当前位置:网站首页>Chapters 6 and 7 of Huawei Deep Learning Course
Chapters 6 and 7 of Huawei Deep Learning Course
2022-08-01 07:28:00 【swl.raven】
Table of Contents
Chapter 7 Parameter Adjustment
Learning Links
Chapter 6 Initialization
First of all, what is initialization?
The so-called initialization is to find the initial value of the parameter W in the training network.
Then why initialize?Why is initialization so important?
Generally, the neural network needs to optimize a very complex nonlinear model. In order to find the optimal solution, the selection of the initial point plays an important role:
- The choice of initial point sometimes determines whether the algorithm converges
- When converging, the selection of the initial point determines the speed of learning
- Oversized initialization leads to gradient explosion, and too small initialization leads to gradient disappearance
Now that we know the importance of initialization, we must find a good initialization method.
First, we need to know the criteria for good initialization:
- The activation value of each layer of neurons will not be saturated
- The activation value of each layer cannot be 0
Next, there are several initialization methods:
- All-zero initialization: parameters are initialized to zero
Disadvantages: Neurons in the same layer will learn the same features and cannot destroy the symmetry properties of different neurons.
- Random initialization: Initialize parameters to small random numbers.Typically random values are sampled from a Gaussian distribution, and each dimension of the final parameter comes from a multidimensional Gaussian distribution.
Disadvantage: Optimization gets bogged down once the random distribution is not chosen properly:
If the initial value of the parameter is too small, it will cause a small gradient during backpropagation. For a deep network, a single gradient will diffuse during backpropagation, and the convergence speed will decrease.
If the initial value is too large, it will easily lead to saturation.
- Xavier initialization: ensure that the variance of the input and output of each layer is consistent, and initialize the parameters to
Disadvantage: The effect of activation function on data distribution is not considered

- He initialization: divide by 2 on the basis of Xavier, that is, initialize the parameter to
Advantages: The influence of the ReLU function on the output data distribution is considered, so that the variance of the input and output is consistent

Chapter 7 Parameter Adjustment
The general parameter W is a parameter that is automatically updated during the model training process, and some parameters need to be manually set and adjusted, that is, hyperparameter adjustment.
So what are the hyperparameters?
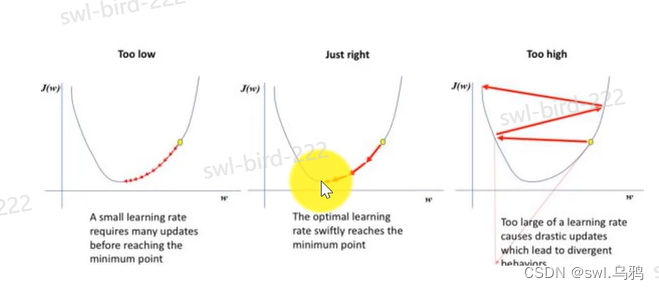
Learning rate: determines the step size of parameter update changes
It can be seen that choosing the appropriate learning rate can find the optimal solution
Minibatch: batch size.If it is too small, the training speed will be very slow; if it is too large, the training speed will be very fast, but it will take up more memory and may also reduce the accuracy.
According to experience, 32, 64, 128, 256 is a good choice (usually it is a power of 2, because the internal processing of the computerThey are all binary, and the memory is generally a power of 2)
Momentum decay parameter β, number of neurons in hidden layer, hyperparameter of Adam optimization algorithm, layers (number of neural network layers), decay_rate (learning decay rate)
You probably know what hyperparameters there are, so you need to constantly adjust these parameters during the training process to find the optimal parameter combination. Here are a few training techniques to introduce how to adjust them:
Trial and error method: Follow the entire experimental process (from data collection to feature map visualization), then iterate sequentially on hyperparameters until time expires.
The disadvantage is that the time is too long and the efficiency is low.
Grid search: As the name suggests, it is to put the hyperparameters we need to adjust in a coordinate system (similar to a grid), and continuously adjust to find the optimal point (hyperparameter combination).
The disadvantage is that it is only suitable for cases where there are fewer hyperparameters to be adjusted. If there are too many, the more dimensions are required, and the more complicated the grid search is.

Random search: The difference from grid search is that the selection point is randomly searched in the configuration space. The advantage is that the optimal point can be found quickly with less resources. Experiments have proved the effect.

Whether it is grid search or random search, each new guess is independent of previous training, so there is a Bayesian optimization method:
Bayesian optimization: The process of the method is as follows
Build the model->select hyperparameters->train, evaluate->optimize the model, then return to the second step
边栏推荐
猜你喜欢
Golang: go get url and form attribute value

阿里云李飞飞:中国云数据库在很多主流技术创新上已经领先国外

MVVM项目开发(商品管理系统一)
Golang: go open web service
Offer刷题——1

升级为重量级锁,锁重入会导致锁释放?

Introduction to the basic principles, implementation and problem solving of crawler
VSCode 快捷键及通用插件推荐

mysql中添加字段的相关问题

dbeaver连接MySQL数据库及错误Connection refusedconnect处理
随机推荐
数据分析5
The use of Golang: go template engine
return; represents meaning
微信小程序请求封装
爬虫基本原理介绍、实现以及问题解决
USB 协议 (二) 术语
VoLTE基础学习系列 | 什么是SIP和IMS中的Forking
Guest brush SQL - 2
根据指定区域内容生成图片并进行分享总结
Golang:go模版引擎的使用
请问用flinksql写入数据到clickhouse需要引入什么依赖吗?
POJ1251丛林之路题解
Offer brush questions - 1
NIO编程
MySQL row locks and gap locks
七夕来袭——属于程序员的浪漫
I have three degrees, and I have five faces. I was "confessed" by the interviewer, and I got an offer of 33*15.
rhcsa 第三次
华为深度学习课程第六、七章
C语言学习概览(二)