This article follows on from the last one :
The comparative study of the gods in the twilight age
If there is any mistake , Please criticize and correct me .
Looking at this piece reminds me of GPT and BERT. At that time GPT Just come out , Amazing , Although the pre training model and fine-tuning are done with unlabeled data . so what BERT It's coming out. , The language model is trained with a larger data set and a larger model . And also wrote in the paper “ We made two models , One bert base, One bert large, do bert base Why . It's about talking to GPT Compare .”

Can you bear this once it comes out . therefore GPT I made one GPT-2. Make a larger language model with a larger data set .
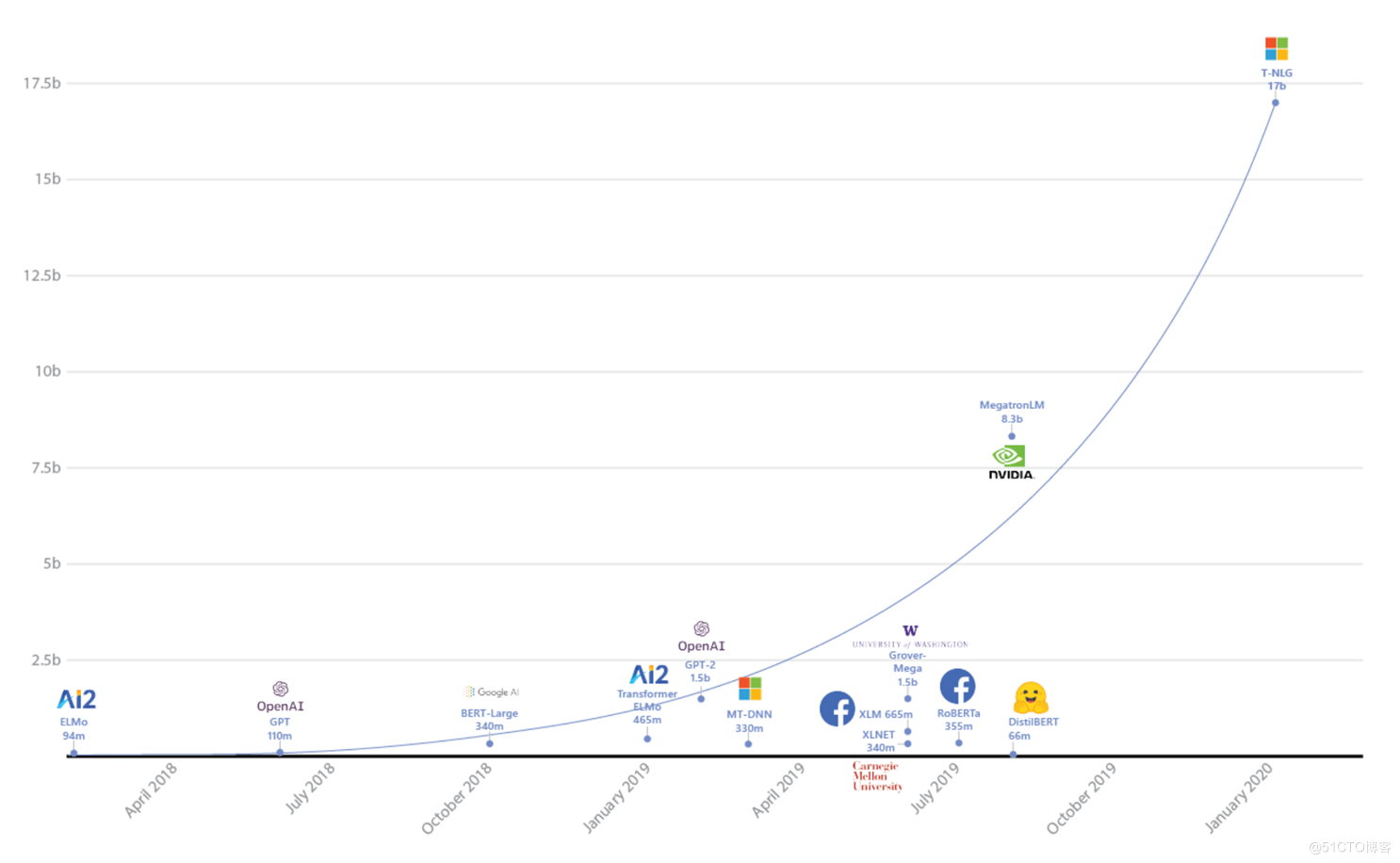
From then on NLP The pre training model in the field has a trend of becoming bigger and bigger . Each family began to develop large pre training models . But this trend has stopped recently , We found that big is not necessarily effective . Start focusing on small and beautiful models . The "small" here does not mean to make the model smaller and smaller , But the model volume is moderate , But it can achieve better results .
The following figure comes from :
Turing-NLG: A 17-billion-parameter language model by Microsoft - Microsoft Research
Then let's talk about the protagonist today . This is for MoCo and SimCLR Two families , The two families compare with each other . But the atmosphere is better than NLP Much more harmonious . The leaders of the two families quote each other , Learn from each other . The style of writing is not that I have to step on you , It means that we learn from the experience of others .
