当前位置:网站首页>硬件设备计算存储及数据交互杂谈
硬件设备计算存储及数据交互杂谈
2022-07-31 22:50:00 【wujianming_110117】
硬件设备计算存储及数据交互杂谈
参考文献链接
https://mp.weixin.qq.com/s/OHEIwhZj5l8bKmk_-ZZg4Q
https://mp.weixin.qq.com/s/n-TT-sJ7O2fe83sdnPApqA
https://mp.weixin.qq.com/s/O5ariNSDdsLALs_UTsqdVw
https://mp.weixin.qq.com/s/gOip1AmkDw51qKDDfWem7Q
FPGA知识及芯片技术
FPGA可用于处理多元计算密集型任务,依托流水线并行结构体系,FPGA相对GPU、CPU在计算结果返回时延方面具备技术优势。
计算密集型任务:矩阵运算、机器视觉、图像处理、搜索引擎排序、非对称加密等类型的运算属于计算密集型任务。该类运算任务可由CPU卸载至FPGA执行。
FPGA执行计算密集型任务性能表现:
• 计算性能相对CPU:如Stratix系列FPGA进行整数乘法运算,其性能与20核CPU相当,进行浮点乘法运算,其性能与8核CPU相当。
• 计算性能相对GPU:FPGA进行整数乘法、浮点乘法运算,性能相对GPU存在数量级差距,可通过配置乘法器、浮点运算部件接近GPU计算性能。
FPGA执行计算密集型任务核心优势:搜索引擎排序、图像处理等任务对结果返回时限要求较为严格,需降低计算步骤时延。传统GPU加速方案下数据包规模较大,时延可达毫秒级别。FPGA加速方案下,PCIe时延可降至微秒级别。远期技术推动下,CPU与FPGA数据传输时延可降至100纳秒以下。
FPGA可针对数据包步骤数量搭建同等数量流水线(流水线并行结构),数据包经多个流水线处理后可即时输出。GPU数据并行模式依托不同数据单元处理不同数据包,数据单元需一致输入、输出。针对流式计算任务,FPGA流水线并行结构在延迟方面具备天然优势。
FPGA用于处理通信密集型任务不受网卡限制,在数据包吞吐量、时延方面表现优于CPU方案,时延稳定性较强。
通信密集型任务:对称加密、防火墙、网络虚拟化等运算属于通信密集型计算任务,通信密集数据处理相对计算密集数据处理复杂度较低,易受通信硬件设备限制。
FPGA执行通信密集型任务优势:
① 吞吐量优势:CPU方案处理通信密集任务需通过网卡接收数据,易受网卡性能限制(线速处理64字节数据包网卡有限,CPU及主板PCIe网卡插槽数量有限)。GPU方案(高计算性能)处理通信密集任务数据包缺乏网口,需依靠网卡收集数据包,数据吞吐量受CPU及网卡限制,时延较长。FPGA可接入40Gbps、100Gbps网线,并以线速处理各类数据包,可降低网卡、交换机配置成本。
② 时延优势:CPU方案通过网卡收集数据包,并将计算结果发送至网卡。受网卡性能限制,DPDK数据包处理框架下,CPU处理通信密集任务时延近5微秒,且CPU时延稳定性较弱,高负载情况下时延或超过几十微秒,造成任务调度不确定性。FPGA无需指令,可保证稳定、极低时延,FPGA协同CPU异构模式可拓展FPGA方案在复杂端设备的应用。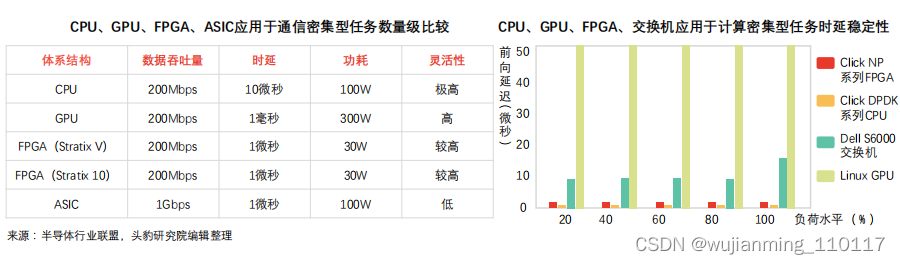
FPGA部署包括集群式、分布式等,逐渐从中心化过渡至分布式,不同部署方式下,服务器沟通效率、故障传导效应表现各异。
FPGA嵌入功耗负担:FPGA嵌入对服务器整体功耗影响较小,以Catapult联手微软开展的FPGA加速机器翻译项目为例,加速模块整体总计算能力达到103Tops/W,与10万块GPU计算能力相当。相对而言,嵌入单块FPGA导致服务器整体功耗增加约30W。
FPGA部署方式特点及限制:
① 集群部署特点及限制:FPGA芯片构成专用集群,形成FPGA加速卡构成的超级计算器(如Virtex系列早期实验板于同一硅片部署6块FPGA,单位服务器搭载4块实验板)。
• 专用集群模式无法在不同机器FPGA之间实现通信;
• 数据中心其他机器需集中发送任务至FPGA集群,易造成网络延迟;
• 单点故障导致数据中心整体加速能力受限
② 网线连接分布部署:为保证数据中心服务器同构性(ASIC解决方案亦无法满足),该部署方案于不同服务器嵌入FPGA,并通过专用网络连接,可解决单点故障传导、网络延迟等问题。
• 类同于集群部署模式,该模式不支持不同机器FPGA间通信;
