当前位置:网站首页>【广告系统】Parameter Server分布式训练
【广告系统】Parameter Server分布式训练
2022-07-05 10:36:00 【CC‘s World】
在广告/推荐/搜索场景,目前主流算法采用embedding+DNN的模型结构,随着数据量越来越多,单机训练已经无法满足实时要求。针对广告/推荐场景,一般采用Parameter Server的方式进行分布式训练,简称ps,ps可以同时做到对数据和模型的并行训练。Parameter Server直译就是参数服务器,这里的参数,指的是模型权重,以及中间的过程变量。
一、基本原理
以往的分布式计算,比如mapreduce的原理,是将任务和数据分配到多个节点中做并行计算,来缩短任务的执行时间。对于分布式训练来说,同样是希望将训练任务部署到多个节点上并行计算,但是因为反向传播涉及到梯度的汇总和权重的更新,相比之前的分布式计算更加复杂。也有采用hadoop或者spark的分布式训练,用单个driver或者master节点来汇总梯度及更新权重,但是受限于单节点的内存容量,支持的模型大小有限。另外,集群中运行最慢的那个worker,会拖累整个训练的迭代速度。为了解决这些问题,Parameter Server做了新的设计。
Parameter Server主要包括两类节点,一类是server节点,server节点可以有若干个,模型的权重和参数存储在这些server节点中,并在server节点中进行更新,每个server节点都存储和管理一部分模型参数,避免单个master节点内存和算力的不足,从而实现了模型的并行;另外一类是worker节点,也可以有若干个,全部训练样本均匀分配给所有worker节点,worker节点并行执行前向和后向计算,从而实现数据的并行。
worker节点主要通过pull和push这两个操作,和server节点进行通信和交互,pull和push是ps中的重要操作。在训练之前,所有server节点完成对模型权重的初始化。第一次训练,worker节点从全部server节点中,pull相应的权重,进行前后向计算得到梯度,然后把梯度push到对应的多个server节点。server节点获取到所有worker的梯度并做汇总之后,对权重进行一次更新。之后worker节点再一次进行pull和push操作,反复循环,直到worker节点跑完所有的训练数据。
每一次迭代,worker只拉取部分权重,而不需要拉取全部的权重。这是为什么?这要从广告/推荐场景的特点说起,就是特征高维稀疏。所谓高维,就是特征非常多,比如特征数量的规模可以从千万到千亿级别,单机都无法存储,需要分布式存储。所谓稀疏,就是每个训练样本用到的特征非常少,几十几百或者几千,所以每一次训练迭代,只更新了极少部分特征权重,绝大多数权重都没有更新,所以worker只需要拉取部分权重即可,不必把所有的权重都拉到本地,而且模型太大的情况下,worker也放不下。