Let's take a look at this today 4 Papers :
MoCo v1
Address of thesis :
[1911.05722] Momentum Contrast for Unsupervised Visual Representation Learning (arxiv.org)
Code address :
facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722 (github.com)

One day Facebook I want to make something , You could view it as instDisc^[
[1805.01978] Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination (arxiv.org)
] Improved version . They have simply and effectively improved the previous article . And the thesis is also very well written . It is written from the top down . No certain writing skills , It is impossible to achieve such an effect .
MoCo Its main contribution is to summarize the previous methods of comparative learning into a dictionary query problem . He used memory bank Instead of storage, we use queues to store the information we have learned . A momentum encoder is also proposed . This forms a large and consistent Dictionary , Can help better comparative learning .
Its design and instDisc Almost exactly , First of all, from a model point of view , Both working models use ResNet-50. The dimension is reduced to 128 dimension . The vector after dimensionality reduction is done once
normalization , The data enhancement methods are almost borrowed from the past , The later learning rate 0.03, Training 200 individual epochs These are also related to InstDisc bring into correspondence with . The objective function is also used .InstDisc It uses NCE loss,MoCo It uses infoNCE loss.
SimCLR
Address of thesis :
[2002.05709] A Simple Framework for Contrastive Learning of Visual Representations (arxiv.org)

Look at the list of authors .Hinton Your name appears here , Almost blinded me .
This method is simple and effective . Although the complex method looks very good , But it's not that we don't like simple methods , But like effective methods .SimCLR That's it Simple.
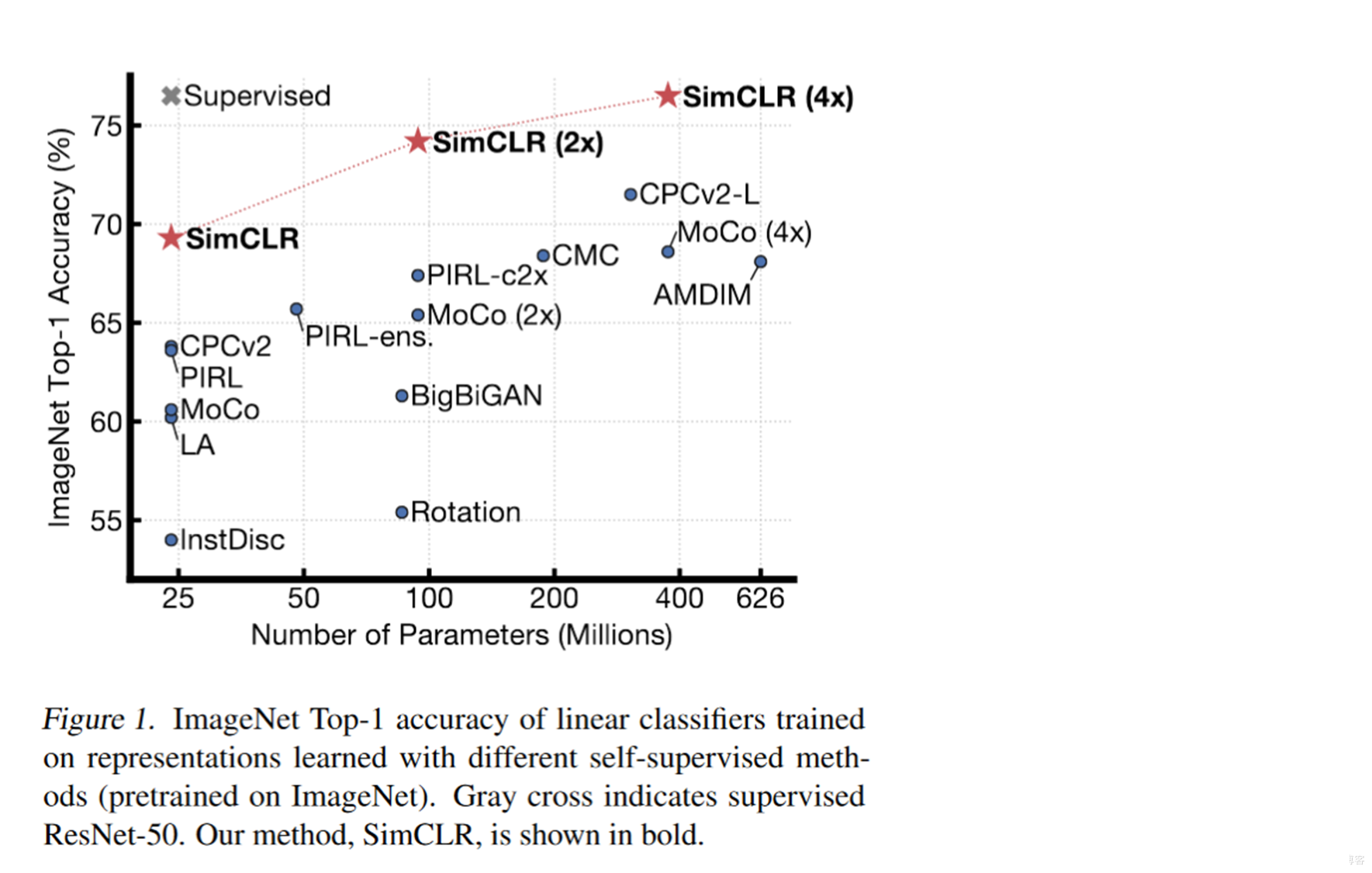
Just say it works , So how effective it is . Take a look at the following picture . The author has put networks of different sizes here . We can see SimCLR The effect can be said to be a unique ride . But it has a little problem , It's its batch size Set it big , Ordinary machines can't run . So it's not good for ordinary people to want to repeat it .
