当前位置:网站首页>Transformers loading Roberta to implement sequence annotation task
Transformers loading Roberta to implement sequence annotation task
2022-06-26 08:27:00 【xuanningmeng】
transformers load roberta Realize the sequence annotation task
I've been studying intermittently recently hugging face Of transformers, Mainly using transformers Loading various pre training models to realize sequence annotation . The main content of this blog is to compete for loading roberta The pre training model does the sequence annotation task . The general content is as follows :
(1)roberta Model
(2)transformers Realize sequence annotation
roberta Model
Struggle for bert Model , There are many improved versions of the model ,roberta Model and bert The model has the following differences , among roberta The full name is Robustly optimized BERT approach.
(1)roberta The training corpus is increased , Model effect ratio bert good
(2)roberta Using dynamic mask, This with bert Of mask Dissimilarity ,bert During model training , every last epoch The data of mask Are all the same , and roberta Improved this maks The way , Adopt dynamic mask, Per one epoch Of the input data mask Dissimilarity
(3)roberta use Byte-Pair Encoding Coding method of , using character- and word-level representations
(4)roberta To cancel the nsp, The experiment in this paper proves that nsp Loss of downstream tasks 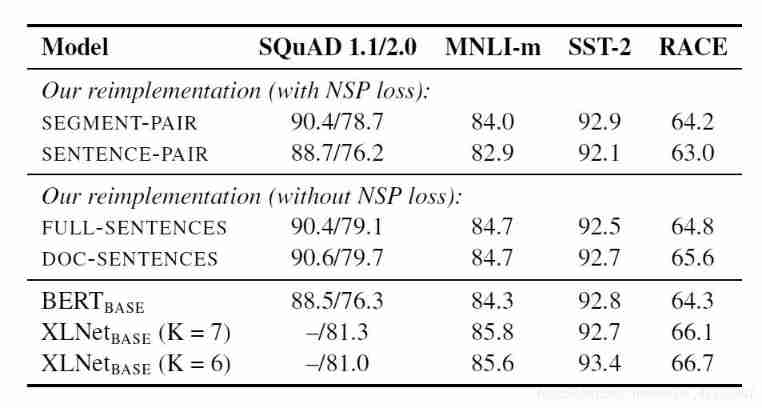
(5)roberta The optimizer for adam The parameters of
(6)roberta In training , Can take bigger batch size
transformers Realize sequence annotation
Here are transformers load roberta The pre training model realizes sequence annotation , It adopts the... Of Harbin Institute of technology roberta-wwm Model .
(1)tokenizer
from tokenizers import BertWordPieceTokenizer
def get_tokenizer(model_path):
vocab_file = os.path.join(model_path, "vocab.txt")
tokenizer = BertWordPieceTokenizer(vocab_file,
lowercase=True)
return tokenizer
(2) Model input feature words
Model input and bert Keep your input consistent
def convert_example_to_feature(context, context_tags, tokenizer):
code = tokenizer.encode(context)
new_tags = []
for offset in code.offsets:
if offset != (0, 0):
start_index, end_index = offset
new_tags.append(context_tags[start_index])
assert len(code.ids) == len(code.type_ids) == len(code.attention_mask)
return code.ids, code.type_ids, code.attention_mask, new_tags
def create_inputs_targets_roberta(sentences, tags, tag2id, max_len, tokenizer):
tokenizer.enable_padding(length=max_len)
tokenizer.enable_truncation(max_length=max_len)
dataset_dict = {
"input_ids": [],
"token_type_ids": [],
"attention_mask": [],
"tags": []
}
for sentence, tag in zip(sentences, tags):
sentence = ''.join(sentence)
input_ids, token_type_ids, attention_mask, \
post_tags = convert_example_to_feature(sentence, tag, tokenizer)
dataset_dict["input_ids"].append(input_ids)
dataset_dict["token_type_ids"].append(token_type_ids)
