author |Stan Kriventsov
compile |Flin
source |medium
In this post , I want to be able to , Explain the author's submission to 2021 ICLR The new paper from the conference “ A graph is equal to 16x16 A word : Transformers for large-scale image recognition ” The meaning of ( So far anonymous ).
In another article , I offer an example , This example takes this new model ( be called Vision Transformer, Vision transformer ) And PyTorch Used together with standards MNIST Data sets for prediction .
since 1960 In depth learning since ( Machine learning uses neural networks to have more than one hidden layer ) It has come out , But what makes deep learning really come to the forefront , yes 2012 In the year AlexNet, A convolution network ( Simply speaking , A network , First look for small patterns in each part of the image , Then try to combine them into a whole picture ), from Alex Krizhevsky Design , Won the year ImageNet The winner of the image classification contest .
-
ImageNet Image classification contest :https://en.wikipedia.org/wiki/ImageNet
Over the next few years , Deep computer vision technology has experienced a real revolution , New convolution architectures emerge every year (GoogleNet、ResNet、DenseNet、EfficientNet etc. ), In the ImageNet And other benchmark datasets ( Such as CIFAR-10、CIFAR-100) Set a new precision record on the .
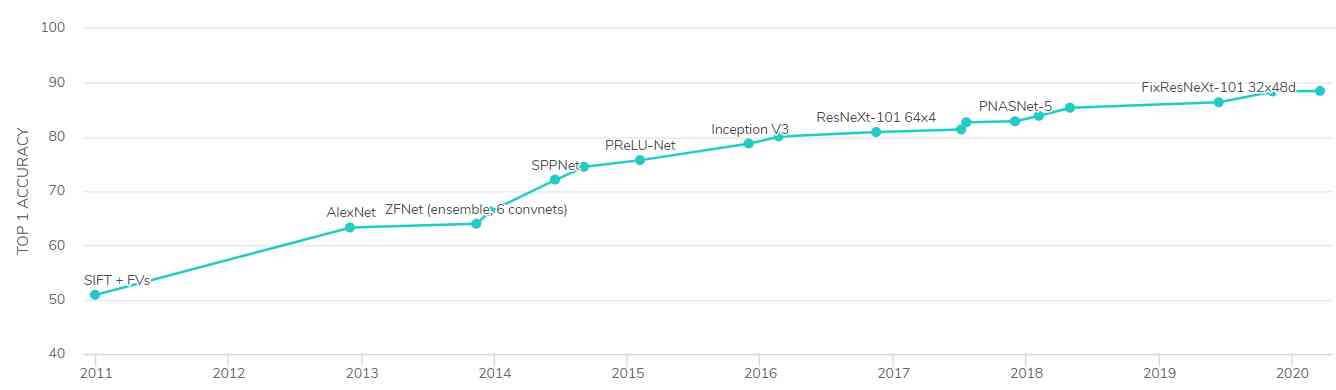
The figure below shows from 2011 Since then ImageNet The highest accuracy of machine learning models on datasets ( On the first attempt, correctly predict the accuracy of the content of the image ) The progress of .
However , In the past few years , The most interesting development of deep learning is not in the field of images , It's in natural language processing (NLP) in , This is from Ashish Vaswani Et al. 2017 Year paper “ Attention is everything you need ” For the first time .
- Address of thesis :https://arxiv.org/abs/1706.03762
The thought of attention , It refers to the weight that can be trained , Simulate the importance of each connection between different parts of the input sentence , Yes NLP The effect of this is similar to the convolution network in computer vision , It greatly improves the machine learning model for various language tasks ( Such as natural language understanding ) And the effect of machine translation .
What makes attention so effective for linguistic data , Because understanding human language often requires tracking long-term dependencies . We might start by saying “ We arrived in New York ”, And said, “ The weather in the city is fine ”. For any human reader , It should be clear , In the last sentence “ City ” refer to “ New York ”, But for one based only on nearby data ( Like convolutional networks ) Find the model of the pattern in , This connection may not be detectable .
The problem of long-term dependence can be solved by using recursive networks , for example LSTMs, Before the transformer comes ,LSTMs It's actually NLP The top model in , But even those models , It's also hard to match specific words .
The global attention model in the transformer measures the importance of each connection between any two words in the text , This explains the advantages of their performance . For sequential data types that are less important to attention ( for example , Time domain data such as daily sales or stock prices ), Recursive networks are still very competitive , It may still be the best choice .
Although in NLP In the equal sequence model , Dependencies between distant objects may have special significance , But in the image task , They can't be ignored . To form a complete picture , You usually need to understand the various parts of the image .
up to now , The reason why attention models don't perform well in computer vision is the difficulty of scaling them ( They are scaled to N², therefore 1000x1000 The full set of attention weights between the pixels of an image will have a million items ).
