当前位置:网站首页>Summary of deep learning tuning tricks
Summary of deep learning tuning tricks
2022-07-06 05:19:00 【Xiaoshu Xiaoshu】
Looking for the right learning rate (learning rate)
Learning rate is a very important super parameter , What about this parameter , Facing different scales 、 Different batch-size、 Different optimization methods 、 Different data sets , The most suitable values are uncertain , We can't determine exactly by experience alone lr Value , The only thing we can do , It is to constantly find the most suitable learning rate for the current state in training .
For example, the figure below uses fastai Medium lr_find() Function to find the right learning rate , According to the learning rate below - The loss curve shows that the appropriate learning rate is 1e-2.

Recommend an article fastai Chief designer 「Sylvain Gugger」 A blog of :How Do You Find A Good Learning Rate[1]
And related papers Cyclical Learning Rates for Training Neural Networks[2].
learning-rate And batch-size The relationship between
Generally speaking , The bigger batch-size The greater the learning rate .
The principle is simple , The bigger batch-size It means when we study , In the direction of convergence confidence The bigger it is , We are moving in a more determined direction , And the small ones batch-size It's a bit messy , There's no regularity , Because compared to the big batch , In the case of small batches, we can't take care of more situations , So you need a small learning rate to make sure you don't make mistakes .
Look at the picture below Loss Loss And Learning rate Lr The relationship between :
![]()
With enough video memory , It's better to use a larger batch-size Training , After finding the right learning rate , It can speed up convergence .
in addition , The larger batch-size You can avoid batch normalization There are some small problems , Refer to the following Pytorch library Issue[3]
Weight initialization
Weight initialization compared to other trick In general, it is not used very frequently .
Because most people use pre training models , The weights used are models trained on large data sets , Of course, you don't need to initialize the weights yourself . Only domains without a pre training model will initialize their own weights , Or to initialize the weights of the last several fully connected layers of the neural network in the model .
The commonly used weight initialization algorithm is 「kaiming_normal」 perhaps 「xavier_normal」.
Related papers :
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification[4]
Understanding the difficulty of training deep feedforward neural networks[5]
Xavier Initial paper [6]
He Initial paper [7]
Not initializing may slow down convergence , Influence the convergence effect .
following Input size for network , Is the output size of the network , by or
uniform Evenly distributed initialization :
Xavier The initial method , For ordinary activation functions (tanh, sigmoid):
He initialization , Apply to ReLU:
normal Gaussian distribution initialization , among stdev Is the standard deviation of Gaussian distribution , The mean value is set to 0:
Xavier The initial method , For ordinary activation functions (tanh,sigmoid):
He initialization , Apply to ReLU:
svd initialization : Yes RNN It has a better effect . Reference paper :https://arxiv.org/abs/1312.6120[8]
dropout
dropout It refers to the training process of deep learning network , For neural network units , According to a certain probability, it will be discarded from the network temporarily . Note that 「 temporary 」, For random gradient descent , Because it's random discard , So every one of them mini-batch They're training different networks .
Dropout Be similar to bagging ensemble Reduce variance. That's voting to reduce variability . Usually we use it in the full connection layer dropout, In the convolution layer, we don't use . but 「dropout」 It's not suitable for all situations , Don't be mindless Dropout.
Dropout It is generally suitable for the whole connection layer , The parameters of the convolution layer are not many , So no need dropout, In addition, it has little effect on the generalization ability of the model .![]()
We usually use the full connection layer at the beginning and end of the network , and hidden layers The convolution layer in the network . So in general , In the whole connection layer , Using a higher probability of dropout In the convolution layer, we use low probability or not dropout.
Dataset processing
There are mainly 「 Data filtering 」 as well as 「 Data to enhance 」
fastai Why the image enhancement technology in is relatively good [9]
It's hard to excavate hard-negative-mining
It is difficult for analytical models to predict the correct samples , Give targeted methods .