• 搭载FPGA芯片的服务器具备高度定制化特点,运维成本较高
③ 共享服务器网络部署:该部署模式下,FPGA置于网卡、交换机间,可大幅提高加速网络功能并实现存储虚拟化。FPGA针对每台虚拟机设置虚拟网卡,虚拟交换机数据平面功能移动至FPGA内,无需CPU或物理网卡参与网络数据包收发过程。该方案显著提升虚拟机网络性能(25Gbps),同时可降低数据传输网络延迟(10倍)。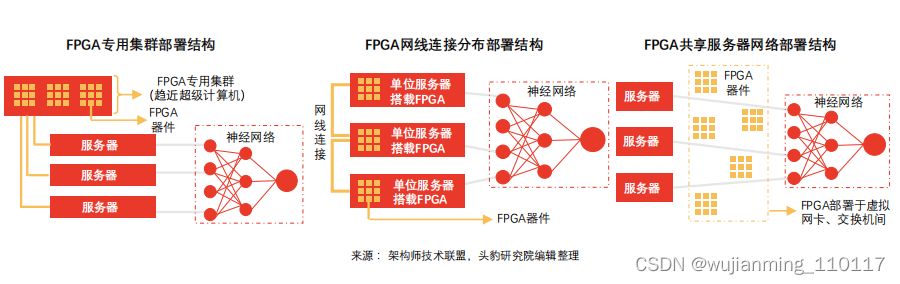
分享服务器网络部署模式下,FPGA加速器有助于降低数据传输时延,维护数据中心时延稳定,显著提升虚拟机网络性能。
分享服务器网络部署模式下FPGA加速Bing搜索排序:Bing搜索排序于该模式下采用10Gbps专用网线通信,每组网络由8个FPGA组成。其中,部分负责提取信号特征,部分负责计算特征表达式,部分负责计算文档得分,最终形成机器人即服务(RaaS)平台。FPGA加速方案下,Bing搜索时延大幅降低,延迟稳定性呈现正态分布。该部署模式下,远程FPGA通信延迟相对搜索延迟可忽略。
Azure服务器部署FPGA模式:Azure针对网络及存储虚拟化成本较高等问题采取FPGA分享服务器网络部署模式。随网络计算速度达到40Gbps,网络及存储虚拟化CPU成本激增(单位CPU核仅可处理100Mbps吞吐量)。通过在网卡及交换机间部署FPGA,网络连接扩展至整个数据中心。通过轻量级传输层,同一服务器机架时延可控制在3微秒内,触达同数据中心全部FPGA机架时延可控制在20微秒内。
依托高带宽、低时延优势,FPGA可组成网络交换层与服务器软件之间的数据中心加速层,并随分布式加速器规模扩大实现性能超线性提升。
数据中心加速层:FPGA嵌入数据中心加速平面,位于网络交换层(支架层、第一层、第二层)及传统服务器软件(CPU层面运行软件)之间。
加速层优势:
• FPGA加速层负责为每台服务器(提供云服务)提供网络加速、存储虚拟化加速支撑,加速层剩余资源可用于深度神经网络(DNN)等计算任务。
• 随分布式网络模式下FPGA加速器规模扩大,虚拟网络性能提升呈现超线性特征。
加速层性能提升原理:使用单块FPGA时,单片硅片内存不足以支撑全模型计算任务,需持续访问DRAM以获取权重,受制于DRAM性能。加速层通过数量众多的FPGA支撑虚拟网络模型单层或单层部分计算任务。该模式下,硅片内存完整加载模型权重,可突破DRAM性能瓶颈,FPGA计算性能得到充分发挥。加速层需避免计算任务过度拆分而导致计算、通信失衡。
嵌入式eFPGA技术在性能、成本、功耗、盈利能力等方面优于传统FPGA嵌入方案,可针对不同应用场景、不同细分市场需求提供灵活解决方案.
eFPGA技术驱动因素:设计复杂度提升伴随设备成本下降的经济趋势促发市场对eFPGA技术需求。
器件设计复杂度提升:SoC设计实现过程相关软件工具趋于复杂(如Imagination Technologies为满足客户完整开发解决方案需求而提供PowerVR图形界面、Eclipse整合开发环境),工程耗时增加(编译时间、综合时间、映射时间,FPGA规模越大,编译时间越长)、制模成本提高(FPGA芯片成本为同规格ASIC芯片成本100倍)。
设备单位功能成本持续下降:20世纪末期,FPGA平均售价较高(超1,000元),传统模式下,FPGA与ASIC集成设计导致ASIC芯片管芯面积、尺寸增大,复杂度提升,早期混合设备成本较高。21世纪,相对批量生产的混合设备,FPGA更多应用于原型设计、预生产设计,成本相对传统集成持续下降(最低约100元),应用灵活。eFPGA技术优势:
更优质:eFPGA IP核及其他功能模块的SoC设计相对传统FPGA嵌入ASIC解决方案,在功耗、性能、体积、成本等方面表现更优。
更方便:下游应用市场需求更迭速度快,eFPGA可重新编程特性有助于设计工程师更新SoC,产品可更长久占有市场,利润、收入、盈利能力同时大幅提升。eFPGA方案下SoC可实现高效运行,一方面迅速更新升级以支持新接口标准,另一方面可快速接入新功能以应对细分化市场需求。
更节能:SoC设计嵌入eFPGA技术可在提高总性能的同时降低总功耗。利用eFPGA技术可重新编程特性,工程师可基于硬件,针对特定问题对解决方案进行重新配置,进而提高设计性能、降低功耗。
FPGA技术无需依靠指令、无需共享内存,在云计算网络互连系统中提供低延迟流式通信功能,可广泛满足虚拟机之间、进程之间加速需求.
