当前位置:网站首页>Handling write conflicts under multi-master replication (4) - multi-master replication topology
Handling write conflicts under multi-master replication (4) - multi-master replication topology
2022-07-31 15:32:00 【Huawei cloud】
The topology of replication describes the communication path through which write requests are propagated from one node to another.With two masters, as in Figure-7, there is only one reasonable topology: M1 must synchronize all his writes to M2, and vice versa.When there are more than two M, a variety of different topologies are possible.Figure-8 illustrates some examples.
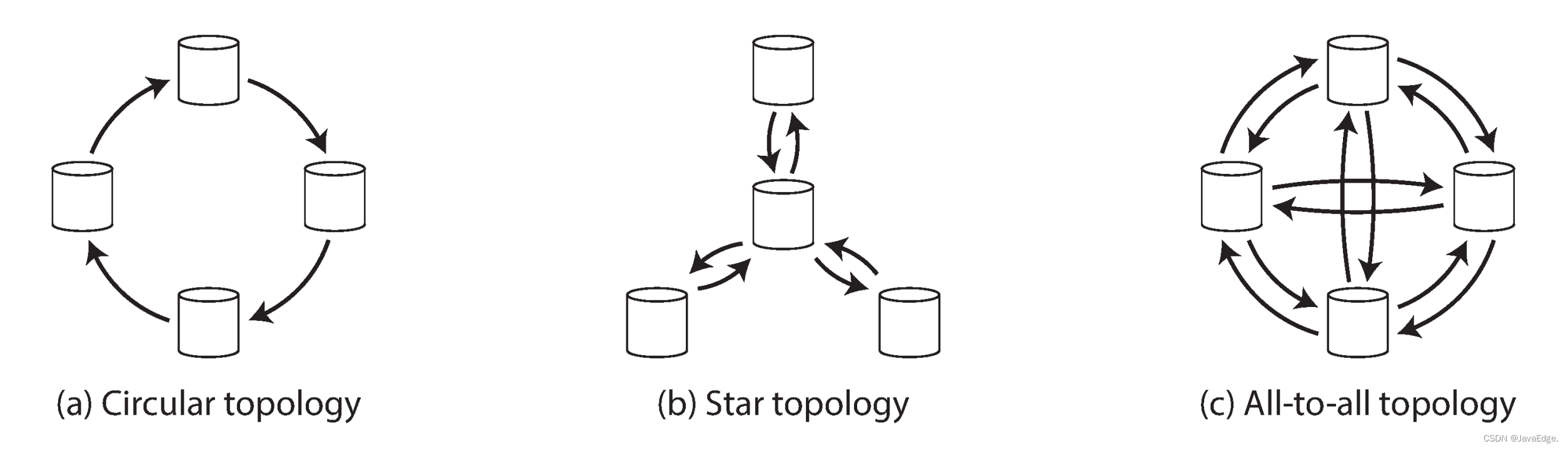
The most common topology is all-to-all, i.e. Figure-8, where each M synchronizes its writes to all other Ms.
But more restricted topologies are also used: for example, MySQL only supports circular topologies, where each node receives writes from the previous node and writes those writes (plus its own writes)In) forwarded to the subsequent node.
Another popular structure is the star shape ^v.A designated root node forwards writes to all other nodes.The star topology can be generalized to trees.
Ring, star topology
Write requests need to go through multiple nodes to reach all replicas, i.e. intermediate nodes need to forward data changes received from other nodes.To avoid infinite loops, each node needs to be assigned a unique identifier, and each write request in the replication log is marked with the identifiers of all nodes that have passed.When a node receives a data change marked with its own identifier, the data change will be ignored, avoiding repeated forwarding.
Questions
If a node fails, it may disrupt the flow of replicated messages between other nodes, rendering them unable to communicate until the node is repaired.Topologies can be reconfigured to work on failed nodes, but in most deployments this reconfiguration must be done manually.A more densely connected topology (such as all-to-all) is more fault-tolerant because it allows messages to travel along different paths, avoiding a single point of failure.
All-to-all topologies can also be problematic.Especially when some network links may be faster than others (network congestion), as a result some replicated messages may "overtake" others, as shown in Figure-9.
