当前位置:网站首页>Model compression | tip 2022 - Distillation position adaptation: spot adaptive knowledge distillation
Model compression | tip 2022 - Distillation position adaptation: spot adaptive knowledge distillation
2022-06-12 08:11:00 【Promising youth】
TIP 2022 - Distillation position adaptation :Spot-adaptive Knowledge Distillation
This article has authorized the polar market platform , It was launched on the official account of Jishi platform . No second reprint is allowed without permission .

- Original sparrow document :https://www.yuque.com/lart/gw5mta/vhbggb
- The paper :https://arxiv.org/abs/2205.02399
- Code :https://github.com/zju-vipa/spot-adaptive-pytorch
Summary of content
Distillation of knowledge (KD) It has become a good paradigm of compressed deep neural network . The typical method of knowledge distillation is to train students' network under the supervision of teachers' network , In one or more locations in the teacher network (spots, namely layers) To take advantage of (harness) knowledge . Throughout the distillation process , Once the distillation position is specified for all training samples, it will not be changed .
In this work , We believe that the distillation position should adapt to the training sample and distillation cycle . therefore , We propose a new distillation strategy , be called spot-adaptive KD(SAKD), In each training iteration throughout the distillation period , The distillation position is determined adaptively in the teacher network for each sample . because SAKD Actually focus on “ Where to distill ”, Rather than the extensive study of most existing works “ What do you want to distill ”, Therefore, it can be seamlessly integrated into existing distillation methods to further improve its performance .
stay 10 Experiments on two state-of-the-art distillation algorithms verify the homogeneity and heterogeneity (homogeneous and heterogeneous, It mainly emphasizes whether the student network and the teacher network have the same style of Architecture ) Under the setting of distillation SAKD Effectiveness in improving its distillation performance .
Related work