FPGA云计算任务执行流程:主流数据中心以FPGA为计算密集型任务加速卡,赛灵思及阿尔特拉推出基于OpenCL的高层次编程模型,模型依托CPU触达DRAM,向FPGA传输任务,通知执行,FPGA完成计算并将执行结果传输至DRAM,最终传输至CPU。
FPGA云计算性能升级空间:受限于工程实现能力,当前数据中心FPGA与CPU之间通信多以DRAM为中介,通过烧写DRAM、启动kernel、读取DRAM的流程完成通信(FPGADRAM相对CPU DRAM数据传输速度较慢),时延近2毫秒(OpenCL、多个kernel间共享内存)。CPU与FPGA间通信时延存在升级空间,可借助PCIe DMA实现高效直接通信,时延最低可降至1微秒。
FPGA云计算通信调度新型模式:新通信模式下,FPGA与CPU无需依托共享内存结构,可通过管道实现智行单元、主机软件之间的高速通信。云计算数据中心任务较为单一,重复性强,主要包括虚拟平台网络构建和存储(通信任务)以及机器学习、对称及非对称加密解密(计算任务),算法较为复杂。新型调度模式下,CPU计算任务趋于碎片化,远期云平台计算中心或以FPGA为主,并通过FPGA将复杂计算任务卸载至CPU(区别于传统模式下CPU卸载任务至FPGA的模式)。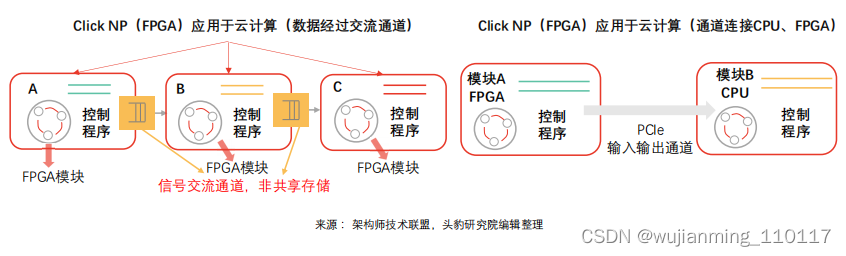
FPGA芯片行业形成以来,全球范围约有超70家企业参与竞争,新创企业层出不穷(如Achronix Semiconductor、MathStar等)。产品创新为行业发展提供动能,除传统可编程逻辑装置(纯数字逻辑性质),新型可编程逻辑装置(混讯性质、模拟性质)创新速度加快,具体如Cypress Semiconductor 研 发 具 有 可 组 态 性 混 讯 电 路 PSoC(Programmable System on Chip),再如Actel推出Fusion(可程序化混讯芯片)。此外,部分新创企业推出现场可编程模拟数组FPAA(Field Programmable Analog Array)等。
随智能化市场需求变化演进,高度定制化芯片(SoC ASIC)因非重复投资规模大、研发周期长等特点导致市场风险剧增。相对而言,FPGA在并行计算任务领域具备优势,在高性能、多通道领域可以代替部分ASIC。人工智能领域多通道计算任务需求推动FPGA技术向主流演进。
基于FPGA芯片在批量较小(流片5万片为界限)、多通道计算专用设备(雷达、航天设备)领域的优势,下游部分应用市场以FPGA取代ASIC应用方案。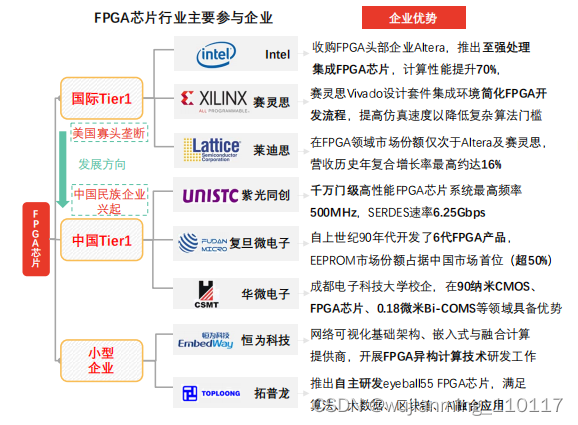
从产品角度分析,中国FPGA硬件性能指标相较赛灵思、Intel等差距较大。紫光同创是当前中国市场唯一具备自主产权千万门级高性能FPGA研发制造能力的企业。上海复旦微电子于2018年5月推出自主知识产权亿门级FPGA产品。中国FPGA企业紧跟大厂步伐,布局人工智能、自动驾驶等市场,打造高、中、低端完整产品线。
中国FPGA企业竞争突破口现阶段中国FPGA厂商芯片设计软件、应用软件不统一,易在客户端造成资源浪费,头部厂商可带头集中产业链资源,提高行业整体竞争力。
内存市场格局优化
市场:利基 DRAM主要产品,全球市场超 70 亿美金。存储是半导体第二大细分市场,2021/2020 年全球市场规模为 1534/1175 亿美金,占半导体整体规模的比例为28%/27%。DRAM 是存储器第一大市场,2021/2020 年全球市场规模为 930/643 亿美金,占存储整体规模的比例为 61%/55%。下载链接:DDR3存储器行业深度报告:全球市场超 70 亿美金,大厂退出格局优化。
DDR3 是 DDR SDRAM 第三代产品,从 2007年推出至今已发展十五年,2014 年占存储市场的比例达 84%,后随着更高端产品 DDR4推出,逐渐被替代为利基产品,目前是利基 DRAM 的主要品类。2022/2021 年,DDR3占存储整体规模的比例为 8%/8%,达 75/74 亿美金。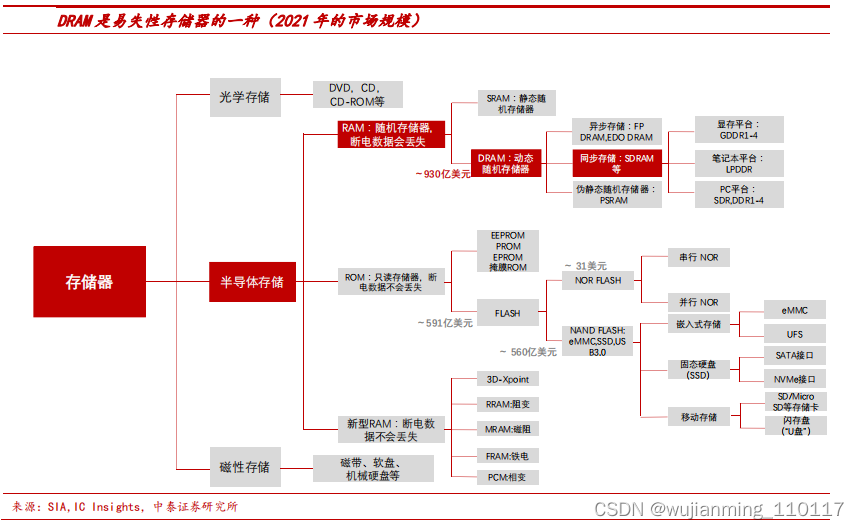
格局:主流以韩美为主力,利基大厂退出格局持续优化。
1)主流 DRAM 市场,2021年三星、海力士、美光占有率依次为 43%、28%、23%,合计达 94%,行业呈现“三足鼎立”之势。从 2013 年至今,三大原厂合计市占率持续超过 90%,在 2019 年达到顶峰 99%,2020 年和 2021 年随着大陆厂商扩产,市占率略微下滑到 94%。
2)利基DDR3 市场,根据测算,2021 年存储大厂三星、美光、海力士分别占据 40%、23%、4%份额,台系南亚、华邦的市占率分别为 22%、5%,三星和海力士今明两年陆续退出,台系厂商扩产有限,行业格局优化。
也从制程演进、料号数量角度对比海内外发展进度:从制程看,三大原厂 DDR3 制程为 20nm,南亚为 20nm,华邦为 25nm,兆易 DDR3 采用长鑫 17nm 制程,北京君正(ISSI)和东芯股份采用力晶 25nm 制程,由此可见在 DDR3 领域,兆易 DDR3 产品制程最为先进;从料号布局看,三大原厂 DDR4料号数量遥遥领先,中国台湾厂商利基产品料号数量瞩目,大陆兆易、君正、东芯主要发力 DDR3 和小容量 DDR4,其中东芯布局较为完善,兆易料号增加速度明显。
应用:主流以手机+PC+服务器三大市场为主,利基偏重长尾市场。主流 DRAM 市场,2021 年手机、服务器、PC 依次占比 39%、34%、13%,合计占比 86%,三大市场推动发展。利基 DDR3 市场,消费电子占比 79%,是第一大应用,工业占比 12%,汽车占比 9%,整体看主要应用于对容量、速率要求低的领域。从应用形式看,DDR3 主要是与主控芯片(如 MCU、MPU、Soc)配套使用,满足主控芯片的存储需求。