每个server节点只存储部分权重,如果有多个worker同时用到这部分权重,那么server需要把所有worker的梯度都汇总起来,再去更新权重。而一个worker用到的权重,也可能分布在多个server上,需要从多个server做pull和push。所以worker和server在通信的时候是多对多的关系。
逻辑回归是广告/推荐场景中广泛使用的算法,论文以逻辑回归为例对算法做了描述。逻辑回归目标函数如下,包括loss和正则化这两项,一般采用L1正则化,目的是让大量权重为0,得到稀疏权重,降低线上推理复杂度。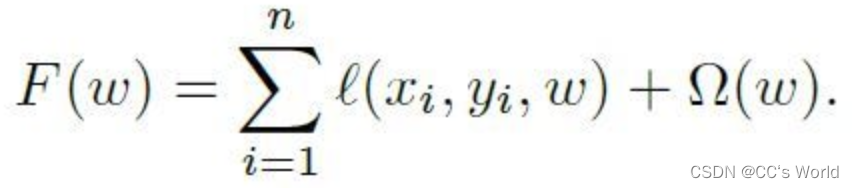
对照下图,完整的算法描述如下:
- 任务调度器:调用LoadData函数,将训练样本分配给所有worker,然后对所有worker进行若干轮迭代;
- worker节点:获取到训练数据,以及初始化权重,进行迭代;
- server节点:从所有worker获取到梯度,并进行汇总aggregate,这里是采用求和,一般求和或平均都可以,计算正则化项的梯度,对权重进行更新。

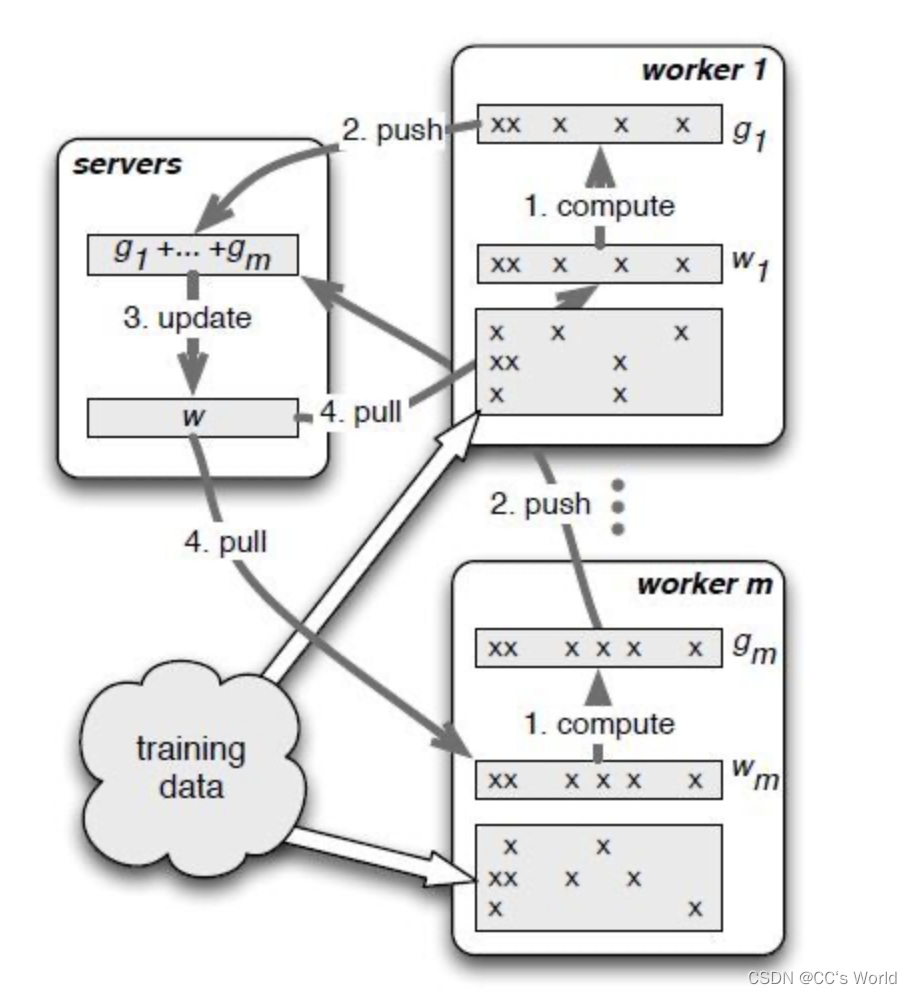
结合下图进一步说明训练过程,在训练之前先将训练样本分配到各个worker上。
- worker根据本地的训练数据和权重w,计算得到梯度g。下图worker的细节很有意思,这里有m个worker,每个worker只分配到部分训练数据,每一部分训练数据只用到了部分特征,对应也只用到了部分权重w,反向传播计算出这部分权重的梯度g。特征,权重w,梯度g,在worker中非空的列是对应的,为空的列表示该worker没有用到的特征/权重/梯度。
- 将计算好的梯度push到servers,servers进行汇总。
- 根据汇总之后的梯度,对权重进行更新。
- worker将更新之后的权重pull到本地。反复循环上述过程,直到迭代结束。
二、整体架构
论文中提出的架构下图所示。系统包括一个server group和多个worker group,server group包括一个server manager和若干个server节点,每个worker group包含一个任务调度器task scheduler和多个worker节点,worker group连接分布式文件系统,例如hdfs/s3等,获取到training data。
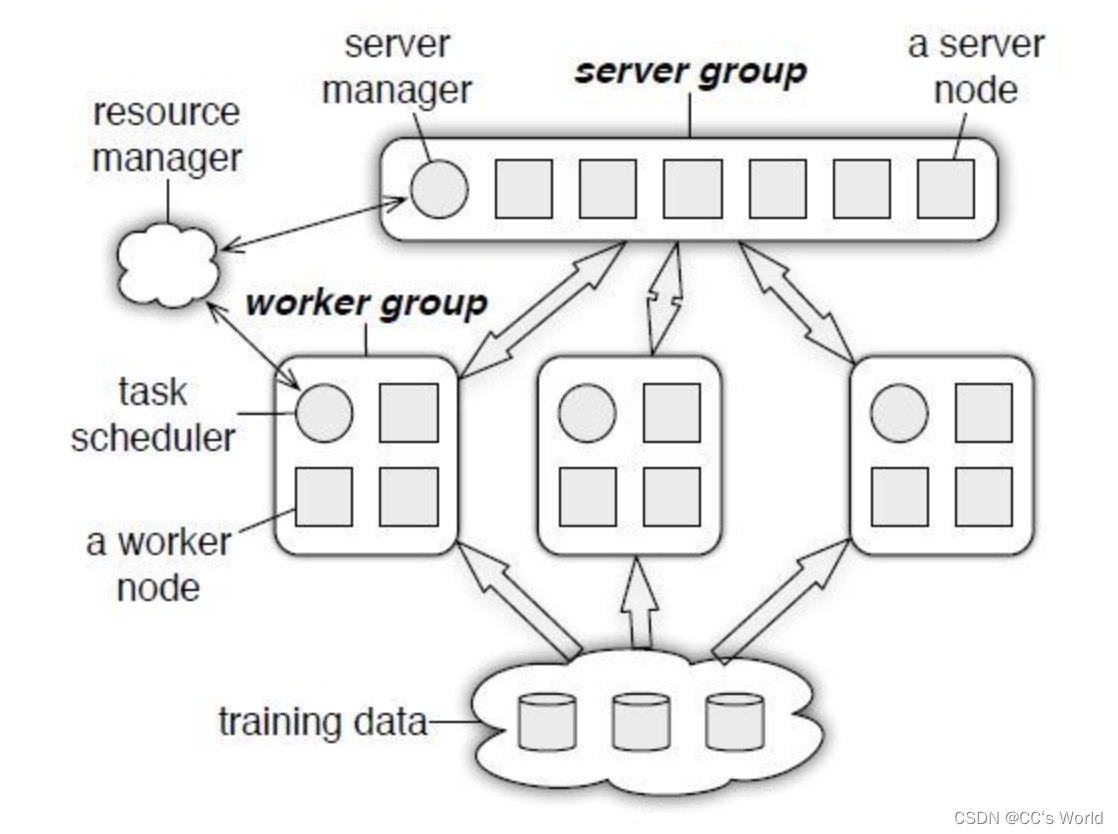
为了保证伸缩性和可靠性,server group内部的server节点之间相互通信,用于备份或者迁移参数。server manager保存和管理所有server节点的元数据,例如权重参数如何分配,以及监控节点是否正常。
