当前位置:网站首页>Call the classic architecture and build the model based on the classic
Call the classic architecture and build the model based on the classic
2022-07-01 01:22:00 【L_ bloomer】
1 Call the classic architecture
Most of the time , We won't go from 0 To create our own architecture , Instead, choose a suitable architecture or idea from the classic architecture , On the classic architecture, the architecture is customized and modified according to the needs of data ( Yes, of course , We can only call what we have learned 、 And master the structure of the principle , Otherwise, we will have no way to start when revising ). stay PyTorch in , Basically all classical architectures have been implemented , So we can go straight from PyTorch in “ Transfer Library ” To use . Unfortunately , Most of the libraries directly transferred out cannot meet our own needs , But we can still call PyTorch As the basis of our own architecture .
PyTorch There is a very important and easy-to-use package in the framework :torchvision, The package is mainly composed of 3 The sub package consists of , Namely :torchvision.datasets、torchvision.models、torchvision.transforms. from torchvision Invoking the complete model architecture , These architectures are located in “CV Common models ” modular torchvision.models in . stay torchvision.models in . stay torchvision.models in , framework / The model is divided into 4 Large type : classification 、 Semantic segmentation 、 object detection / Instance segmentation and key point detection 、 Video classification . For each type of Architecture ,models Both contain at least one parent class that implements the architecture itself ( Present as “ Hump type ‘ name ) And a subclass containing pre training functions ( All lowercase ). For having different depths 、 In terms of architectures with different structures , It may also contain multiple subclasses .( Parents and children : The relationship between the basic skeleton and the basic implementation )



 For only one architecture 、 There are no different depths of AlexNet Come on , The structure of the two classes is the same
For only one architecture 、 There are no different depths of AlexNet Come on , The structure of the two classes is the same
m.AlexNet() # Check what parameters need to be filled in ?
m.alexnet() # take AlexNet The functions of the parent class are included in , Parameter input to the original schema is not allowed , But you can do pre training
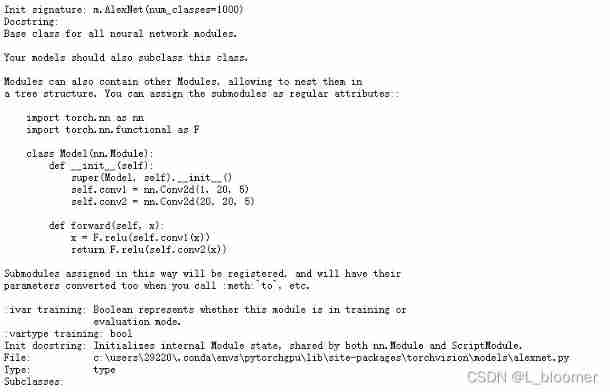

For residual Networks , A parent class is a class that implements a specific architecture , Subcategory is a class that has filled in the required parameters
m.ResNet() # You can implement structures of different depths from this class
m.resnet152() # The specific depth and parameters are locked , You can perform pre training on this class


When actually using the model , We almost always call lowercase classes directly , Unless we want to modify the internal architecture on a large scale . As shown below , The way to call a class is very simple :



