当前位置:网站首页>Kettle读取按行分割的文件
Kettle读取按行分割的文件
2022-07-27 02:08:00 【LongJ_Sir】
Kettle是一个开源的ETL工具,支持来自众多的数据源间的数据迁移,笔者也是N年前有所使用,最近在迁移一批来自HDFS的文本数据时,又想到了这个工具的使用,来HDFS的文本常会以行进行分割存储,笔者这次遇到的就是6千余万行的json数据,总体量在20G,在网上找了一圈也没找到读取多行文本的操作,于是就自己摆弄了一下,特此作为记录:
数据格式如下:
{"type": "Feature", "properties": {},"geometry": {"type": "Polygon","coordinates": [[[-19.441364292429924, 65.52333266640196], [-19.441369748908993, 65.52335128397081], [-19.441456975615232, 65.52334689547278], [-19.441451519136184, 65.5233282779008], [-19.441364292429924, 65.52333266640196]]]}}
{"type": "Feature", "properties": {},"geometry": {"type": "Polygon","coordinates": [[[-22.023537553224426, 64.34071231744036], [-22.023766291888357, 64.34079685621145], [-22.023896688463573, 64.34073070136526], [-22.02366796389063, 64.340646160667], [-22.023537553224426, 64.34071231744036]]]}}
{"type": "Feature", "properties": {},"geometry": {"type": "Polygon","coordinates": [[[-20.53351958043648, 64.21502080919846], [-20.533556158627654, 64.21504083748084], [-20.533638377500047, 64.21501242439349], [-20.53360179930887, 64.21499239609055], [-20.53351958043648, 64.21502080919846]]]}}按行进行分割的JSON,需要将其导入到postgresql中:
在kettle中新建“转换”,在输入中选择文本文件输入,添加需要进行抽取的问题吧:

在“内容”管理卡将格式改为Unix,在“字段”管理卡点击获取字段即可对定义字段名称:

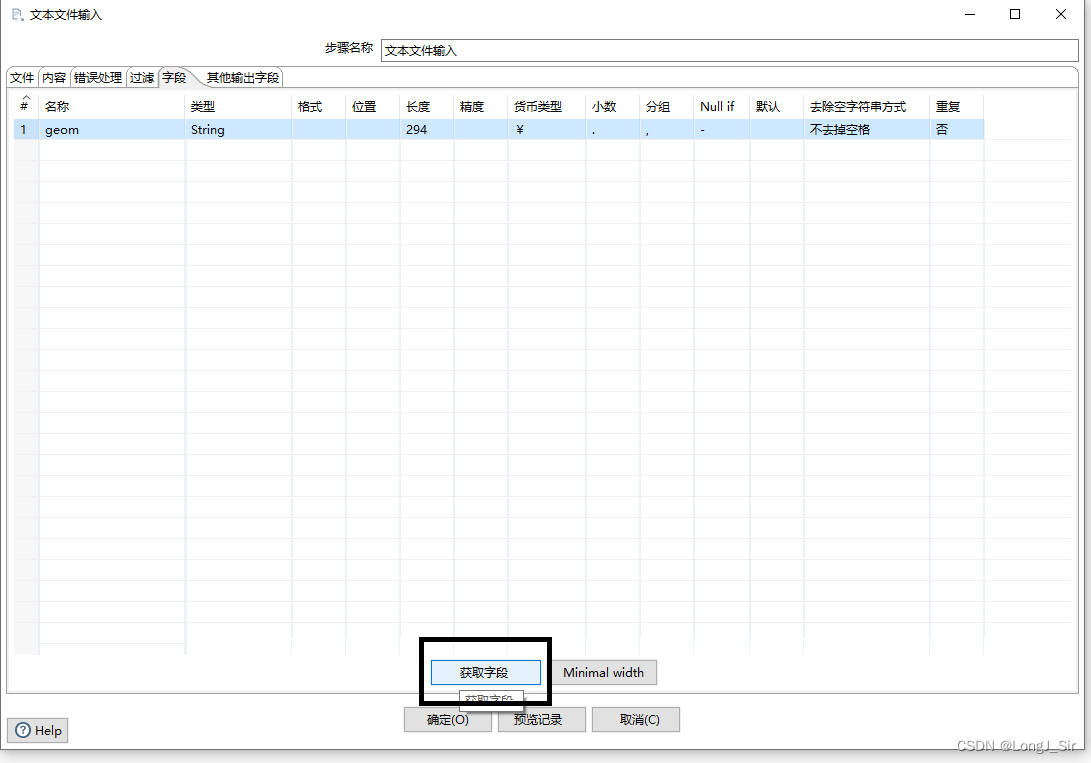
然后就可以预览记录:

为了读取JSON中的某个Key下的值,我们在之后可以加入一个“JSON输入”,在“文件”管理卡选择“源定义在一个字段里”,“从字段获取源”中选择上一步输出的字段:


在“字段”管理卡用JSONPath配置字段:

