当前位置:网站首页>量化交易入门教程
量化交易入门教程
2022-06-27 20:19:00 【小熊coder】
一、百科定义
量化交易是指以先进的数学模型替代人为的主观判断,利用计算机技术从庞大的历史数据中海选能带来超额收益的多种“大概率”事件以制定策略,极大地减少了投资者情绪波动的影响,避免在市场极度狂热或悲观的情况下作出非理性的投资决策。
国外市场
首先,从全球市场的参与主体来看,按照管理资产的规模,2018年全球排名前六位中的五家资管机构,都是依靠计算机技术来开展投资决策,而且进入2019年由量化及程序化交易所管理的资金规模进一步扩大。
其次,全球超70%的资金交易用计算机或者程序进行,其中一半是由量化或者程序化的管理人来操盘。在国外招聘网站搜索金融工程师(包括量化、数据科学等关键词)会出现超过33万个相关岗位。
第三,从高校的培养方向来看,已有超过450所美国大学设置了金融工程专业,每年相关专业毕业生达到1.5万人,市场需求与毕业生数量的差距显著,因此数据科学、计算机科学、会计以及相关STEM(基础科学)学生毕业后进入金融行业从事量化分析和应用开发的相关工作。 [1]
国内发展趋势
目前国内量化投资规模大概是3500到4000亿人民币,其中公募基金1200亿,其余为私募量化基金,数量达300多家,占比3%(私募管理人共9000多家),金额在2000亿左右。中国证券基金的整体规模超过16万亿,其中公募14万亿,私募2.4万亿,乐观估计,量化基金管理规模在国内证券基金的占比在1%~2%,在公募证券基金占比不到1%,在私募证券基金占比5%左右,相比国外超过30%的资金来自于量化或者程序化投资,国内未来的增长空间巨大。 [1]
交易特点
量化投资和传统的定性投资本质上来说是相同的,二者都是基于市场非有效或弱有效的理论基础。两者的区别在于量化投资管理是“定性思想的量化应用”,更加强调数据。量化交易具有以下几个方面的特点:
1、纪律性。根据模型的运行结果进行决策,而不是凭感觉。纪律性既可以克制人性中贪婪、恐惧和侥幸心理等弱点,也可以克服认知偏差,且可跟踪。
2、系统性。具体表现为“三多”。一是多层次,包括在大类资产配置、行业选择、精选具体资产三个层次上都有模型;二是多角度,定量投资的核心思想包括宏观周期、市场结构、估值、成长、盈利质量、分析师盈利预测、市场情绪等多个角度;三是多数据,即对海量数据的处理。
3、套利思想。定量投资通过全面、系统性的扫描捕捉错误定价、错误估值带来的机会,从而发现估值洼地,并通过买入低估资产、卖出高估资产而获利。
4、概率取胜。一是定量投资不断从历史数据中挖掘有望重复的规律并加以利用;二是依靠组合资产取胜,而不是单个资产取胜。
应用
量化投资技术包括多种具体方法,在投资品种选择、投资时机选择、股指期货套利、商品期货套利、统计套利和算法交易等领域得到广泛应用。在此,以统计套利和算法交易为例进行阐述。
1、统计套利 [2]
统计套利是利用资产价格的历史统计规律进行的套利,是一种风险套利,其风险在于这种历史统计规律在未来一段时间内是否继续存在。
统计套利的主要思路是先找出相关性最好的若干对投资品种,再找出每一对投资品种的长期均衡关系(协整关系),当某一对品种的价差(协整方程的残差)偏离到一定程度时开始建仓,买进被相对低估的品种、卖空被相对高估的品种,等价差回归均衡后获利了结。股指期货对冲是统计套利较常采用的一种操作策略,即利用不同国家、地区或行业的指数相关性,同时买入、卖出一对指数期货进行交易。在经济全球化条件下,各个国家、地区和行业股票指数的关联性越来越强,从而容易导致股指系统性风险的产生,因此,对指数间的统计套利进行对冲是一种低风险、高收益的交易方式。
