data)
"""Output results of the first two samples : For the output
# Third order polynomial function fitting ( normal )
fit_and_plot(poly_features[:n_train, :], poly_features[n_train:, :],labels[:n_train], labels[n_train:])
plt.show()

# Linear function fitting (⽋ fitting )
fit_and_plot(features[:n_train, :], features[n_train:, :],labels[:n_train],labels[n_train:])
plt.show() 

# Training samples do not ⾜( Over fitting )
fit_and_plot(poly_features[0:2, :], poly_features[n_train:, :],labels[0:2],labels[n_train:])
plt.show()

summary :
- because ⽆ Method to estimate generalization error from training error ,⼀ Reducing training error blindly does not mean generalization error ⼀ It's bound to decrease . machine Learning models should focus on reducing generalization errors .
- You can make ⽤ Validate data set to enter ⾏ Model selection .
- ⽋ Fitting refers to the model ⽆ Method to get a lower training error , Over fitting means that the training error of the model is far ⼩ Its error on the test data set .
- Models with appropriate complexity should be selected and avoid making ⽤ Too few training samples .
边栏推荐
- Servlet advanced
- Transformation from AC5 to AC6 (1) - remedy and preparation
- In depth learning, the parameter quantity (param) in the network is calculated. The appendix contains links to floating point computations (flops).
- visual studio2019的asp.net项目添加日志功能
- MES帮助企业智能化改造,提高企业生产透明度
- A brief summary of C language printf output integer formatter
- Vision Transformer | Arxiv 2205 - LiTv2: Fast Vision Transformers with HiLo Attention
- Uni app screenshot with canvas and share friends
- js中的数组
- Leetcode notes: Weekly contest 280
猜你喜欢

How to write simple music program with MATLAB

Record the treading pit of grain Mall (I)

Derivation of Poisson distribution

(P40-P41)move资源的转移、forward完美转发

js中的正则表达式

Introduction to coco dataset

Model compression | tip 2022 - Distillation position adaptation: spot adaptive knowledge distillation

工厂的生产效益,MES系统如何提供?

ctfshow web 1-2

FPGA implementation of right and left flipping of 720p image
随机推荐
MYSQL中的调用存储过程,变量的定义,
Hands on learning and deep learning -- Realization of linear regression from scratch
vm虚拟机中使用NAT模式特别说明
ctfshow web 1-2
DUF:Deep Video Super-Resolution Network Using Dynamic Upsampling Filters ...阅读笔记
Introduction to coco dataset
You get download the installation and use of artifact
(P40-P41)move资源的转移、forward完美转发
Pytorch profiler with tensorboard.
MYSQL中的触发器
Principes et exemples de tâches OpenMP
How to write simple music program with MATLAB
2.1 链表——移除链表元素(Leetcode 203)
802.11 protocol: wireless LAN protocol
Installation series of ROS system (II): ROS rosdep init/update error reporting solution
FPGA generates 720p video clock
Discrete chapter I
Final review of Discrete Mathematics (predicate logic, set, relation, function, graph, Euler graph and Hamiltonian graph)
Cookies and sessions
(P21-P24)统一的数据初始化方式:列表初始化、使用初始化列表初始化非聚合类型的对象、initializer_lisy模板类的使用