这篇文章是接着上一篇讲的:
如果有什么漏误,请大家批评指正。
看这一块的时候让我回想起了GPT和BERT。那个时候GPT刚出来,惊为天人,虽然用无标签数据做出来了预训练模型加微调的事情。然后呢BERT就出来了,用更大的数据集更大的模型训练了语言模型。并且还在论文中写的“我们做了两个模型,一个bert base,一个bert large,做bert base的原因。就是要和GPT比较。”

这话一出来你能忍吗。所以GPT啪就做了一个GPT-2。用更更大的数据集做出来一个更更大的语言模型。
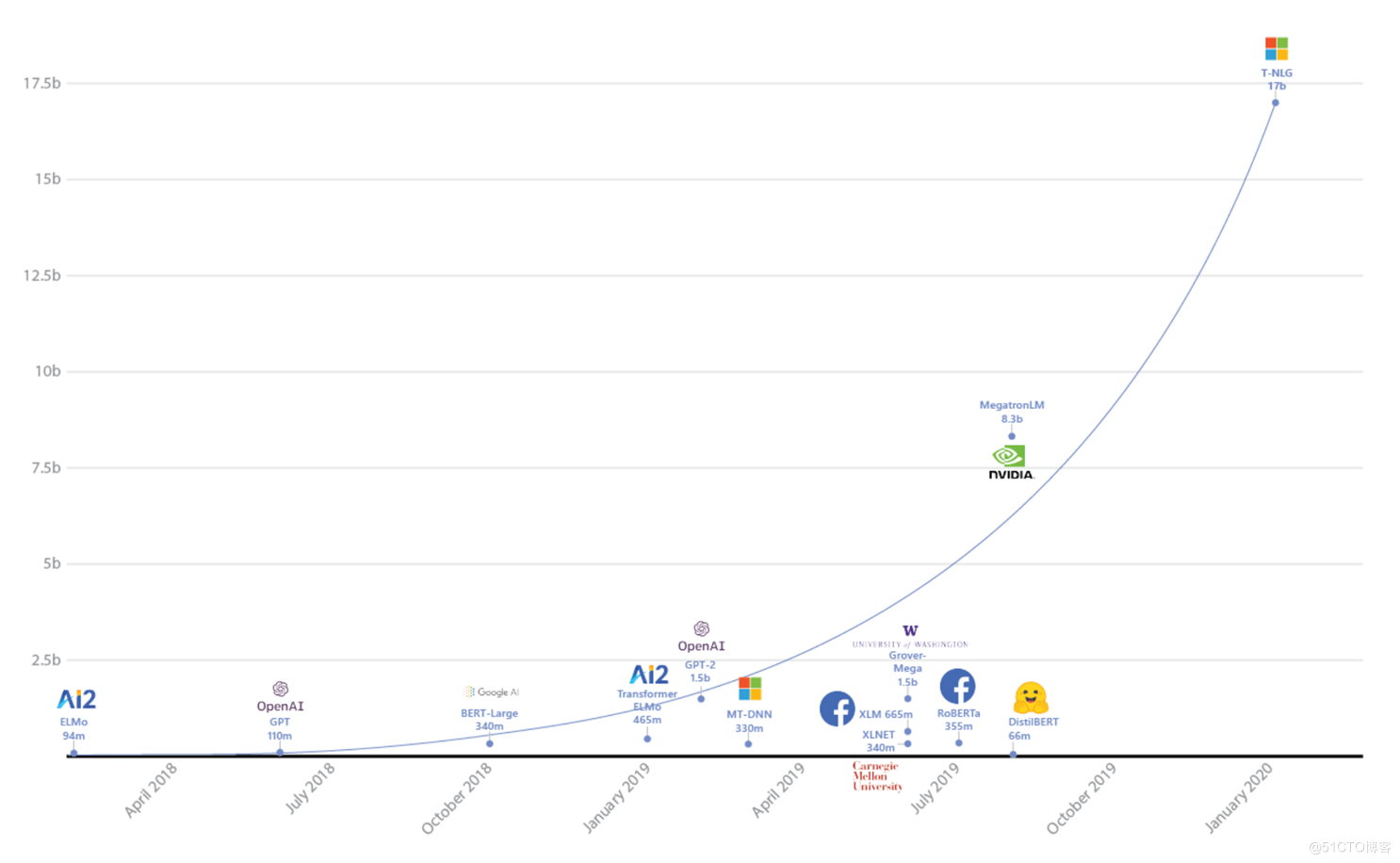
从那之后NLP领域的预训练模型就有着越做越大的趋势。各家都开始搞大的预训练模型。不过最近这个趋势已经收住了,大家发现大并不一定有效。开始专注于小而美的模型了。这里的小不是指把模型越做越小,而是模型体量适中,但是能取得更好的效果。
下图来自:
Turing-NLG: A 17-billion-parameter language model by Microsoft - Microsoft Research
然后再说一下今天要说的主角。这个是针对MoCo和SimCLR两家的,这两家互相比较。但是氛围却比NLP和谐多了。两家的大佬互相引用,互相借鉴。论文的文风也不是我一定要踩你一脚,而是说我们借鉴了谁谁谁的经验。
今天就来看一下这4篇论文:
MoCo v1
