当前位置:网站首页>In depth learning, the parameter quantity (param) in the network is calculated. The appendix contains links to floating point computations (flops).
In depth learning, the parameter quantity (param) in the network is calculated. The appendix contains links to floating point computations (flops).
2022-06-12 07:53:00 【Wait for Godot.】
List of articles
- The amount of parameters in the network (param) And floating point computation (FLOPs) The calculation of
- One 、 The amount of parameters in the network (param) What is it? ? Floating point computation (FLOPs) What is it? ?
- Two 、 How to calculate the parameter quantity in the network (param)
- additional : Parameter and model memory \ Model size relationship
- Summary and floating-point computation FLOPs Guidelines
The amount of parameters in the network (param) And floating point computation (FLOPs) The calculation of
One 、 The amount of parameters in the network (param) What is it? ? Floating point computation (FLOPs) What is it? ?
- The amount of parameters in the network (param) Corresponding to Space Space Concept , And spatial complexity .
- Floating point computation (FLOPs) Corresponding to Time Time Concept , Corresponding to the time complexity .
namely , Network parameters (param) It is closely related to video memory ; Floating point computation (FLOPs) and GPU The calculation speed of .
Two 、 How to calculate the parameter quantity in the network (param)
The amount of parameters in the network (param) The calculation of
The parameter calculation in the network needs to be divided into
Convolution layer :
The parameters that need attention are (kernel_size,in_channel,out_channel)
Calculation formula :
Full version : c o n v _ p a r a m = ( k e r n e l _ s i z e ∗ i n _ c h a n n e l + b i a s ) ∗ o u t _ c h a n n e l conv\_param = (kernel\_size*in\_channel+bias)*out\_channel conv_param=(kernel_size∗in_channel+bias)∗out_channel, Default b i a s = 1 bias=1 bias=1,out_channel yes filter( Represents the number of convolution kernels ), And each convolution kernel has a corresponding bias.
Abridged edition : c o n v _ p a r a m = k e r n e l _ s i z e ∗ i n _ c h a n n e l ∗ o u t _ c h a n n e l conv\_param = kernel\_size*in\_channel*out\_channel conv_param=kernel_size∗in_channel∗out_channel, because bias It will not affect the change of order of magnitude , Generally, it can be omitted .
for instance :
As shown in the figure below :
image_size = 5x5x3
kernel_size = 3x3
in_channel = 3 ( Images channel)