2、算法交易。
算法交易又称自动交易、黑盒交易或机器交易,是指通过设计算法,利用计算机程序发出交易指令的方法。在交易中,程序可以决定的范围包括交易时间的选择、交易的价格,甚至包括最后需要成交的资产数量。
算法交易的主要类型有: (1) 被动型算法交易,也称结构型算法交易。该交易算法除利用历史数据估计交易模型的关键参数外,不会根据市场的状况主动选择交易时机和交易的数量,而是按照一个既定的交易方针进行交易。该策略的的核心是减少滑价(目标价与实际成交均价的差)。被动型算法交易最成熟,使用也最为广泛,如在国际市场上使用最多的成交加权平均价格(VWAP)、时间加权平均价格(TWAP)等都属于被动型算法交易。 (2) 主动型算法交易,也称机会型算法交易。这类交易算法根据市场的状况作出实时的决策,判断是否交易、交易的数量、交易的价格等。主动型交易算法除了努力减少滑价以外,把关注的重点逐渐转向了价格趋势预测上。 (3) 综合型算法交易,该交易是前两者的结合。这类算法常见的方式是先把交易指令拆开,分布到若干个时间段内,每个时间段内具体如何交易由主动型交易算法进行判断。两者结合可达到单纯一种算法无法达到的效果。
算法交易的交易策略有三:一是降低交易费用。大单指令通常被拆分为若干个小单指令渐次进入市场。这个策略的成功程度可以通过比较同一时期的平均购买价格与成交量加权平均价来衡量。二是套利。典型的套利策略通常包含三四个金融资产,如根据外汇市场利率平价理论,国内债券的价格、以外币标价的债券价格、汇率现货及汇率远期合约价格之间将产生一定的关联,如果市场价格与该理论隐含的价格偏差较大,且超过其交易成本,则可以用四笔交易来确保无风险利润。股指期货的期限套利也可以用算法交易来完成。三是做市。做市包括在当前市场价格之上挂一个限价卖单或在当前价格之下挂一个限价买单,以便从买卖差价中获利。此外,还有更复杂的策略,如“基准点“算法被交易员用来模拟指数收益,而”嗅探器“算法被用来发现最动荡或最不稳定的市场。任何类型的模式识别或者预测模型都能用来启动算法交易。
潜在风险
量化交易一般会经过海量数据仿真测试和模拟操作等手段进行检验,并依据一定的风险管理算法进行仓位和资金配置,实现风险最小化和收益最大化,但往往也会存在一定的潜在风险,具体包括:
1、历史数据的完整性。行情数据不完整可能导致模型与行情数据不匹配。行情数据自身风格转换,也可能导致模型失败,如交易流动性,价格波动幅度,价格波动频率等,而这一点是量化交易难以克服的。
2、模型设计中没有考虑仓位和资金配置,没有安全的风险评估和预防措施,可能导致资金、仓位和模型的不匹配,而发生爆仓现象。
3、网络中断,硬件故障也可能对量化交易产生影响。
4、同质模型产生竞争交易现象导致的风险。
5、单一投资品种导致的不可预测风险。
为规避或减小量化交易存在的潜在风险,可采取的策略有:保证历史数据的完整性;在线调整模型参数;在线选择模型类型;风险在线监测和规避等。
量化策略
量化策略是指使用计算机作为工具,通过一套固定的逻辑来分析、判断和决策。量化策略既可以自动执行,也可以人工执行。 [3]
一个完整的量化策略包含哪些内容?
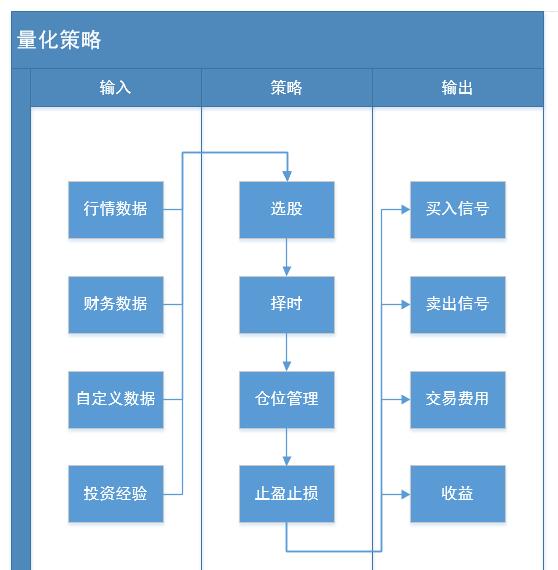 量化策略
量化策略
一个完整的策略需要包含输入、策略处理逻辑、输出;策略处理逻辑需要考虑选股、择时、仓位管理和止盈止损等因素。
选股