Multi-model fusion
Ensemble It's the ultimate nuclear weapon of the paper , There are several ways in deep learning
The same parameters , Different initialization methods
Different parameters , adopt cross-validation, Choose the best groups
The same parameters , Different stages of model training , That is, models with different iterations .
Different models , Linear fusion . for example RNN And traditional models .
To improve the performance and robustness of the model :probs The fusion and laws and regulations governing balloting .
Let's say there is model 1, model 2, model 3, It can be fused like this :
1. model1 probs + model2 probs + model3 probs ==> final label
2. model1 label , model2 label , model3 label ==> voting ==> final label
3. model1_1 probs + ... + model1_n probs ==> mode1 label, model2 label And model3 Acquired label Ways and 1 identical ==> voting ==> final label
The inspiration of the third way comes from , If one model The random seeds are not fixed , Multiple predictions may lead to different results .
The effect of the above methods should be based on label Number , Data set size and other characteristics, specific analysis of specific issues , The performance may be different , The way is nothing more than probs Fusion and voting alone or combination .
Differential learning rate and transfer learning
First of all, transfer learning , Transfer learning is a common deep learning skill , We use a lot of classic pre training models to train our own tasks directly . Although the fields are different , But in terms of the breadth of learning weight , There is a connection between the two tasks .

From above , Let's get it 「model A」 Trained model weight to train our own model weight (「Model B」), among ,modelA May be ImageNet Pre training weight of , and ModelB It's the pre training weights we want to use to identify cats and dogs .
What is the relationship between differential learning rate and transfer learning ? Let's take the training weights of other tasks directly , It's going on optimize When , How to choose an appropriate learning rate is a very important issue .
In a general way , The neural network we designed ( Here's the picture ) It is generally divided into three parts , Input layer , The hidden layer and the output layer , As the number of layers increases , The more abstract the features learned by neural networks are . therefore , In the figure below, the learning rate of convolution layer and full connection layer should also be set differently , Generally speaking , The learning rate of convolution layer should be lower , And the learning rate of full connection layer can be improved appropriately .

That's what differential learning rate means , Set up different learning rates at different levels , It can improve the training effect of neural network , See the connection below for details .

The above example is from :towardsdatascience.com/transfer-le…[10]
Cosine annealing (cosine annealing) And hot restart
「 cosine 」 It's like a cosine curve ,「 Anneal 」 It's a descent ,「 Cosine annealing 」 It's just that the learning rate is like a cosine function .
「 Hot restart 」 It's in the process of learning ,「 Learning rate 」 Slow down and then suddenly 「 Rebound 」( restart ) And then it goes down slowly .
The combination of the two is the learning rate chart below :

For more details, you can see how to adjust the parameters of Zhihu machine learning algorithm ? Here's a guide to setting the learning rate of neural networks [11]
And related papers SGDR: Stochastic Gradient Descent with Warm Restarts[12]
Tried to fit a small data set
This is a classic little trick 了 , But a lot of people don't , You can try it .
Turn off regularization / Random deactivation / Data expansion , Use a small part of the training set , Let the neural network train for several cycles . Make sure you can achieve zero loss , without , So it's possible that something went wrong .
Multiscale training
Multi scale training is a kind of 「 Directly effective 」 Methods , By inputting image data sets of different scales , Because of the particularity of neural network convolution pooling , In this way, the neural network can fully learn the features of images with different resolutions , It can improve the performance of machine learning .
It can also be used to deal with over fitting effects , When the image data set is not particularly sufficient , You can train small images first , Then increase the size and train the same model again , This kind of thinking is Yolo-v2 It's also mentioned in my paper :
![]()
It should be noted that : Multi scale training is not suitable for all deep learning applications , Multi scale training can be regarded as a special data enhancement method , The size of the image has been adjusted . If possible, it's best to use visual code to take a close look at the multi-scale image ,「 Let's see if multi-scale will affect the overall information of the image 」, If it affects the image information , In this way, direct training will mislead the algorithm and result in failure to get the expected results .
