当前位置:网站首页>Siamrpn: recommended regional network and twin network
Siamrpn: recommended regional network and twin network
2022-07-26 14:46:00 【The way of code】
Address of thesis :http://openaccess.thecvf.com/content_cvpr_2018/papers/Li_High_Performance_Visual_CVPR_2018_paper.pdf
Abstract
Most excellent visual target trackers are difficult to have real-time speed . In this article , We propose a twin candidate region generation network (Siamese region proposal network), abbreviation Siamese-RPN, It can use large-scale images to train offline end-to-end . In particular , This structure contains Twin subnetwork (Siamese subnetwork) and Candidate regions generate networks (region proposal subnetwork), The candidate area generation network includes classification and Return to Two branches . In the tracking phase , Our proposed method is constructed as a single sample detection task (one-shot detection task).
We pre calculate the template branches in the twin subnet , That's the first frame , And it is constructed as a convolution layer in the area extraction network in the detection branch , For online tracking . Thanks to these improvements , Traditional multi-scale testing and online fine-tuning can be discarded , This also greatly improves the speed .Siamese-RPN Ran out 160FPS The speed of , And in VOT2015,VOT2016 and VOT2017 Has achieved leading results .
1. introduction
Compared with the most advanced method based on correlation filter which is properly designed , The tracker based on off-line training and deep learning can get better results . The key is to generate a network of candidate twin candidate regions (Siamese-RPN). It consists of Template Branch and Detection branch form , They train large-scale image pairs offline in an end-to-end manner . By the most advanced candidate region extraction methods RPN Inspired by the , We are concerned about feature map Make proposal extraction . With the standard RPN Different , We use the relevant feature mapping of two branches to extract proposals . In the tracking task , We have no predefined categories , Therefore, we need the template branch to encode the appearance information of the target into RPN In the element map to distinguish the foreground and background .
In the tracking phase , The author regards this task as a single target detection task (one-shot detection), What does that mean , Is to put the first frame bb As an example of detection , Detect similar targets in other frames .
in summary , The author's contribution has the following three points :
1. Put forward Siamese region proposal network, Be able to use ILSVRC and YouTube-BB A large amount of data for offline end-to-end training .
2. In the tracking phase, the tracking task is constructed into a local single target detection task .
3. stay VOT2015, VOT2016 and VOT2017 Leading performance on , And the speed can reach 160fps.
2. Related work
2.1 RPN
RPN namely Region Proposal Network, Yes, it is RON To select the region of interest , namely proposal extraction. for example , If a region's p>0.5, It is thought that there may be 80 One of the categories , It's not clear what kind it is . Only this and nothing more , The network only needs to select these areas that may contain objects , These selected areas are also called ROI(Region of Interests), That is, the region of interest . Of course RPN At the same time feature map Frame these ROI Approximate location of the region of interest , The output Bounding Box.
2.2 One-shot learning
The most common example is face detection , Only know the information on one picture , Use this information to match the image to be detected , This is the single sample test , It can also be called a learning .
3 Siamese-RPN framework
3.1 SiamFC
So-called Siamese( twin ) The Internet , It refers to that the main structure of the network is divided into two branches , These two are like twins , Weight of shared volume layer . The upper one (z) Called template Branch (template), Used to extract the features of the template frame .φ Represents a feature extraction method , What is extracted in this paper is the depth feature , After the full convolution network, we get a 6×6×128 Of feature map φ(z). Next one (x) It is called detection branch (search), It is on the current frame according to the result of the previous frame crop Out of search region. After extracting the depth feature, we get a 22×22×128 Of feature map φ(x). Template support feature map In the detection area of the current frame feature map Do matching operation on , It can be seen as φ(z) stay φ(x) Slide up to search , Finally, we get a response diagram , The most responsive point on the graph is the position of the target corresponding to this frame .

Siamese The advantage of the network is , hold tracking The task is made into a test / Match task , Whole tracking The process does not require updating the network , This makes the algorithm fast (FPS:80+). Besides , Sequel CFNet The two tasks of feature extraction and feature discrimination are made into an end-to-end task , It is the first time to combine depth network and correlation filtering .
Siamese There are also obvious defects :
1. Template support is only carried out in the first frame , This makes the template features not very adaptable to the changes of the target , When the goal changes greatly , The features from the first frame may not be sufficient to characterize the target . As for why we only extract template features in the first frame , I think it may be because :
(1) The features of the first frame are the most reliable and robust , stay tracking When it is impossible to determine which frame is reliable , Only the first frame feature is enough to get good accuracy .
(2) The algorithm of extracting template features only in the first frame is simpler , Faster .
2.Siamese Method can only get the center position of the target , But we can't get the size of the target , So we can only adopt simple multi-scale plus regression , This increases the amount of calculation , At the same time, it is not accurate enough .
Network training principle