论文地址:
[1911.05722] Momentum Contrast for Unsupervised Visual Representation Learning (arxiv.org)
代码地址:
facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722 (github.com)

有一天呢 Facebook想做了一个东西,可以把它看成instDisc^[
[1805.01978] Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination (arxiv.org)
]的改进版。他们简单而有效的改进了前面这篇文章。并且论文也写得特别好。采用的是自顶向下的写作方式。没有一定的写作功底,是达不到这样的效果的。
MoCo 的主要贡献就是把之前对比学习的一些方法都归纳总结成了一个字典查询的问题。他把之前用memory bank存储改为了用队列咱存储所学到的信息。还提出了动量编码器。这样形成一个又大又一致的字典,能帮助更好的对比学习。
它的设计方式和instDisc几乎完全一样,首先从模型的角度上来说,两个工作的模型使用的都是ResNet-50。降维的时候也都是降到了128维度。降维之后的向量都做了一次
归一化,数据增强方式也差不多是借鉴过来的,后面的学习率0.03,训练200个epochs这些也都是跟InstDisc保持一致。使用了目标函数也差不多。InstDisc使用的是NCE loss,MoCo使用的是infoNCE loss。
SimCLR
论文地址:
[2002.05709] A Simple Framework for Contrastive Learning of Visual Representations (arxiv.org)

看一下作者列表。Hinton的名字出现在这里,差点闪瞎了我。
这个方法呢简单有效。虽然复杂的方法看起来非常牛,但是大家也不是不喜欢简单的方法,而是喜欢有效的方法。SimCLR就做到了Simple。
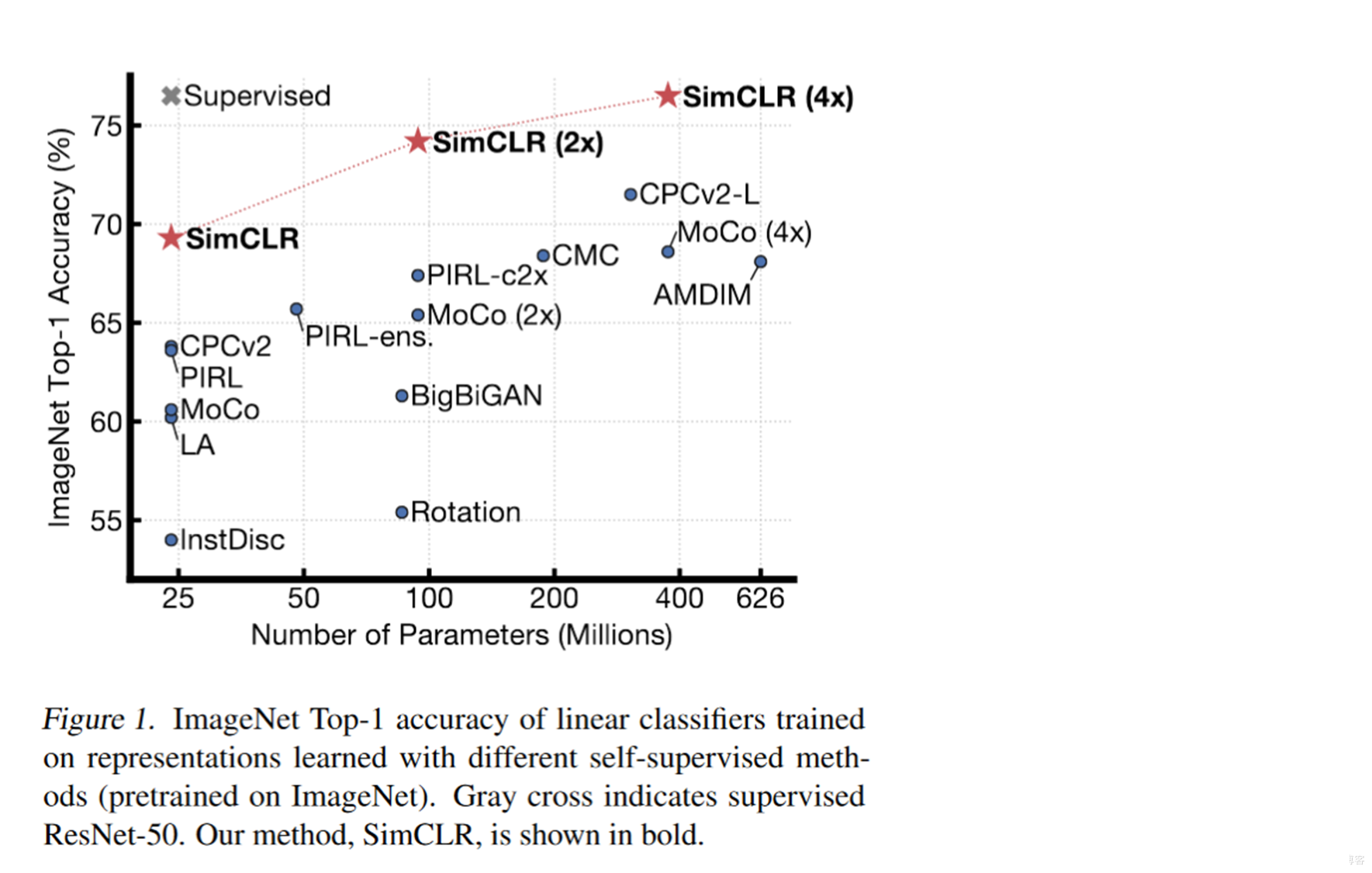
光说它有效,所以它是多有效。呢看一下下面这张图。作者在这里放了不同大小的网络。我们可以看到SimCLR的效果可以说是一骑绝尘。但是它存在一点点问题,就是它的batch size设置的比较大,一般的机器是跑不起来的。所以你普通人想复现一下不太行。
然后我们再来看一下它是怎么设计的。还记不记得之前我们讲的那个InvaSpread^[
[1904.03436] Unsupervised Embedding Learning via Invariant and Spreading Instance Feature (arxiv.org)