量化选股就是用量化的方法选择确定的投资组合,期望这样的投资组合可以获得超越大盘的投资收益。常用的选股方法有多因子选股、行业轮动选股、趋势跟踪选股等。
1 多因子选股
多因子选股是最经典的选股方法,该方法采用一系列的因子(比如市盈率、市净率、市销率等)作为选股标准,满足这些因子的股票被买入,不满足的被卖出。
2 风格轮动选股
风格轮动选股是利用市场风格特征进行投资,市场在某个时刻偏好大盘股,某个时刻偏好小盘股,如果发现市场切换偏好的规律,并在风格转换的初期介入,就可能获得较大的收益。
3 行业轮动选股
行业轮动选股是由于经济周期的的原因,有些行业启动后会有其他行业跟随启动,通过发现这些跟随规律,我们可以在前者启动后买入后者获得更高的收益,不同的宏观经济阶段和货币政策下,都可能产生不同特征的行业轮动特点。
4 资金流选股
资金流选股是利用资金的流向来判断股票走势。巴菲特说过,股市短期是投票机,长期看一定是称重机。短期投资者的交易,就是一种投票行为,而所谓的票,就是资金。如果资金流入,股票应该会上涨,如果资金流出,股票应该下跌。所以根据资金流向就可以构建相应的投资策略。
5 动量反转选股
动量反转选股方法是利用投资者投资行为特点而构建的投资组合。索罗斯所谓的反身性理论强调了价格上涨的正反馈作用会导致投资者继续买入,这就是动量选股的基本根据。动量效应就是前一段强势的股票在未来一段时间继续保持强势。在正反馈到达无法持续的阶段,价格就会崩溃回归,在这样的环境下就会出现反转特征,就是前一段时间弱势的股票,未来一段时间会变强。
6 趋势跟踪策略
当股价在出现上涨趋势的时候进行买入,而在出现下降趋势的时候进行卖出,本质上是一种追涨杀跌的策略,很多市场由于羊群效用存在较多的趋势,如果可以控制好亏损时的额度,坚持住对趋势的捕捉,长期下来是可以获得额外收益的。
择时
量化择时是指采用量化的方式判断买入卖出点。如果判断是上涨,则买入持有;如果判断是下跌,则卖出清仓;如果判断是震荡,则进行高抛低吸。
常用的择时方法有:趋势量化择时、市场情绪量化择时、有效资金量化择时、SVM量化择时等。
仓位管理
仓位管理就是在你决定投资某个股票组合时,决定如何分批入场,又如何止盈止损离场的技术。
常用的仓位管理方法有:漏斗型仓位管理法、矩形仓位管理法、金字塔形仓位管理法等
止盈止损
止盈,顾名思义,在获得收益的时候及时卖出,获得盈利;止损,在股票亏损的时候及时卖出股票,避免更大的损失。
及时的止盈止损是获取稳定收益的有效方式。
策略的生命周期
一个策略往往会经历产生想法、实现策略、检验策略、运行策略、策略失效几个阶段。
产生想法
任何人任何时间都可能产生一个策略想法,可以根据自己的投资经验,也可以根据他人的成功经验。
实现策略
产生想法到实现策略是最大的跨越,实现策略可以参照上文提到的“一个完整的量化策略包含哪些内容?”
检验策略
策略实现之后,需要通过历史数据的回测和模拟交易的检验,这也是实盘前的关键环节,筛选优质的策略,淘汰劣质的策略。
实盘交易
投入资金,通过市场检验策略的有效性,承担风险,赚取收益。
策略失效
市场是千变万化的,需要实时监控策略的有效性,一旦策略失效,需要及时停止策略或进一步优化策略。
二、量化交易入门
已剪辑自: https://cuijiahua.com/blog/2021/07/qt-1.html
摘要量化交易的入门级教程,Jack 的理财之路
老读者应该知道,我炒股两年多了。
从最开始的基金,到后来的股票,金额一直不大,最多就加到30万。
涨势最好的时候,差不多每天能有个近万的浮盈,偶尔还有过浮盈近两万的时候。

