当前位置:网站首页>urllib的介绍和基本使用基本使用
urllib的介绍和基本使用基本使用
2022-07-22 18:45:00 【冲锋的禾】
1.urllib是什么
urllib是爬虫常用的一个库,通过他我们能爬取浏览器上的数据
2.urllib的基本使用
#使用urllib获取百度首页的源码
import urllib.request
#(1)定义一个url :你要访问的页面:baidu.com
url = 'http://www.baidu.com/?tn=59044660_1_hao_pg&H123Tmp=nunew11'
#(2)模拟浏览器给服务器发送请求
response = urllib.request.urlopen(url)
#(3)获取响应中的页面的源码
#read方法 返回的是字节形式二进制数据
#二进制==》字符串 解码 decode('编码格式')
content = response.read().decode('utf-8')
#(4)打印数据
print(content)注意:要用http而不是https,
原因:https相较于http的区别:
1、https的端口是443,而http的端口是80,且两者的连接方式不同;
2、http传输是明文的,而https是用ssl进行加密的,https的安全性更高;
3、https是需要申请证书的,而http不需要。 本文操作环境:Windows7系统、Dell G3电脑。
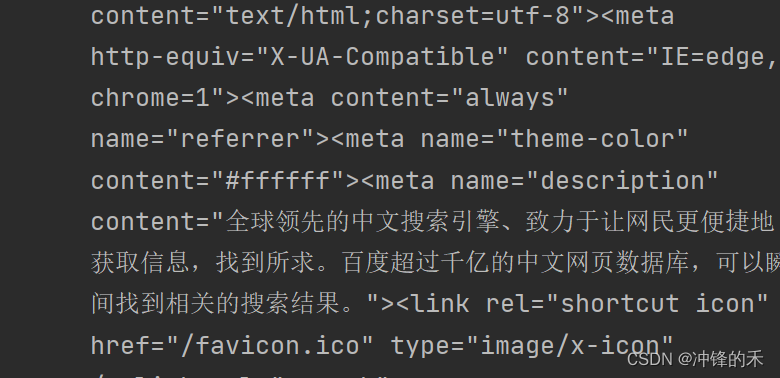
运行结果(截取部分):
边栏推荐
- Linux环境下oracle切换用户并查询数据库命令
- Elementary analysis of graph convolution neural network (GCN)
- [strong net cup 2019] casual note
- 【考研词汇训练营】Day 10 —— capital,expand,force,adapt,depand
- 影響接口查詢速度的情况
- Attack and defense world - hacknote
- 最大连续子序列--每日一题
- R language uses openxlsx package to output excel report
- Live video system source code, save platform video content locally
- SFM与MVS区别
猜你喜欢

Li Xiang, director of ZTE cloud infrastructure open source and standards: open source risks and open source governance for enterprises

Robot Arm 机械臂源码解析

Pad in pytorch_ sequence、pack_ padded_ Sequence and pad_ packed_ Sequence function
PWN —— ret2libc1

Illustration and text demonstrate the movable range of the applet movable view

Oracle switches users and queries database commands under linux environment

centos7安装和卸载mysql5.7

阿里云盘 iOS /安卓版 3.8.0 更新,可根据清晰度缓存视频了

Iqiyi opens the authorization to Tiktok and opens a new door to the value of content

接口文档进化图鉴, 用过第一款接口文档工具的人暴露年龄了
随机推荐
Ropgadget -- ret2syscall
Introduction to distributed learning and federated learning
Selenium error reporting solution
Statement和PreparedStatement的区别及占位符使用方法
Why is the mobile phone signal poor when Im instant messaging is developed
Iqiyi opens the authorization to Tiktok and opens a new door to the value of content
开放原子开源基金会副秘书长刘京娟:中国开源发展现状及趋势思考
USACO data set (2022.07.22)
USACO资料集(2022.07.22)
node进程对象的属性
怎么为typora配置一个可爱的小鲨鱼主题?
Oracle switches users and queries database commands under linux environment
接口文档进化图鉴, 用过第一款接口文档工具的人暴露年龄了
Centos7 installing and uninstalling mysql5.7
The first PWN stack overflow simple question
R语言箱线图添加 t.test 显著性-
Stack overflow basic exercise question - 3 (with a comparison of 32 and 64 bit differences)
Context Encoders: Feature Learning by Inpainting 论文笔记
Drawing dumbbell diagram with R language
Linux环境下oracle切换用户并查询数据库命令