Then let's take a look at how it is designed . Do you remember the one we talked about before InvaSpread^[
[1904.03436] Unsupervised Embedding Learning via Invariant and Spreading Instance Feature (arxiv.org)
]. This work can be regarded as an improvement of the above work . We mentioned earlier that the job is relatively poor , No, tpu, The quantity version is set less . And the method of quality expansion is also relatively simple , So it didn't get a particularly amazing effect . however SimCLR Mingming seems to come down in one continuous line with him , Why did you suddenly make a circle . Because this work has been done very well .
Let's take a look at how it is designed . Here it is extracting a mini batch As x. Respectively for x Use different augmentation methods for data augmentation , obtain
and
. And then put
and
Feed to a twin network . These two encoders
Are shared parameters , We can think of it as the same encoder , After encoding, the representation vector is obtained
, Here's the difference , stay
There's a... In the back MLP, become
, Then use
To do comparative study .
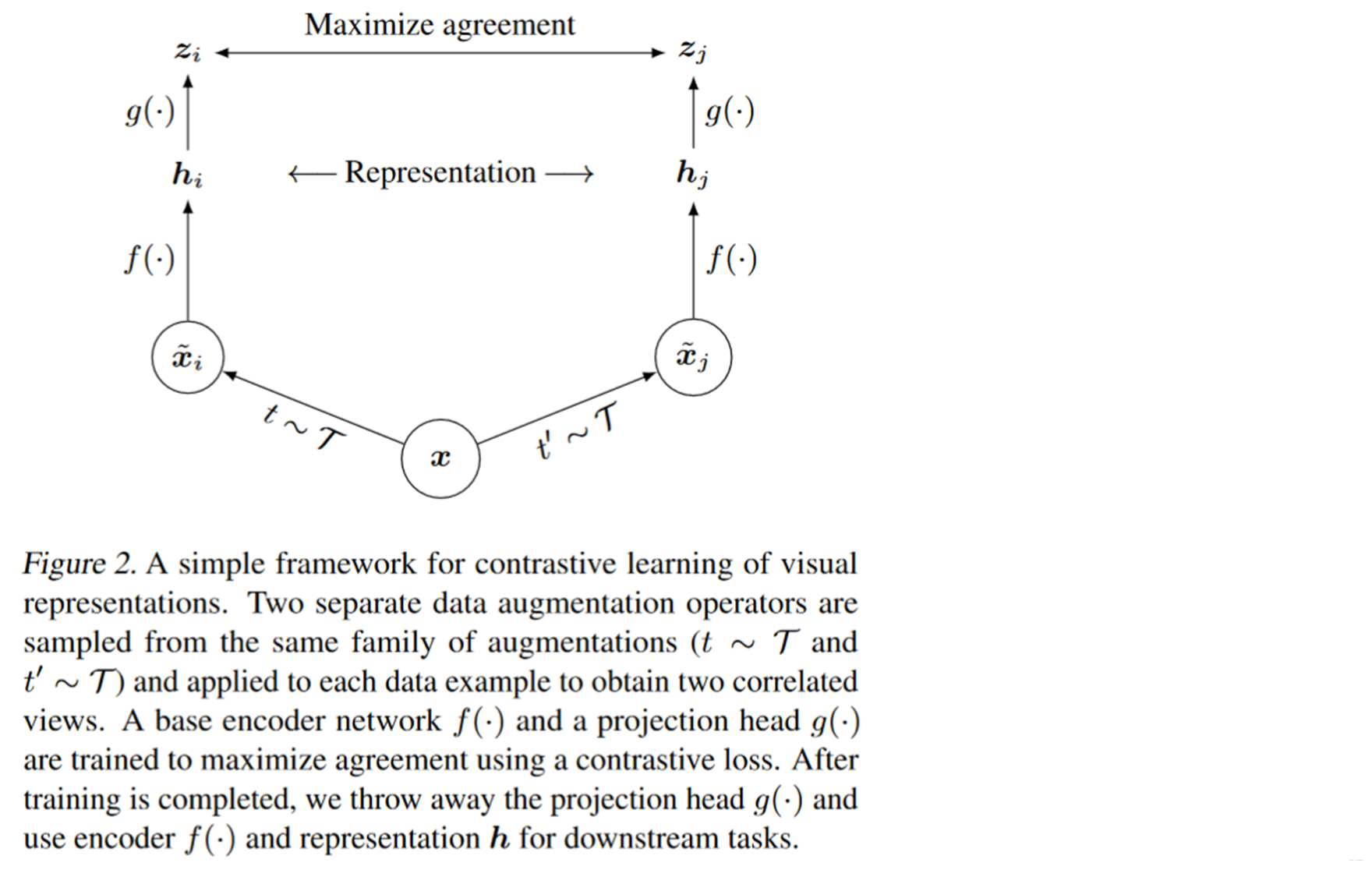
If it is represented by a model diagram :
InvaSpread:
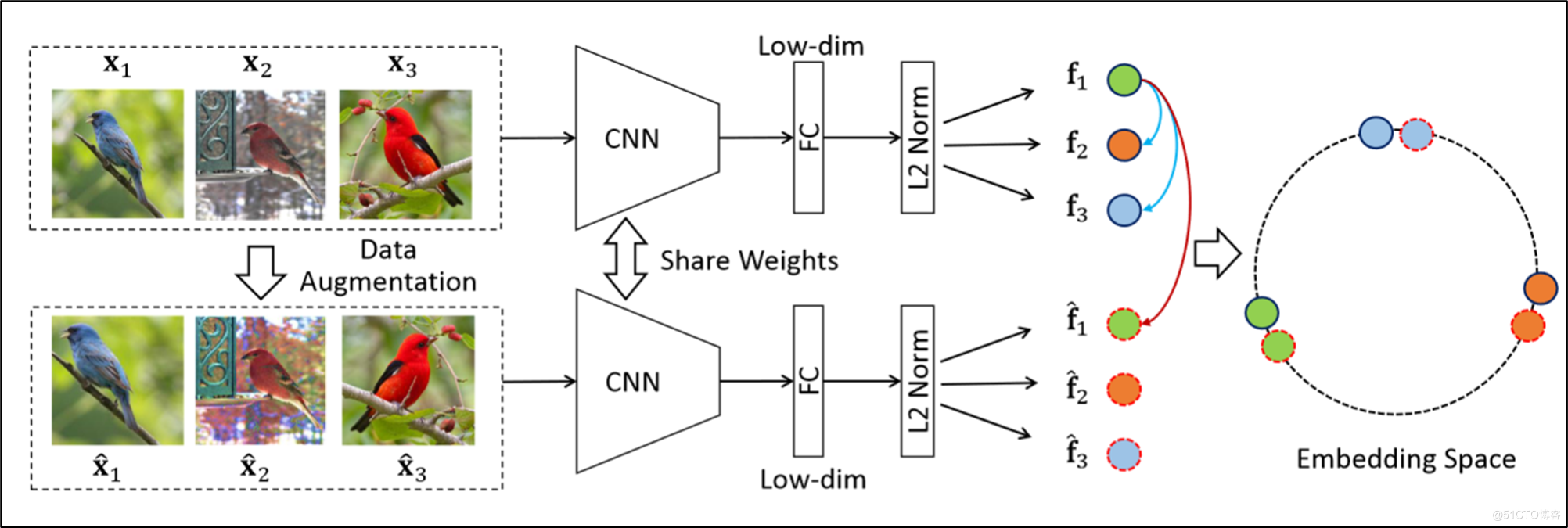
He is throwing the original picture into a twin network , Then throw the expanded image into another part of the twin network .
SimCLR:
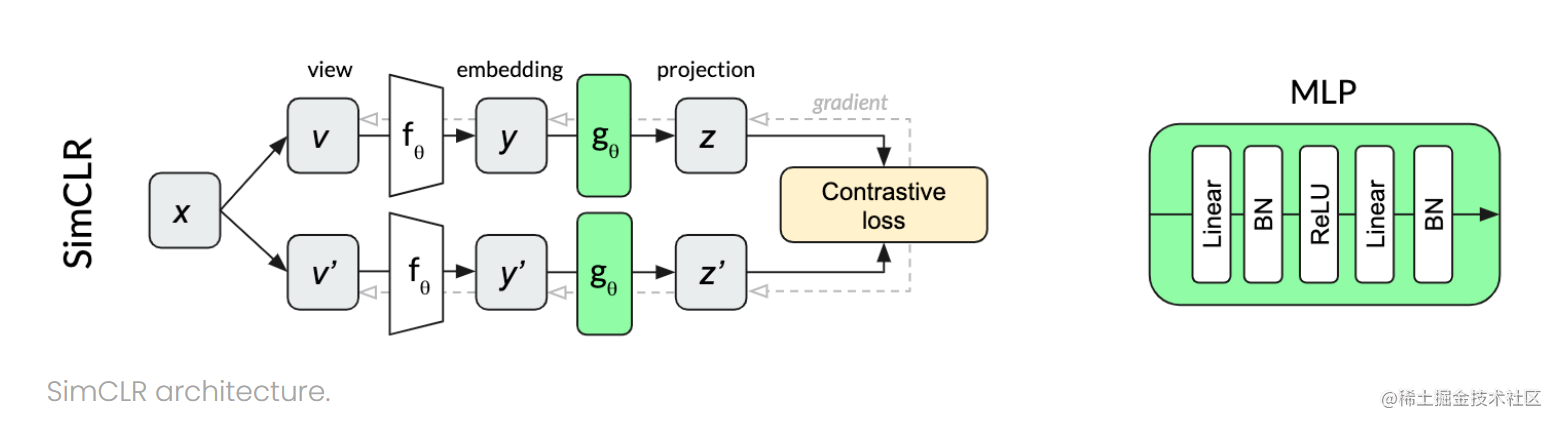
Here is to throw two augmented data into the network , Finally, there will be a MLP. In fact, it is a linear layer plus a ReLu Activation function .