在 TI、高通、瑞萨、Mobileye、安霸、NXP 的主控芯片中都有配臵 DDR3,NXP 在 MCU 等主控芯片领域是领先者,详细梳理了 NXP 官网列示的 8175 款配有 DDR3 的主控芯片的下游应用情况(截至 2022/4),DDR3 广泛应用于消费电子、通讯基础设施、工业和汽车中,其中配臵 DDR3 的应用于消费电子及通讯基础设施的主控芯片达 4702 款,占比 58%,工业控制主控芯片 1869 款,占比 23%,汽车电子主控芯片 1586 款,占比19%,一般在 1 款主控芯片中根据存储需求配臵 1-2 颗 DDR3。结构优化叠加长尾市场,DDR3 价格表现优于其他 DRAM 产品,且与同容量的 DDR4 产品价格出现倒挂。
长鑫引领大陆 DRAM 产业发展,大陆积极布局 DDR3 市场。大陆厂商聚焦利基产品,在利基 DRAM、SLC NAND、Nor Flash、EEPROM 等利基产品全面布局,多为 fabless模式,长鑫定位 IDM、发力主流 DRAM,另外北京君正、兆易创新、东芯股份等均在DDR3 领域有所布局。
兆易创新早于 2016 年开始布局 DRAM 领域,2021 年 6 月量产首款自研 19nm 4G DDR4 产品,2022 年拟推出 17nm DDR3 产品,从 2022 年产品手册可见,2Gb DDR3 料号数量 12 种,4Gb 料号数量 12 种,聚焦商规和工规。北京君正通过收购 ISSI 迅速切入存储芯片领域,目前在大陆 DRAM 领域布局最为全面,通过官网统计可见,DDR1、DDR2、DDR3、DDR4 均有布局,其中料号分布依次为 26%、21%、44%、9%,公司也是全球车规 DRAM 领先企业,市占率 15%,为第二大厂商。
东芯股份为大陆 SLC NAND 龙头,收购韩国 Fidelix,加速 DRAM 研发过程。2021 年东芯 DRAM 营收 0.79 亿元,占公司总营收比例为 7%,yoy+67%,是增速最快的产品线。2020 年,DDR3 占营收的比例为 2%,1Gb、2Gb、4Gb 料号数量分别为 3、3、4,消费电子是主要下游应用。
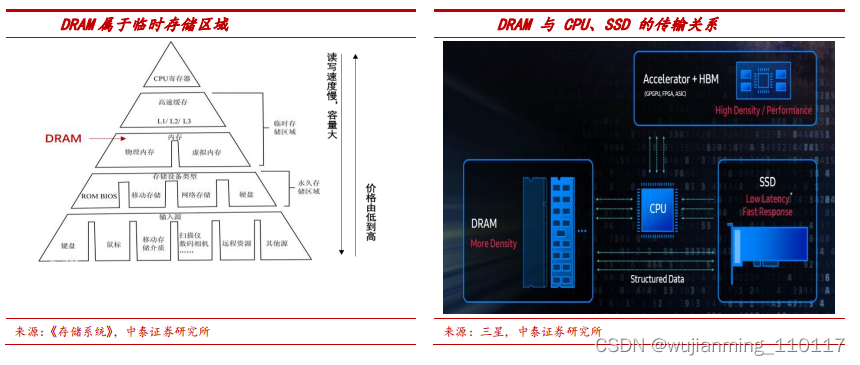
同步 DRAM 速度更快,替代异步 DRAM。按照 RAM 和 CPU 是否同频,DRAM可分为同步DRAM(Synchronous DRAM,简称 SDRAM)和异步 DRAM(Asynchronous DRAM)。在异步 DRAM 中,CPU 与 RAM 之间没有公共的时钟信号,当 RAM 不能及时提供数据时,CPU 需等待内存数据,这严重影响性能。为解决该问题,同步 DRAM 应运而生,在 RAM 中加入时钟输入引脚,使得 CPU 与 RAM 之间有公共的时钟信号、实现同步,此时 CPU 无需等待数据,读写速度加快、数据的传输效率大幅提升。异步 DRAM 通常适用于低速存储系统,但不适用于现代高速存储系统,在 1996-2002 年期间,同步 DRAM 逐步取代了异步 DRAM,逐步占领了内存市场。
同步 DRAM 不断迭代,新 DDR 逐步替换老 DDR 是行业规律。根据时钟边沿读取数据,同步 DRAM 分为 SDR(Single Data Rate)和 DDR(Double DataRate)技术,在 2003 年之后,SDR SDRAM(有时也简称为 SDRAM)逐渐被存取速度更快的 DDR SDRAM 取代。DDR SDRAM 已经发展至第五代,分别是:第一代 DDR SDRAM,第二代 DDR2 SDRAM,第三代 DDR3 SDRAM,第四代 DDR4 SDRAM,第五代 DDR5 SDRAM。每一次迭代,基本都能实现芯片性能翻倍,当新一代性能更好的 DDR 出现时,老一代 DDR 会逐渐被替代。

技术实现路径:内部时钟频率提升不大,每一代主要通过翻倍预取来实现数据的传输速度的提升。DDR 中有两个时钟频率,一个是内部时钟频率(也称为核心频率),是内存收到指令到将数据的传输到 I/O 接口上所需要的反应速度,这主要由存储单元内部的电容、晶体管、放大器等微观结构决定,提升难度大,所以从 SDR 到 DDR5,内部时钟频率虽有提升但提升幅度不大;另一个是外部时钟频率(也称为 I/O 时钟频率),外部时钟频率在核心时钟频率的基础上,通过翻倍预取提高速度。
• 1)SDR SDRAM:在一个时钟周期里只在上升沿传输数据,所以 SDR 也叫Single Data Rate SDRAM,此时数据的传输速率的提升主要是靠提升内部时钟频率。
• 2)DDR1 SDRAM:内部时钟频率提升难度大,因此通过在时钟周期的上升沿和下降沿各输出一次数据,相当于在一个时钟周期需要预取 2 倍数据,即每当读取一笔数据的时候,都会一共读取 2 笔的数据。因此在内部时钟频率不变的情况下,DDR1 的数据的传输速率实现翻倍。
• 3)DDR2 SDRAM:预取 4 倍数据,数据的传输速率达到内部时钟频率的 4倍,较 DDR1 提升 2 倍。
• 4)DDR3 SDRAM:预取 8 倍数据,此时数据的传输速率达到内部时钟频率的 8 倍,较 DDR2 提升 2 倍。
• 5)DDR4 SDRAM:标准型 DDR 的总线位宽是 64bit,若进行 16 倍预取,总共有 128Byte 的数据,超过了目前主流处理器的 Cacheline size(用于处理器缓存的基本数据单元)64Byte 的数据通道,由于 Cacheline 的限制,DDR4 没有将预取加倍,而是使用 Bank Group 技术,通过两个不同 Bank Group 的 8 倍预取来拼凑出一个 16 倍的预取,当 DRAM 获得了两笔数据的读命令,并且这两笔数据的内容分布在不同的Bank Group中时,由于每个 Bank Group 可以独立完成读取操作,两个 Bank Group 几乎可以同时准备好这两笔 8 倍数据。然后这两笔 8 倍数据被拼接成 16 倍的数据,数据的传输速度达到内部时钟频率的 16 倍,较 DDR3 提升 2 倍。