Cross Validation Cross validation
In Li Hang's statistical method, he said , Cross validation is often used in practical applications 「 There's not enough data 」 And used , The basic purpose is to reuse data . In general, we divide all the data into training set and verification set, which is a simple cross validation , Can be called 1 Crossover verification .「 Be careful , Cross validation has nothing to do with test sets , The test set is used to measure the standard of our algorithm , Not involved in cross validation .」
Cross validation is only for training set and verification set .
Cross validation is Kaggle It's a skill that's highly praised in the competition , We often use 5- fold (5-fold) Cross validation , Divide the training set into 5 Share , Randomly select one as the verification set and the rest as the training set , loop 5 Time , This is quite common, and the amount of calculation is not very large . There's another one called leave-one-out cross validation Leave a cross validation , This kind of cross validation is n- Fold and cross ,n Represents the capacity of a dataset , This method is only suitable for small amount of data , This method is rarely used when the amount of calculation is very large .
Wu Enda has a class The nuts and bolts of building applications using deep learning[13] It also mentions .![]()
optimization algorithm
In principle, different optimization algorithms are suitable for different tasks , But most of our optimization algorithms are adam and SGD+monmentum.
Adam Can solve a lot of strange problems ( Sometimes loss It can't go down , in Adam Just in a second ), It can also bring a lot of strange problems ( For example, the frequency of words varies greatly , At present batch The word vectors of the words that don't have are also updated ; Another example Adam and L2 The complex effect of regular combination ). Be bold and careful when using it , In case of problems, find all kinds of magic Adam( such as MaskedAdam[14], AdamW What? ) Rescue .
But read some blogs and say adam Compared with SGD, Fast convergence , But the generalization ability is poor , Better results seem to require fine tuning SGD.
adam,adadelta etc. , On small data , The effect of my experiment here is not as good as sgd, sgd The convergence rate will be slower , But the final result of convergence , It's generally better .
If you use sgd Words , You can choose from 1.0 perhaps 0.1 The learning rate started to , After a while , Check on the validation set , If cost No decline , Cut the learning rate by half . I've read a lot of papers that do this , The results of my own experiment are also very good . Of course , You can also use ada The series starts with , At the end of the day , Replace it with sgd Keep training . There will also be improvements . It is said that adadelta In general, the effect of classification is better ,adam In the generation problem, the effect is better .
adam Although the convergence is fast, the solution is often not sgd+momentum The solution is better , If we don't consider the time cost, we still use sgd Well .
adam It doesn't need special adjustment lr,sgd Take more time to tune lr and initial weights.
Data preprocessing method
zero-center , This is quite common .
PCA whitening, This one is less used .
Training skills
To do gradient normalization , That is, the calculated gradient divided by minibatch size
clip c( Gradient cut ): Limit the maximum gradient , It's actually value = sqrt(w1^2+w2^2….), If value Over threshold , Even a coefficient of attenuation , Give Way value The value of is equal to the threshold : 5,10,15
dropout It has a good effect on preventing over fitting of small data , The value is generally set to 0.5
On the small data dropout+sgd In most of my experiments , The effect is very obvious . So if possible , It is suggested that we must try .
dropout The location is quite exquisite , about RNN, Put it in the input ->RNN And RNN-> Output position . About RNN How to use dropout, You can refer to this paper :http://arxiv.org/abs/1409.2329[15]
except gate Places like that , You need to limit the output to 0-1 outside , Try not to use sigmoid, It can be used tanh perhaps relu Activation functions like that .
sigmoid Function in -4 To 4 Section in , There's a big gradient . Outside the range , The gradient is close to 0, It's easy to cause the gradient to disappear .
Input 0 mean value ,sigmoid The output of the function is not 0 Mean .
rnn Of dim and embdding size, Generally from 128 Start adjusting up and down . batch size, Generally from 128 The left and right began to adjust . batch size Fit is the most important thing , It's not that the bigger the better .
word2vec initialization , On small data , It can not only effectively improve the convergence rate , It can also improve the results .