Distillation of knowledge
take DNN Deploying to edge devices with limited resources still exists difficult . In order to make DNN More applicable to these realities , Distillation of knowledge (KD) Used to target DNN Build a lightweight alternative to . Its main typical idea is to adopt a “ Teachers' - Student ” Form of learning , Here are competitive lightweight alternatives ( Called students ) By imitating well behaved but cumbersome structures “ Teachers' ”DNN Arising from the act of . Implicit knowledge learned by using the teacher model (dark knowledge), Light weight de The student model is expected to achieve comparable performance , But the parameters are much less .
KD It has gradually become a mature model compression paradigm , There have been a lot of related work .
Except for the classic “ Teachers' - Student ” normal form , There are also other forms :
- mutual distillation: The integrated form of a student model will cooperate in learning and teach each other throughout the training process , Make the teacher and student model develop together .
- self distillation: Not applicable to independent teacher network , Instead, monitor the shallower layers by using deeper outputs , So as to refine students' knowledge of the network itself .
- knowledge amalgamation: It aims to integrate knowledge from multiple teacher models , So as to build a single multi task student model .
- data-free distillation: Will relax the following assumptions : Training data of teacher model can be used to train students . That is, knowledge should be transferred to students without any original training data .
In this work , We still follow the traditional setting , That is, both the teacher network and the original training data can be used to train the student network . But we think that , This general idea can also be applied to all kinds of KD Set up , This will be left to future work .
Based on the difference of distillation position , They can be roughly divided into two categories :
- one-spot Distillation :KD Only in a single location , The typical form is in logit layer .
- Hinton In their work on distillation, et al. Proposed to minimize the difference between teachers' probability output and students' network output .
- Contrast means distillation (CRD) Using comparative learning method to extract structural knowledge , That is, the interdependence between different output dimensions of the representation layer .
- Relational knowledge distillation (RKD) Transfer the relationship of data samples from teacher model to student model , The interrelations are generated in a single presentation layer .
- multi-spot Distillation : By mining knowledge from multiple layers in the teacher network , So as to supervise the learning of student model .
- Fitnets Not only the output , It also uses the intermediate representation that the teacher learned , As a hint for training students .
- Pay attention to transfer (AT) Strategy , Improve the performance of the student model by forcing students to imitate the attention maps of different layers of a powerful teacher network .
- Activate boundary (AB) The distillation activation boundary formed by different layers of hidden neurons transmits the knowledge of the teacher model .
because multi-spot Distillation method and one-spot Methods compared , Use more information from the teacher model , Therefore, it is generally considered that they can show better migration effect .
Existing distillation methods , Whether it's one-spot still mutli-spot, All share a common characteristic : Distillation point is usually a manually designed option , Can't optimize , Especially for networks with hundreds or thousands of layers . One side , If the distillation point is too sparse , The student model is not fully supervised by teachers . On the other hand , If distillation spots are set too densely , for example , Every possible layer or neuron is used , The learning of student model may be over regularized , This will also lead to deterioration of distillation performance .
Besides , The current method uses a global distillation strategy , That is, once the distillation point is determined , It is fixed for all samples . The basic assumption is , This distillation point is optimal for the entire data distribution , This is not true in many cases . Ideally , We want to be able to automatically determine the distillation point for each sample and every possible location .
This work proposes a new distillation strategy spot-adaptive KD(SAKD). This makes the distillation point adaptive with the training sample and distillation stage .
So , We first combine the student model and the teacher model into a multi-path routing network , Pictured 2 Shown . Structure provides a variety of feasible paths for data flow . When the data reaches the network branch point , A lightweight strategy network (policy network) The optimal propagation path will be selected for each sample .
- If the data is routed to the layer of the teacher model , It indicates the corresponding layer in the student model ( Abbreviated as student level ) Cannot replace layer in teacher model ( It is abbreviated as teacher level ). therefore , The knowledge in the teacher level should be distilled to the corresponding student level .
- If the data is routed to the student layer , It shows that these students are good substitutes for the corresponding teachers , This results in better or at least comparable performance . Distillation is not allowed in these layers .
Because the policy network is designed on the basis of the routing network , And optimize the routing network at the same time , Therefore, it can automatically determine the best distillation point of each sample in the training iteration of the student model .
So we can see that , The proposed method focuses on “ Where to refine ”, This is different and orthogonal to the current work , They mainly studied “ What needs distillation ”, That is, the form of knowledge to be distilled . therefore , The proposed method can be seamlessly combined with existing methods , To further enhance distillation performance . To be specific , The proposed method is naturally compatible with homogeneous distillation , The student model is the same as the teacher model . however , Experiments show that , At the heterogeneous distillation setting , The proposed method can also play a good role , There are great differences between the student model and the teacher model . Besides , Although the proposed method is mainly used for multi-spot Distillation , But it can also be improved by dynamically determining the distillation of each training sample one-spot Distillation performance .
Overall speaking , The main contributions are :
- The adaptive distillation problem is introduced for the first time , The distillation point should be adapted to different training samples and distillation stages .
- To address this issue , Came up with a spot-adaptive Distillation strategy , It can automatically determine the distillation position , The distillation position can be adapted to the training sample and period .
- The experimental results show that the proposed method is effective in improving the existing distillation strategy .
Routing network (Routing Networks)
Routing network is a highly modular neural network , This is to encourage task decomposition 、 Key attributes needed to reduce model complexity and improve model generalization capabilities . A routing network usually consists of two trainable components : A set of function modules (function settings) And a policy agent (policy agent).
- Function modules : In neural network settings , The function module is realized by sub network , And is used as a candidate module for processing input data .
- Policy agent : For each sample , The policy agent selects a subset of function modules from these candidates , Assemble them into a complete model , The assembly model is applied to the input data for task prediction . Several algorithms have been proposed to optimize the policy module , Including genetic algorithms , Multi agent reinforcement learning , Re parameterization strategy, etc .
Routing networks are closely related to several structures , For example, conditional calculation 、 Expert mixed model , And their variants based on modern attention and sparse structure . They have been successfully applied to multi task learning , Transfer learning and language model . In this work , With the help of routing network , We propose a new distillation strategy , To automatically determine the distillation position in the network .
Position adaptive knowledge distillation (SPOT-ADAPTIVE KNOWLEDGE DISTILLATION)