As shown in the figure , The target template of the previous frame and the search area of the next frame can form many pairs of templates - Candidate pairs (exemplar-candidate pair), But according to the principle of discriminant tracking , Only the target of the next frame and the target area of the previous frame ( namely exemplar of T frame-exemplar of T+1 frame) It belongs to the positive sample of the model , The rest are large exemplar-candidate pair All negative samples . This completes the end-to-end training of the network structure .
3.2 Siamese-RPN
On the left is the twin network structure , The network structure and parameters of the upper and lower branches are exactly the same , Above is the input of the first frame bounding box, Use this information to detect the target in the candidate area , Template frame . Here are the frames to be detected , obviously , The search area of the frame to be detected is larger than that of the template frame . In the middle is RPN structure , It's divided into two parts , The upper part is the classification Branch , The features of the template frame and the detection frame after passing through the twin network pass through a convolution layer , After the convolution layer, the feature of the template frame becomes 2k×256 passageway ,k yes anchor Number , Because it is divided into two categories , So it is 2k. The following is the boundary box regression Branch , Because there are four quantities [x, y, w, h], So it is 4k On the right is the output .

3.3 Twin feature extraction sub network
In the process of the training AlexNet, Removed conv2 conv4 Two layers of .φ(z) Is template frame output ,φ(x) Is the detection frame output
3.4 Candidate area extraction sub network
Classification branch and regression branch convolute the features of template frame and detection frame respectively :
contain 2k Channel vectors , Each point in represents positive and negative excitation , Classification by cross entropy loss ; contain 4k Channel vectors , Each dot represents anchor and gt Between dx,dy,dw,dh, adopt smooth L1 Loss gains :
Ax, Ay, Aw, Ah yes anchor boxes Center point coordinates and length and width ; Tx, Ty, Tw, Th yes gt boxes, Why do you do this , Because there are differences in size between different pictures , We should normalize them .
smoothL1 Loss :
3.5 Training phase : End to end training twins RPN
Because the change of two consecutive frames in tracking is not great , therefore anchor Use only one scale ,5 Different aspect ratios ( And RPN Medium 3×3 individual anchor Different ). When IoU Greater than 0.6 Time is the future , Less than 0.3 Time is the background .
4. Tracking as one-shot detection
Average loss function L:
As mentioned above , Give Way z Presentation template patch,x Indicates detection patch, function φ Express Siamese Feature extraction subnet , function ζ Indicates the regional recommendation subnet , Then the one-time detection task can be expressed as :
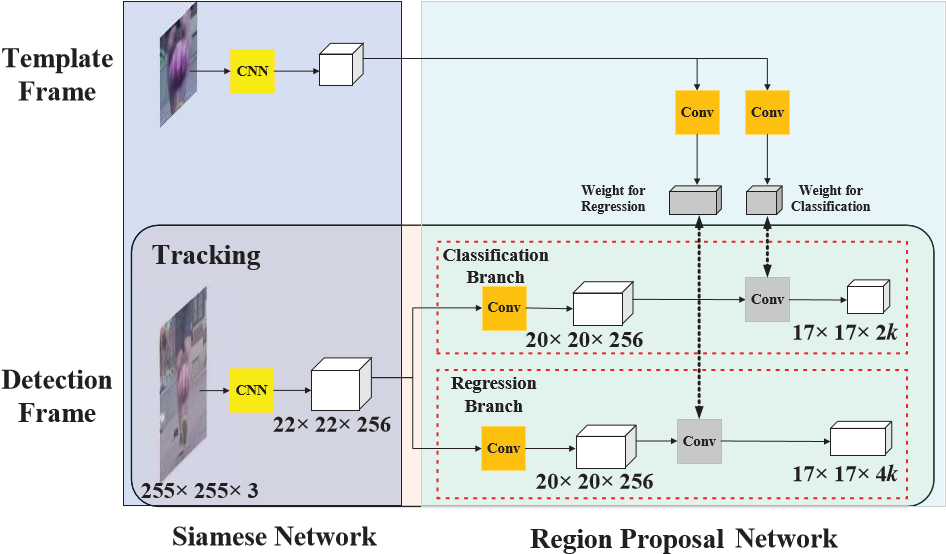
Pictured , The purple part looks like the original Siamese The Internet , After the same CNN Then I got two feature map, The blue part is RPN. The template frame is RPN Through the convolution layer ,$ \phi (x){reg} \phi (x){cls}$ As the core used for detection .
To put it simply , It is the branch of pre training template , Use the target feature of the first frame to output a series weights, And these weights, Contains information about the goal , As a detection branch RPN Network parameters go detect The goal is . The advantage of this is :
(1) Template support can learn one encode The characteristics of the target , Use this feature to find the target , This is better than using the first frame directly feature map Matching is more robust .
(2) Compared with the original Siamese The Internet ,RPN The network can directly regress the coordinates and dimensions of the target , Both accurate , It doesn't need to be like multi-scale A waste of time .
After going through the network , We express classification and regression feature mapping as point sets :
Because the odd channels on the classification feature map represent positive activation , We collect all In front of K A little bit , among l Is odd , And indicates that the point set is :
among I,J,L Are some index sets .
Variable i and j Code the positions of corresponding anchors respectively ,l Code the ratio of the corresponding anchor , Therefore, we can export the corresponding anchor set as :
Besides , We found that On ANC* The activation of the gets the corresponding refinement coordinates as :
Because it's classification , Before the election k A little bit , Choose in two steps :
First step , Discard those too far away from the center bb, Only select from a fixed square smaller than the original feature map , Here's the picture :