Try to do... With the data shuffle
LSTM Of forget gate Of bias, use 1.0 Or a larger value for initialization , Better results can be achieved , From this paper :http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf[16], I set this experiment here 1.0, It can improve the convergence speed . In practice , Different tasks , You may need to try different values .
Batch Normalization It is said that it can improve the effect , Reference paper :Accelerating Deep Network Training by Reducing Internal Covariate Shift
If your model includes a full connectivity layer (MLP), And the input and output are the same size , You can think about MLP Replace with Highway Network, I try to improve the results a little bit , It is suggested that as a final means of upgrading the model , The principle is simple , It's just adding a... To the output gate To control the flow of information , Please refer to the paper for details : http://arxiv.org/abs/1505.00387[17]
come from @ Zhang Xinyu's technique : One round plus regular , A round without regularity , Go back and forth .
In the case of large data sets , Run full data as soon as you come up . It is recommended to use first. 1/100、1/10 Let's go for a run , Have a bottom line for model performance and training time , Extrapolate how long it takes to run full data . Don't do large-scale experiments without enough confidence .
subword It's always going to rise steadily , It just works .
GPU When reporting a mistake, try to put it in CPU Top heavy running , Error messages are more friendly . for example GPU newspaper "ERROR:tensorflow:Model diverged with loss = NaN" In fact, it's probably input ID Beyond the softmax The scope of the vocabulary .
In determining the initial learning rate , From a very small value ( for example 1e-7) Start , Then every step exponentially increases the learning rate ( For example, expanding 1.05 times ) Training . It should be observed that the loss function is checkered with the number of training steps , Choose the learning rate of the period where the loss decreases the fastest .
Add a rnn trick, It's still without considering the cost of time ,batch size=1 It's a good one regularizer, At least in some task On , It's also possible that many people can't reproduce it alex graves One of the reasons for the experimental results , Because he always put batch size set 1.
Pay attention to the reproducibility and consistency of the experiment , Pay attention to develop a good habit of recording experiments ==> Otherwise, how to analyze the experimental conclusion .
Super parameter ,learning rate above all , Recommend to understand cosine learning rate and cyclic learning rate, The second is batchsize and weight decay. When your model is good , We can try to do data augmentation and change the loss function to add icing on the cake .
Reference resources :
There are many techniques for training neural networks Tricks\( Full summary \)[18]
What do you have deep learning(rnn、cnn) The experience of tuning parameters ?[19]
Bag of Tricks for Image Classification with Convolutional Neural Networks[20],trick Collection 1.
Must Know Tips/Tricks in Deep Neural Networks[21],trick Collection 2.
33 This is a secret of neural network training [22],trick Collection 3.
26 Second second GPU Training CIFAR10[23], The engineering practice .
Batch Normalization[24], Although metaphysics , But they feed a lot of alchemists .
Searching for Activation Functions[25],swish Activation function .
author : Mangosteen fruit , Reprinted from :NewBeeNLP
边栏推荐
- [noip2008 improvement group] stupid monkey
- Simple understanding of interpreters and compilers
- Oracle query table index, unique constraint, field
- 毕业设计游戏商城
- Can the feelings of Xi'an version of "Coca Cola" and Bingfeng beverage rush for IPO continue?
- Easy to understand I2C protocol
- Nacos TC setup of highly available Seata (02)
- flutter 实现一个有加载动画的按钮(loadingButton)
- RT thread analysis - object container implementation and function
- In 2022, we must enter the big factory as soon as possible
猜你喜欢
Figure database ongdb release v-1.0.3

ByteDance program yuan teaches you how to brush algorithm questions: I'm not afraid of the interviewer tearing the code

nacos-高可用seata之TC搭建(02)
Can the feelings of Xi'an version of "Coca Cola" and Bingfeng beverage rush for IPO continue?