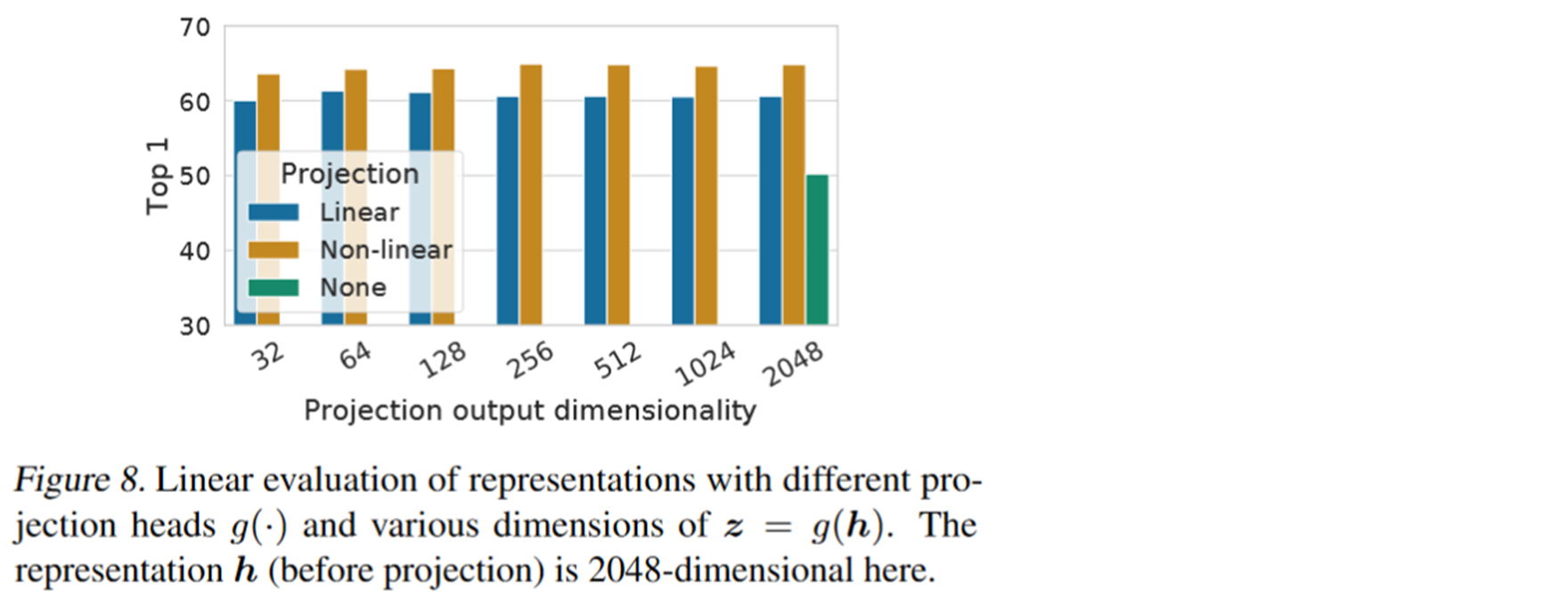
The result was directly mentioned 10 percentage . So the author himself is surprised , Why is there such a good effect . Many experiments have been done for this purpose . The green block in the following figure is not added MLP When , Blue is added with a linear layer , But when the activation function is not used . Yellow is a linear layer , And when using the activation function .
We can see add one MLP It really has obvious effect .
We said earlier that because the above work is a single data augmentation method . No effective data growth mode has been found , So here SimCLR Many comparative experiments have also been done .

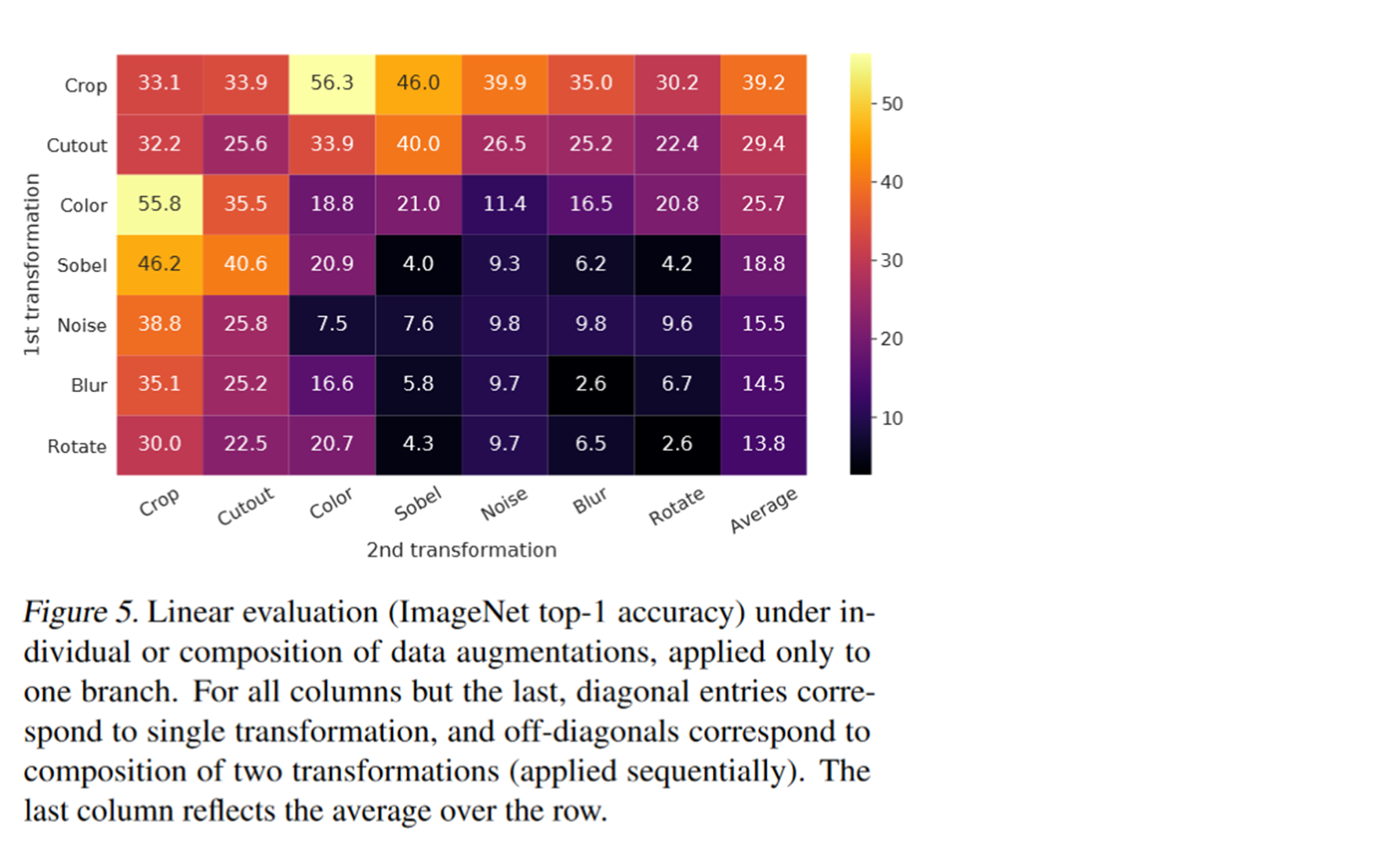
For example, partial cropping of the picture . Convert the picture . Change the color of the picture , Change the saturation of the picture . Cut out a piece of the picture . Or use different Gaussian noises . If you look at the picture here, you should use the maximum and minimum filters . At last, a few sobel Sharpen the filter .
The final result is as follows . We can see that the two yellow boxes have the highest scores . That is, use at the same time crop and color When . Therefore, these two data expansion methods are selected in this case .
