当前位置:网站首页>[translation] reduced precision in tensorrt
[translation] reduced precision in tensorrt
2022-07-27 02:03:00 【Master Fuwen】
Original address :
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#reduced-precision
6.5. Reduced Precision
6.5.1. Network-Level Control of Precision
By default ,TensorRT With 32 position Precision work , But you can also use 16 Bit floating point and 8 Bit quantized floating point Perform the operation . Using lower accuracy requires less memory and can perform faster calculations .
Reducing accuracy support depends on your hardware ( see also NVIDIA TensorRT Support the hardware and precision parts of the matrix ). You can query the builder Builder To check the accuracy support supported on the platform :
C++
if (builder->platformHasFastFp16()) {
… };
Python
if builder.platform_has_fp16:
Setting the corresponding flag in the builder configuration will notify TensorRT It may choose a low precision implementation :
C++
config->setFlag(BuilderFlag::kFP16);
Python
config.set_flag(trt.BuilderFlag.FP16)
There are three precision marks :FP16、INT8 and TF32, They can be enabled independently .
Be careful , If TensorRT The overall running time of the program is short , Or there is no low precision implementation ,TensorRT We will still choose a more accurate way .
When TensorRT When selecting precision for a layer , It will automatically convert weights as needed to run .
sampleGoogleNet and sampleMNIST Examples of using these flags are provided .
Although the use of FP16 and TF32 The accuracy is relatively simple , But use INT8 There will be additional complexity . For more information , Please see use INT8 chapter .
6.5.2. Layer-Level Control of Precision
Builder flags Allow coarse-grained precision control . However , Sometimes a part of the network needs a higher dynamic range or is sensitive to numerical accuracy . You can limit the input and output types of each layer :
C++
layer->setPrecision(DataType::kFP16)
Python
layer.precision = trt.fp16
This provides the preferred type of input and output ( Here is DataType::kFP16 ).
You can further set the layer Output The preferred type of precision :
C++
layer->setOutputType(out_tensor_index, DataType::kFLOAT)
Python
layer.set_output_type(out_tensor_index, trt.fp16)
The calculation will use the same floating-point type as the input . majority TensorRT The implementation has the same input and output floating-point types ; however ,Convolution、Deconvolution and FullyConnected Can support quantitative Of INT8 Input and Unquantified Of FP16 or FP32 Output , Because sometimes in order to maintain accuracy , Quantitative input is required , But output high-precision tensor .
Set precision constraint prompt TensorRT You should choose a layer implementation that matches the input and output precision types , If the accuracy type of the output of the previous layer does not match that of the input data of the next layer , The insert Data format conversion (reformat) operation .
Please note that , These types are enabled only by flags in the builder configuration ,TensorRT To choose an implementation with these types .
By default ,TensorRT Only when high-performance network is required, such an implementation will be selected . If the other implementation is faster ,TensorRT Will use it and issue a warning . You can override this behavior by modifying the type constraint in the builder configuration .
C++
config->setFlag(BuilderFlag::kPREFER_PRECISION_CONSTRAINTS)
Python
config.set_flag(trt.BuilderFlag.PREFER_PRECISION_CONSTRAINTS)
If constraints are preferred ,TensorRT Will obey them , Unless there is no corresponding precision realization , under these circumstances , It warns and uses the fastest available implementation .
To change a warning to an error , Please use OBEY instead of PREFER :
C++
config->setFlag(BuilderFlag::kOBEY_PRECISION_CONSTRAINTS);
Python
config.set_flag(trt.BuilderFlag.OBEY_PRECISION_CONSTRAINTS);
sampleINT8API Explains the use of these API Reduce precision .
Precision constraints are optional —— You can use C++ Medium layer->precisionIsSet() or Python Medium layer.precision_is_set Query whether constraints are set . If no precision constraint is set , So from C++ Medium layer->getPrecision() The result returned , Or in Python Read from precision attribute , It doesn't make sense . Output type constraints are also optional .
If ILayer::setPrecision perhaps ILayer::setOutputType API There is no use to set precision constraints , that BuilderFlag::kPREFER_PRECISION_CONSTRAINTS or BuilderFlag::kOBEY_PRECISION_CONSTRAINTS Will be ignored .
Then one floor Layer You can choose any precision or output type stay builder Allowed precision options .
Please note that ,layer->getOutput(i)->setType() and layer->setOutputType() There is a difference between —— The former is an optional type , It limits TensorRT The implementation that will be selected for the layer . The latter is mandatory ( The default is FP32) And specify the type of network output .
If they are different ,TensorRT A cast will be inserted to ensure that both specifications are met . therefore , If you call setOutputType() To specify the network output , Usually, the corresponding network output should also be configured to have the same type .
( This part is messy )
6.5.3. TF32
TensorRT By default, you are allowed to use TF32 Tensor Cores. When calculating the inner product , For example, in convolution or matrix multiplication ,TF32 Do the following :
- take FP32 The multiplicand is rounded to FP16 precision , But keep FP32 Dynamic range .
- Calculate the exact product of the rounded multiplicand .
- Add the multiplication accumulation to FP32 In total .
TF32 Tensor Cores have access to FP32 Speed up the network , Accuracy is usually not lost . For models that require high dynamic range weights or activation , It is better than FP16 More powerful .
There is no guarantee TF32 Tensor Cores Will be actually used , There is no way to enforce their use ——TensorRT You can always go back to FP32, If the platform does not support TF32, Always fall back . however , You can clear TF32 builder Flag to disable them .
C++:
config->clearFlag(BuilderFlag::kTF32);
Python
config.clear_flag(trt.BuilderFlag.TF32)
Despite the settings BuilderFlag::kTF32, But set environment variables when building the engine NVIDIA_TF32_OVERRIDE=0 Will disable TF32 . This environment variable is set to 0 It will cover NVIDIA Any default value or programming configuration of the Library , So they will never be used TF32 Tensor Cores Speed up FP32 Calculation .
This is just a debugging tool ,NVIDIA No code outside the library should change the behavior based on this environment variable . except 0 Any other settings other than are reserved for future use .
Warning : When the engine is running, set the environment variable NVIDIA_TF32_OVERRIDE Setting to different values may lead to unpredictable accuracy / Performance impact . It is best not to set when the engine is running .
Be careful : Unless your application needs TF32 Provide a higher dynamic range , otherwise FP16 Will be a better solution , Because it almost always produces faster performance .
边栏推荐
- 解决方案:Win10如何使用bash批处理命令
- [cann training camp] enter media data processing (Part 2)
- Homework 1-4 learning notes
- Acwing 1057. stock trading IV
- Proxmox VE安装与初始化
- [polymorphism] the detailed introduction of polymorphism is simple and easy to understand
- 项目 | 实现一个高并发内存池
- Domain name analysis and DNS configuration installation
- Use of shell (11) brackets
- DHCP experiment ideas
猜你喜欢