• 6)DDR5 SDRAM:在 Bank Group 技术的基础上,使用通道拆分技术增加预取倍数,将 64 位的总线分成 2 个独立的 32 位通道,此时每个通道都只提供 32bit 数据,将预取增加到 16 倍,仍然保证了 Cacheline 的大小还是 64Byte。通道拆分带来的 16 倍预取,叠加 Bank Group 增加的 2 倍,数据的传输速率达到内部时钟频率的 32 倍,较 DDR4 又提升 2 倍。
按照应用场景,DRAM 分成标准 DDR、LPDDR、GDDR 三类。JEDEC(固态技术协会,微电子产业的领导标准机构)定义并开发了以下三类 SDRAM 标准,以帮助设计人员满足其目标应用的功率、性能和尺寸要求。
• 1)标准型 DDR:Double Data Rate SDRAM,针对服务器、云计算、网络、笔记本电脑、台式机和消费类应用程序,允许更宽的通道宽度、更高的密度和不同的外形尺寸。
• 2)LPDDR:Low Power Double Data Rate SDRAM,针对尺寸和功率非常敏感的移动和汽车领域,有低功耗的特点,提供更窄的通道宽度。
• 3)GDDR:Graphics Double Data Rate SDRAM,适用于具有高带宽需求的计算领域,例如图形相关应用程序、数据中心和 AI 等,与 GPU 配套使用。另外,DRAM 按照市场流行程度可分为主流 DRAM 和利基型 DRAM。
DDR3 是利基产品,目前主流是 DDR4,DDR5 跑马进场。产品不断迭代,按照市场流行程度可分为主流产品和利基产品,利基产品一般是从主流规格中退役的产品。目前市场主流 DRAM 是容量 8GB+的 DDR4/DDR5,容量在 4GB 及以下的 DDR4、DDR3 等现阶段属于利基 DRAM。DDR3 主要应用于液晶电视、数字机顶盒、播放机等消费型电子与网络通讯等领域,需求较为稳定,很多都是客制化晶片,不属于大众规格产品,价格主要受供给影响。

DDR3 市场规模超 70 亿美金,市场逐渐萎缩,但生命力持久、中短期仍占据一定行业地位。
• 1)市场规模:自 2007 年 JEDEC 发布 DDR3 标准至今,DDR3(包括标准DDR3、LPDDR3)已发展 15 年,2020 年在 DRAM 市场占比 20%,预计 2021年占比 8%,2022 年有望维持 8%的占比。预计 2021 年、2022 年市场规模将分别达到 74 亿美金、75 亿美金。
• 2)市场逐渐萎缩:2020 年 DDR4/DDR4+占比超过 80%,目前处于 DDR4 替代 DDR3 的切换期。DDR3 市场在逐渐萎缩,其市场规模在 2014 年达到最大值 394 亿美金,到 2020 年缩小到 129 亿美金,市场规模年复合增长率为-20%。
• 3)被替代速度放缓,中短期仍占据一定行业地位。从 DDR3 标准的推出,到 2010 年 DDR3 市场规模超过 DDR2,历经三年时间;从 2012 年 JEDEC推出 DDR4 标准,到 2018 年 DDR4 市场规模超过 DDR3,耗时 6 年。DDR3被 DDR4 完全替代的速度相对放缓。认为原因有二:
①主流 DDR3 时代导入的产品量远大于主流 DDR2 时导入的产品量,仅从全球 PC 年出货量看,根据 IDC 的数据,2007 年(DDR3 新发布,DDR2 是主流)出货 2.7 亿台,2014 年(DDR4 发布,DD3 是主流)出货 3.5 亿台,增长近 30%,因为各代 DDR 之间不兼容,如果升级 DDR,需要将 CPU、主板等一并更换,替换成本高,替换成 DDR4 的动力减弱。
② DDR3 目前主要需求落在大量的低容量低端消费电子领域。该领域产品不追求高性能,短时间内无升级需求,如 WiFi 路由器、家电等消费性电子产品的首选仍是 DDR3,另外在汽车、工业领域,DDR3 也有其较为稳定的市场,同时从 DDR3 切换到 DDR4 仰赖主控芯片厂的芯片迭代、终端市场的共同推进。DDR3 的需求是来自于技术迭代过程中的滞后性,硬件迭代速度慢,预计这种滞后性在中短期内仍将存在。
PCIe 7.0发布,速度高达512 GB/s
2022 年 PCI-SIG 开发者大会正在如火如荼举行,而藏在无处不在的 PCIe 接口标准背后的标准委员会PCI-SIG 宣布,PCIe 7.0 规范的目标是在 2025 年向其成员发布,数据速率高达 128 GT/s。在编码开销之前,这相当于通过 16 通道 (x16) 连接实现 512 GB/s 的双向吞吐量。PCI-SIG 是 PCIe 接口背后的联盟,这是一个由 900 多家成员公司组成的开放行业标准。
PCI-SIG 指出,PCIe 7.0 接口将通过 x16 连接提供高达 512 GB/s 的双向吞吐量,但这是在编码开销(encoding overhead )和标头效率(header efficiency)的影响之前,这两者都会影响可用带宽。
PCIe 7.0 接口将继续使用 1b/1b flit 模式编码和随 PCIe 6.0 引入的 PAM4 信号技术,这与PCIe 3.0 到PCIe 5.0 规范中使用的 128b/130b 编码和 NRZ 信号相比有显著改进。因此,实际可用带宽将略低于 512 GB/s 的数字,但仍代表 PCIe 6.0 接口的两倍。
正如在跳转到 PCIe 4.0 和 5.0 时看到的那样,由于更快的信号传输速率,PCIe 走线的长度将再次缩短。这意味着在没有额外组件的情况下,PCIe 根设备(如 CPU)和终端设备(如 GPU)之间的最小允许距离将缩短。因此,与在前几代接口中看到的相比,主板将需要更多的重定时器(retimers )和由更高质量材料组成的更厚 PCB,而 PCIe 7.0 支持将导致主板价格再次上涨。