dataset_dict["attention_mask"].append(attention_mask)
if len(post_tags) < max_len - 2:
pad_bio_tags = post_tags + [tag2id['O']] * (max_len - 2 - len(post_tags))
else:
pad_bio_tags = post_tags[:max_len - 2]
dataset_dict["tags"].append([tag2id['O']] + pad_bio_tags + [tag2id['O']])
for key in dataset_dict:
dataset_dict[key] = np.array(dataset_dict[key])
x = [
dataset_dict["input_ids"],
dataset_dict["token_type_ids"],
dataset_dict["attention_mask"],
]
y = dataset_dict["tags"]
return x, y
(3) Model
stay transformers load roberta Model development fine-tuning, Chinese sequence tagging uses TFBertForTokenClassification. The code of the model is as follows :
model = TFBertForTokenClassification.from_pretrained(args["pretrain_model_path"],
from_pt=True,
num_labels=len(list(tag2id.keys())))
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5, epsilon=1e-08)
# we do not have one-hot vectors, we can use sparse categorical cross entropy and accuracy
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
model.summary()
model.fit(train_x,
train_y,
epochs=epoch,
verbose=1,
batch_size=batch_size,
validation_data=(dev_x, dev_y),
validation_batch_size=batch_size
) # , validation_split=0.1
# model save
model_file = os.path.join(args["output_path"], "ner_model.h5")
model.save_weights(model_file, overwrite=True)
# save pb model
tf.keras.models.save_model(model, args["pb_path"], save_format="tf")
(4) Model evaluation
id2tag = {
value: key for key, value in tag2id.items()}
pred_logits = model.predict(data, batch_size=batch_size)[0]
# pred shape [batch_size, max_len]
preds = np.argmax(pred_logits, axis=2).tolist()
assert len(preds) == len(seq_len_list)
# get predcit label
predict_label = []
target_label = []
for i in range(len(preds)):
pred = preds[i][1:]
temp = []
true_label = label[i][:min(seq_len_list[i], len(pred))]
for j in range(min(seq_len_list[i], len(pred))):
temp.append(id2tag[pred[j]])
assert len(temp) == len(true_label)
target_label.append(true_label)
predict_label.append(temp)
# Calculation precision, recall, f1_score
precision = precision_score(target_label, predict_label, average="macro", zero_division=0)
recall = recall_score(target_label, predict_label, average="macro", zero_division=0)
f1 = f1_score(target_label, predict_label, average="macro",
zero_division=0)
logger.info(classification_report(target_label, predict_label))
The results on different data sets are supplemented later , If there is a mistake , You are welcome to testify .
边栏推荐
- Wifi-802.11 2.4G band 5g band channel frequency allocation table
- Getting started with idea
- How to Use Instruments in Xcode
- OpenCV Learning notes iii
- Analysis of internal circuit of operational amplifier
- The solution of installing opencv with setting in pycharm
- Pychart connects to Damon database
- Idea automatically sets author information and date
- optee中的timer代码导读
- STM32 project design: temperature, humidity and air quality alarm, sharing source code and PCB
猜你喜欢