Finally, let's talk about the selection method of positive and negative samples . If you look at the InvaSpread It should be easy to guess what double sample and negative sample selection methods he used . Different enhancement methods of the same image as positive samples . The enhancement of other pictures is taken as negative samples . It's also a mini batch The number of pictures in is N, Then there will be two positive samples and 2N-2 Negative samples .
And here we can see , Compared with previous work , It does not use an extra space to store information . There is only one encoder , It's not necessary memory bank, There is no need for queues and momentum encoders . The positive and negative samples are all from the same mini-batch From inside . The whole forward process is very direct , That is, the picture is encoded by the encoder and then the dimension is reduced , One more pass MLP, Finally, it is a comparative study loss. Simple, violent and effective . It's very popular .
MoCo v2
Address of thesis :
[2003.04297] Improved Baselines with Momentum Contrastive Learning (arxiv.org)

It is amazing to see the effect of the above work ,MoCo The author also moved his mind . He found that uh huh .SimCLR Some of the practices in are plug and play , Just move in as you like . So he went straight to MoCo I have learned from .
Then he put forward MoCo v2, This is not really a paper , It has only two pages as a technical report . You can think of it as the update instructions given to users after the software is updated . He has improved a total of 4 In terms of :
The following picture shows some of their improvements .
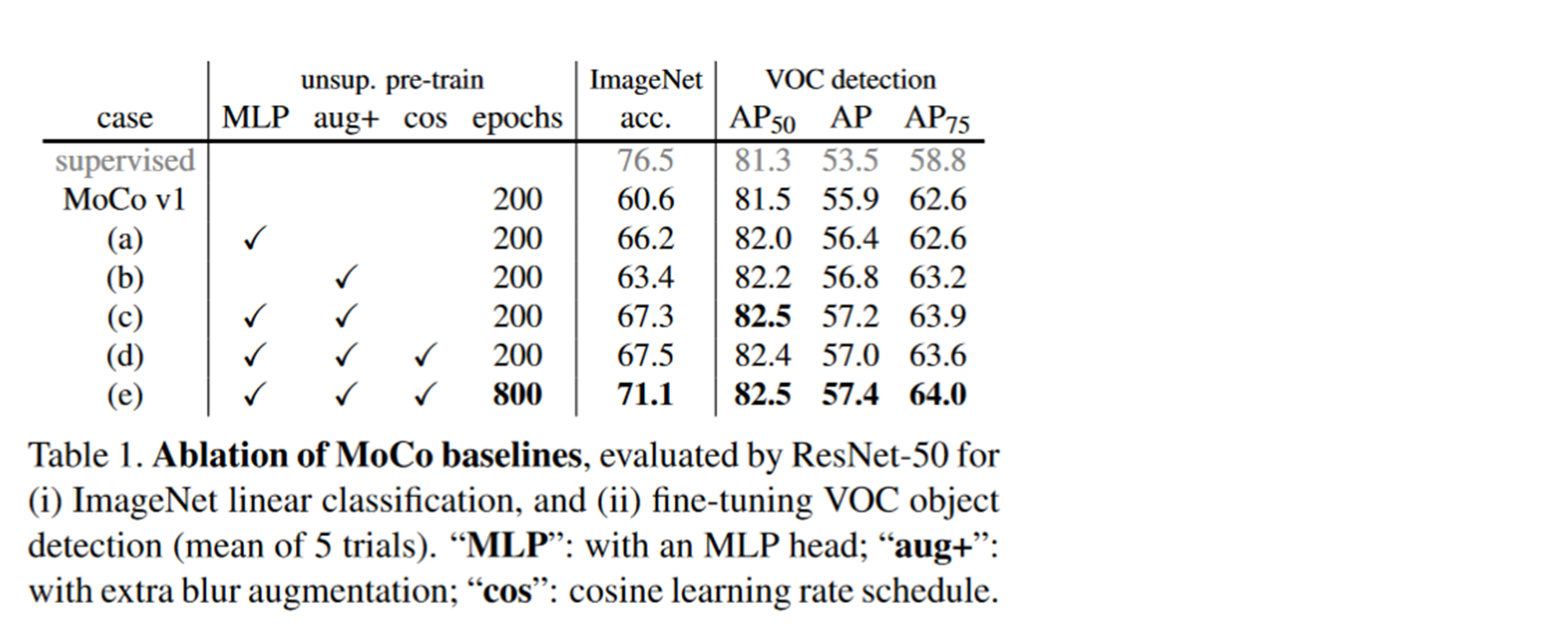
experiment A Yes, just add one MLP. experiment B Is the use of a richer data growth approach . experiment C yes MLP Used with data augmentation . experiment D It's increased cosine Of learning rate schedule. Being willing increases the training epoch. We can see that there has been a significant improvement .
That's with SimCLR Compare the :
Take a look at table 2 first :
The top half of Table 2 is running 200 individual epochs, But I tried different batch size. We can see simCLR Only in mini batch The effect will be better when it is very big , But the effect is not as good as MoCo v2. The lower part of Table 2 is simCLR Set a relatively large batch size. Lengthen the training epochs. We can see or simCLR better .
Table 3 shows the cost of calculation ,simCLR Less computing resources .
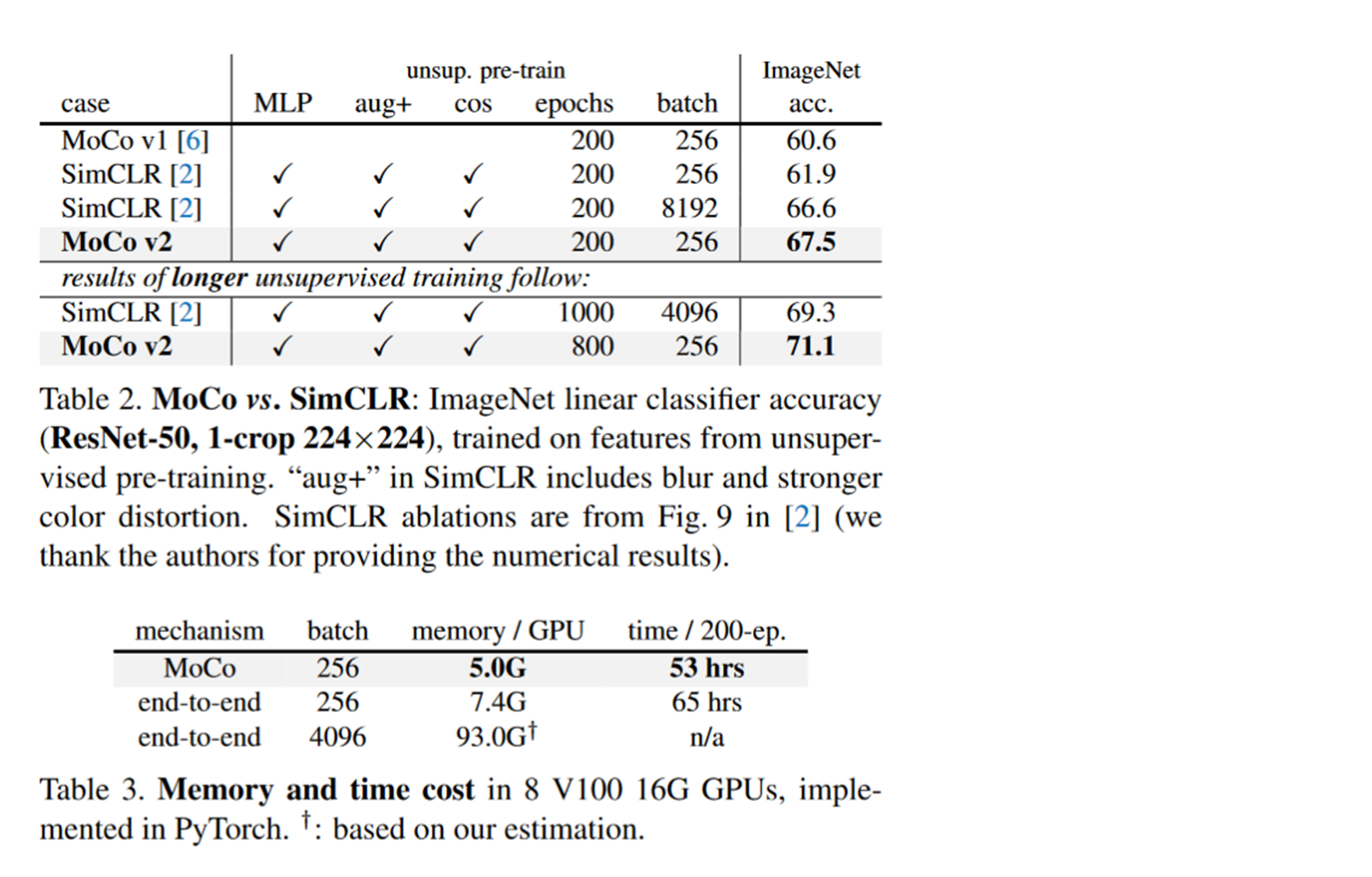
Comprehensive comparison shows that MoCo v2 better , And take the civilian route , It is more suitable for ordinary people to reproduce and use .
