当前位置:网站首页>Implement custom spark optimization rules
Implement custom spark optimization rules
2022-07-27 15:37:00 【wankunde】
List of articles
Catalyst optimizer
Spark SQL Use a call catalyst The optimizer for all uses spark sql and dataframe dsl Query optimization . Optimized queries are better than using RDD Programs written directly run faster .catalyst yes rule based Optimizer , Many optimization rules are provided internally , These internal optimization rules will be introduced in detail later , Today, we will mainly discuss how to do this without modifying the source code , Write and apply our customized optimization rules in the way of plug-ins .
Write an optimization rule in practice
Let's make a simple optimization rule here , Realization function : If we select A numeric field of type to multiply 1.0 This string , Let's optimize the multiplication calculation .
Write optimization rules
import org.apache.spark.internal.Logging
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.catalyst.expressions._
object MultiplyOptimizationRule extends Rule[LogicalPlan] with Logging {
def apply(plan: LogicalPlan): LogicalPlan = plan transformAllExpressions {
case Multiply(left,right) if right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Double] == 1.0 =>
logInfo("MyRule Optimization rules take effect ")
left
}
}
Register optimization rules
adopt spark Provide an interface to register the optimization rules we have written
spark.experimental.extraOptimizations = Seq(MultiplyOptimizationRule)
test result
Let's test it on the command line , We can see Project In the selected field ,(cast(id#7L as double) * 1.0) AS id2#12 Has been optimized to cast(id#7L as double) AS id2#14
scala> val df = spark.range(10).selectExpr("id", "concat('wankun-',id) as name")
df: org.apache.spark.sql.DataFrame = [id: bigint, name: string]
scala> val multipliedDF = df.selectExpr("id * cast(1.0 as double) as id2")
multipliedDF: org.apache.spark.sql.DataFrame = [id2: double]
scala> println(multipliedDF.queryExecution.optimizedPlan.numberedTreeString)
00 Project [(cast(id#7L as double) * 1.0) AS id2#12]
01 +- Range (0, 10, step=1, splits=Some(1))
import org.apache.spark.internal.Logging
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.catalyst.expressions._
object MultiplyOptimizationRule extends Rule[LogicalPlan] with Logging {
def apply(plan: LogicalPlan): LogicalPlan = plan transformAllExpressions {
case Multiply(left,right) if right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Double] == 1.0 =>
logInfo("MyRule Optimization rules take effect ")
left
}
}
scala> spark.experimental.extraOptimizations = Seq(MultiplyOptimizationRule)
spark.experimental.extraOptimizations: Seq[org.apache.spark.sql.catalyst.rules.Rule[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]] = List(MultiplyOptimizationRule$@675d209c)
scala>
scala> val multipliedDFWithOptimization = df.selectExpr("id * cast(1.0 as double) as id2")
multipliedDFWithOptimization: org.apache.spark.sql.DataFrame = [id2: double]
scala> println(multipliedDFWithOptimization.queryExecution.optimizedPlan.numberedTreeString)
00 Project [cast(id#7L as double) AS id2#14]
01 +- Range (0, 10, step=1, splits=Some(1))
Add hook and extension point functions
Through the above example , We go through spark Interface programming provided , It can be implemented to add our customized optimization rules .
But our spark-sql Tools don't allow us to add rules directly , in addition ,catalyst There's also... Inside Analysis, Logical Optimization, Physical Planning Multiple stages , If we want to make a function expansion in these places , It's not convenient . So in Spark 2.2 Version introduces a more powerful feature , Add hooks and extension points .
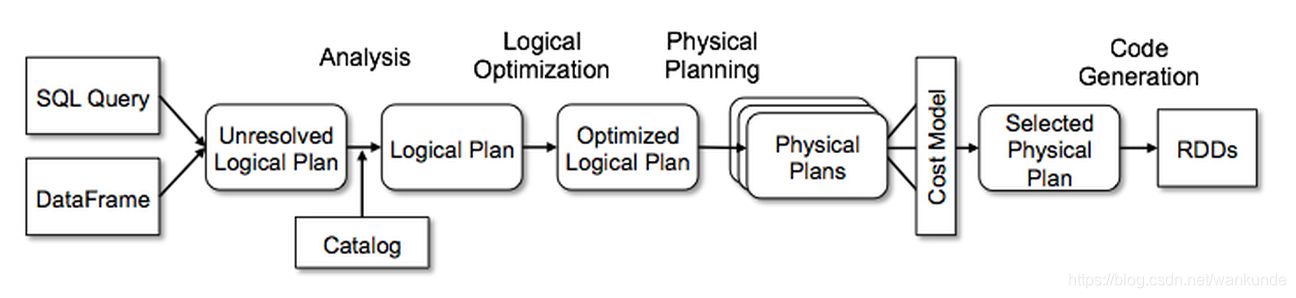
Write custom optimization rules and extension points
Or take the function of realizing function as an example :
package com.wankun.sql.optimizer
import org.apache.spark.internal.Logging
import org.apache.spark.sql.catalyst.expressions.{
Literal, Multiply}
import org.apache.spark.sql.{
SparkSession, SparkSessionExtensions}
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.types.Decimal
/** * @author kun.wan * @date 2020-03-03. */
case class MyRule(spark: SparkSession) extends Rule[LogicalPlan] with Logging {
override def apply(plan: LogicalPlan): LogicalPlan = {