自从今年2月份,股市开启困难模式后,这样的好日子就到头了。
年初,大几万的浮盈,也折损了大半,再加上今年计划要用到大钱,身体被掏空的那种。

股市投资这块就保守了很多,基本固定在10万左右的低仓位,重在参与了。
一直有读者想看我理财类的文章,最开始应允下来,后来仔细想了想。
你说,我一个技术类博主,写理财,那不是不务正业吗?
况且,我也不是学金融出身的,虽然凭运气在股市赚过一些小钱,但毕竟咱不是专业的,不敢乱指挥。
最近突然转念一想,理财+技术,这个路子我倒是可以。
我很喜欢学新知识,不仅仅局限于计算机技术,时刻保持一颗好奇心,什么都想学点。
正好,近期打算出一篇量化交易的视频,探讨探讨人工智能技术,在投资股市这件事上的应用。
学着学着,我发现,这里面的水挺深,量化交易,并没有我想像的那么好做,要学的知识有点多。
上周末,我花费了一天的时间,算是刚刚入个门。
**今天,先整理分享下,量化交易的基础知识,**为视频做个热身。
量化交易
量化交易就是,借助现代统计学和数学的方法,利用计算机技术来进行交易的证券投资方式。
主要涵盖的知识点如下:

数学、编程、金融、算法都得懂,哪里不会补哪里就行。
量化平台
抓数据,写策略,在线交易,如果自己一个人来做,成本太高,不利于初期的学习。
我调研了一些量化分析平台,可以帮助我们聚焦到学习量化交易的策略学习上。
我觉得可以用来入门的平台有:
- 聚宽
- vnpy
量化交易的平台有很多,比如掘金、米筐、优矿等。
但适合入门的,可以直接看这聚宽和vnpy。
聚宽的社区比较活跃,有不少技术教程,适合新手入门。
https://www.joinquant.com/study
这里的知识点,就有不少可以学习,同时还有很多大佬分享自己的策略。
vnpy推荐的原因在于它是开源的,可以系统学习如何构建一个量化交易系统。
https://github.com/vnpy/vnpy
如果想自己实现一个量化交易的框架,可以从这里参考很多代码。
小试牛刀
聚宽量化交易平台的使用,比较简单。
我们以这个平台为例,讲解一个简单的量化策略。
我们回归问题的本质,买股票无非两点:
- 买哪支股票
- 何时买,何时卖
1、买哪支股票
投资者,选股票,最直接的就是看财务报表。
至少是包括资产负债表、损益表、现金流量表,这三表。
这里的数据就太多了,每个表都有各种各样的指标。
这些指标数据,在量化交易里,叫因子。
我理解,就是我们机器学习中,常说的特征,每一个因子都可以算作一个维度的特征。
我们可以,利用这些已知的数据,构建多维的特征数据,然后将它交给机器学习算法,让算法判断这只股票,值不值得购买。
这又回到了,做算法的老生常谈的问题,选择哪些特征,去拟合数据。
妥了,特征工程走起。

这些最底层的特征,属于一种基础的因子。
在量化交易中,还可以根据这些数据,计算出更“高维”的因子,即特征。
比如净资产收益率,英文缩写叫ROE。
净资产收益率就是公司税后利润除以净资产得到的百分比率。
即,净资产收益率=净利润/净资产
净利润,在利润表里,净资产,在资产负债表。
净资产收益率反映股东权益的收益水平,用以衡量公司运用自有资本的效率。
指标值越高,说明投资带来的收益越高。该指标体现了自有资本获得净收益的能力。
净资产收益率,就是通过一些“低维”的特征,计算出的“高维”的特征。
选股票,其实就是根据这些指标,选择出,你认为值得投资的股票。
为了简化策略,这里就简单的,单一的,利用这个净资产收益率ROE,作为我们的价值选股思想的指标。
简单暴力一点,计算当前所有股票的ROE,由大到小排序,选择top10,作为我们的股票持仓。
2、何时买,何时卖
投资者,都想买在低点,卖在高点。
10块钱买,100块卖,赚个差价,赚了90。
这个问题的本质就是:低买高卖。
但现实往往是残酷的。