值得注意的是,每条通道的带宽将更高,现在对于 x1 连接的双向带宽为 32 GB/s,可以允许某些设备的“更细”连接(例如,使用 x4 而不是 x8 连接)。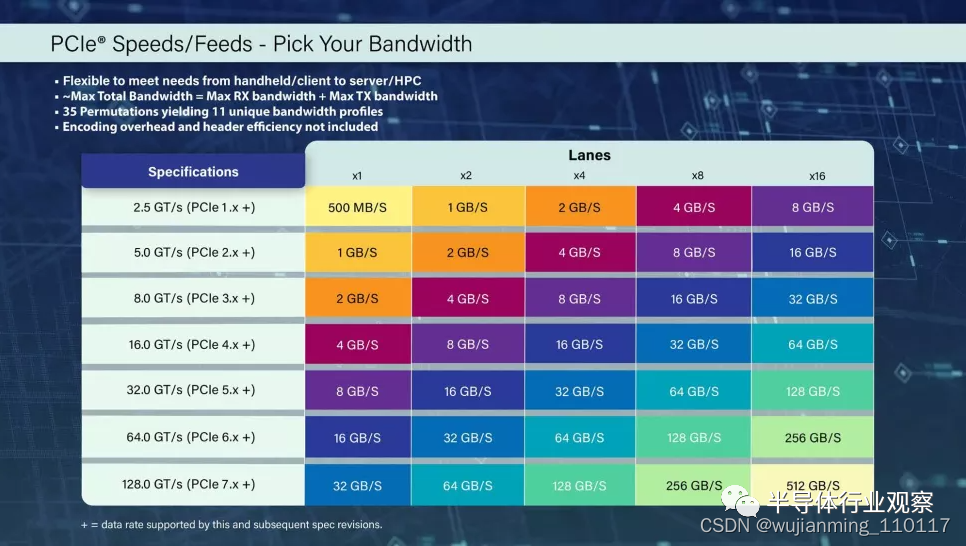
PCIe 7.0 规范的基础工作是在PCI-SIG 今年早些时候完成 PCIe 6.0 规范之后制定的,将提供比上一代 PCIe 6.0 接口增加一倍的带宽。然而,还需要一段时间才能看到支持这种快速接口的 SSD 和 GPU 等设备——这些规范通常在看到出货硅片之前很久就得到批准和最终确定。
注意到,市场上仍然没有多少PCIe 5.0设备,尽管该接口确实出现在英特尔Alder Lake的主流主板上,并且还将出现在 AMD 即将推出的 Zen 4 Ryzen 7000上今年晚些时候到货的平台。首批 PCIe 5.0 SSD 将与 Ryzen 7000 处理器同时上市,但已经看到了用于数据中心和 AI/ML 设备的 PCIe 5.0 设备的产品公告。
换句话说,在相当长的一段时间内都不会在市场上看到 PCIe 7.0 设备,尽管 PCI-SIG 现在开始定义规范并希望实现其每三年发布一个新规范的目标。PCIe 7.0 规范预计将在 2025 年落地,但要到 2028 年才能看到终端设备。
PCIe 7.0 规范目标:
通过 x16 配置提供 128 GT/s 的原始比特率和高达 512 GB/s 的双向传输速率
利用 PAM4(4 级脉冲幅度调制)信令
关注渠道参数和覆盖范围
继续提供低延迟和高可靠性的目标
提高电源效率
保持与所有前几代 PCIe 技术的向后兼容性
符号列表
“30 年来,PCI-SIG 的指导原则一直是,‘如果建造,就会来,’”Insight 64 研究员 Nathan Brookwood 说。“PCI 技术的早期并行版本可容纳数百兆字节/其次,与 1990 年代的图形、存储和网络需求相匹配。2003 年,PCI-SIG 演变为支持千兆字节/秒速度的串行设计,以适应更快的固态磁盘和 100MbE 以太网。几乎就像发条一样,PCI-SIG 每三年将 PCIe 规范带宽翻一番,以应对新兴应用和市场的挑战。今天宣布的 PCI-SIG 计划将通道速度翻倍至 512 GB/s(双向)使其有望在另一个 3 年周期内将 PCIe 规范性能翻一番。”进一步指出。
“随着即将推出的 PCIe 7.0 规范,PCI-SIG 继续 30 年来的承诺,即提供推动创新边界的行业领先规范,”PCI-SIG 总裁兼主席 Al Yanes 说。“随着 PCIe 技术不断发展以满足高带宽需求,工作组的重点将放在通道参数和覆盖范围以及提高功率效率上。”Al Yanes 接着说。
PCIe 7.0 规范旨在支持新兴应用,例如 800 G 以太网、AI/ML、云和量子计算;和数据密集型市场,如超大规模数据中心、高性能计算 (HPC) 和军事/航空航天。
数据中心“芯片”竞争格局
随着人工智能及大数据崛起,数据中心日益庞大,储存容量也因疫后数位转型加速而大幅成长。另一方面,智能型网路卡与资料处理器所代表的新兴加速运算装置预料也将带动伺服器硬体加速成长,掀起资料中心运算架构变革潮。CPU核心数增加以优化记忆体应用、提升高效运算能力成为重要课题。
CPU发展史堪称Intel和AMD「双雄争霸」的发展史,可分为4位微处理器、8位微处理器、16位微处理器、32位微处理器及六64位微处理器等。Intel于1971年推出世上第一款微处理器4004,是包含2300个晶体管的4位CPU。
17年前,第一颗双核心X86处理器问世,AMD推出首款Opteron双核处理器,Intel也推出双核处理器,开启CPU多核处理器(Multi-Core Processor)时代。在多核处理器的竞技上,Intel多半保持领先,但约6年前AMD重返伺服器市场,抢先对手推出32核心伺服器处理器EPYC,刷新Intel的24核心纪录。迄今,双雄争霸互有胜出。
过去,单颗CPU核心数不够多,处理能力相对较弱,只能以增加CPU颗数的方式搭配高效能应用伺服器,组成更多CPU核心的运算丛集以提高伺服器处理效能。当CPU核心数达64核心,代表一台64核单路伺服器就能协助企业执行各种复杂运算或高密集运算工作。
X86处理器在随后的发展中逐步推展大量平行运算或浮点运算可视化、AI、深度学习等应用,之后,图形处理器(GPU)出现,智能型网路卡(SmartNIC)与资料处理器(DPU)等新兴加速运算装置陆续分食X86处理器的运算工作,催化新一波伺服器硬体加速变革。
另一方面,为迎合DPU市场需求,业者必须快速提升伺服器的处理能力,增加伺服器CPU核心是最简单也最容易的方式。
此外,AI与特定运算的需求越来越大,加上物联网网路传输数据的安全性需求增高,处理器架构也必须全面翻新才能因应市场需求。市场上的CPU分为两大阵营,一是以Intel、AMD为首的复杂指令集CPU,二是以IBM、ARM为首的精简指令集CPU,除了品牌相异,产品架构也不尽相同,Intel、AMD CPU为X86架构,IBM CPU为PowerPC架构,ARM则是ARM架构。
新一代异质运算架构提升运算效能
由于AI加速芯片和资料处理芯片(DPU)加入运算阵容,新一代异质运算架构逐步成形。因应全数据料中心高效能运算、云端与AI运算需求,带动运算力更强大、更高效的伺服器需求。Intel称霸半导体界十余载,如今,X86中央处理器统治资料中心运算架构的局面已然松动。
图一: Arm推出新Armv9 架构CPU(source:Arm)
AI时代处理深度学习需要运用复杂运算,「效能」与「能耗」成为企业亟需解决的两大问题,因此衍生出GPU、FPGA及ASIC 等异质运算架构。异质运算是指系统使用不同的计算单元,如CPU、GPU、DPU、VPU、FPGA、ASIC等,不同运算工作需要交由符合需求的专用处理器执行才能大幅提升运算效能或改善能源使用效率。