]。这个工作可以认为是上面这个工作的改进吧。我们前面提到了那个工作比较穷,没有tpu,数量版设置的比较少。并且素质增广的方法用的也比较单一,所以没有取得特别炸裂特别惊艳的效果。但是SimCLR明明看似和他一脉相承,为什么突然就出圈了呢。因为这个工作实验做得特别充足。
我们先来看一下它是怎么设计的。在这里它是抽取一个mini batch作为x。分别对x使用不同的增广方法做数据增广,得到
和
。然后把
和
喂给一个孪生网络。这两个编码器
是共享参数的,我们可以把它视为是同一个编码器,编码之后得到表示向量
,这里区别就来了,在
后面加了一个MLP,变成
,之后使用
去做对比学习。
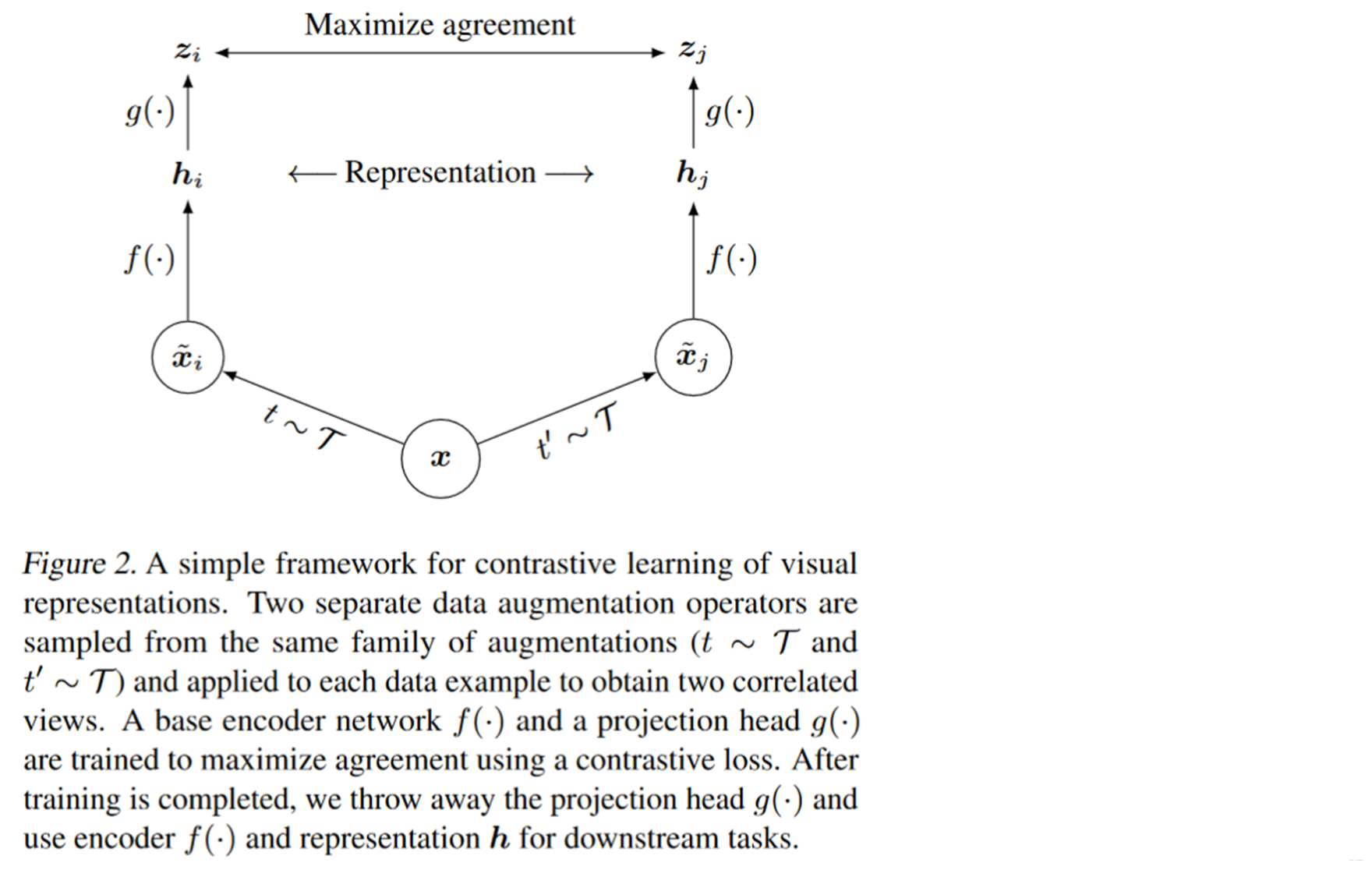
如果用模型图表示的话:
InvaSpread:
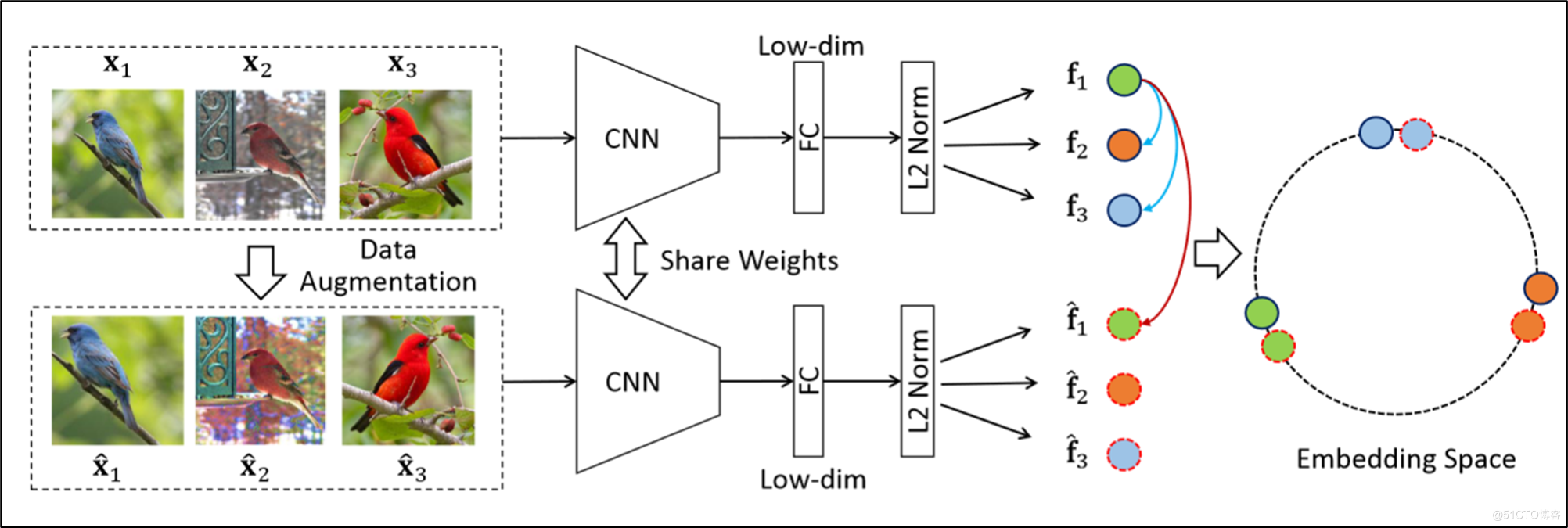
他是把原图丢进一个孪生网络里,然后把增广之后的图丢进孪生网络的另一部分。
SimCLR:
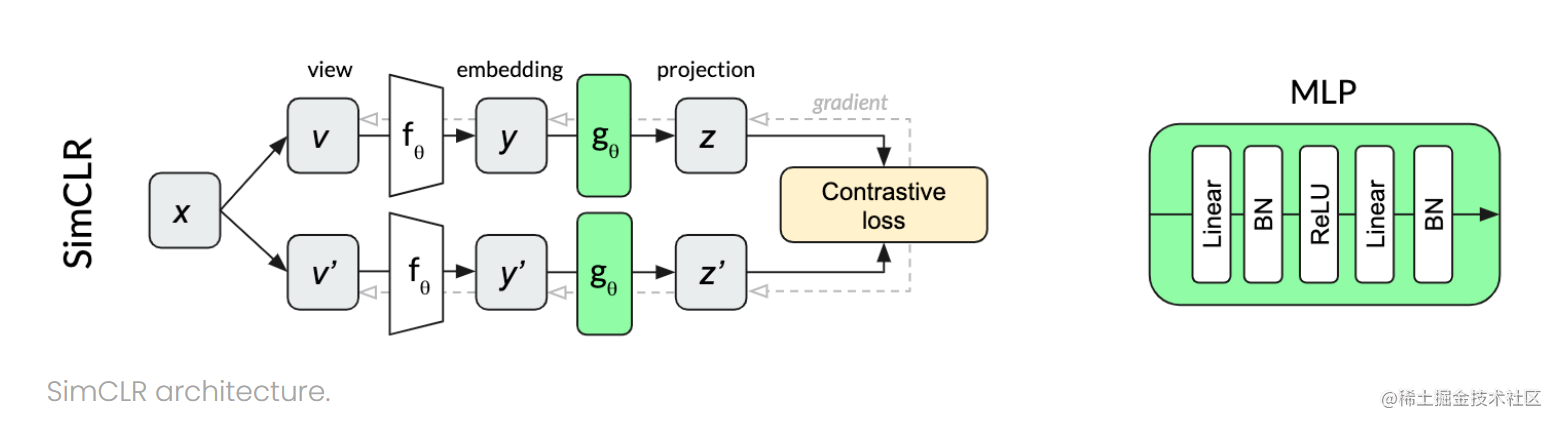
在这里是把两个增广数据丢进网络里,最后还要经过一个MLP。其实就是一个线性层加了一个ReLu激活函数。
结果直接提了10个百分点。所以作者自己也很诧异,为什么会有这么好的效果。为此做了很多实验。下图绿色块就是不加MLP的时候,蓝色是加上一个线性层,但是不使用激活函数的时候。黄色是加上线性层,并且使用激活函数的时候。