The whole model consists of two main components : Multipath routing network and a lightweight policy network .
- Multipath routing network is composed of teacher model and student model , And has an adaptation layer , So as to adapt to each other's characteristics when necessary .
- When the data reaches the branch point in the routing network , The policy network is used to make routing decisions in each sample on the data flow path .
The general idea of the proposed distillation method is to automatically determine whether to carry out distillation at the candidate distillation point , Pictured 2 Shown . If the sample is routed by the policy network to some teacher layer , It indicates that the corresponding student layer cannot replace these teacher layers . therefore , The knowledge in the teacher level should be distilled into the corresponding student level . If the data is transferred to some student layers through the policy network , It shows that these students are good substitutes for the corresponding teachers , Can produce superior or at least comparable performance . These locations no longer require distillation .
The ultimate goal of distillation is to make the policy network gradually select the student layer for routing data , This means that the student model is a good substitute for the teacher network .
Multipath routing network
No loss of generality , Suppose a convolutional neural network for visual classification (CNN) There are several convolution blocks used to represent learning 、 A fully connected layer for vectorizing feature maps and a layer for making probabilistic predictions softmax layers . Each convolution block consists of several convolution layers , Each convolution layer is followed by a nonlinear activation layer and a batch normalization layer . generally speaking , After each block , The characteristic image will be reduced by the pooling layer or convolution layer 2 One or more .
thus , Teacher network and student network can be roughly expressed as several convolution blocks 、 A linear layer and a softmax Cascading combinations of layers .
The multi route network is composed of teacher and student networks , Among them, the interlayer is interrelated . However, due to the dimension mismatch between their layers , Therefore, this paper also introduces the 1x1 Convolution adaptation layer . thus , Multipath routing network can also be seen as using multiple volume layers 、 A linear layer and softmax Cascade structure of layers , But unlike a single network , The convolution layer and the linear layer are the result of the weighted fusion of the corresponding structures of the teacher network and the student network ( Here we will use the adaptation layer to align the features ). The weight used for fusion comes from the policy network , Its value range is 0 To 1. When the feature fusion weight takes a discrete value , In fact, the network has become a combination of the teacher network part layer and the student network part layer .
Using a routing network , The ultimate goal is to get an independent student model , It can perform as well as possible on tasks of interest .
Policy network
We use the policy network to make decisions for each sample on the data flow path through the routing network . ad locum , We only use the lightweight full connection layer to implement the policy network .
- The input is a spliced teacher and student model .
- Its output is N+1 individual 2 Dimensional routing vector , there N+1 Indicates the number of branch points , That is, the number of candidate distillation points . Each routing vector is a probability distribution , We draw a classification value from it (categorical value), Make decisions for data flow paths at branch points in a routing network .
Sampling operations are nondifferentiable for discrete cases . To ensure the differentiability of the sampling operation , Use here Gumbel-Softmax Technology to implement policy network . Formally speaking , For the first i Branch points , The corresponding routing vector is a two-dimensional vector , Here the first element stores the representation of the i How likely is the teacher network layer in a block to be used to process incoming data .
Forward propagation , The strategy derives discrete decisions from the classification distribution based on the following distribution :
there w It's a two-dimensional one-hot vector , and “one_hot” The function returns one-hot A function of a vector . The rightmost quantity is a two-dimensional vector , The elements are all from Gumbel Plotted in the distribution i.i.d sample , Used to add a small amount of noise , To avoid argmax The operation always selects the element with the highest probability value .
In order to ensure the differentiability of discrete sampling function , It's used here Gumbel-Softmax Techniques to relax during back propagation w.

there τ It's a temperature parameter , Used to approximate the sharpness of the distribution . Note that for w Each vector in the , The sum of the two elements contained therein is 1.
Spot-adaptive Distillation
The proposed location adaptive distillation is constructed by simultaneously training the routing network and the policy network . From the perspective of policy network and routing network , The network proposed by the training is nonstationary , Because the best routing strategy depends on the module parameters , vice versa .
In this work , Multi route network and policy network are trained simultaneously in an end-to-end manner .