out_channel = 2 ( Number of convolution kernels \filter number )
Then the Number of parameters by :
Full version : c o n v _ p a r a m = ( k e r n e l _ s i z e ∗ i n _ c h a n n e l + b i a s ) ∗ o u t _ c h a n n e l = = ( 5 ∗ 5 ∗ 3 + 1 ) ∗ 2 = 152 conv\_param = (kernel\_size*in\_channel+bias)*out\_channel==(5*5*3+1)*2 = 152 conv_param=(kernel_size∗in_channel+bias)∗out_channel==(5∗5∗3+1)∗2=152
Abridged edition : c o n v _ p a r a m = k e r n e l _ s i z e ∗ i n _ c h a n n e l ∗ o u t _ c h a n n e l = 5 ∗ 5 ∗ 3 ∗ 2 = 150 conv\_param = kernel\_size*in\_channel*out\_channel =5*5*3*2 = 150 conv_param=kernel_size∗in_channel∗out_channel=5∗5∗3∗2=150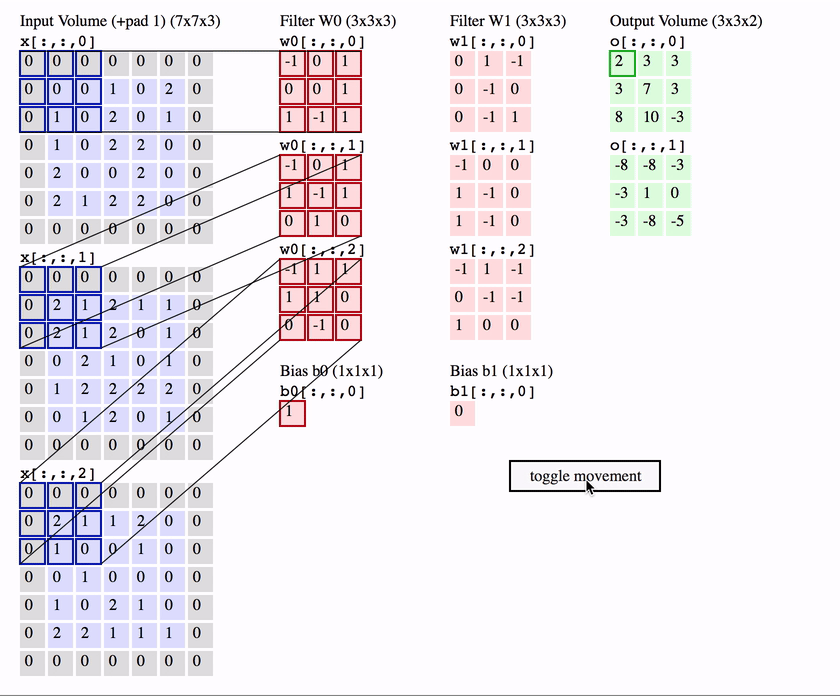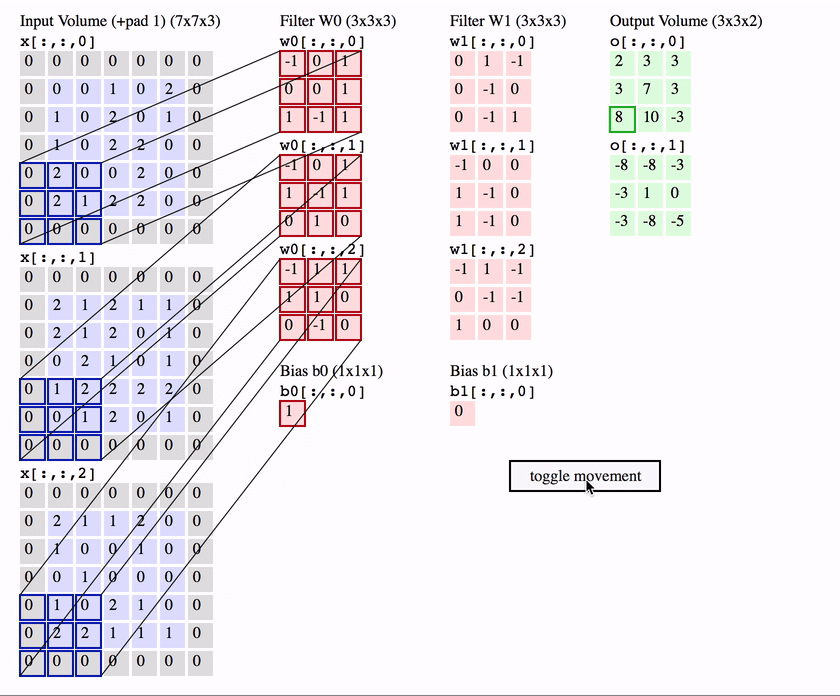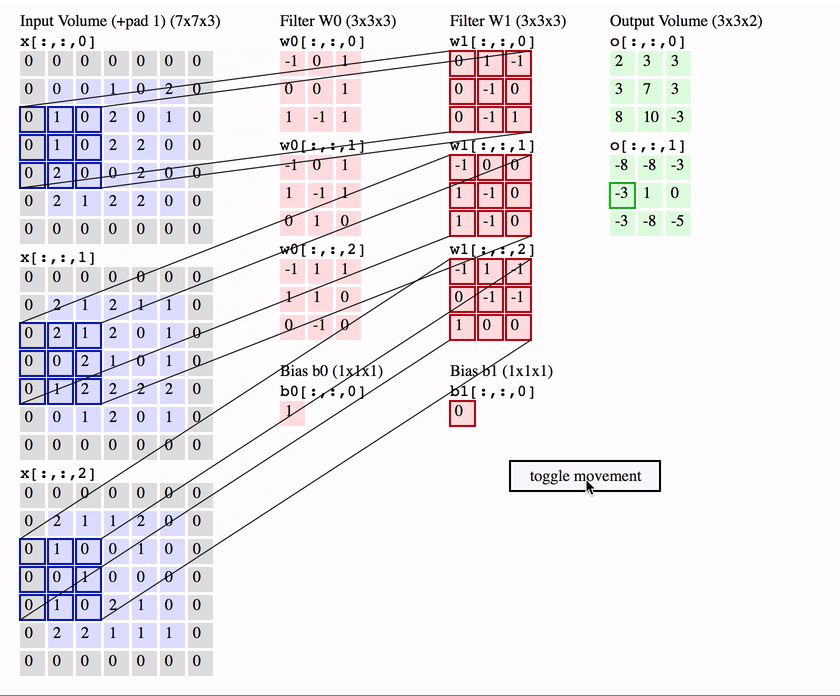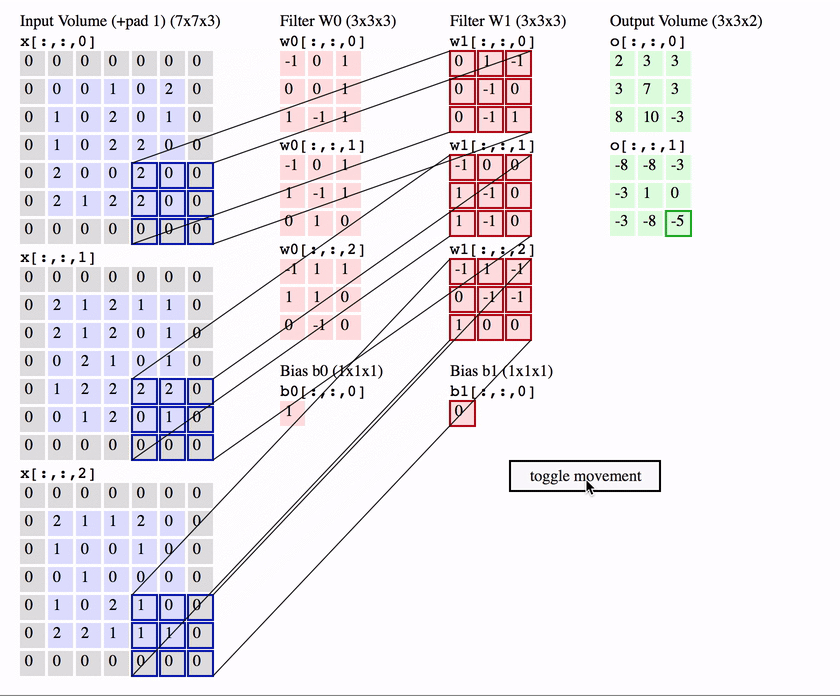
Pooling layer :
Pooling layer doesn't need parameters . for example max_pooling: Just maximize pooling directly , No parameters required .
Fully connected layer :
There are two cases of full connection layer , One is from convolution layer to full connection layer , One is full connection layer to full connection layer , Therefore, we need to discuss it according to the situation :
CONV->FC And calculation formula
C o n v _ F C _ p a r a m = f e t u r e m a p _ s i z e ∗ i n _ c h a n n e l ∗ o u t _ n e u r a l Conv\_FC\_param = feturemap\_size*in\_channel*out\_neural Conv_FC_param=feturemap_size∗in_channel∗out_neural
feturemap_size : Dimension of the feature drawing of the previous floor
in_channel : The number of convolution kernels in the previous layer
out_neural : Number of neurons in the whole connecting layer
FC->FC And calculation formula
F C _ F C _ p a r a m = i n _ n e u r a ∗ ∗ o u t _ n e u r a l − b i a s FC\_FC\_param = in\_neura**out\_neural-bias FC_FC_param=in_neura∗∗out_neural−bias
bias = out_neural, Every neuron has a bias. In general, it can be ignored bias.
Code display
Pytorch There are many packets for calculating the parameter quantity in the network , for example torchstat、thop、ptflops、torchsummary wait , Here we will select some parts to show .
- First, build a simple CNN The Internet :
import torch
from torch import nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height gray just have one level
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
print(cnn) # net architecture
- Calculate the parameters
Torchstat Use of the bag
from torchstat import stat
# Import model , Enter the size of a picture
stat(cnn, (1, 28, 28))
Output results :