我们可以看到加上一个MLP确实具有明显的效果。
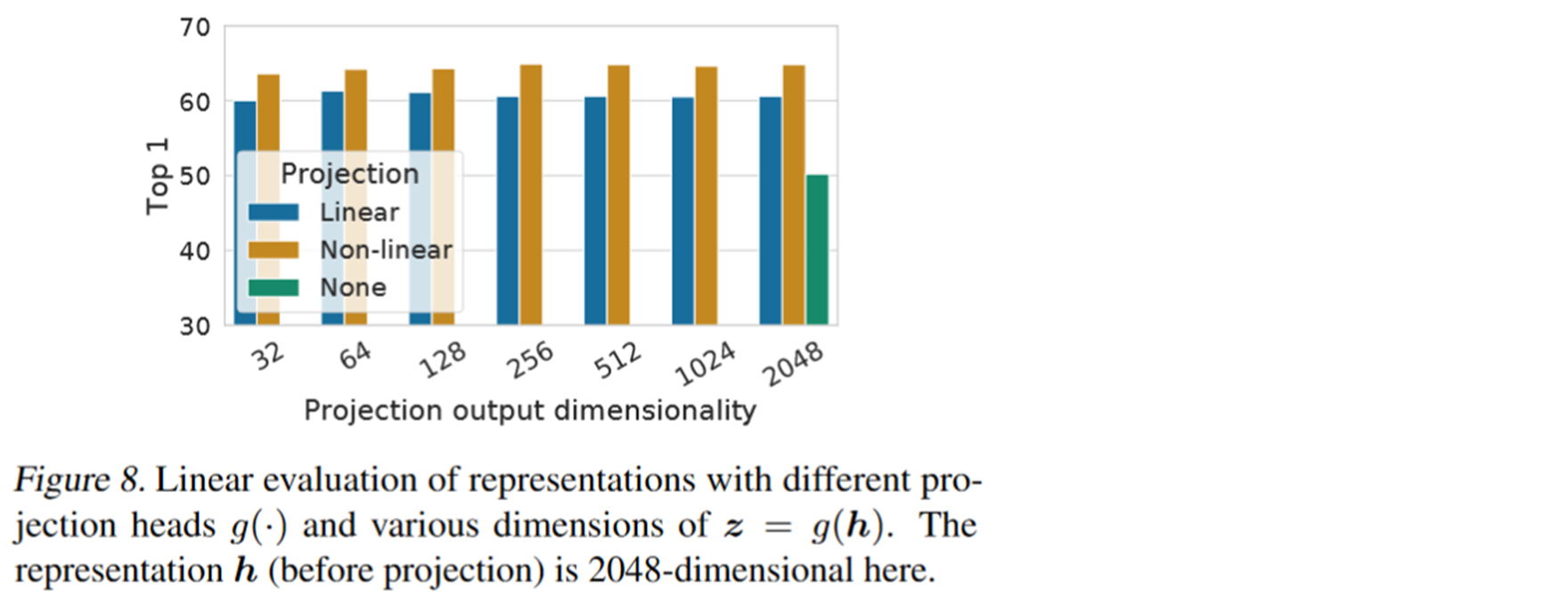
我们前面说因为上面那个工作是数据增广方法单一。没有找到效果比较好的数据增长方式,因此在这里呢SimCLR也做了许多对比实验。

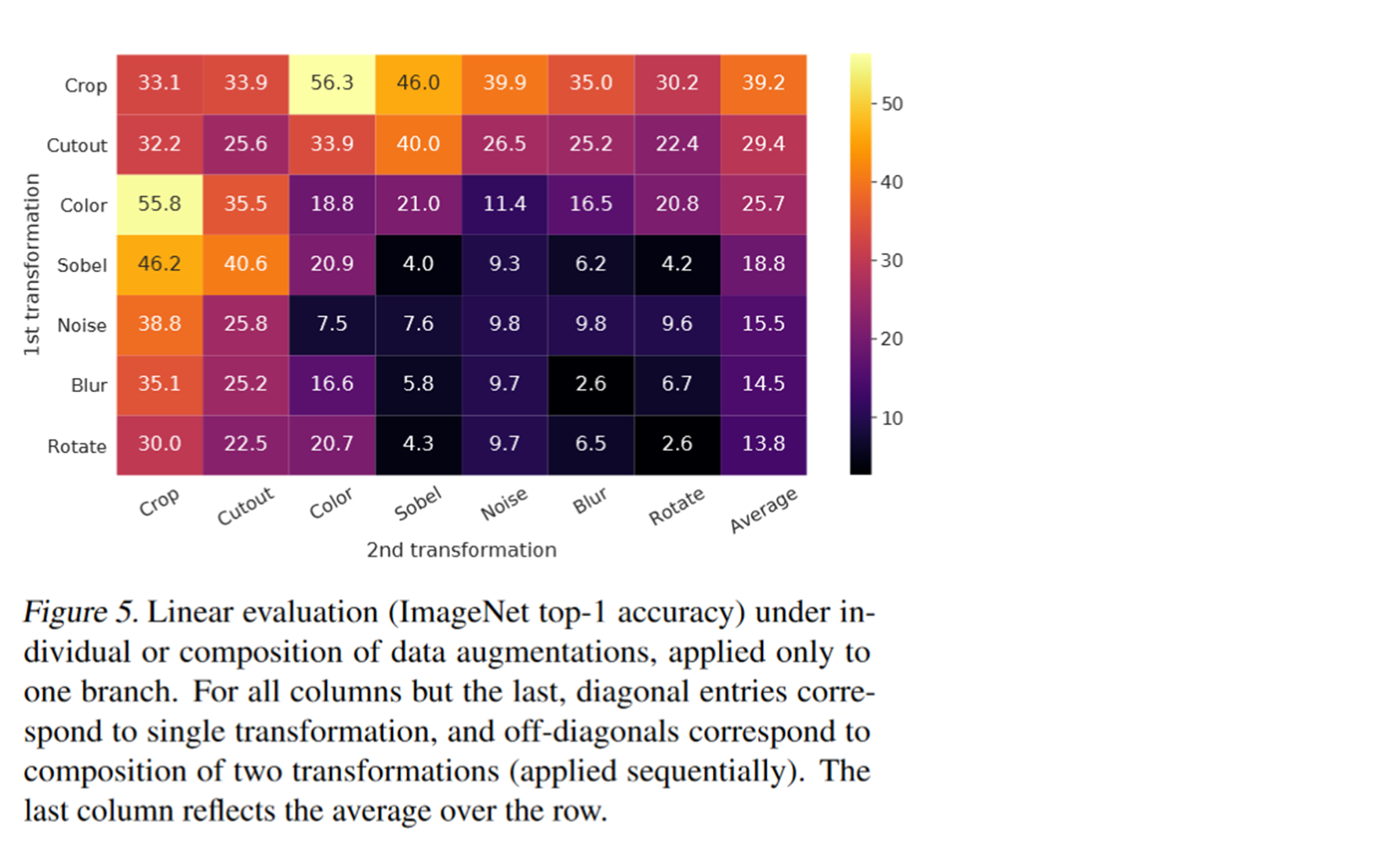
比如对图片进行部分裁剪。对图片进行转换。修改图片的颜色,修改图片的饱和度。将图片剪出一块。或者使用不同的高斯噪声。这里看图片的话应该是使用了最大值和最小值滤波器。最后还使用了少个sobel锐化滤波器。
最后的结果如下。我们可以看到两个黄色框框的分是最高的。也就是同时使用crop和color的时候。因此最后本案中就选用了这两个数据增广方式。
最后再说一下正负样本的选择方法。如果看了InvaSpread我们应该很容易猜到他用的是什么双样本和负样本选择方法。同一张图片的不同增强方式作为正样本。而其他图片的增强作为负样本。在这里也是一个mini batch中图片数量为N,那就会存在两个正样本和2N-2个负样本。
并且在这里我们可以看出,相对于之前的工作,它是没有使用到一个额外的空间进行存储信息的。这里只有一个编码器,既不需要memory bank,也不需要队列和动量编码器。正负样本全都是从同一个mini-batch里来的。整个前向过程非常的直接,就是图片进入编码器编码然后降维,再经过一个MLP,最后算个对比学习的loss。简单暴力并且有效。深受大家欢迎。
