当前位置:网站首页>Deep learning, thinking from one dimensional input to multi-dimensional feature input
Deep learning, thinking from one dimensional input to multi-dimensional feature input
2022-07-03 05:48:00 【code bean】
From one dimensional input to multidimensional features
When looking at one dimension alone , I haven't felt anything yet .
But when I see this picture , My first reaction was , The original meaning of activation function is !
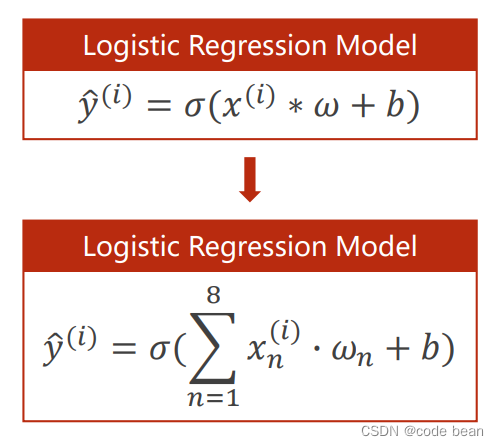

( But here is another point to note : Here is only the input dimension increased , Output or 0 and 1, So this is still a problem of two categories , Only the input characteristics become multidimensional , When it comes to multi classification, we should introduce softmax 了 )
At first I was thinking , Why should we add the eight characteristics of a piece of data into a linear equation Give again “ Sigma ” function ?
Then think of , Because each feature contributes differently to the whole , So there are different wb, Yes wb Blessing , So adding eigenvalues is not incomprehensible . then Linear systems The result value of “ Sigma ” function , In this way, the system has nonlinearity , This is also the purpose of the activation function —— It can fit more complex decision boundaries .
Then look at this picture :

Two implications of this picture
1 All forms of multiplication and accumulation , In fact, it can be converted into Multiplication of vectors , In turn to , Why should vector multiplication be designed like this , It may be to simplify the writing of accumulation .
2 After being written as a vector, you can use many vector properties . such as , It should have been x*w, Now I want to become w*x, But matrices have no commutative law , But according to the characteristics of transpose , We can xw All transposed , So they can change positions .
But there are still problems , there b How did you get it ? From the formula, it seems to appear out of thin air !
So I feel that there is a little problem with this way of writing , The more common way to write it should be , Add a dimension :

That is, first in X Add a... In front of the 1, As the base of the offset term ,( here X From n The dimensional vector becomes n+1 Dimension vector , Turn into [1, x1,x2…] ), then , Let each classifier train its own bias term weight , So the weight of each classifier becomes n+1 dimension , namely [w0,w1,…], among ,w0 Is the weight of the offset term , therefore 1*w0 Is the bias of this classifier / Intercept . such , Just let the intercept b This seems to be related to the slope W Different parameters , It's all unified to the next framework , Make the model constantly adjust parameters in the process of training w0, So as to achieve adjustment b Purpose .
————————————————
Copyright notice : This paper is about CSDN Blogger 「 Almost Human V」 The original article of , follow CC 4.0 BY-SA Copyright agreement , For reprint, please attach the original source link and this statement .
Link to the original text :https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/81074408
But I still have a problem , If in ,X Add a... In front of the 1 For the base , But adjust w0 When , The base is 1, That's equivalent to every linear function b It's still the same ? Then if it is here 1 Change to the previous linear function b Is it more reasonable ?
I'm not sure here ( Follow up in understanding .)
In a word, this offset term b The role of is Build in space No Across the origin A straight line / Plane / hyperplane . In this way, we can better classify ( Better build decision boundaries )( Digression : But in Euclidean space vectors, the vectors we discuss all cross the origin )


Solved the case
The lines here are not the origin , But vectors in Euclidean space all cross the origin , How do these vectors come from , I don't know if you have the same question as me .
This is before me , A question raised :