worker group中,各个worker之间不需要进行通信,worker只需要与server节点通信。worker group中的任务调度器,对worker分配任务,并监控任务进度。
一个ps系统可以同时跑多个applications,一个application即一个训练任务。一个worker group是application的最小单位,即一个worker group最多只能跑一个application。而一个application可以跑在一个或者多个worker group上。application之间通过独立参数命名空间对worker group进行资源隔离。
在这个系统中,server节点和worker节点是分离的,这与目前主流的ps系统设计不太一样。
三、技术细节
3.1 哈希表和副本
server节点采用(key, value)的方式存储权重参数,例如对LR来说,key和value分别对应特征ID和权重。

3.2 动态伸缩
集群中有大量的服务器,难免会有服务器出现故障。为了保证任务持续进行不被中断,系统需要具备动态伸缩的能力,可以随时添加或者删除节点。
对于server和worker,添加和删除节点有不同的操作。可以再回顾下前面的系统架构图,这里结合架构图进行说明。添加server节点步骤如下:
- server manager给新节点分配一个key range,原来的master需要分割和删除相应的key range;
- 新节点获取到该key range的数据成为master,同时获取另外k个key range的副本数据成为slave;
- server manager广播节点的变化,其他节点基于key range的变化,释放相应的数据,并且将未完成的任务,提交到新加入的节点。
server节点删除也是类似步骤,server manager会将丢失节点的key range分配给其他节点。server manager会检查server节点的心跳,判断是否出现异常。
添加worker节点比较简单,步骤如下:
- 任务调度器给新的worker节点分配一部分训练数据;
- 新节点获取相应的训练数据,并开始进行训练;
- 任务调度器广播节点的变化,其他节点释放相应的训练数据。
3.3 异步任务和灵活一致性
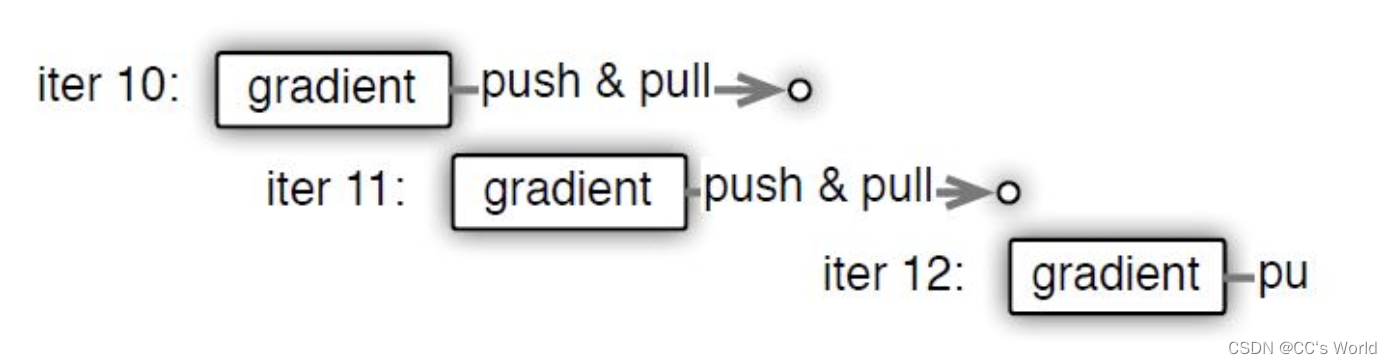
整个ps系统有很多节点,节点之间通过远程过程调用,即RPC来启动任务,例如pull或push操作等。异步任务指的是,当调用者发起远程任务之后,可以不用等到应答和任务结束,就立即执行下一步计算,下一步任务的执行不需要依赖上一步任务的完成。下图中描述了两种依赖关系,第一种,worker计算出第10次迭代的梯度之后,立即进行第11次迭代,而不需要pull新的权重过来,没有等待时间,效率较高;第二种,第12次迭代依赖第11次迭代的完成,需要等待。如果希望提高整个系统的效率,需要减少等待时间,尽可能减少任务之间的依赖。但是减少依赖可能导致数据不一致,仍以下图为例,当第10次迭代之后,立即进行第11次迭代,权重没有得到更新,这可能影响到训练任务的收敛速度。因此系统的效率和算法的收敛速度之间是一对矛盾体,需要平衡和折中。