module name input shape output shape params memory(MB) MAdd Flops MemRead(B) MemWrite(B) duration[%] MemR+W(B)
0 conv1.0 1 28 28 16 28 28 416.0 0.05 627,200.0 326,144.0 4800.0 50176.0 46.17% 54976.0
1 conv1.1 16 28 28 16 28 28 0.0 0.05 12,544.0 12,544.0 50176.0 50176.0 0.22% 100352.0
2 conv1.2 16 28 28 16 14 14 0.0 0.01 9,408.0 12,544.0 50176.0 12544.0 12.20% 62720.0
3 conv2.0 16 14 14 32 14 14 12832.0 0.02 5,017,600.0 2,515,072.0 63872.0 25088.0 35.98% 88960.0
4 conv2.1 32 14 14 32 14 14 0.0 0.02 6,272.0 6,272.0 25088.0 25088.0 0.05% 50176.0
5 conv2.2 32 14 14 32 7 7 0.0 0.01 4,704.0 6,272.0 25088.0 6272.0 5.03% 31360.0
6 out 1568 10 15690.0 0.00 31,350.0 15,680.0 69032.0 40.0 0.35% 69072.0
total 28938.0 0.16 5,709,078.0 2,894,528.0 69032.0 40.0 100.00% 457616.0
=========================================================================================================================================
Total params: 28,938
-----------------------------------------------------------------------------------------------------------------------------------------
Total memory: 0.16MB
Total MAdd: 5.71MMAdd
Total Flops: 2.89MFlops
Total MemR+W: 446.89KB
Torchinfo Use of the bag : ( Just finished writing , Find out torchsummary Renamed torchinfo 了 , Use this )
pip install torchinfo
#from torchsummary import summary
from torchinfo import summary
# Import model , Enter the size of a picture
#summary(cnn.cuda(), input_size=(1, 28, 28), batch_size=-1)
batch_size = 1
summary(model, input_size=(batch_size, 1, 28, 28))
Output results :
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 28, 28] 416
ReLU-2 [-1, 16, 28, 28] 0
MaxPool2d-3 [-1, 16, 14, 14] 0
Conv2d-4 [-1, 32, 14, 14] 12,832
ReLU-5 [-1, 32, 14, 14] 0
MaxPool2d-6 [-1, 32, 7, 7] 0
Linear-7 [-1, 10] 15,690
================================================================
Total params: 28,938
Trainable params: 28,938
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.32
Params size (MB): 0.11
Estimated Total Size (MB): 0.44
----------------------------------------------------------------
The display results of the two packages have their own advantages and disadvantages , Can be used according to requirements .
Thop Use of packages and Pytorch Use of built-in parameter calculation :
from thop import profile
model = build_detection_model(cfg).cuda()
# Import model , Enter the size of a picture
print(model)
input = torch.randn(1, 3, 300, 300).cuda()
flop, para = profile(model, inputs=(input, ))
print('Flops:',"%.2fM" % (flop/1e6), 'Params:',"%.2fM" % (para/1e6))