logInfo(" Start using MyRule Optimize the rules ")
plan transformAllExpressions {
case Multiply(left, right) if right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.isInstanceOf[Decimal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Decimal].toDouble == 1.0 =>
logInfo("MyRule Optimization rules take effect ")
left
}
}
}
class MyExtensions extends (SparkSessionExtensions => Unit) with Logging {
def apply(e: SparkSessionExtensions): Unit = {
logInfo(" Get into MyExtensions The extension point ")
e.injectResolutionRule(MyRule)
}
}
Package the above code as spark-extensions-1.0.jar
Configure and enable customization Spark Expand
spark-sql --master local --conf spark.sql.extensions=com.wankun.sql.optimizer.MyExtensions --jars /Users/wankun/ws/wankun/spark-extensions/target/spark-extensions-1.0.jar
Test optimization rules
You can see plan By Analyzed after , Multiplication disappears , Customized optimization rules have taken effect .
spark-sql> explain extended
> with stu as (
> select 1 as id, 'wankun-1' as name
> union
> select 2 as id, 'wankun-2' as name
> union
> select 3 as id, 'wankun-3' as name
> )
> select id * 1.0
> from stu;
20/03/04 01:56:16 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Start using MyRule Optimize the rules
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Start using MyRule Optimize the rules
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Start using MyRule Optimize the rules
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) MyRule Optimization rules take effect
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Start using MyRule Optimize the rules
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Start using MyRule Optimize the rules
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Start using MyRule Optimize the rules
20/03/04 01:56:18 INFO CodeGenerator: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Code generated in 156.862003 ms
== Parsed Logical Plan ==
CTE [stu]
: +- SubqueryAlias `stu`
: +- Distinct
: +- Union
: :- Distinct
: : +- Union
: : :- Project [1 AS id#0, wankun-1 AS name#1]
: : : +- OneRowRelation
: : +- Project [2 AS id#2, wankun-2 AS name#3]
: : +- OneRowRelation
: +- Project [3 AS id#4, wankun-3 AS name#5]
: +- OneRowRelation
+- 'Project [unresolvedalias(('id * 1.0), None)]
+- 'UnresolvedRelation `stu`
== Analyzed Logical Plan ==
id: decimal(10,0)
Project [cast(id#0 as decimal(10,0)) AS id#8]
+- SubqueryAlias `stu`
+- Distinct
+- Union
:- Distinct
: +- Union
: :- Project [1 AS id#0, wankun-1 AS name#1]
: : +- OneRowRelation
: +- Project [2 AS id#2, wankun-2 AS name#3]
: +- OneRowRelation
+- Project [3 AS id#4, wankun-3 AS name#5]
+- OneRowRelation
== Optimized Logical Plan ==
Aggregate [id#0, name#1], [cast(id#0 as decimal(10,0)) AS id#8]
+- Union
:- Project [1 AS id#0, wankun-1 AS name#1]
: +- OneRowRelation
:- Project [2 AS id#2, wankun-2 AS name#3]
: +- OneRowRelation
+- Project [3 AS id#4, wankun-3 AS name#5]
+- OneRowRelation
== Physical Plan ==
*(5) HashAggregate(keys=[id#0, name#1], functions=[], output=[id#8])
+- Exchange hashpartitioning(id#0, name#1, 200)
+- *(4) HashAggregate(keys=[id#0, name#1], functions=[], output=[id#0, name#1])
+- Union
:- *(1) Project [1 AS id#0, wankun-1 AS name#1]
: +- Scan OneRowRelation[]
:- *(2) Project [2 AS id#2, wankun-2 AS name#3]
: +- Scan OneRowRelation[]
+- *(3) Project [3 AS id#4, wankun-3 AS name#5]
+- Scan OneRowRelation[]
Time taken: 1.945 seconds, Fetched 1 row(s)
sparkSession There are extension points left for users in ,Spark catalyst The extension point of is SPARK-18127 Introduced in ,Spark Users can go to SQL Extend custom implementations at various stages of processing , Very powerful and efficient
- injectOptimizerRule – add to optimizer Custom rule ,optimizer Be responsible for the optimization of logical execution plan , In our example, we extend the logic optimization rules .
- injectParser – add to parser Custom rule ,parser be responsible for SQL analysis .
- injectPlannerStrategy – add to planner strategy Custom rule ,planner Responsible for the generation of physical execution plan .
- injectResolutionRule – add to Analyzer Custom rule to Resolution Stage ,analyzer Responsible for generating logical execution plans .
- injectPostHocResolutionRule – add to Analyzer Custom rule to Post Resolution Stage .
- injectCheckRule – add to Analyzer Customize Check The rules .