何时买,何时卖,在量化交易中,有个指标,阻力支撑相对强度,即RSRS。
了解,阻力支撑相对强度,首先要知道什么是阻力位和支撑位。
阻力位是指目标价格上涨时可能遇到的压力,即交易者认为卖方力量开始反超买方,从而价格难以继续上涨或从此回调下跌的价位;
支撑位则是交易者认为买方力量开始反超卖方,从而止跌或反弹上涨的价位。
阻力支撑相对强度是一种阻力位与支撑位的运用方式,它不再把阻力位与支撑位当做一个定值,而是看做一个变量,反应了交易者对目前市场状态顶底的一种预期判断。
我们按照不同市场状态分类来说明支撑阻力相对强度的应用逻辑:
市场在上涨牛市中:
- 如果支撑明显强于阻力,牛市持续,价格加速上涨
- 如果阻力明显强于支撑,牛市可能即将结束,价格见顶
市场在震荡中:
- 如果支撑明显强于阻力,牛市可能即将启动
- 如果阻力明显强于支撑,熊市可能即将启动
市场在下跌熊市中:
- 如果支撑明显强于阻力,熊市可能即将结束,价格见底
- 如果阻力明显强于支撑,熊市持续,价格加速下跌
每日最高价和最低价是一种阻力位与支撑位,它是当日全体市场参与者的交易行为所认可的阻力与支撑。一个很自然的想法是建立最高价和最低价的线性回归,并计算出斜率。即:
当斜率值很大时,支撑强度大于阻力强度。在牛市中阻力渐小,上方上涨空间大;在熊市中支撑渐强,下跌势头欲止。
当斜率值很小时,阻力强度大于支撑强度。在牛市中阻力渐强,上涨势头渐止;在熊市中支撑渐松,下方下跌空间渐大。
RSRS指标的计算,有两种方法,第一种方法是直接将斜率作为指标值,第二种方法是在斜率基础上进行标准化。
以第二种方法为例,RSRS斜率标准分指标择时策略如下:
- 取前M日的RSRS斜率时间序列。(M = 600)
- 计算当日RSRS斜率的标准分
其中,为前M日的斜率均值,为前M日的标准差。
\3. 若大于,则全仓买入;若小于,则卖出平仓。
其中,。
小试牛刀
OK,买哪支股票,以及何时买,何时卖,这两个问题解决了,我们就可以开始写代码了。
这里需要先掌握,聚宽的使用方法,以及一些api。
这部分比较简单,直接平台的官方手册就行。
编写如下代码:
Python
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167 | ‘’‘策略思路:选股:财务指标选股择时:RSRS择时持仓:有开仓信号时持有10只股票,不满足时保持空仓 ‘’’# 导入函数库import statsmodels.api as smfrom pandas.stats.api import ols # 初始化函数,设定基准等等def initialize(context): # 开启动态复权模式(真实价格) set_option(‘use_real_price’, True) # 过滤掉order系列API产生的比error级别低的log # log.set_level(‘order’, ‘error’) set_parameter(context) ### 股票相关设定 ### # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock’) ## 运行函数(reference_security为运行时间的参考标的;传入的标的只做种类区分,因此传入’000300.XSHG’或’510300.XSHG’是一样的) # 开盘前运行 run_daily(before_market_open, time=‘before_open’, reference_security=‘000300.XSHG’) # 开盘时运行 run_daily(market_open, time=‘open’, reference_security=‘000300.XSHG’) # 收盘后运行 #run_daily(after_market_close, time=‘after_close’, reference_security=‘000300.XSHG’) ‘’‘参数设置部分==’‘‘def set_parameter(context): # 设置RSRS指标中N, M的值 #统计周期 g.N = 18 #统计样本长度 g.M = 1100 #首次运行判断 g.init = True #持仓股票数 g.stock_num = 10 #风险参考基准 g.security = ‘000300.XSHG’ # 设定策略运行基准 set_benchmark(g.security) #记录策略运行天数 g.days = 0 #set_benchmark(g.stock) # 买入阈值 g.buy = 0.7 g.sell = -0.7 #用于记录回归后的beta值,即斜率 g.ans = [] #用于计算被决定系数加权修正后的贝塔值 g.ans_rightdev= [] # 计算2005年1月5日至回测开始日期的RSRS斜率指标 prices = get_price(g.security, ‘2005-01-05’, context.previous_date, ‘1d’, [‘high’, ‘low’]) highs = prices.high lows = prices.low g.ans = [] for i in range(len(highs))[g.N:]: data_high = highs.iloc[i-g.N+1:i+1] data_low = lows.iloc[i-g.N+1:i+1] X = sm.add_constant(data_low) model = sm.OLS(data_high,X) results = model.fit() g.ans.append(results.params[1]) #计算r2 g.ans_rightdev.append(results.rsquared) ## 开盘前运行函数 def before_market_open(context): # 输出运行时间 #log.info(‘函数运行时间(before_market_open):’+str(context.current_dt.time())) g.days += 1 # 给微信发送消息(添加模拟交易,并绑定微信生效) send_message(‘策略正常,运行第%s天~’%g.days) ## 开盘时运行函数def market_open(context): security = g.security # 填入各个日期的RSRS斜率值 beta=0 r2=0 if g.init: g.init = False else: #RSRS斜率指标定义 prices = attribute_history(security, g.N, ‘1d’, [‘high’, ‘low’]) highs = prices.high lows = prices.low X = sm.add_constant(lows) model = sm.OLS(highs, X) beta = model.fit().params[1] g.ans.append(beta) #计算r2 r2=model.fit().rsquared g.ans_rightdev.append(r2) # 计算标准化的RSRS指标 # 计算均值序列 section = g.ans[-g.M:] # 计算均值序列 mu = np.mean(section) # 计算标准化RSRS指标序列 sigma = np.std(section) zscore = (section[-1]-mu)/sigma #计算右偏RSRS标准分 zscore_rightdev= zscorebetar2 # 如果上一时间点的RSRS斜率大于买入阈值, 则全仓买入 if zscore_rightdev > g.buy: # 记录这次买入 log.info(“市场风险在合理范围”) #满足条件运行交易 trade_func(context) # 如果上一时间点的RSRS斜率小于卖出阈值, 则空仓卖出 elif (zscore_rightdev < g.sell) and (len(context.portfolio.positions.keys()) > 0): # 记录这次卖出 log.info(“市场风险过大,保持空仓状态”) # 卖出所有股票,使这只股票的最终持有量为0 for s in context.portfolio.positions.keys(): order_target(s, 0) #策略选股买卖部分 def trade_func(context): #获取股票池 df = get_fundamentals(query(valuation.code,valuation.pb_ratio,indicator.roe)) #进行pb,roe大于0筛选 df = df[(df[‘roe’]>0) & (df[‘pb_ratio’]>0)].sort(‘pb_ratio’) #以股票名词作为index df.index = df[‘code’].values #取roe倒数 df[‘1/roe’] = 1/df[‘roe’] #获取综合得分 df[‘point’] = df[[‘pb_ratio’,‘1/roe’]].rank().T.apply(f_sum) #按得分进行排序,取指定数量的股票 df = df.sort(‘point’)[:g.stock_num] pool = df.index log.info(‘总共选出%s只股票’%len(pool)) #得到每只股票应该分配的资金 cash = context.portfolio.total_value/len(pool) #获取已经持仓列表 hold_stock = context.portfolio.positions.keys() #卖出不在持仓中的股票 for s in hold_stock: if s not in pool: order_target(s,0) #买入股票 for s in pool: order_target_value(s,cash)#打分工具def f_sum(x): return sum(x) ## 收盘后运行函数 def after_market_close(context): #得到当天所有成交记录 trades = get_trades() for _trade in trades.values(): log.info(‘成交记录:’+str(_trade)) #打印账户总资产 log.info(‘今日账户总资产:%s’%round(context.portfolio.total_value,2)) #log.info(’##############################################################’) |
|---|---|
左边写好代码,输入回测时间和金额就可以运行了。