近年来,异质运算的定义越来越多元,也包含使用不同架构的处理器及使用不同处理器架构的伺服器解决方案,主要目的是在最短时间内快速解决特殊工作负载,比方Arm架构处理器不只具有运算核心数量较多、功耗较低等优势,也更容易与Arm架构行动装置互通有无,顺畅沟通。
采用不同处理器架构相当于进阶版的异质运算,除了X86架构,还有Arm架构处理器等替代方案可以搭配各类新运算产品。随着晶圆代工商业模式成主流,AMD与苹果(Apple)似已威胁到Intel的霸主地位,过去2年,几大龙头业者也陆续推出新的CPU产品及异质运算架构解决方案。
商机可期龙头业者动作频频
从数据面观察,不难看出数据中心运算架构商机可期,几大龙头业者也为加速抢滩而动作频频。IDC《全球边缘运算支出报告》指出,2022年全球边缘运算支出预计达1760亿美元,较2021年成长14.8%,至于企业和服务供应商在边缘解决方案的软硬体及服务支出预计在2025年达到2740亿美元的水准。由于边缘部署具有多样化需求,为技术供应商创造极大商机,预料市场将出现更多新的解决方案。
以企业端来说,2022年边缘投资大宗包含制造营运、生产资产管理、智能电网、全通路营运、公共安全与紧急应变、货运监控和智能交通系统。预估2020-2025年,公共基础设施维护、网路维护、解剖诊断和AR 辅助手术等领域支出成长较快。IDC进一步指出,美国将成边缘解决方案的最大投资者,预计2022年支出达765亿美元,西欧和中国则是第二大地区,支出总额分别为306亿美元和208亿美元。
DIGITIMES Research则预期,2022年下半年IC短缺可望缓解,由于北美云端业者、大型资料中心(如字节跳动、BAT)对伺服器需求强劲,加上Intel、AMD新一代CPU 2021下半年起小量出货带动换机潮,全球伺服器出货量呈现强劲成长力道。
几大龙头厂近2-3年动作频频,较劲意味浓厚。Arm于2021年发表全新Armv9架构的全面运算解决方案,带来次世代沉浸式与互动式体验,提供更高的运算效能、安全性与扩充性。Arm推出Cortex-X2、Cortex-A710及Cortex-A510三款CPU产品,提升笔电效能及智能电视用户体验,也为手游提供高效率的电池续航力。
图二: 英特尔首度在PC X86架构处理器上推出具有大小核心的异质架构处理器(source:Intel)
Arm资深副总裁暨终端产品事业群总经理Paul Williamson 表示,Cortex-X2 是第一颗Armv9旗舰CPU,与Cortex-X1相较,效能提升16%,机器学习效能则提升二倍,预计带来逾30%的峰值效能,可以同步满足高阶智能手机、笔电需求;Cortex-A710则是第一颗基于Armv9 的大核CPU,与Cortex-A78相比,能源效率提升30%、效能提高10%;Cortex-A510是首次推出的高效率小核核心,效能增加35%,机器学习效能更提升逾三倍,适合运用于智能手机、家用及穿戴装置。
Arm也推出四款GPU新品:Mali-G710、Mali-G610、Mali-G510及Mali-G310。与Mali-G78相较,Mali-G710的效能提升20%、机器学习效能提高35%、能源效率提高20%,主攻高阶智能手机与Chromebook市场;Mali-G610承袭Mali-G710功能但价格更亲民;Mali-G510不仅效能提升,耗电量也节省22%,锁定中阶智能手机、高阶智能电视与机上盒市场;Mali-G310则是将Valhall架构与高品质绘图技术导入成本较低的入门智能手机、扩增实境装置与穿戴装置。
2021年底,Intel发表Alder Lake第12代Intel Core桌上型6款处理器,在伺服器虚拟化及软体定义化架构下陆续加入X86指令集,让X86处理器可以承担资料中心多数的运算负载。这款首度使用Intel 7纳米制程的混合架构CPU产品命名第12代Intel Core i9-12900K,堪称「地表最强游戏处理器」,16核心包含效能核心(P-core)及效率核心(E-core),也是X86架构个人电脑处理器首度使用大小核心设计。市场评估,Intel此举将掀起新一轮竞赛,尤其大小核心的混合架构设计,直接挑战2020年苹果发表的自研芯片M1,向其他龙头大厂示威的意图也很明显。
迎战双A(AMD与APPLE) Intel强势回归
在此不得不提CPU两大阵营外的第三方新势力:苹果(Apple),以及苹果掀起的异质核心(大小核心)概念。苹果于2020年发表采用Arm架构设计的自研芯片M1后,异质核心(大小核心)概念引起全球关注。M1系列处理器具有两大特点,一是异质核心概念让电脑可以视工作吃重度不同,将适合的工作内容分派给大核心或小核心处理,这般「适才适性」的处理方式大大降低机器耗能,提高运算最佳化效能;二是统一记忆体架构,透过M1 MAX,CPU跟GPU(显示芯片)可以同步共享64GB记忆体,达资料存取频宽最大化效能。
图三: 全系列新款AMD Ryzen 6000系列处理器(Source:AMD)
紧跟在Intel之后,AMD在2022年初发表全系列新款AMD Ryzen 6000系列处理器,全新Zen 3+核心架构内建全新AMD RDNA? 2架构的显示核心。AMD Ryzen 6000系列处理器采用台积电6纳米制程技术,带来1080p 3A级游戏体验以及超长的电池续航力。此外,AMD也发表新款Ryzen 7 5800X3D桌上型处理器,采用AMD 3D V-Cache技术,并率先采用Zen 4架构与全新AMD Socket AM5插槽的新款Ryzen 7000系列CPU。Ryzen 6000系列处理器的时脉速度高达5 GHz,堪称目前速度最快的AMD Ryzen处理器,与Ryzen 5000系列相比,处理速度提高1.3倍,显示效能提高2.1倍。
AMD在GPU和CPU运算核心部分都能提出效能更好的架构,如Zen和RDNA架构。绘图处理器GPU可以负责处理电脑显示绘图相关项目,Zen架构可协助电脑在执行网页浏览、多工作业及串流视讯应用时更快速处理显示速度,RDNA架构有助CPU更快速处理数据运算与执行指令。