MoCo v2
论文地址:
[2003.04297] Improved Baselines with Momentum Contrastive Learning (arxiv.org)

看到上面这篇工作的效果那么惊艳,MoCo的作者也动了心思。他发现嗯嗯。SimCLR中的一些做法都是即插即用型的,你随便搬过来就可以了。所以他就直接在MoCo中借鉴了一下。
然后就提出了MoCo v2,这篇其实并不能算是一篇论文,它只有两页是作为一个技术报告。你可以认为是一个软件更新了之后给用户说的那个更新说明。他一共改进了4个方面:
下面这张图就是他们改进的一些效果。
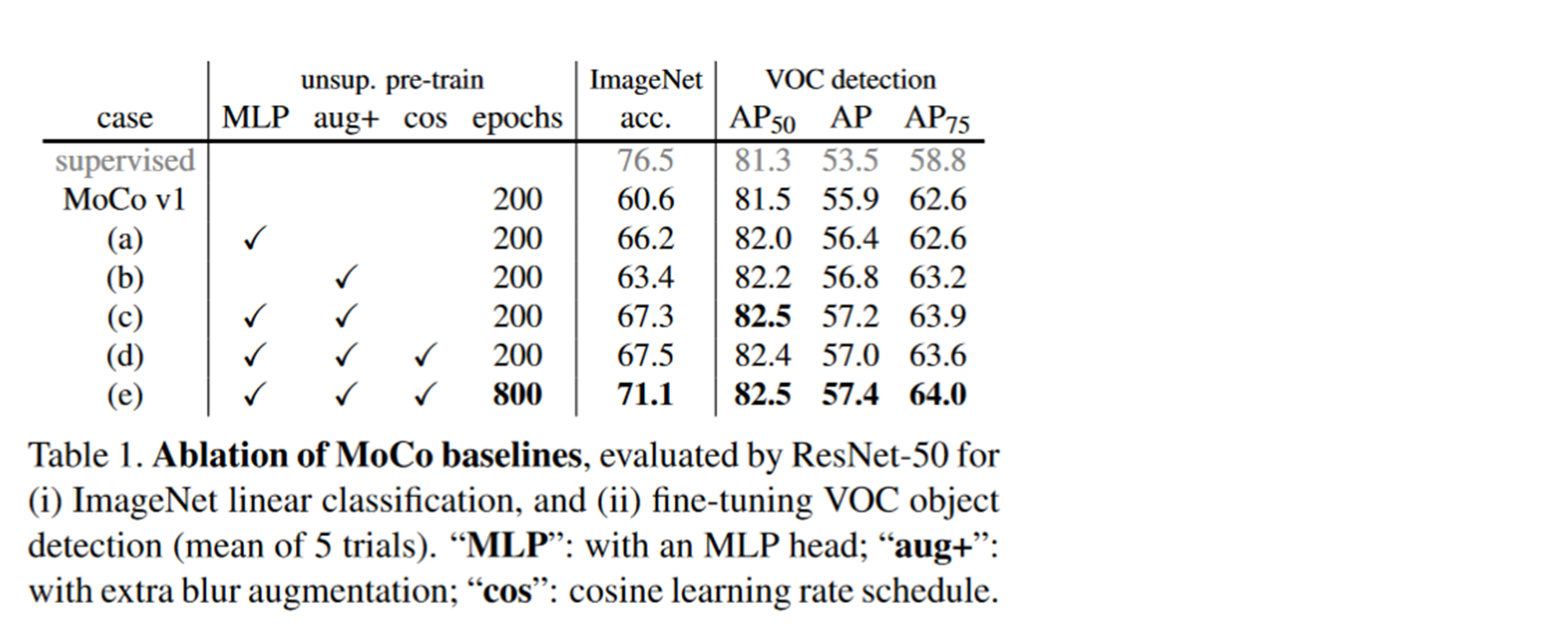
实验A是只加上一个MLP。实验B是使用了更丰富的数据增长方式。实验C是MLP和数据增广方式一起用。实验D是增加了cosine的learning rate schedule。愿意就是增加了训练的epoch。我们可以看到出现了效果明显的提升。
那在和SimCLR对比一下:
先看一下这个表二:
表二的上半部分都是跑200个epochs,但是尝试了不同的batch size。我们可以看到simCLR只有在mini batch很大的时候效果才会好一点,但是效果也不如MoCo v2。表二的下半部分是simCLR设置了一个比较大的batch size。加长了训练的epochs。我们可以看到还是simCLR效果更好。