异步训练主要是针对worker节点的,目前主流的ps系统,worker节点都是同步的,而server节点是异步的。
四、目前主流的一些ps方案
4.1 阿里的XDL
在广告/推荐/搜索场景,目前主流的模型结构是embedding+DNN,embedding部分通过训练学习到特征的表示,而DNN部分基于输入embedding来预估分数。
商业场景的数据具有高维的特点,特征数量可以从千万到百亿规模,这就导致模型的大部分参数都集中在embedding这部分,往往占据整个模型大小的99.9%以上,这对模型的存储是个挑战。数据还具有稀疏的特点,单个样本只会用到极少量的特征,所以每一次训练要从规模庞大的特征中检索出一小部分embedding。综上,embedding部分的难点在于存储和检索。DNN这部分主要是稠密计算。论文[1]基于这样的特点,对embedding+DNN的网络结构做了抽象,把embedding的部分称为Sparse Net,把DNN的部分称为Dense Net。关于Dense Net计算这部分,已有的训练框架,包括Tensorflow, Pytorch和MxNet等都已经做的很好,但是对于Sparse Net这部分,这些框架支持得不太好,所以XDL的主要工作在Sparse Net这部分。从论文[1]中了解到,在阿里的商业场景中,XDL日常支持几十亿规模的特征。
论文[1]:XDL: An Industrial Deep Learning Framework for High-dimensional Sparse Data
作为一个ps系统,XDL也包括server和worker两类节点。与上篇介绍的ps系统不同,从论文[1]的描述中,XDL中的节点既可以是物理节点,即server和worker分别部署在不同的物理机上,也可以是逻辑节点,即server和worker以进程的方式部署在同一台物理机上。后者是目前ps的主流做法,好处是减少了跨物理机之间的通信。XDL对server和worker换了个说法,server叫做Advanced Model Server(AWS),worker叫Backend Worker(BW),我们为了统一,仍然用server和worker指代。
具体架构如下图所示,从上到下依次是用户前端,提供python接口,用于给算法工程师做算法开发;server/AWS,用于存储和更新sparse net,即embedding,图中还包含了CNN/RNN网络,表示server同样可以支持CNN/RNN网络的存储和训练,我们这里忽略它;worker,获取embedding向量之后调用tf或者mxnet进行前后向计算;最下面是数据来源,可以支持多种类型的数据源,包括分布式文件系统,比如HDFS等,用来做离线训练,和流式数据源,比如Kafka等,用来做在线或实时训练。