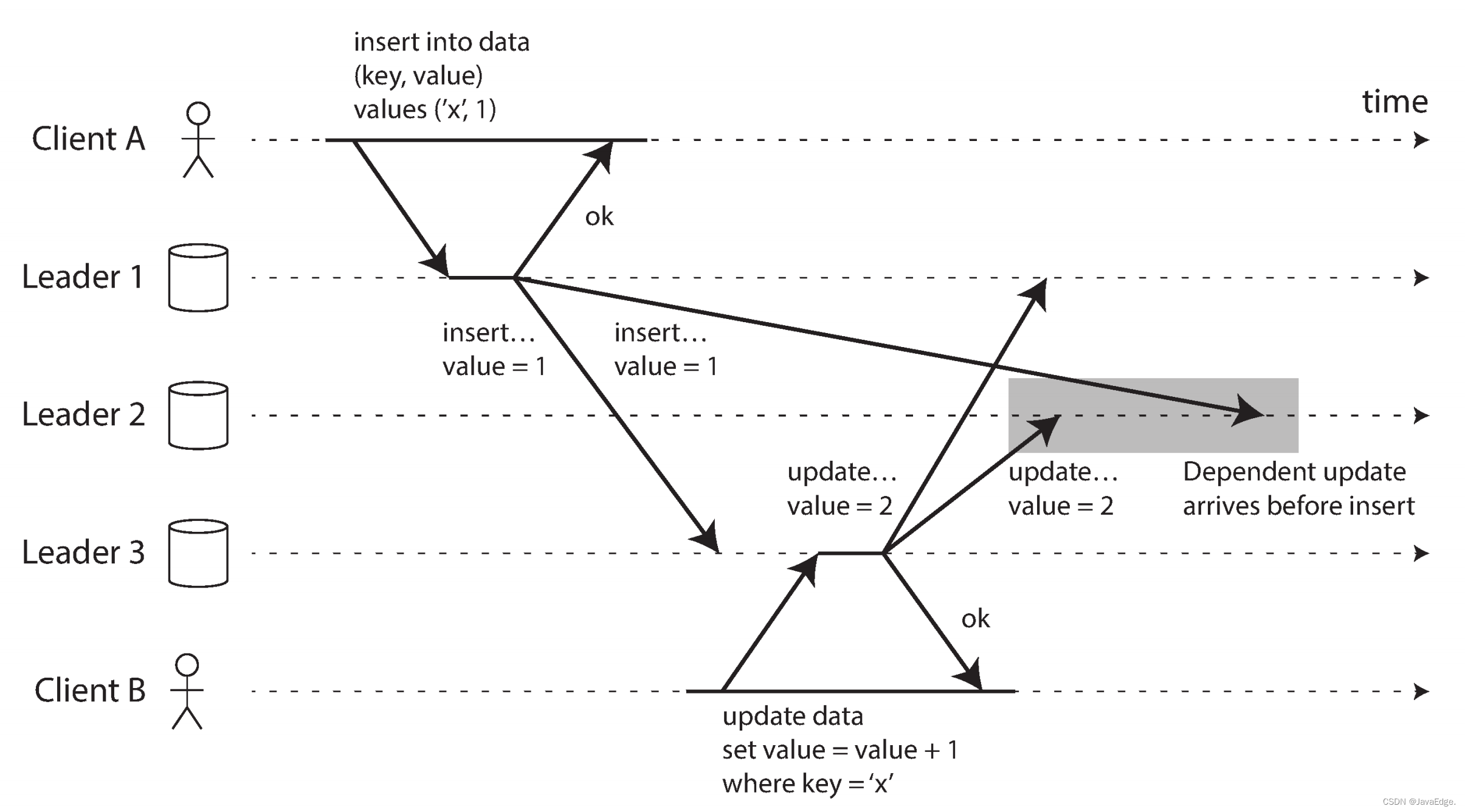 Client A sends L1A row is inserted into the table, and B updates the row in L3.However, L2 can receive writes in a different order: updates (from its perspective, updates to rows that don't exist in the database) can be received first, and then L1's insert log (which should arrive before the update log).
Client A sends L1A row is inserted into the table, and B updates the row in L3.However, L2 can receive writes in a different order: updates (from its perspective, updates to rows that don't exist in the database) can be received first, and then L1's insert log (which should arrive before the update log).
This is a causality problem, similar to "consistent prefix reads": updates depend on previously completed inserts, so make sure all nodes receive inserts before processing updates.Adding a timestamp to each log write is not enough, mainly because there is no way to ensure that the clocks are fully synchronized and thus the received logs cannot be ordered correctly on L2.
To properly order log messages, a version vector can be used.Conflict detection technology is not fully implemented in many primary replication systems.As PostgreSQL BDR does not provide causal ordering of writes, Tungsten Replicator for MySQL does not even attempt to detect conflicts.
边栏推荐
- mongo enters error
- Grafana安装后web打开报错
- 腾讯云部署----DevOps
- Oracle动态注册非1521端口
- The use of button controls
- R语言ggplot2可视化:使用ggpubr包的ggboxplot函数可视化箱图、使用font函数自定义图例标题文本(legend.title)字体的大小、颜色、样式(粗体、斜体)
- mysql black window ~ build database and build table
- Synchronized and volatile interview brief summary
- 三、数组
- Why don't you make a confession during the graduation season?