After communicating with the teacher , My conclusion is that :
That can be understood from two aspects :
The first one is :
A one-dimensional Euclidean space X Store all x The possibility of , A one-dimensional Euclidean space Y Store all y The possibility of .
And in two Euclidean spaces xy There is a one-to-one correspondence , With this relationship ,
Each pair xy It can also form a new two-dimensional Euclidean space XY. If there is another one-dimensional Euclidean space B,
Store all intercept b, And this B and XY There is also a one-to-one correspondence , According to these relationships , We can describe the straight line of intercept .
such as XY There's an element in (x1, y1) B There's an element in b1, Through these three pieces of information, we can describe a line segment with intercept .
And this B It can also be used as a feature item , Put in X Matrix , A new column .The second kind :
Regard Euclidean space as a set of points , stay X and W Before expansion ,XY The space formed by all the points in is actually a straight line passing through the origin .
stay X and W After expanding one dimension ,XY The space formed by all points in is an intercept ( But the origin ) The straight line of .
( you 're right , I was really going to X Y W These spaces are confused , The teacher woke me up here !!!)summary :
Although the vectors in Euclidean space are all vectors passing through the origin , But if you take these vectors as a point ( Ignore origin ), These points constitute
A space . This space might be N A line in dimensional space , One face , Or a person This is the concept of subspace .
That's it , I hope I can help people who are as confused as me .
Reference material :
《PyTorch Deep learning practice 》 Complete the collection _ Bili, Bili _bilibili
Bias term in neural network b What is it ?_ Almost Human V The blog of -CSDN Blog
边栏推荐
- Personal outlook | looking forward to the future from Xiaobai's self analysis and future planning
- redis 无法远程连接问题。
- 期末复习DAY8
- Notepad++ wrap by specified character
- Solve the 1251 client does not support authentication protocol error of Navicat for MySQL connection MySQL 8.0.11
- "C and pointer" - Chapter 13 advanced pointer int * (* (* (*f) () [6]) ()
- mapbox尝鲜值之云图动画
- PHP notes are super detailed!!!
- Apt update and apt upgrade commands - what is the difference?
- [Shangshui Shuo series together] day 10
猜你喜欢

Sophomore dilemma (resumption)

Today, many CTOs were killed because they didn't achieve business

Redis使用Lua脚本简介
![[teacher Zhao Yuqiang] Cassandra foundation of NoSQL database](/img/cc/5509b62756dddc6e5d4facbc6a7c5f.jpg)
[teacher Zhao Yuqiang] Cassandra foundation of NoSQL database
Apache+php+mysql environment construction is super detailed!!!
Beaucoup de CTO ont été tués aujourd'hui parce qu'il n'a pas fait d'affaires

How to install and configure altaro VM backup for VMware vSphere
Notepad++ wrap by specified character

【一起上水硕系列】Day 10
![[escape character] [full of dry goods] super detailed explanation + code illustration!](/img/33/ec5a5e11bfd43f53f2767a9a0f0cc9.jpg)
[escape character] [full of dry goods] super detailed explanation + code illustration!
随机推荐
[untitled]
Redis encountered noauth authentication required
Installation of CAD plug-ins and automatic loading of DLL and ARX
Get and monitor remote server logs
Altaro requirements for starting from backup on Hyper-V
Analysis of the example of network subnet division in secondary vocational school
NG Textarea-auto-resize
Shanghai daoning, together with American /n software, will provide you with more powerful Internet enterprise communication and security component services
"C and pointer" - Chapter 13 function pointer 1: callback function 2 (combined with template to simplify code)
"C and pointer" - Chapter 13 function of function pointer 1 - callback function 1
为什么网站打开速度慢?
How to create your own repository for software packages on Debian
牛客网 JS 分隔符
Source insight License Activation
[teacher Zhao Yuqiang] Cassandra foundation of NoSQL database
[video of Teacher Zhao Yuqiang's speech on wot] redis high performance cache and persistence
Ext4 vs XFS -- which file system should you use
Personal outlook | looking forward to the future from Xiaobai's self analysis and future planning
Redhat7系统root用户密码破解
Method of finding prime number