Here I would like to add a little bit of my personal thinking . be relative to BERT and GDP The arms race , So far ,GDP What we do is to make the model bigger and bigger , however BERT Compared with its variants, the model is still relatively small . So that's what I said earlier BERT It's a civilian route , Small and beautiful . I feel moco This is the same way here .
SimCLR v2
Address of thesis :
[2006.10029] Big Self-Supervised Models are Strong Semi-Supervised Learners (arxiv.org)

SimCLR v2, It is only a small part of this paper , It just says how to get from v1 Change to v2, It is an improvement on the model , In fact, they are all talking about how to do semi supervised learning . Namely SimCLR v2 They have shown a great style , He said I was too lazy to fight back , I went on with my work , I just made a little improvement . This model is only a small part of my work . It's mainly about
A very large self supervised training model is very suitable for semi supervised learning
.
Let's take a look at his supervised learning . He first worked out with unsupervised training SimCLR v2. Then fine tune the model using some labeled data , Apply to downstream tasks .
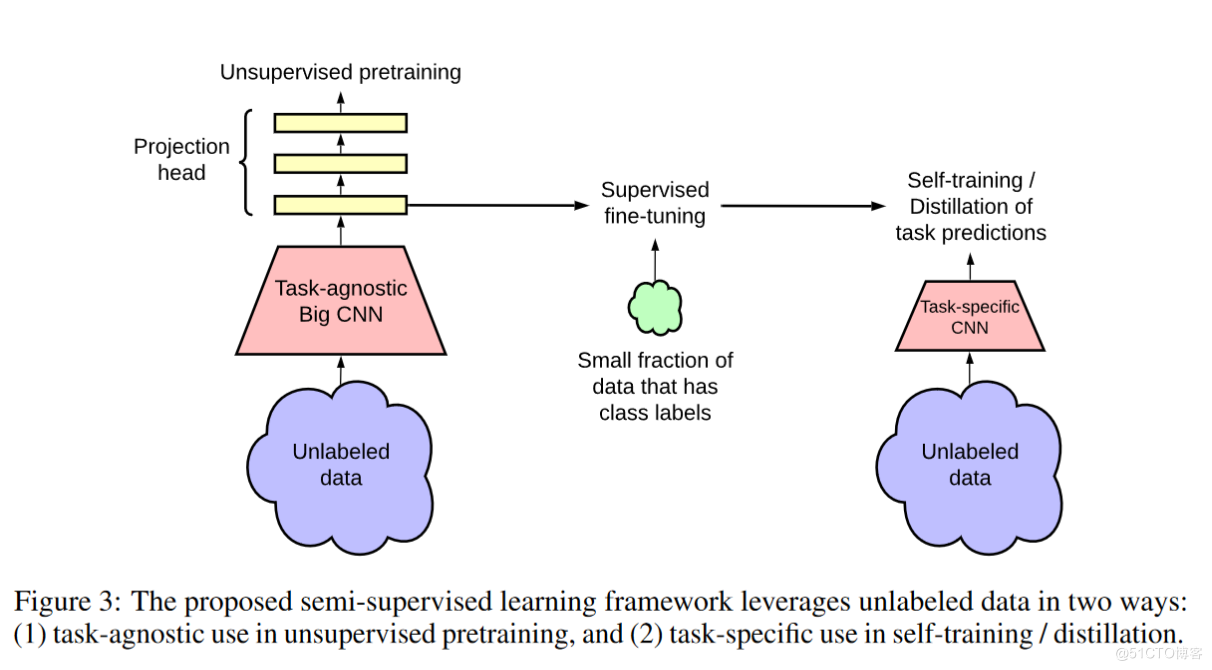
Here the author also spent twoorthree pages to introduce SimCLR v1 How did it become SimCLR v2 Of .
First, a larger model was used . another 152 Layer residual network selective kernels, That is to say SK net, The backbone network has become very strong .
Before SimCLR say mlp Layer useful , and MoCo v2 It also proved particularly useful , therefore SimCLR The author thinks that this layer is so useful , Would it be more useful to make it a little deeper , So it tried to change from two layers to three layers. Will the performance continue to improve . Of course, it is found that two layers are enough through experiments , So in this article, a two-tier MLP. It turned out to be a linear layer plus ReLu The activation function of becomes Linear layer +ReLu+ Linear layer +ReLu.
Finally, they also used a momentum encoder .
If you don't count the content of semi supervised learning ,SimCLR v2 Also a 2 Page technical report .
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/186/202207051000464271.html