Reference documents
边栏推荐
- Network device hard core technology insider router Chapter 15 from deer by device to router (Part 2)
- 使用解构交换两个变量的值
- Multi table query_ Exercise 1 & Exercise 2 & Exercise 3
- Leetcode interview question 17.21. water volume double pointer of histogram, monotonic stack /hard
- Spark 本地程序启动缓慢问题排查
- shell脚本读取文本中的redis命令批量插入redis
- [TensorBoard] OSError: [Errno 22] Invalid argument处理
- The design method of integral operation circuit is introduced in detail
- 【剑指offer】面试题55 - Ⅰ/Ⅱ:二叉树的深度/平衡二叉树
- How to package AssetBundle
猜你喜欢

Spark 3.0 DPP实现逻辑

Leetcode interview question 17.21. water volume double pointer of histogram, monotonic stack /hard
Unity performance optimization ----- occlusion culling of rendering optimization (GPU)

【剑指offer】面试题49:丑数

【剑指offer】面试题53-Ⅰ:在排序数组中查找数字1 —— 二分查找的三个模版
![[0 basic operations research] [super detail] column generation](/img/cd/f2521824c9ef6a50ec2be307c584ca.png)
[0 basic operations research] [super detail] column generation

Spark Filter算子在Parquet文件上的下推

学习Parquet文件格式
How to take satisfactory photos / videos from hololens

Leetcode 781. rabbit hash table in forest / mathematical problem medium
随机推荐
复杂度分析
Method of removing top navigation bar in Huawei Hongmeng simulator
【剑指offer】面试题45:把数组排成最小的数
Network equipment hard core technology insider router Chapter 16 dpdk and its prequel (I)
Fluent -- layout principle and constraints
Jump to the specified position when video continues playing
【剑指offer】面试题54:二叉搜索树的第k大节点
Alibaba's latest summary 2022 big factory interview real questions + comprehensive coverage of core knowledge points + detailed answers
$router.back(-1)
Set the position of the prompt box to move with the mouse, and solve the problem of incomplete display of the prompt box
Read the wheelevent in one article
【剑指offer】面试题53-Ⅰ:在排序数组中查找数字1 —— 二分查找的三个模版
2022-07-27 Daily: IJCAI 2022 outstanding papers were published, and 298 Chinese mainland authors won the first place in two items
USB interface electromagnetic compatibility (EMC) solution
实现自定义Spark优化规则
微信公众平台开发概述
使用Lombok导致打印的tostring中缺少父类的属性
TCC
[正则表达式] 单个字符匹配
Network equipment hard core technology insider router Chapter 13 from deer by device to router (Part 1)