接下来就可以通过预览转换来预览过程:
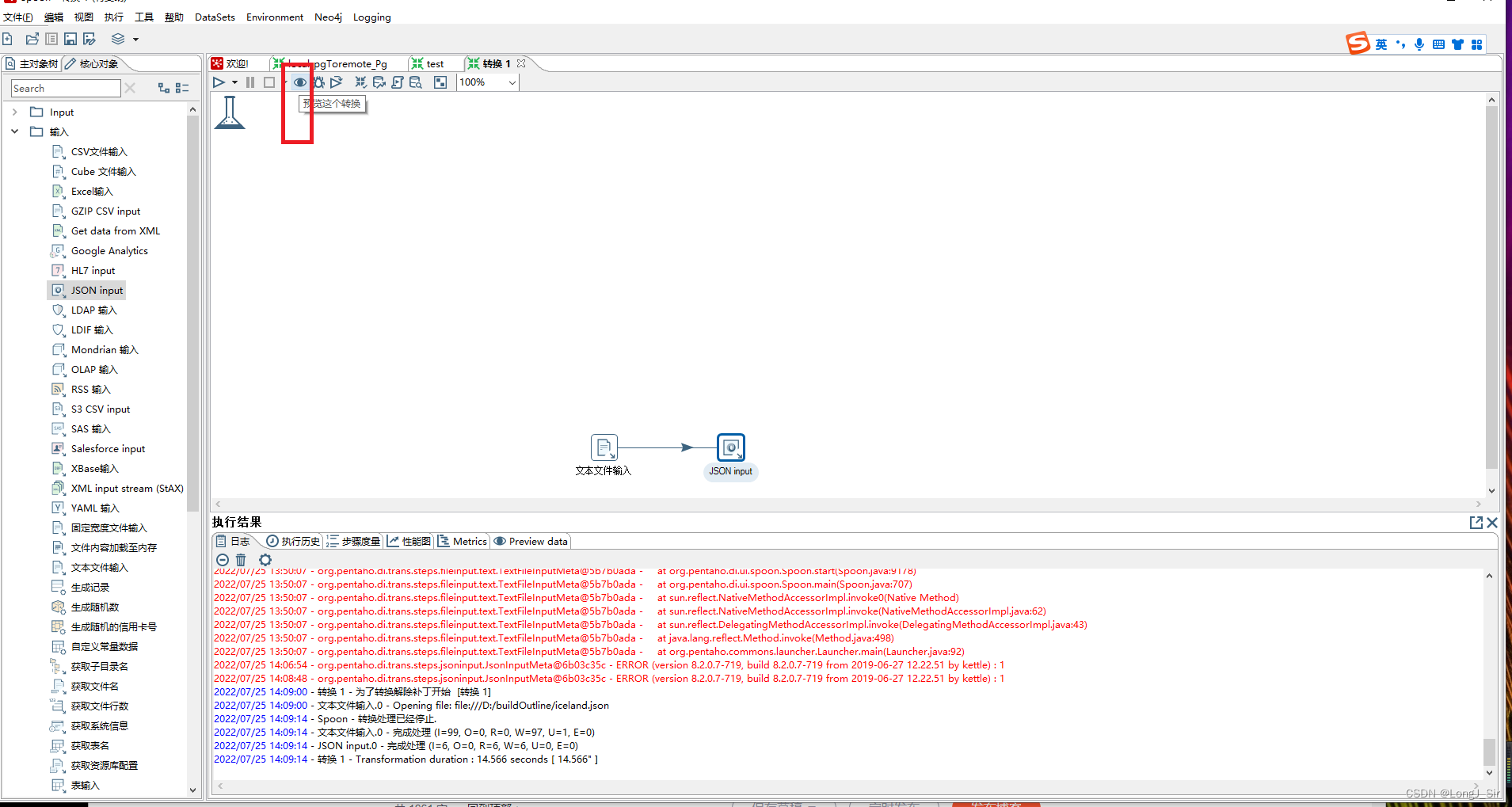

之后就可以按照入库的方式配置输出了。
打完收工,测试下来,6千5百万条文本数据到postgresql 用时37分钟,执行效率上应该算非常快了。
边栏推荐
- Does Oracle have a distributed database?
- The application and significance of digital twins are the main role and conceptual value of electric power.
- [flask] the server obtains the file requested by the client
- Typescript TS basic knowledge interface, generics
- Technology vane | interpretation of cloud native technology architecture maturity model
- Contour detection based on OpenCV (2)
- 一种分布式深度学习编程新范式:Global Tensor
- Network security / penetration testing tool awvs14.9 download / tutorial / installation tutorial
- Unity game, the simplest solution of privacy agreement! Just 3 lines of code! (Reprinted)
- app端接口用例设计方法和测试方法
猜你喜欢

JMeter distributed pressure measurement

Code practice when the queue reaches the maximum length

477-82(236、61、47、74、240、93)

数字孪生实际应用:智慧城市项目建设解决方案
How many implementation postures of delay queue? Daily essential skills!

Pytoch loss function summary

Contour detection based on OpenCV (1)
![[1206. Design skip table]](/img/a9/ca45c9fedd6e48387821bdc7ec625c.png)
[1206. Design skip table]
Add support for @data add-on in idea

MySQL的数据库有关操作
随机推荐
Message rejected MQ
Deeply understand the underlying data structure and algorithm of MySQL index
spark学习笔记(五)——sparkcore核心编程-RDD转换算子
【1206. 设计跳表】
PyCharm中Debug模式进行调试详解
Redis spike case, learn from Shang Silicon Valley teacher in station B
redis入门练习
太强了,一个注解搞定接口返回数据脱敏
How to interact with the server when the client sends an SQL message
Double disk: the main differences between DFS and BFS, the differences in ideology, and the differences in code implementation
opiodr aborting process unknown ospid (21745) as a result of ORA-609
《稻盛和夫给年轻人的忠告》阅读笔记
Leetcode 207. curriculum (July 26, 2022)
shell awk
榕树贷款C语言结构体里的成员数组和指针
[regular] judgment, mobile number, ID number
Sqlserver select * can you exclude a field
技术风向标 | 云原生技术架构成熟度模型解读
How to uniquely identify a user SQL in Youxuan database cluster
[learning notes, dog learning C] string + memory function