Due to different network architectures , Therefore, different architecture classes do not share properties or methods , We need to check the architecture ourselves before calling . We can modify the super parameter settings of some layers according to our own needs . 
If we want to modify the classic architecture , We have to revise... Layer by layer . One layer of the convolutional network may be used for all subsequent layers An impact , Therefore, we often only input to the network 、 Fine tune the output layer , The middle tier of the schema will not be modified . However , Most of it Time sharing and full application of classical architecture can not meet our modeling needs , So we need to build our own architecture based on the classic architecture .
2 Self built architecture based on classic architecture
Almost all modern classic architectures are based on ImageNet Data sets 224x224 The size of the 、1000 Constructed by classification , Therefore, almost all classical architectures will have 5 Next sampling ( The pool layer or step size is 2 The convolution of layer ). When our data set is large enough , We will give priority to using the classic architecture to run on the data set , But when our image size is small , We don't have to expand the image to 224x224 Size to fit the classic architecture ( It can be used transform.Resize Do it , However, the prediction effect after amplification and conversion may not be very good ). This will not only increase the computational power requirements 、 The calculation time becomes longer , It may not be able to achieve good results . If possible , On smaller pictures , We hope to keep the status quo as far as possible to control the overall amount of calculation .
For convolution Architecture , Change the of the characteristic graph Number of inputs and outputs The behavior of is only related to oneortwo layers , To change the Dimension of characteristic drawing The behavior of will affect the whole architecture . therefore , We usually learn from the classic architecture ” extract “ Part to use , There is also a small possibility from 0 Build your own new architecture . Suppose we are using something similar to Fashion-MNIST Size ,28x28 Data set of , On such a dataset , The only chance we may perform the next sampling is 2 Time , Once from 28x28 Dimensionality reduction 14x14, Another time is from 14x14 Dimensionality reduction 7x7. Such a data set is not very suitable for tens of millions 、 Classic architectures with hundreds of millions of parameters . under these circumstances , torchvision.models The built-in architecture cannot flexibly meet the requirements , Therefore, we often do not directly use the built-in Architecture , Instead, the architecture is reconstructed on the basis of its own architecture .
Here's an example based on VGG And residual network self built architecture :
We may have many different ideas for building architecture . The most common way is to follow VGG To deepen the network , The other is to use blocks in classical Networks ( For example, the classical residual unit in residual network 、GoogLeNet Medium inception Isostructure ) To deepen the network . Experience proves that , stay inception It would be good to add some ordinary convolution layer before the residual unit , So here I use VGG The idea of , Then use the residual unit . You can freely combine your favorite structures .




边栏推荐
- The quantity and quality of the devil's cold rice 101; Employee management; College entrance examination voluntary filling; Game architecture design
- For the first time in more than 20 years! CVPR best student thesis awarded to Chinese college students!
- 软硬件基础知识学习--小日记(1)
- K210 site helmet
- K210 access control complete
- Xjy-220/43ac220v static signal relay
- uniapp官方组件点击item无效,解决方案
- DLS-20型双位置继电器 220VDC
- ESP8266 RC522
- None of the following candidates is applicable because of a receiver type mismatch
猜你喜欢

XJY-220/43AC220V静态信号继电器

Day31-t1380-2022-02-15-not answer by yourself

Hoo research | coinwave production - nym: building the next generation privacy infrastructure

dc_labs--lab1的学习与总结

HDU 2488 A Knight's Journey(DFS)

Oracle temporary table explanation

Q play soft large toast to bring more comfortable sleep

Poor students can also play raspberry pie

Docker 部署 MySQL 8
Q弹松软的大号吐司,带来更舒服的睡眠
随机推荐
ORB-SLAM2源码学习(二)地图初始化
集群与LVS介绍及原理解析
K210 access control complete
XJY-220/43AC220V静态信号继电器
JS to convert numbers into Chinese characters for output
Win11安装redis 数据库以及redis desktop manager的下载
2021电赛F题openmv和K210调用openmv api巡线,完全开源。
Hoo research | coinwave production - nym: building the next generation privacy infrastructure
CSDN common complex formula template record
Unhandled Exception: MissingPluginException(No implementation found for method launch on channel)
Two-stage RO: part 1
解析融合学科本质的创客教育路径
PHP online confusion encryption tutorial sharing + basically no solution
Docker 部署 MySQL 8
人穷志不短,穷学生也能玩转树莓派
Detailed analysis of operators i++ and ++i in JS, i++ and ++i
【学习笔记】倍增 + 二分
【go】go 实现行专列 将集合进行转列
The quantity and quality of the devil's cold rice 101; Employee management; College entrance examination voluntary filling; Game architecture design
fluttertoast