The center distance is 7, Look carefully at the picture and you can see , Every grid has k A rectangle .
The second step , Use cosine window ( Restrain those with too large distance ) And scale change punishment ( Suppress large scale changes ) Come on proposal Sort , Choose the best . The specific formula can be seen in the paper .
Use these points to correspond to anchor box Combined with the regression results bounding box:
an Namely anchor Box of ,pro It is the final boundary box after regression thus ,proposals set Just choose .
Then through non maximum inhibition (NMS), seeing the name of a thing one thinks of its function , That is to remove all the boxes that are not huge , because anchor There is usually overlap overlap, therefore , identical object Of proposals There is also overlap . To solve the overlap proposal problem , use NMS Algorithm to deal with : Two proposal between IoU Greater than the preset threshold , Then discard score Lower proposal.
IoU The presetting of the threshold value needs to be handled carefully , If IoU It's too small , May be lost objects Some of proposals; If IoU Overvalued , May lead to objects There are many proposals.IoU Typical values for 0.6.
5. Implementation details
We use from ImageNet [28] Pre training improved AlexNet, The parameters of the first three convolutions are fixed , Only adjust Siamese-RPN The last two convolutions in . These parameters are obtained by using SGD Optimize the equation 5 From the loss function in . A total of 50 individual epoch,log space The learning rate has increased from 10-2 Down to 10-6. We from VID and Youtube-BB Extract image pairs from , By selecting an interval less than 100 And perform further cropping procedures . If the size of the target bounding box is expressed as (w,h), We take size A×A Cut the template patch for the center , Its definition is as follows :
among p =(w + h)/2
Then adjust it to 127×127. Clip the detection patch on the current frame in the same way , Its size is twice that of the template patch , And then adjust to 255×255.
In the reasoning stage , Because we make online tracking a one-time detection task , So there is no online adaptation . Our experiment is with Intel i7,12G RAM,NVidia GTX 1060 Of PC Upper use PyTorch Realized .
Learn more about programming , Please pay attention to my official account :

边栏推荐
- winscp传输文件和VNC连接问题
- 『BaGet』带你一分钟搭建自己的私有NuGet服务器
- 请问下大家,flink sql有没有办法不输出update_before?
- 保证接口数据安全的10种方案
- Would you please tell me if there is a way for Flink SQL not to output update_ before?
- 14. Bridge based active domain adaptation for aspect term extraction reading notes
- GOM login configuration free version generate graphic tutorial
- C # use shift > > and operation and & to judge whether the two binary numbers have changed
- Plato farm is expected to further expand its ecosystem through elephant swap
- 键盘快捷键操作电脑(自己遇到不会的)
猜你喜欢

Summary of target tracking related knowledge

~6. CCF 2021-09-1 array derivation

SP export map to Maya

Learning basic knowledge of Android security
图神经网络Core数据集介绍

WPF common function integration

【使用工具条绘图】

VP video structured framework

Error reported by Nacos enabled client
10 schemes to ensure interface data security
随机推荐
Kubernetes----Pod配置资源配额
Win11 running virtual machine crashed? Solution to crash of VMware virtual machine running in win11
Multithreading - thread pool
如何评价测试质量?
Flask send_ Absolute path traversal caused by file function
VBA 上传图片
JS creative range select drag and drop plug-ins
C# 常用功能整合
Pdf translation, which translation company in Beijing is good
Mysql5.7 is installed through file zip - Ninth Five Year Plan xiaopang
[draw with toolbar]
过滤器和拦截器的区别
Annotation and reflection
【2022国赛模拟】白楼剑——SAM、回滚莫队、二次离线
填问卷,领奖品 | 诚邀您填写 Google Play Academy 活动调研问卷
Canvas mesh wave animation JS special effect
c# 用移位 >> 和运算与 &判断两个 二进制数 是否发生过改变
嵌入式开发:调试嵌入式软件的技巧
智能家居行业发展,密切关注边缘计算和小程序容器技术
C# NanUI 相关功能整合