我直接回测了2010年1月到2020年1月效果,投资十年的收益:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wZGtjo9t-1656245804019)(https://cuijiahua.com/wp-content/uploads/2021/07/qt-7.png)]
直接起飞,初始资金50万,赚了几百万,很稳!

我又回测了2020年1月到2021年6月,一年半的收益:

跑输大盘8.35%,不过也没亏,年化率也能有个11.40%,还可以吧。
总结
这个策略,没有用到历史数据,是根据当前的一些指标进行决策的。
投资理财,这方面的知识,还是要学习的,不投资股市,买个银行定期这些也挺好。
我们寒窗苦读,一方面就是想学有所成,赚钱,过个舒服的生活。
学校教我们各种基础知识,唯独很少直接地教我们,如何去赚钱,去理财,管理自己的财富。
所以,自学吧。人生在于折腾,各种知识都学学,挺好,挺有意思。
现在,虽然股市是困难模式,但是仍然有很多机会,我们也可以利用这个时间,补充自己的知识。
年入百万,对于现在的我来说,还是洗洗睡吧,梦里什么都有。
本期硬核,喜欢的朋友,转发,点赞走一波,让我瞧一瞧~
感兴趣的人多,后面继续出。
我是 Jack,我们下期见!
三、如何自学量化
我刚知道有知乎这个社群之后就关注了这个问题,并且看完了下面好多大佬们的回答。没想到4年之后,也有人来邀请我答这个问题。
先说说我对学习这个事情本身的看法:学习这个事情,个体差异很大,尤其是非全日制的学习(我主要指的是自学)。因为大家能够接触到的知识来源不一致,加上没有任何的约束,在学习的时间安排,学习效率,效果检验等方面都会存在不同的问题。我是一个纯粹的自学者,多年的自学让我练就一套自学体系,那我就从我自己的经验出发来说说学习的事情。自学最大的难度不是知识的复杂度,而是自我坚持和最优化的学习路径问题。先说说自我坚持,看书会犯困、注意力集中的时间不长,嘈杂的事情会干扰中断学习,畏难情绪、拖延症、懒癌这些问题我也是存在的。要克服这些问题其实是反人性的,痛苦自不必说了。但人为达目的总是会想办法解决,我的解决方案就是以下几点:坚持。坚持是一种习惯的最佳培养方式,到点必须执行某种动作,长期坚持。我就坚持看出,到点就执行,哪怕打开书我就犯困,走神,也要坚持执行,而且坚持看30分及以上。训练速读速记的能力。这个技能是自学者的必备技能,因为他可以帮你充分利用碎片时间。这个技能经常会给我带来惊喜,长期大量的碎片信息记忆积累,会在不经意的某天链接成知识块,也为我进行系统学习时提供充足的素材、提高学习效率。最重要的一点是,它是灵感的重要来源。建立学习正反馈机制。为什么人喜欢玩游戏,尤其是电子游戏,有人专门分析过这个问题,那就是游戏有及时的反馈,然玩家随时获得成就感,所以就会不断的投入注意力。我也为自己在学习问题上建立了很多正反馈机制,例如,如果一周内我的学习时间达到10小时,我就会去吃点好吃的。如果超过15小时,我就会去买点自己想要的。如果超过20小时,我就会在周日给自己放一个小假。再例如,激发自己的好奇心和欲望,让自己能够想要去知道结果,或者急切的渴望达成。再再例如,让自己中二一点,给这件事情赋予一个神圣的意义,让整个事情充满仪式感。。。。与自己的终极目标相结合。这个其实是第三条的超级加强版,其实很多人都论述过这个观点,那就是把一件辛苦的事情和自己的终极目标相结合,那么这件事情会变得非常有乐趣,谁劝都没用。丰富的学习手段。这个主要是看个人的爱好了,我的做法是把记笔记变成一种乐趣,我纸质笔记和电子笔记都用,还买了彩色笔丰富笔记颜色。总之就是弄一些让自己能够愉悦的学习工具来使用。