Questions d'examen écrit classiques du pointeur
Unity Vector3. Use and calculation principle of reflect
指针经典笔试题
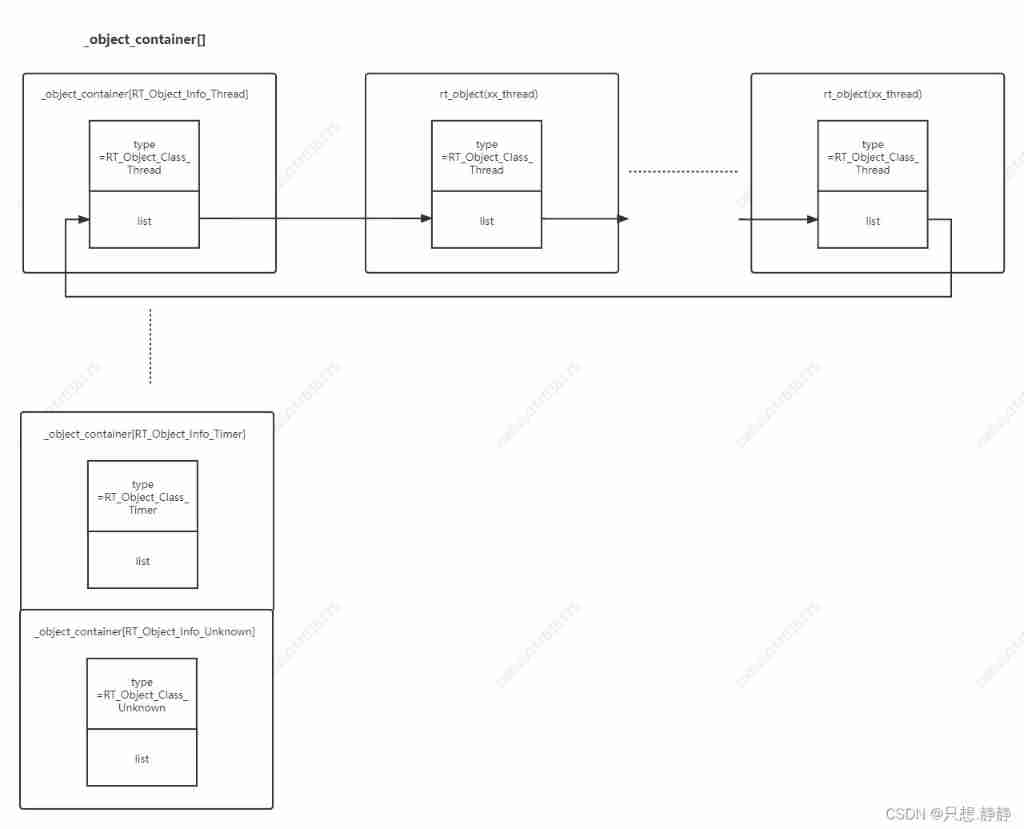
RT thread analysis - object container implementation and function
初识CDN
![[untitled]](/img/7e/d0724193f2f2c8681a68bda9e08289.jpg)
[untitled]
随机推荐
MySQL if and ifnull use
Mysql高级篇学习总结9:创建索引、删除索引、降序索引、隐藏索引
Postman pre script - global variables and environment variables
Extension of graph theory
Talking about the type and function of lens filter
Huawei equipment is configured with OSPF and BFD linkage
Hyperledger Fabric2. Some basic concepts of X (1)
Easy to understand I2C protocol
SQLite add index
【LeetCode】18、四数之和
浅谈镜头滤镜的类型及作用
Sorting out the knowledge points of multicast and broadcasting
RT thread analysis - object container implementation and function
Review of double pointer problems
Three. JS learning - light and shadow (understanding)
Fiddler installed the certificate, or prompted that the certificate is invalid
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
MySQL advanced learning summary 9: create index, delete index, descending index, and hide index
Quelques conseils communs sur l'inspecteur de l'unit é, généralement pour les extensions d'éditeur ou d'autres
[lgr-109] Luogu may race II & windy round 6