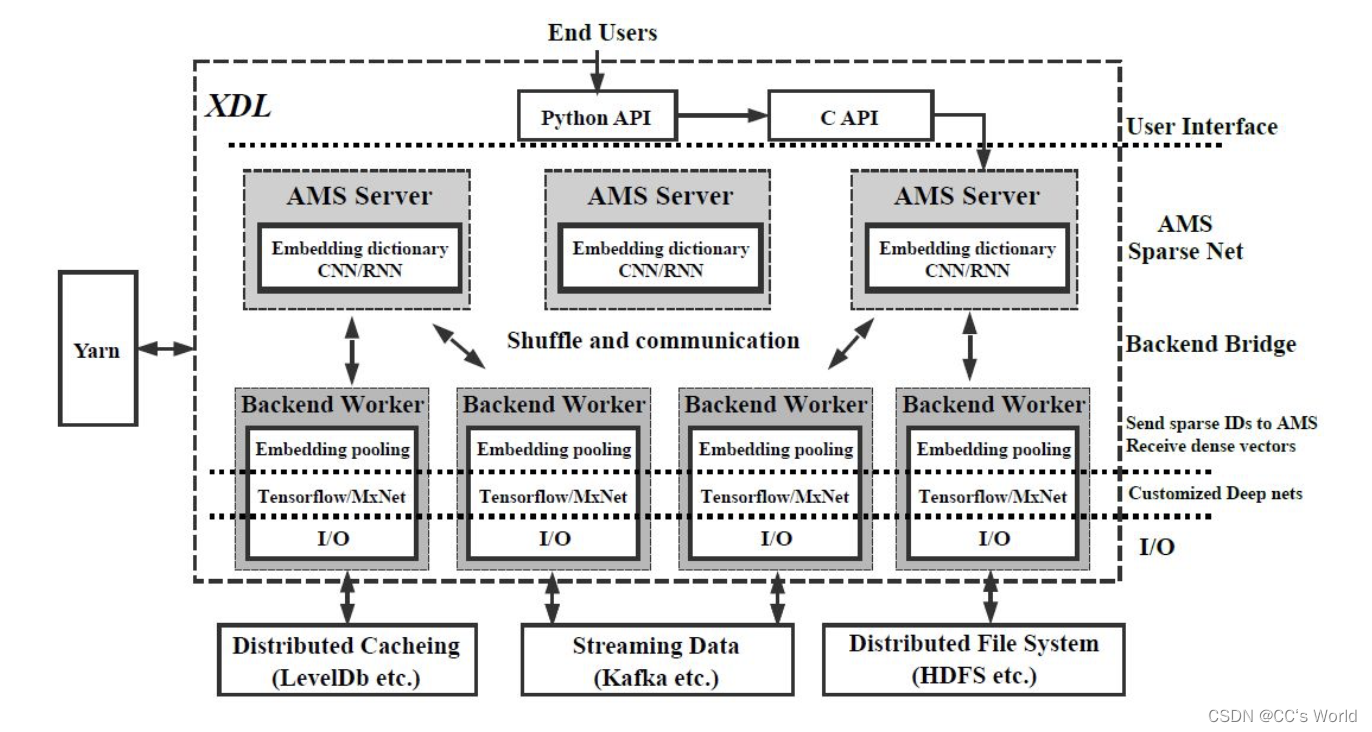
训练过程包括前向和后向计算。前向计算中,worker获取训练数据,给server发送特征ID请求,server查找对应的embedding向量并返回给worker,同时worker还要从server拉取最新的dense net,worker对embedding向量做pooling,例如求和或者平均,然后送入dense net进行计算。这部分还是worker的pull操作。后向计算,worker计算出sparse net和dense net的梯度之后发送给server,server收集到所有梯度之后,采用sgd/adagrad等各类优化算法对权重或参数做更新。这部分是worker的push操作。对于一些比较复杂的优化算法,例如,adagrad,adam等,训练过程需要累积梯度或者梯度平方项,这些累积项都存储在server中,server侧基于这些累积项和收集到的梯度,对模型权重做更新。
对于sparse net来说,因为特征规模庞大,所以需要较大的存储空间,又由于特征稀疏的特点,所以每一次只需要查找少量的embedding向量。所以sparse net具有存储大,但是I/O小的特点。dense net占用的存储空间较小,但是每一次训练需要拉取全部的参数,所以dense net对内存要求不大,但是对I/O要求很高。XDL采用不同的方式对两种网络进行管理。对于sparse net,使用hashmap做key-value存储,并且将所有的embedding向量均匀分布在各个server节点中,这对于缓解单个server节点的存储压力和通信都有帮助。dense net同样也均匀分割到所有server节点中。
在生产环境中容错是必不可少的,否则如果机器出现故障导致从头开始训练,会带来时间和资源的浪费。在训练过程中,server会保存模型的快照,可以理解为checkpoint。调度器会根据心跳来监控server的状态,如果检查到server出现异常,任务就会中断,等到server恢复正常后,调度器会通知server加载最近一次的快照继续训练。对于worker来说,训练过程中所有worker会把数据的读取状态上传到server中,如果worker失败之后恢复正常,worker会从server请求读取状态,在数据中断的地方继续训练,这样可以避免样本丢失,或者重复训练等问题。相比上篇中ps系统的动态伸缩容错,XDL的容错比较简单,减少了系统的复杂度。