英伟达(NVIDIA)则在2021年推出首款基于Arm架构打造的NVIDIA Grace CPU,针对AI及高效能运算工作负载所设计,也是目前唯一支援NVLlink传输介面的CPU,可以和GPU搭配运作。NVIDIA创办人暨执行长黄仁勋表示,要将Arm架构芯片拓展至云端运算、超级运算、个人电脑及自动化系统等领域,资料中心产品线将由CPU、GPU、DPU等三种芯片组成,NVIDIA架构平台将同时支援X86跟Arm。
预计2023年初上市的NVIDIA Grace CPU运算效能优于目前效能最快的超级伺服器约10倍的速度,可满足自然语言运算、推荐系统及AI超级运算等先进运算需求,同时可以整合Arm CPU 核心架构和低功率记忆体次系统,兼具高效与节能优势。
CPU双雄争霸2022年更精彩
虽然几大龙头业者竞争态势明显,但各自着眼的产品发展策略不同,比方AMD走小芯片(Chiplets)路线,苹果选择M1 Max单一芯片,前者走小众化路线,后者强调「数大便是美」,在432平方公厘面积的M1芯片内布建高达570亿电晶体,功耗仅约90W。
数据显示,M1 Max GPU足以匹媲美AMD与Nvidia的高阶GPU。在Intel发表异质核心X86处理器后,X86架构往前推进一大步,未来CPU效能还有拓展空间,至于AMD等强敌未来是否跟进异质架构,对于市场及相关技术发展带来何种变数,值得观察。
参考文献链接
https://mp.weixin.qq.com/s/OHEIwhZj5l8bKmk_-ZZg4Q
https://mp.weixin.qq.com/s/n-TT-sJ7O2fe83sdnPApqA
https://mp.weixin.qq.com/s/O5ariNSDdsLALs_UTsqdVw
https://mp.weixin.qq.com/s/gOip1AmkDw51qKDDfWem7Q
边栏推荐
- Collation of knowledge points in Ningbo University NBU IT project management final exam
- Drawing process of hand-drawn map of scenic spots
- 【ACM】2022.7.31训练赛
- 一文带你了解 Grafana 最新开源项目 Mimir 的前世今生
- UOS - WindTerm use
- @JsonFormat(pattern=“yyyy-MM-dd“)时间差问题
- Dry goods | 10 tips for MySQL add, delete, change query performance optimization
- 【FPGA教程案例43】图像案例3——通过verilog实现图像sobel边缘提取,通过MATLAB进行辅助验证
- TestCafeSummary
- @JsonFormat(pattern="yyyy-MM-dd") time difference problem
猜你喜欢
Dry goods | 10 tips for MySQL add, delete, change query performance optimization

Payment module implementation

嵌入式开发没有激情了,正常吗?
支付模块实现

Federated Learning: Multi-source Knowledge Graph Embedding in Federated Scenarios
VOT2021比赛简介
景区手绘地图的绘制流程
面试突击69:TCP 可靠吗?为什么?
UOS - WindTerm use
I don't know what to do with sync issues


随机推荐
Advanced Algebra _ Proof _ Any matrix is similar to an upper triangular matrix
输入输出优化
Unity - by casting and cloning method dynamic control under various UGUI create and display
flowable workflow all business concepts
消息队列消息存储设计(架构实战营 模块八作业)
10大主流3D建模技术
程序进程和线程(线程的并发与并行)以及线程的基本创建和使用
周总结
Go1.18 upgrade function - Fuzz test from scratch in Go language
逐步手撕轮播图3(保姆级教程)
什么是动态规划,什么是背包问题
The latest masterpiece!Alibaba just released the interview reference guide (Taishan version), I just brushed it for 29 days
[QNX Hypervisor 2.2用户手册]9.14 set
Chapter Six
A high-quality WordPress download site template theme developed abroad
Program processes and threads (concurrency and parallelism of threads) and basic creation and use of threads
TestCafeSummary
[Code Hoof Set Novice Village 600 Questions] Merge two numbers without passing a character array
IDA PRO中汇编结构体识别
hboot and recovery, boot.img, system.img