Maybe more importantly , in fact , Contrary to the words in the text , The pixels in the picture themselves are not very meaningful , So connecting them through attention doesn't make much sense .
This new paper proposes a method , It doesn't care about pixels , It's about small areas of the image ( Maybe it's in the title 16x16, Although the optimal block size actually depends on the image size and content of the model ).
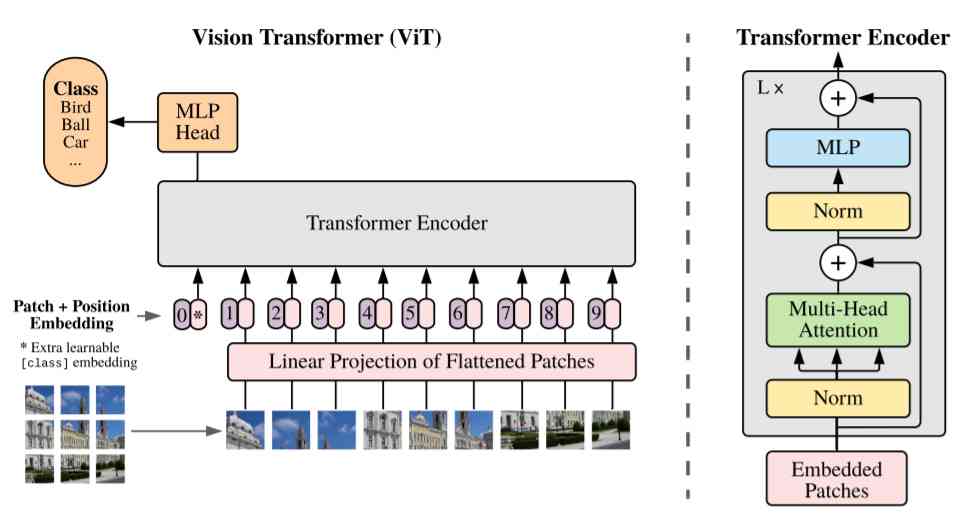
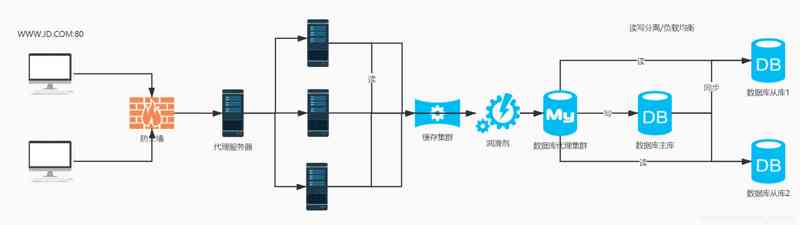
The picture above ( From the paper ) Shows how the visual transformer works .
Each color block in the input image is flattened by using a linear projection matrix , And add location embedding to it ( Learning numbers , It contains information about the initial position of the color block in the image ). This is necessary , Because the transformer will process all the inputs , Regardless of the order , Therefore, it is helpful for the model to evaluate the attention weight correctly . Additional class tags are connected to the input ( Position in the image 0), As a placeholder for the class to predict in the classification task .
Be similar to 2017 edition , The transformer encoder consists of multiple attention , Normalized and fully connected layer composition , These layers have residuals ( skip ) Connect , As shown in the right half of the figure .
In each area of interest , Multiple headers can capture different connection patterns . If you are interested in learning more about transformers , I suggest reading Jay Alammar I wrote this wonderful article .
The output is fully connected MLP The header can provide the desired category prediction . Of course , As it is today , The master model can be pre trained on large image data sets , Then you can use standard transfer learning methods to get the final MLP Head fine tuning for specific tasks .
One of the features of the new model is , Although according to the research in this paper , It is more effective than convolution method to obtain the same prediction accuracy with less computation , But as it receives more and more data training , Its performance seems to be improving , This is more than any other model .
The author of this article contains 3 Billion private googlejft-300M Visual converter images are trained on the dataset , This leads to state-of-the-art accuracy in many benchmarks . One can expect this pre trained model to be released soon , So that we can all try .
- Data sets :https://arxiv.org/abs/1707.02968
See the new application of neural attention in the field of computer vision , It's so exciting ! Hopefully in the next few years , On the basis of this development , Can make greater progress !
Link to the original text :https://medium.com/swlh/an-image-is-worth-16x16-words-transformers-for-image-recognition-at-scale-brief-review-of-the-8770a636c6a8
Welcome to join us AI Blog station :
http://panchuang.net/
sklearn Machine learning Chinese official documents :
http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station :
http://docs.panchuang.net/