MySQL中对于事务完整的超详细介绍

Regular expression gadget series

Removal and addition of reference types in template and generic programming

【无标题】
![[polymorphism] the detailed introduction of polymorphism is simple and easy to understand](/img/85/7d00a0d9bd35d50635a0e41f49c691.png)
[polymorphism] the detailed introduction of polymorphism is simple and easy to understand

Process and planned task management
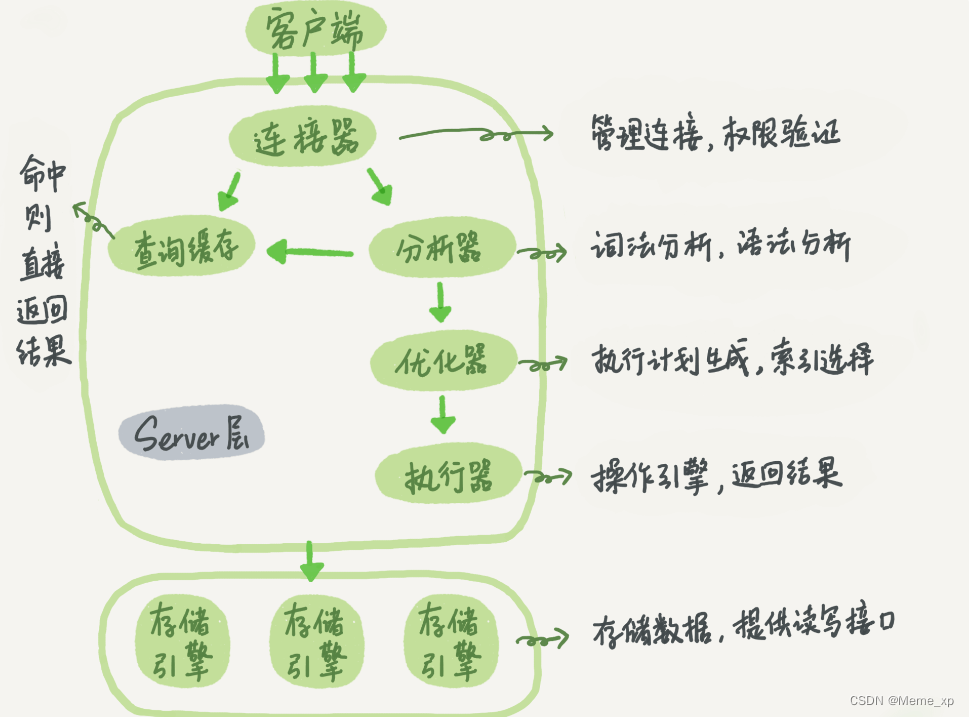
mysql一个select语句的执行过程
![[cann training camp] enter media data processing 1](/img/6c/76d3784203af18a7dee199c3a7fd24.png)
[cann training camp] enter media data processing 1

MySQL backup recovery
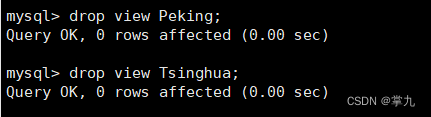
MySQL view
随机推荐
Initial experience of cloud database management
Removal and addition of reference types in template and generic programming
Ubuntu12.10 installing mysql5.5 (II)
iptables
It's the first time to write your own program in C language. If you have a boss, you can help a little
Shell (8) cycle
Talking about server virtualization & hyper convergence & Storage
Shell script - automatically deploy DNS services
System safety and Application
Project | implement a high concurrency memory pool
The bottom implementation of vector container
负载均衡的运用
left join 、inner join 、right join区别
CEPH (distributed storage)
网络与VPC之动手实验
作业1-4学习笔记
MySQL多表查询
(atcoder contest 144) f - fork in the road (probability DP)
Constructor, copy function and destructor
introduction