total = sum([param.nelement() for param in model.parameters()])
print('Number of parameter: %.2fM' % (total/1e6))
additional : Parameter and model memory \ Model size relationship
Parameters occupy video memory = Number of parameters ×n
n=4:float32
n=2:float16
n=8:double64
besides ,batch_size The input pictures occupy most of the video memory .
The model size It's the size of the model , We usually use parameter quantities parameter To measure , Be careful , Its unit is . But because many model parameters are too large , So we usually choose a more convenient unit : mega (M) To measure . such as ResNet-152 The parameter quantity of can reach 60 million = 0.0006M. Sometimes ,model size In the actual calculation, in addition to the parameters , It also includes network architecture information and optimizer information . For example, store a general CNN Model (ImageNet Training ) Need greater than 300MB.
M and MB The conversion relationship of :
For example, I have a model parameter quantity that is 1M, In the general framework of deep learning ( for instance PyTorch), It's usually 32 Bit storage .32 Bit storage means 1 For each parameter 32 individual bit To store . So this has 1M The size of the storage space required for the model of parameter quantity is :1M * 32 bit = 32Mb = 4MB. because 1 Byte = 8 bit. current quantization Technology is to reduce the number of bits occupied by parameters : For example, I use 8 Bit storage , that : The size of the required storage space is :1M * 8 bit = 8Mb = 1MB.
Summary and floating-point computation FLOPs Guidelines
Floating point computation :
FLOPs How to calculate
Reference resources :
https://blog.csdn.net/m0_51004308/article/details/118048504
https://blog.csdn.net/weixin_45292794/article/details/108227437
https://blog.csdn.net/Leo_whj/article/details/109636819
边栏推荐
- 解决上传SFTPorg.apache.commons.net.MalformedServerReplyException: Could not parse respon
- Unity uses shaders to highlight the edges of ugu I pictures
- Topic 1 Single_Cell_analysis(1)
- Voice assistant - Introduction and interaction process
- Work summary of the week from November 22 to 28, 2021
- Voice assistant - Measurement Indicators
- Leetcode34. find the first and last positions of elements in a sorted array
- Summary of machine learning + pattern recognition learning (VI) -- feature selection and feature extraction
- Voice assistant - overall architecture and design
- Preliminary knowledge next New concepts such as isr/rsc/edge runtime/streaming in JS
猜你喜欢