The complete objective function consists of four parts :
- Cross entropy loss of student model supervision using truth value .
- Use the teacher model to predict the effect of student model supervision KL The divergence , This is related to Hinton The common distillation losses presented in the work are consistent . Service factor β1 weighting .
- Existing knowledge distillation losses based on middle layer characteristics . for example FitNets、Attention Transfer And so on . Service factor β2 weighting .
- Using the truth value to supervise the prediction from the routing network in the form of cross entropy Routing loss . Use β3 weighting . What is said here seems a little confusing , In fact, the pseudocode provided by the author can provide an intuitive understanding . The routing network can be considered as a forward propagation network independent of the student network and the teacher network , Its sub structures are the weighted combination of the teacher network and the student network .
Throughout the training phase , The pre training parameters of the teacher model are kept fixed . The trainable parameters only include the parameters of the student model , Adaptation layer and policy network . The policy network and adaptation layer only participate in the calculation of routing loss , Their parameters are trained only under the supervision of routing loss .
Student network and strategy network form a ring , The output of the student model enters the strategy network , The output of the strategy network enters the student network again . In order to stabilize the training of student network , We no longer transfer the gradient of the backpropagation strategy network to the student network .
Early in training , Because the teacher model has been properly trained , Therefore, the strategy network is more likely to pass the samples to the teacher level . under these circumstances , Knowledge distillation occurs at all candidate distillation points . As the training goes on , The student model has gradually mastered the teacher's knowledge at different levels . under these circumstances , The policy network can plan a path for each sample , The teacher level and the student level are intertwined . therefore , The distillation of knowledge is carried out adaptively at certain levels , To promote the best strategy involving only the student level .
optimization algorithm

In order to make the proposed method clearer , Pseudo code in algorithm 1 Provided in the .
- Given two deep neural networks , One of the students S And teachers T. Make x Enter... For the network .
- We express the set of intermediate representations from the teacher and student models as featT and featS, The final forecast is expressed as logitT and logitS.
- Policy network P The input of is the combination of teachers' and students' characteristics . Policy model P The output of is N+1 A two-dimensional routing vector , Expressed as w, They are discrete decisions made during forward propagation , And will be used during backward propagation Gumbel-Softmax To relax .
- One obvious difficulty here is , Students' distillation losses Ls Depends on the routing decision w, Therefore, it is problematic to optimize the student model with the strategy network . We avoid this difficulty by cutting off the gradient operation . It means d Considered constant in loss .
- The complete objective function of the student model is shown in 26 That's ok 〜28 In line , This includes cross entropy loss 、KL Divergence and knowledge distillation losses .
- Then the propagation of multi-channel routing network begins . This includes the teacher model and the student model , The middle layers are interrelated . By setting the student model to eval Pattern ( avoid BN and dropout Repeated changes ), To make the routing network more stable , After obtaining the final forecast , Restore it to train Pattern .
- In order to align the characteristics between teachers and students , The adaptation layer is referenced Hst and Hts.
- The cross entropy loss is finally used to optimize the parameters of the strategy module and the adaptation module .
experiment
Experimental setup
When experimenting with the combination effect of the current method and other methods , All the methods will be similar to the common KD Loss ( From the difference between the softening predictions in the teacher and student models ) Bind together , To improve its performance . therefore , All methods involve at least two distillation points , Whether they were originally single point or multi-point distillation methods , Will become a multipoint version . And these methods are used in this paper , Will determine different distillation points before training , And remain the same throughout the distillation process . If a method uses blocks i(1≤i≤N+1) Knowledge , The distillation point is called i.
The temperature value of softening prediction distribution is set to 4.gumbel-softmax Medium τ Initially set to 5, And gradually fade during training , Therefore, the network can be freely explored at an early stage , And in the later stage, the distillation strategy after convergence .

For the sake of simplicity , Hyperparameters β1 and β3 Set to 1.β2 It is set according to the distillation method . We were using the CRD The parameters in the original paper are set for most distillation methods β2. except FitNets, For more stable training , therefore β2 Set to 1 instead of 1000. β2 The detailed settings of are shown in the table II Shown .
Comparison with existing methods
Homogeneous distillation paradigm

Note that all comparison methods will match the original KD Strategy , And in our scheme , Candidate distillation points include softmax Layer and some intermediate layers . For the middle layer , Different schemes will utilize different numbers of middle layers , The proposed adaptive distillation strategy only determines whether distillation is performed at these distillation points . It does not add any other candidate distillation points to the standard distillation method .
Heterogeneous distillation paradigm

Similar to homogeneous distillation , Candidate distillation points include softmax Layer and middle layer .softmax The layer is always a candidate distillation point in the adaptive scheme .