表三呢就是展示了一下计算的代价,simCLR计算资源消耗更少。
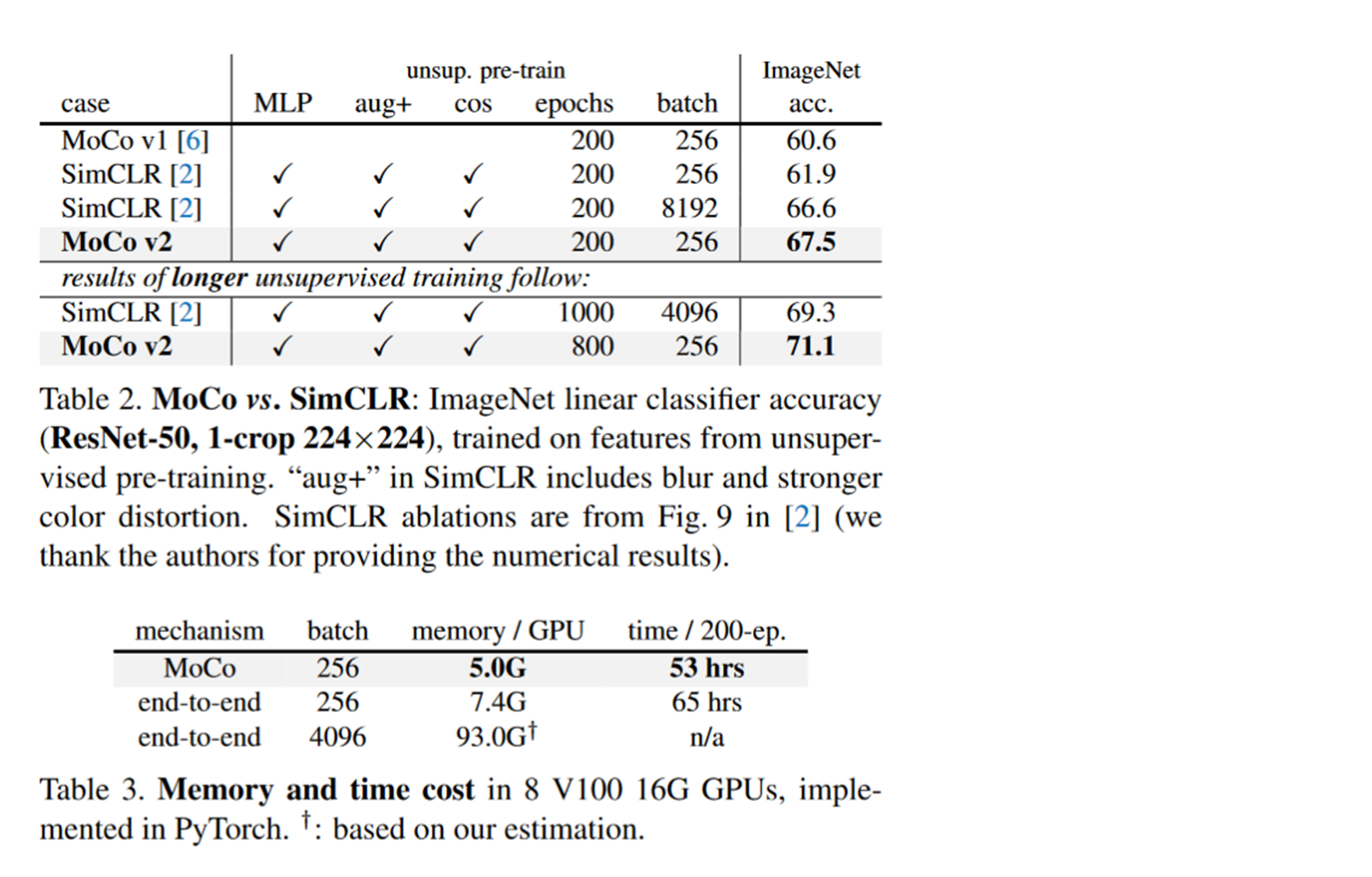
综合对比下来呢就是MoCo v2效果更好,并且走的是平民路线,更适合普通人去复现去使用。
这里补充一点我个人的思考。相对于BERT和GDP的军备竞赛,从目前来看,GDP做的是把模型越做越大,但是BERT和它的变体相比起来模型依旧是比较小的。所以也就是我前面说的BERT做的是平民路线,小而美。我感觉moco在这里也是走这条路子的。
SimCLR v2
论文地址:
[2006.10029] Big Self-Supervised Models are Strong Semi-Supervised Learners (arxiv.org)

SimCLR v2,只是这篇论文一个很小的部分,它只是说怎么从v1变到v2,就是一个模型上的改进,而事实上都在讲如何去做半监督的学习。就是SimCLR v2摆出了大家风范,他说我懒得反击你,我继续做我的工作,我只不过是进行了一点改进而已。而这个模型只是我工作中的一小部分。主要是说
非常大的自监督训练出来的模型非常适合去做半监督学习
。
我们先来看一下他这个监督学习。他先是用无监督训练搞出了SimCLR v2。然后在使用部分有标签的数据对这个模型进行微调,应用到下游任务中。