XDL同时支持同步和异步训练。同步训练,每一轮迭代所有worker都要保持同步,每个worker只进行一次前向和后向计算,server收集所有worker的梯度求平均并更新参数,然后进行下一轮迭代。对于同步训练,每一次迭代的训练速度,取决于整个系统中最慢的worker和最慢的server。异步训练,每个worker各自进行前后向计算,不需要等待其他worker,持续地进行迭代。而在server侧, 只要有worker push新的梯度过来,就会更新参数。这会出现啥情况呢?当某个worker进行前后向计算的时候,用的参数是 w t 1 w_{t1} wt1, 计算出梯度 g t 1 g_{t1} gt1 并且push到server之后,server此时的参数已经被其他worker更新为 w t 2 w_{t2} wt2,server只能用 g t 1 g_{t1} gt1 对 w t 2 w_{t2} wt2 做更新。所以异步训练会存在数据不一致的问题,这会对模型的收敛造成影响。不过对于sparse net影响较小,因为样本特征稀疏,每个worker更新不同的特征,冲突率较低,而对于dense net影响较大,因为每一次迭代需要用到全部dense net。不过实践发现,异步训练可以带来吞吐率的较大提升,而对模型精度损失很小,目前异步训练也是主流的ps训练方式。
【特征准入和淘汰】
商业场景中,时时刻刻都会有新的样本产生,新的样本带来新的特征。有一些特征出现频次较低,如果全部加入到模型中,一方面对内存来说是个挑战,另外一方面,低频特征会带来过拟合。因此XDL针对这样的数据特点,提供了一些特征准入机制,包括基于概率进行过滤,布隆过滤器等。
有一些特征长时间不更新会失效。为了缓解内存压力,提高模型的时效性,需要淘汰过时的特征,XDL支持算法开发者,通过写用户自定义函数(UDF)的方式,制定淘汰规则
4.2 360的TensorNet
该系统是针对tensorflow开发的轻量ps系统,支持tf2.2及以后的版本。TensorNet能支持到百亿特征规模,支持同步训练和异步训练,不过目前开源出来的版本只支持异步训练,同步训练版本还在优化当中。
原生 Tensorflow支持的embedding数量有限,大约只能支持到千万级别的特征规模,无法满足商业场景中大规模特征的需求。TensorNet采用和XDL类似的技术,通过桥接将sparse net的存储和dense net的计算做了分离。
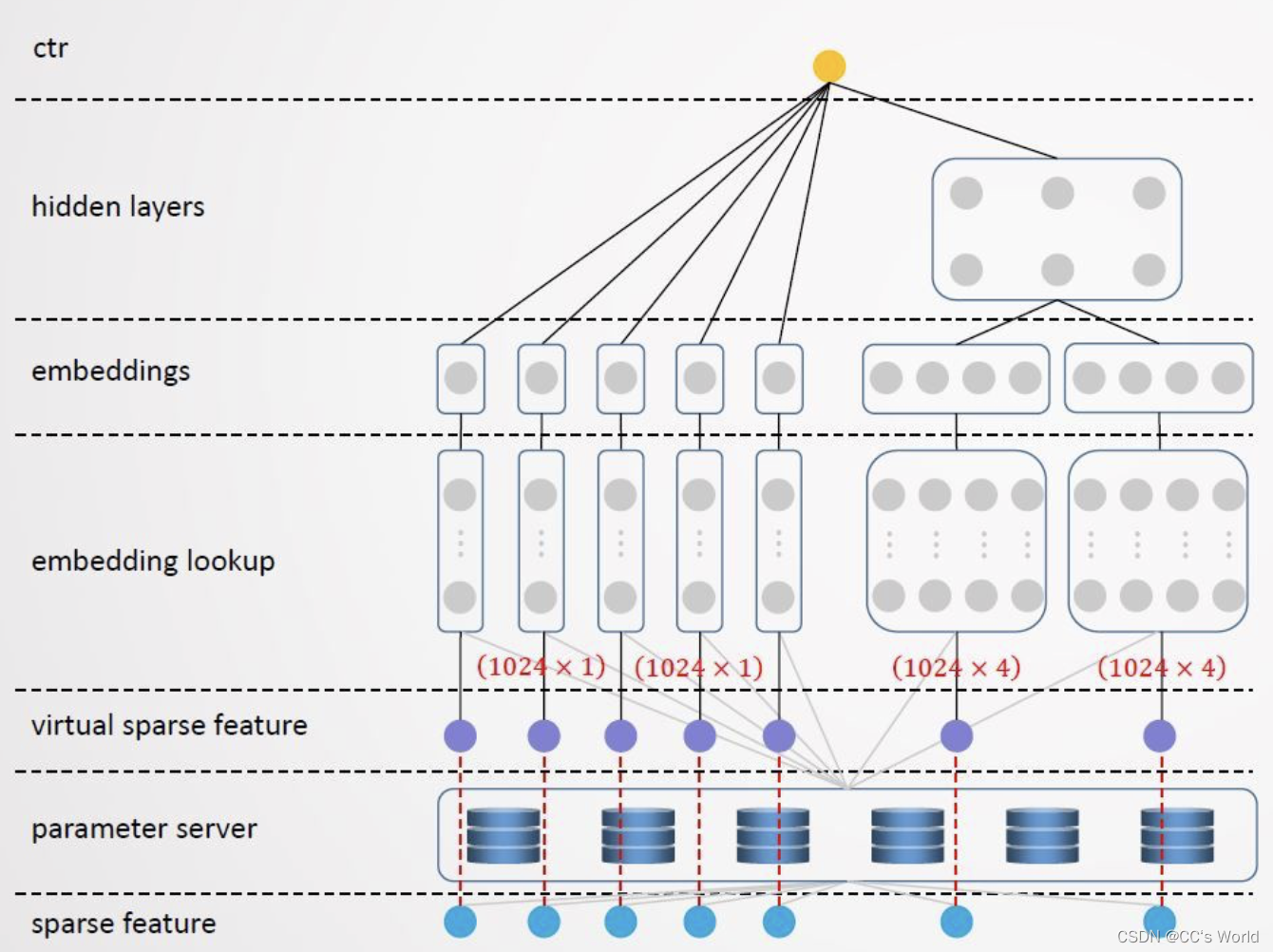
实现原理如下图所示。训练的batch_size=1024,在进行前向计算之前,TensorNet将每个batch的特征ID从0开始重新编排作为输入,这样输入特征的index分布在[0,1024)之间;同时根据原始的特征ID从server拉取对应的embedding向量,填充到tensorflow的embedding矩阵中,这样每个特征field/slot的embedding矩阵大小就只有1024 x 4(以下图中embedding_size=4为例)。对于tensorflow来说,每次迭代只需要在1024 x 4这样非常小的embedding矩阵中做查找。dense网络地计算则完全依赖tensorflow实现,可以基于tensorflow构造各种复杂的网络结构,例如Transformer/Attention/CNN/RNN等,保留了tensorflow设计网络结构的灵活性。