ImageNet Validation on

The authors are also ImageNet The scalability of the proposed strategy is verified on such a large data set .
Ablation Experiment
Whether the policy network can provide effective decisions ?

We verify the practicability of policy network decision-making . So , We introduced four baseline distillation strategies :
- always-distillation: Standard distillation strategy for always distilling at each distillation point .
- rand-distillation: Randomly decide whether to distill at the candidate distillation point .
- anti-distillation: The distillation strategy is the opposite of the proposed adaptive distillation . If the adaptive distillation strategy is carried out at a certain point, distillation will be carried out , Then the strategy will not distill ; otherwise , It will distill at this position .
- no-distillation: The students carried out rash tests without any distillation (trivially) Training for .
It can be seen that , The proposed adaptive distillation is always superior to other benchmarks , Including competitive always-distillation. Although improvements in some distillation methods are sometimes negligible , However, almost all the consistent improvements of distillation verify that the proposed policy network does make useful routing decisions for distillation . Besides ,anti-distillation Often than adaptive-,adaptive- and rand-distillation Performance is much worse , Sometimes even better than not no-distillation The situation is even worse . These results suggest that , Distillation in an inappropriate place may be harmful to the training of students .
How decisions change with location ?

ad locum , We studied the strategy network at different distillation points and distillation stages ( The training period ) Distillation decisions made .** At each candidate distillation location , The possibility of distillation is the ratio of the number of samples distilled at this point to the total number of training samples .** chart 3 The probability curves at different points along the training period are described in .
- In the early stage, due to the well-trained network of teachers , The best routing decision should select the teacher layer at all the branch points in the routing network . therefore , At all distillation points , The probability of distillation should be close to 100%. But because the policy network is initialized randomly , And not yet well trained , So its decisions are random , Therefore, the probability of distillation is very low .
- As the training goes on , Strategic networks gradually learn how to make the right decisions , And found that teachers tend to be better , Therefore, the probability of distillation increases rapidly .
- After a period of distillation , The student model has mastered the teacher's knowledge . Some samples are less useful for training student models , Therefore, the probability of distillation is reduced ( for example KD_1).
generally speaking , Shallow layers are more sensitive to adaptive distillation . Deep words , Almost all samples need to be distilled at all times , just as KD_4 and KL As shown by the curve of . The reason for this phenomenon may be that the shallow features are relatively noisy for distillation . Because the ability of student model is much smaller than that of teacher , Therefore, learning from these noisy functions will reduce their performance on the final goal task .
Should the teacher network be frozen or trainable ?

The teacher network has been frozen in the proposed method . This constraint is relaxed here , Two alternative settings are introduced :
- The teacher network is initialized randomly and trained with the student network ;
- The teacher network is initialized with pre trained parameters , And train with the student network .
The trainable teacher network improves the capability of multi-channel routing network , But it may damage the training of the student model that will be deployed independently . surface VIII The experimental results are provided . It can be seen that , Whether training the teacher network from scratch or from pre trained parameters , Will reduce the distillation performance , To test our hypothesis . What's worse is , The network of training instructors slows down the distillation process , Because updating teacher parameters requires more calculations .
Yes β3 and τ The sensitivity of

The proposed method involves several hyperparameters . however , Most of them were introduced in previous works . We use the settings in these documents . This work also introduces two new super parameters , namely τ and β3. Here alignment for sensitivity analysis , Observe their influence .
The experimental results show that they will affect the results to some extent . however , They enable the proposed adaptive method to achieve higher results than the standard distillation method in a wide range of values . This feature makes the proposed method more potential , Because we haven't adjusted too many parameters .
Visualization of distillation decisions