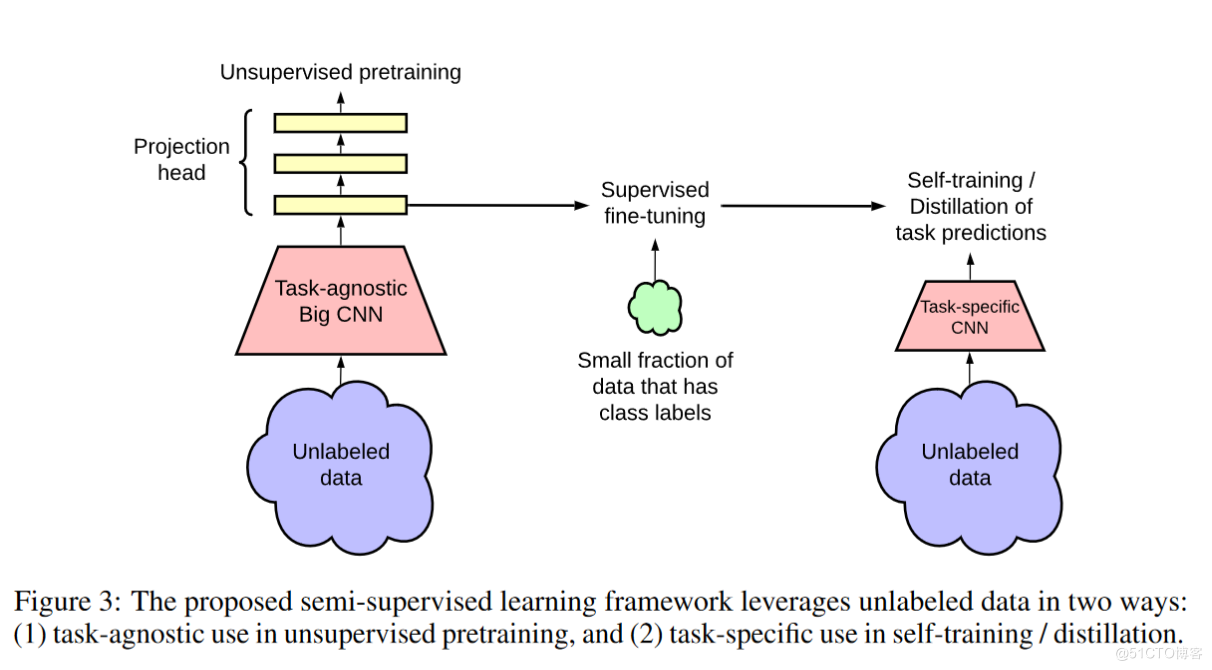
在这里作者也就花了两三页的篇幅介绍了一下SimCLR v1是怎么变成SimCLR v2的。
先是用了一个更大的模型。换了一个152层的残差网络selective kernels,也就是SK net,这个骨干网络变得非常的强。
之前SimCLR说mlp层有用,而且MoCo v2也证明了特别特别的有用,所以SimCLR的作者就想那一层都这么有用了,把它再变深点会不会更有用,所以它就试了试变成两层变成三层这个性能会不会继续提升。当然最后经过实验发现两层就足够了,所以在这篇文章中是加了一个两层的MLP。原来是一个线性层加上ReLu的激活函数这里变成了 线性层+ReLu+线性层+ReLu。
最后是他们也用了动量编码器。
如果不算半监督学习的内容的话,SimCLR v2也是一个2页的技术报告。
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://xie.infoq.cn/article/395b3ece7e14d925600b94eee


![[C language] the use of dynamic memory development](/img/b7/3337bf0df9232d3a44eaeb46b39c63.png)