说法学习本身的问题,接下来说说学习路径的问题:自学最大的问题是没人能告诉你学习的正确路径是什么,你的技能树应该怎么爬。我也被这个问题坑过,之所有花费了好多年时间来进行学习,其实就是属于走迷宫走进了死胡同又退回去重新走而耽误的。不过还好,事情总会过去,困难总会克服,我总结出了一条正确的学习路径:无论你有否编程背景,请先从编程学起。如果已经会编程,那么请加强这种技能。就我个人的人生经验来看,编程这个技能是我所有技能中最有用,最救命的技能。其次,编程也是这个时代最好的技能。就因为我具备了这个技能,并且加强了它,我掌握了matlab,python,这是我最先掌握的两种编程语言。其实在此之前,我学过c和c#,有一定的编程经验。无论你有否数学背景,请先从数学基础学起。说到这一点,我不得不感谢我的编程技能,因为掌握了matlab和python,让我这个学渣能够在2-3年间把数学工具给掌握了。对于最开始除加减乘除之外一概看不懂的人,到掌握运算原理,最后掌握统计学,线代,离散,微积分这些内容。不知道有没有人告诉过你,matlab和python不单可以自动解函数,还可以展示运算过程中的数值传递和转换。无论你有否金融学背景,请先把金融学给学一遍。金融学其实一系列数学在金融领域的应用,主要还是大堆的推导和证明。另外还有一个重要的内容就是,一些数学概念换到金融领域里,会被换成另外一个名称,如果是专门的学习,你根本不知道他们说的同一回事。无论你有否英语背景,请把英语学好。不得不承认,国外的相关资料就是要比国内多,书籍、文献、论文等,不要让英语成为你的绊脚石。(我在努力补英语,它是我的绊脚石)完成以上内容学习,大概需要花费大约3-4年时间,如果你有基础或者天资过人,那么这个时间大约可以缩短30%-50%左右。有了基础之后,我们现在才是正在的真正的量化交易的征途,依然还是没有人来指引学习路径的问题:增加阅读量。有关量化的一切书籍,网文,知乎等等。阅读他们,从中找线索,找方向。从模仿开始。找一个简单的策略,自己编程实现一遍,理解它的每个技术细节,从策略设计思路到系统实现。读论文。读论文是非常有好处的,这个论文不单单是指各大高校里正式发表的文献,同时也包括各位量化大佬在自己的微博,博客,知乎,论坛等媒体上认真写下的文字。最好就是把文章里的东西尽可能的复现一遍。说道复现,重点来了,如果前面说道的四个基础你都掌握的话,那么你读文章及复现结果的能力会得到加强。你会的编程语言越多,你能读的和复现的内容也就越多。毕竟量化大佬们的编程偏好不一样,如果你都会,就不会被这个问题所阻碍。例如,美国一群来自耶鲁、伯克利在华尔街工作的大佬偏好matlab。而来自英国,或者是美国硅谷系的大佬们偏爱python和java。动手能力。话说千里之行始于足下,在好的想法也需要动手实践。不要怕辛苦和失败,反复动作实验才是王道。 好的,到这里整个自学量化的路径,我已经基本写完了。下面附上一个我的个人零散的小经验:除非你清楚的知道这个系统的源代码及工作细节,否则尽量不要使用现成的交易系统和回测系统。(这方面,国内几个python量化平台做的不错,至少让你知道源代码的内容)做实验不能使用穷举法,必须使用A/B test的体系来完成实验设计和实施。有些简单的基础原理,你不能忽视,它往往就是真理。没有圣杯,没有圣杯,没有圣杯。没有完美参数,没有完美参数,没有完美参数。学习没有那么多的浪漫,辛苦前行才是主旋律。如果你总想着循序渐进的入门,那么你根本就找不到门。不要想太多,直接上路就好。基础技能的积累和强化,胜过具体策略的模仿和研究。
好的,到这里整个自学量化的路径,我已经基本写完了。下面附上一个我的个人零散的小经验:除非你清楚的知道这个系统的源代码及工作细节,否则尽量不要使用现成的交易系统和回测系统。(这方面,国内几个python量化平台做的不错,至少让你知道源代码的内容)做实验不能使用穷举法,必须使用A/B test的体系来完成实验设计和实施。有些简单的基础原理,你不能忽视,它往往就是真理。没有圣杯,没有圣杯,没有圣杯。没有完美参数,没有完美参数,没有完美参数。学习没有那么多的浪漫,辛苦前行才是主旋律。如果你总想着循序渐进的入门,那么你根本就找不到门。不要想太多,直接上路就好。基础技能的积累和强化,胜过具体策略的模仿和研究。
暂时就想到这么多,祝大家学习愉快。
四、量化交易平台学习
五、优秀文章分享
https://www.joinquant.com/view/community/detail/454296e2eefcbb30f27313119ac2bb36?type=1
边栏推荐
- [microservices] (16) -- distributed transaction Seata
- OData - API using SAP API hub in SAP S4 op
- Follow the archiving tutorial to learn rnaseq analysis (III): count standardization using deseq2
- 中金证券经理给的开户链接办理股票开户安全吗?我想开个户
- Kill the general and seize the "pointer" (Part 2)
- Azure Kinect DK 实现三维重建 (PC非实时版)
- Livox lidar+ Haikang camera generates color point cloud in real time
- 基于 ESXi 的黑群晖 DSM 7.0.1 安装 VMware Tools
- 个人TREE ALV 模版-加快你的开发
- First knowledge of the second bullet of C language
猜你喜欢
![[microservices] (16) -- distributed transaction Seata](/img/1b/aeb534d5a0bd40f5fc14e64bdf5aa9.png)
[microservices] (16) -- distributed transaction Seata