In order to better understand the decisions made by the policy network , Here is tiny-ImageNet Visualization of decisions on ten categories in .
You can see , Most images to be distilled , Has a better quality than images that will not be distilled . We divide the samples without knowledge distillation into four categories : The content is missing , The subject is ambiguous , Object group , And abnormal morphology . These are represented by the red , yellow , Purple and green boxes indicate .
- The content is missing ( Red ). Due to extreme closeness or uncharacteristic perspective (extreme close-ups or uncharacteristic views), This type of data captures only a portion of the object . In images where other content is missing , The object cannot be distinguished from the background .
- The subject is ambiguous ( yellow ). These images contain multiple objects , Unable to identify which object is the focus of the image . Use these input images , The model can easily learn features that do not belong to the target category and ultimately lead to errors .
- Object group ( violet ). A close-up of a single object can reveal its characteristics in detail , The object group can only provide the overall characteristics .
- Abnormal morphology ( green ). Some of these images are different from most of the images in the dataset , These particular images will not be distilled . The rarity of these images makes them provide features that are incompatible with general features . for example , We can see blue lobsters , Furry penguins and pink haired pigs , This conflicts with the common characteristics of these targets in the dataset .
These low-quality features may produce noisy features or predictions , This may be due to students' limited ability to model , And the learning of the damage model . We acknowledge that , These undistilled images can provide information for the model from another angle , But the noise they introduce is also worth considering . Usually , Discriminative images can provide useful features , Therefore, the distillation decision shown in the figure is reasonable , Therefore, the knowledge of these images will guide students well .
边栏推荐
- Vision transformer | arXiv 2205 - TRT vit vision transformer for tensorrt
- Explanation and explanation on the situation that the volume GPU util (GPU utilization) is very low and the memory ueage (memory occupation) is very high during the training of pytoch
- Leetcode notes: Weekly contest 280
- qt. qpa. plugin: Could not load the Qt platform plugin “xcb“ in “***“
- Vscode的Katex问题:ParseError: KaTeX Parse Error: Can‘t Use Function ‘$‘ In Math Mode At Position ...
- MFC中窗口刷新函数详解
- APS究竟是什么系统呢?看完文章你就知道了
- 超全MES系统知识普及,必读此文
- Prediction of COVID-19 by RNN network
- Debug debugging cmake code under clion, including debugging process under ROS environment
猜你喜欢

Vision Transformer | Arxiv 2205 - LiTv2: Fast Vision Transformers with HiLo Attention

Improvement of hash function based on life game (continued 2)

Prediction of COVID-19 by RNN network
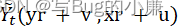
DUF:Deep Video Super-Resolution Network Using Dynamic Upsampling Filters ... Reading notes

FPGA generates 720p video clock

Record the treading pit of grain Mall (I)

ASP.NET项目开发实战入门_项目六_错误报告(自己写项目时的疑难问题总结)

Alibaba cloud deploys VMware and reports an error

Compiling principle on computer -- functional drawing language (V): compiler and interpreter

PPP agreement
随机推荐
Ten important properties of determinant
Explain the basic working principle of Ethernet
从AC5到AC6转型之路(1)——补救和准备
Strvec class mobile copy
Mathematical Essays: Notes on the angle between vectors in high dimensional space
2.2 链表---设计链表(Leetcode 707)
Three data exchange modes: line exchange, message exchange and message packet exchange
Compiling principle on computer -- functional drawing language (V): compiler and interpreter
企业为什么要实施MES?具体操作流程有哪些?
OpenMP task 原理与实例
DUF:Deep Video Super-Resolution Network Using Dynamic Upsampling Filters ...阅读笔记
S-msckf/msckf-vio technical route and code details online blog summary
visual studio2019的asp.net项目添加日志功能
Vision transformer | arXiv 2205 - TRT vit vision transformer for tensorrt
Numpy generates row vectors and column vectors (1024 water medal text)
(P33-P35)lambda表达式语法,lambda表达式注意事项,lambda表达式本质
Transformation from AC5 to AC6 (1) - remedy and preparation
Summary of structured slam ideas and research process
FPGA generates 720p video clock
Alibaba cloud deploys VMware and reports an error