下图以wide&deep模型为例,结合下图做进一步说明,我们从最下层往上看。最下面的sparse feature,输入的是原始的特征ID,从sparse feature到virtual sparse feature,将原始特征ID映射为新的index,范围在[0, 1024)。倒数第二层的parameter server节点,保存全部特征的embedding,TensorNet根据原始特征ID从server拉取对应的embedding,填充至倒数第四层的embedding矩阵中。通过这种方式,将图中从sparse feature到parameter server的查找,转换为从virtual sparse feature到embedding lookup这部分的查找,对tensorflow来说,相当于在一个1024 x 4的embedding矩阵上做查找。之后,从virtual sparse feature一直到最顶层的ctr预估,都由tensorflow来完成。
参考资料
边栏推荐
- 2022年流动式起重机司机考试题库及模拟考试
- 风控模型启用前的最后一道工序,80%的童鞋在这都踩坑
- [vite] 1371 - develop vite plug-ins by hand
- C#实现获取DevExpress中GridView表格进行过滤或排序后的数据
- 关于 “原型” 的那些事你真的理解了吗?【上篇】
- Go project practice - parameter binding, type conversion
- PWA (Progressive Web App)
- 小程序框架Taro
- Use bat command to launch common browsers with one click
- Based on shengteng AI Aibi intelligence, we launched a digital solution for bank outlets to achieve full digital coverage of information from headquarters to outlets
猜你喜欢

第五届 Polkadot Hackathon 创业大赛全程回顾,获胜项目揭秘!
Some understandings of heterogeneous graphs in DGL and the usage of heterogeneous graph convolution heterographconv