Character interception triplets of data warehouse: substrb, substr, substring

资深猎头团队管理者:面试3000顾问,总结组织出8大共性(茅生)

基于 ESXi 的黑群晖 DSM 7.0.1 安装 VMware Tools

Penetration learning - shooting range chapter - detailed introduction to Pikachu shooting range (under continuous update - currently only the SQL injection part is updated)

Livox Lidar+APX15 实时高精度雷达建图复现整理
Spark bug practice (including bug:classcastexception; connectexception; NoClassDefFoundError; runtimeException, etc.)

Advertising is too "wild", Yoshino "surrenders"

Learn to go concurrent programming in 7 days go language sync Application and implementation of cond

Mysql database experiment report (I)
随机推荐
Design of STM32 and rc522 simple bus card system
MapReduce初级编程实践
Advertising is too "wild", Yoshino "surrenders"
Go语言fsnotify接口实现监测文件修改
PE buys a underwear company
跟着存档教程动手学RNAseq分析(一)
MySQL数据库 实验报告(一)
Structured machine learning project (II) - machine learning strategy (2)
About the SQL injection of davwa, errors are reported: analysis and verification of the causes of legal mix of settlements for operation 'Union'
How to prioritize the contents in the queue every second
PE买下一家内衣公司
Day 7 of "learning to go concurrent programming in 7 days" go language concurrent programming atomic atomic actual operation includes ABA problem
Crawler notes (1) - urllib
STM32与RC522简单公交卡系统的设计
99 multiplication table - C language
mongodb基础操作之聚合操作、索引优化
[electron] 基础学习
Follow the archiving tutorial to learn rnaseq analysis (IV): QC method for de analysis using deseq2
Fsnotify interface of go language to monitor file modification
使用同花顺手机炒股安全吗?