Question bank and answers of special operation certificate examination for safety management personnel of hazardous chemical business units in 2022

vscode 1.68变化与关注点(整理导入语句/实验性新命令中心等)

2022 simulated test platform operation of hoisting machinery command test questions

Meter Reading Instrument(MRI) Remote Terminal Unit electric gas water

The project file contains toolsversion= "14.0". This toolset may be unknown or missing workarounds

Seeking for a new situation and promoting development, the head goose effect of Guilin's green digital economy

最新hbuilderX编辑uni-app项目运行于夜神模拟器
Process terminated

AI fanaticism | come to this conference and work together on the new tools of AI!

Topic 1 Single_ Cell_ analysis(1)
随机推荐
Utilize user behavior data
Summary of machine learning + pattern recognition learning (V) -- Integrated Learning
Leverage contextual information
@Datetimeformat @jsonformat differences
Voice assistant - Multi round conversation (theory and concept)
Topic 1 Single_Cell_analysis(2)
20220607. face recognition
解决上传SFTPorg.apache.commons.net.MalformedServerReplyException: Could not parse respon
Leetcode notes: biweekly contest 79
2021.10.31-11.1 scientific research log
Numerical calculation method chapter5 Direct method for solving linear equations
Exposure compensation, white increase and black decrease theory
Multithread decompression of tar
R语言glm函数构建泊松回归模型(possion)、epiDisplay包的poisgof函数对拟合的泊松回归模型进行拟合优度检验、即模型拟合的效果、验证模型是否有过度离散overdispersion
NaiveBayes function of R language e1071 package constructs naive Bayes model, predict function uses naive Bayes model to predict and reason test data, and table function constructs confusion matrix
20220524 backbone deep learning network framework
Compiling principle on computer -- functional drawing language (V): compiler and interpreter
2022 simulated test platform operation of hoisting machinery command test questions
『Three.js』辅助坐标轴
Meter Reading Instrument(MRI) Remote Terminal Unit electric gas water