About the use of Vray 5.2 (self research notes)

In the year of "mutual entanglement" of mobile phone manufacturers, the "machine sea tactics" failed, and the "slow pace" playing method rose
关于vray 5.2的使用(自研笔记)
32: Chapter 3: development of pass service: 15: Browser storage media, introduction; (cookie,Session Storage,Local Storage)
Comparative learning in the period of "arms race"

Broyage · fusion | savoir que le site officiel de chuangyu mobile end est en ligne et commencer le voyage de sécurité numérique!

2022鹏城杯web
Blockbuster: the domestic IDE is released, developed by Alibaba, and is completely open source!
随机推荐
Node の MongoDB Driver
Web3基金会「Grant计划」赋能开发者,盘点四大成功项目
微信核酸检测预约小程序系统毕业设计毕设(7)中期检查报告
Bidirectional RNN and stacked bidirectional RNN
PWA (Progressive Web App)
9、 Disk management
Taro advanced
2022鹏城杯web
【tcp】服务器上tcp连接状态json形式输出
MFC宠物商店信息管理系统
C语言活期储蓄账户管理系统
Implementation of wechat applet bottom loading and pull-down refresh
Implement the rising edge in C #, and simulate the PLC environment to verify the difference between if statement using the rising edge and not using the rising edge
Golang应用专题 - channel
流程控制、
Array
基于昇腾AI丨以萨技术推出视频图像全目标结构化解决方案,达到业界领先水平
QT implements JSON parsing
iframe
LDAP概述