Can the encrypted JS code and variable name be cracked and restored?
2020-10-17
GHUnit: Unit Testing Objective-C for the iPhone
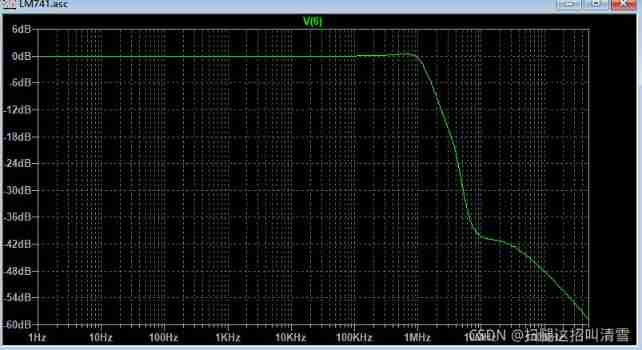
Analysis of internal circuit of operational amplifier

How to debug plug-ins using vs Code

xxl-job配置告警邮件通知

OpenCV Learning notes iii

And are two numbers of S
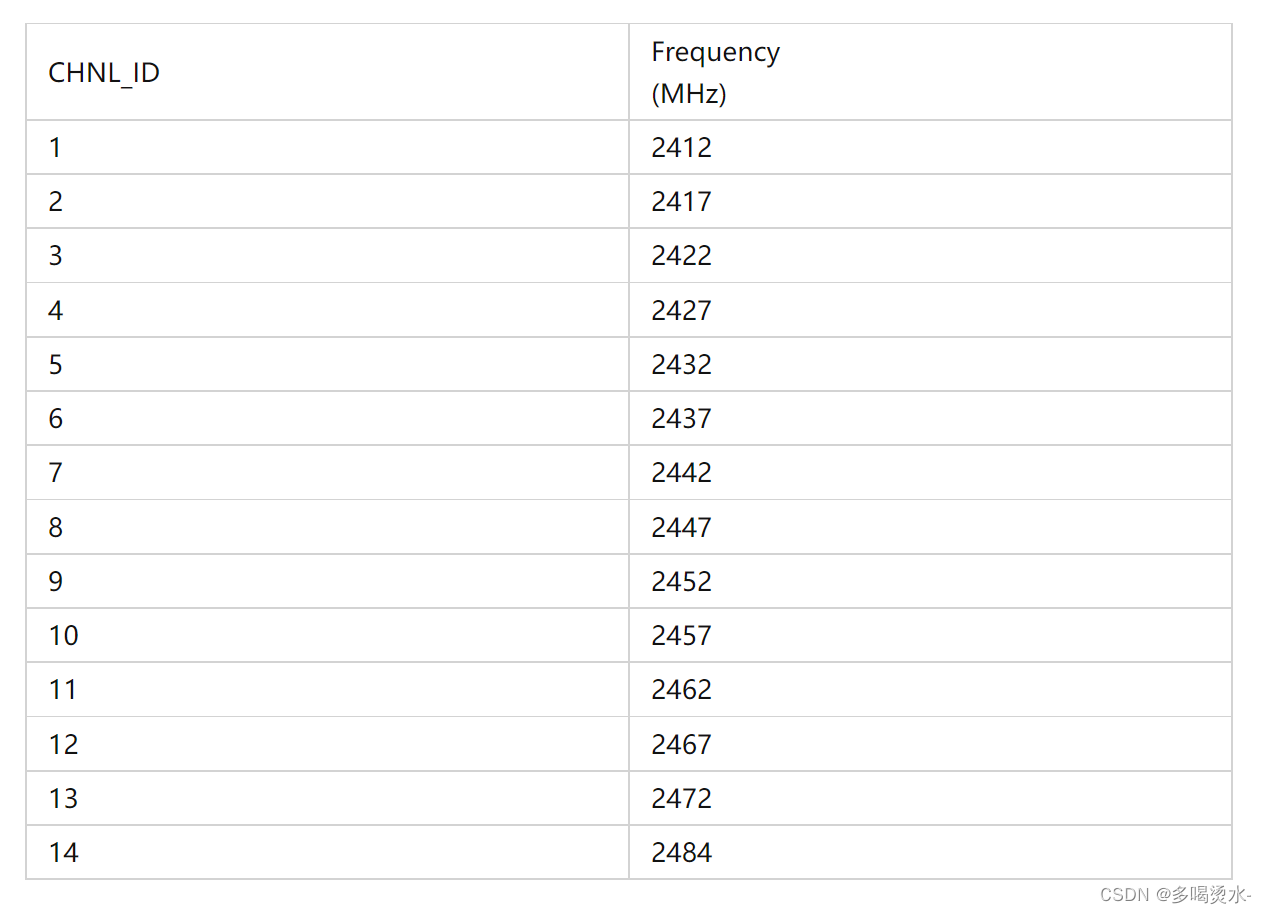
Wifi-802.11 2.4G band 5g band channel frequency allocation table

Discrete device ~ diode triode

随机推荐
加密的JS代码,变量名能破解还原吗?
The difference between push-pull circuit drive and totem pole drive
Oracle 19C download installation steps
JWT in go
Go语言浅拷贝与深拷贝
JS precompile - Variable - scope - closure
Pychart connects to Damon database
73b2d wireless charging and receiving chip scheme
js文件报无效字符错误
FFmpeg音视频播放器实现
Quickly upload data sets and other files to Google colab ------ solve the problem of slow uploading colab files
Timer code guide in optee
Database learning notes I
Interview ES6
MySQL query time period
Rewrite string() method in go language
Win10 mysql-8.0.23-winx64 solution for forgetting MySQL password (detailed steps)
JS file message invalid character error
Necessary protection ring for weak current detection
(5) Matrix key