猜你喜欢

TRACE32 - Common Operations
Ubantu project 4: xshell, XFTP connected the virtual machine and set xshell copy and paste the shortcut
Ubantu专题4:xshell、xftp连接接虚拟机以及设置xshell复制粘贴快捷键

为什么毕业季不要表白?
Word表格转到Excel中
mongo enters error
Word table to Excel
![[CUDA study notes] First acquaintance with CUDA](/img/a2/f322ebe9dc483028f68882ee2c866b.png)
[CUDA study notes] First acquaintance with CUDA
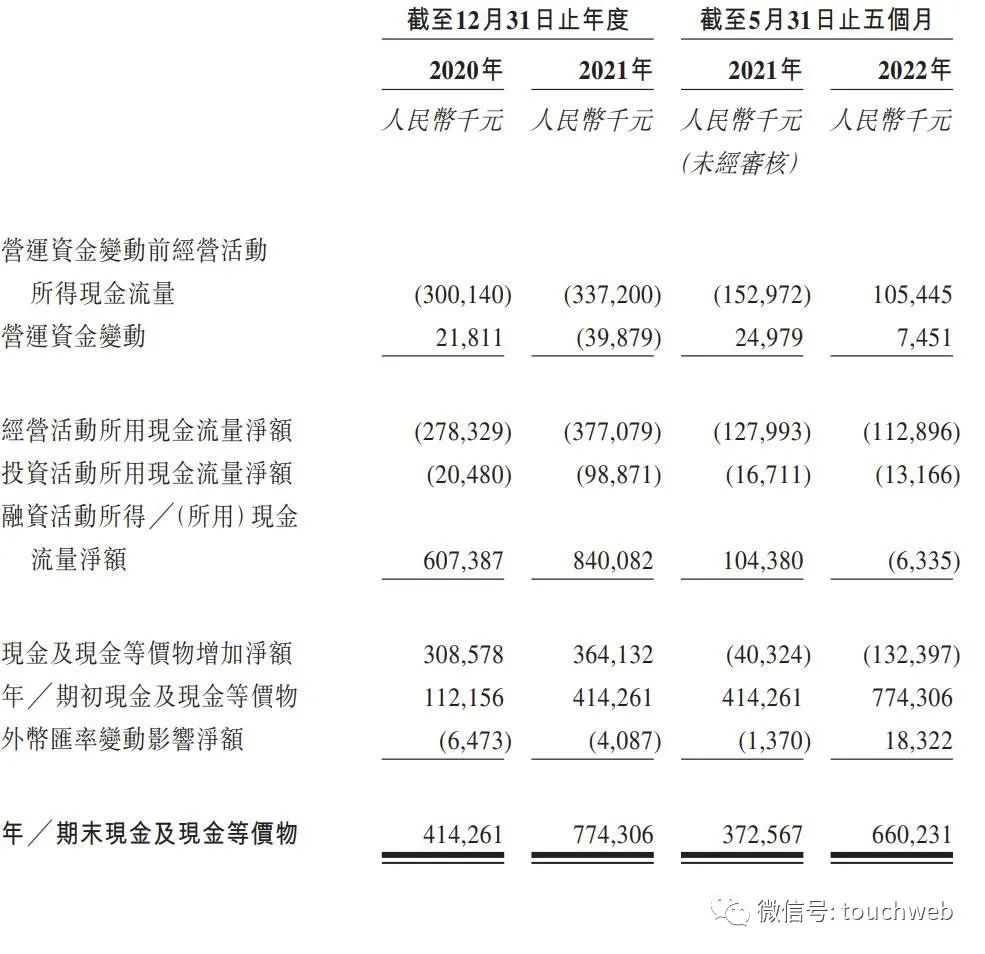
思路迪医药冲刺港股:5个月亏2.9亿 泰格医药与先声药业是股东

定时器的类型
随机推荐
基于ABP实现DDD
type of timer
R language ggplot2 visualization: use the ggboxplot function of the ggpubr package to visualize the grouped box plot, use the ggpar function to change the graphical parameters (caption, add, modify th
What is the difference between BI software in the domestic market?
Delete table data or clear table
R语言ggplot2可视化:使用ggpubr包的ggboxplot函数可视化箱图、使用font函数自定义图例标题文本(legend.title)字体的大小、颜色、样式(粗体、斜体)
Visualize GraphQL schemas with GraphiQL
双边滤波加速「建议收藏」
Tencent Cloud Deployment----DevOps
工程水文学名词解释总结
C语言”三子棋“升级版(模式选择+AI下棋)
修改SQL语言实现Mysql 多表关联查询优化
Gorm—Go语言数据库框架
Emmet 语法
最小费用最大流问题详解
多主复制的适用场景(2)-需离线操作的客户端和协作编辑
radiobutton的使用
ASP.NET Core generates continuous Guid
Insert into data table to insert data
乡村基冲刺港交所:5个月期内亏2224万 SIG与红杉中国是股东