当前位置:网站首页>Mysql database learning (8) -- MySQL content supplement
Mysql database learning (8) -- MySQL content supplement
2022-07-07 05:23:00 【Metaphors of the world】
View
What is a view ?
View is to get a virtual table through query , Then save , You can use it directly next time
Why use views ?
If you want to operate a virtual table frequently ( Make up a table ), It can be made into a view , And then continue to operate
# grammar
create view View name as Query of virtual table sql sentence
# give an example
create view emp2dep as select * from emp inner join dep on emp.dep = dep.id;
Be careful
When the view is saved, there will only be table results , No data ( The data still comes from the previous table )
Views are generally only used to query , The data inside does not need to be modified , May affect the real table
View usage frequency
Not much ,
When you create many views , It will make it difficult to maintain the table
trigger
''' Increase the table data when it meets the requirements 、 Delete 、 The function of automatically triggering in case of change Using triggers can help us monitor 、 journal ... Trigger can be in 6 Automatically triggered in case of increase 、 Delete 、 Before and after the change '''
Basic grammar
create trigger Trigger name before/after insert/update/delete on Table name for each row begin sql sentence end;
# Specific use The name of the trigger We need to See the name and know the meaning
create trigger tri_before_insert_ti before insert on t1 for each row begin sql sentence end;
modify MySQL Default statement Terminator , Works only on the current window
delimiter $$ # Change the default ending symbol to $$
delimiter ;
# Case study ( Similar to the error log function )
create table cmd(
id int primary key auto_increment,
user char(32),
priv char(10),
cmd char(64),
sub_time datetime,
success enum("yes", "no") # 0 Delegate execution failed
);
create table errlog(
id int primary key auto_increment,
err_cmd char(64),
err_time datetime
);
''' When cmd In the table success The fields are no Then trigger execution errlog Inject data into the table NEW It refers to data objects '''
delimiter $$
create trigger tri_insert_after_cmd after insert on cmd for each row
begin
if NEW.success = "no" then
insert into errlog(err_cmd, err_time) values (NEW.cmd, NEW.sub_time);
end if;
end $$
delimiter ;
# To cmd Table insert data
insert into cmd (
user,
priv,
cmd,
sub_time,
success
)
values
("aoteman", "0755", "ls -1 /etc", NOW(), "yes"),
("aoteman", "0755", "cat /etc/password", NOW(), "no"),
("aoteman", "0755", "useradd xxx", NOW(), "no"),
("aoteman", "0755", "ps aux", NOW(), "yes");
# Delete trigger
drop trigger tri_insert_after_cmd;

Business
What is business
Starting a transaction can contain multiple SQL sentence , these sql The statement either succeeds at the same time , Either don't think about success , Call it the atomicity of transactions
The role of affairs
Ensure the security of data operation
Four characteristics of transactions (ACID)
A: Atomicity
A transaction is an indivisible unit , Many operations contained in a transaction , Or at the same time , Or fail at the same time
C: Uniformity
The transaction must be to change the database from one consistent state to another consistent state
I: Isolation,
The execution of one transaction cannot be interfered by other transactions ,
That is, the operation and data used within a thing are isolated from other concurrent transactions , Concurrent transactions do not interfere with each other
D: persistence
It's also called permanence
Once a transaction is executed successfully , Changes to database data should be permanent , The following other operations or faults should not have any impact on the alignment
How to use transactions
1. keyword
start transaction;
2. Rollback operation , Return to the state before the transaction is executed
rollback;
3. Secondary confirmation , Cannot rollback after confirmation
commit;
" Analog transfer "
create table user(
id int primary key auto_increment,
name char(16),
balance int
);
insert into user(name, balance) values
("a", 1000),
("b", 1000),
("c", 1000);
# Start transaction first
start transaction;
# multiple sql sentence
update user set balance=900 where name = "a";
update user set balance=1010 where name = "b";
update user set balance=1090 where name = "c";
rollback;
commit;
stored procedure
Be similar to python Medium Custom function
It contains a series of executable sql sentence , Stored procedures are stored in Mysql Server side , Trigger can be used directly sql Statement execution
delimiter $$
create procedure Name of stored procedure ( Shape parameter 1, Shape parameter 2)
begin
sql sentence
end
delimiter ;
call Name of stored procedure ();
Three development models
1. Application programmers write code for development ,MySQL Write stored procedures in advance , Supply the program call ——( advantage ) Improve development efficiency , Improve the efficiency of execution ;( shortcoming ) Considering the human element 、 Cross departmental communication issues , The scalability of subsequent stored procedures is poor
2. Applications : Programmers write code outside of development , The database operation is also written by myself ——( advantage ) High expansibility ;( shortcoming ) Reduced development efficiency , To write sql The sentence is too complicated , You need to think about sql The problem of optimization
3. Applications only write code , Don't write sql sentence , Based on what others have written MySQL Of python frame (ORM frame ) It can be operated directly ——( advantage ) High development efficiency ;( shortcoming ) Because it is encapsulated by others , Poor extensibility of statements , There may be inefficiencies
Stored procedure demonstration
delimiter $$
create procedure d1(
in m int, # Can't get in , m Can't go back out
in n int,
out res int # This parameter can be returned
)
begin
select * from emp where id > m and age > n;
set res=0; # take res Variable modification , Used to identify that the current stored procedure code is actually executed
end$$
delimiter ;
call d1(1, 28, 10); # Report errors
# in the light of Shape parameter res Can't transfer data directly Should pass a variable name
# Defining variables
set @ret = 10;
# Look at the value of the variable
select @ret;
call d1(1, 28, @ret)
stay pyMySQL How to call
import pymysql
......
......
# Calling stored procedure
cursor.callproc(d1, (1, 5, 10))
print(cursor.fetchall())
function
It's different from stored procedures , It is equivalent to that the stored procedure is a user-defined function , Functions are built-in functions
for instance : NOW()
create table blog(
id int primary key auto_increment,
name char(32),
sub_time datetime
);
insert into blog(name, sub_time)
values
(" The first 1 piece ", "2015-03-01 11:31:21"),
(" The first 2 piece ", "2015-03-11 16:31:21"),
(" The first 3 piece ", "2016-07-01 10:21:21"),
(" The first 4 piece ", "2016-07-22 09:23:21"),
(" The first 5 piece ", "2016-07-23 10:11:11"),
(" The first 6 piece ", "2016-07-25 11:21:31"),
(" The first 7 piece ", "2017-03-01 15:33:21"),
(" The first 8 piece ", "2017-03-01 17:32:21"),
(" The first 9 piece ", "2017-03-01 18:31:21");
select date_format(sub_time, "%Y-%m"), count(id) from blog group by date_format(sub_time, "%Y-%m");

Process control
# if Judge
delimiter //
create procedure proc_if()
begin
declare i int defalut 0;
if i=1 then
select 1;
elseif i =2 then
select 2;
else
select 7;
end if;
end //
delimiter ;
# while loop
delimiter //
create procedure proc_while()
begin
declare num int ;
set num = 0;
while num < 10 do
select
num;
set num = num - 1;
end while;
end //
delimiter ;
Indexes
The data is stored on the hard disk , Querying data inevitably requires IO operation
Indexes : It's a data structure , A catalogue similar to a book . It means that when querying data, you first find the directory and then the data , So as to improve the query speed and reduce IO operation
Index in MySQL It's also called “ key ”, It is a data structure for storage engine to quickly find records (innodb,)
primary key
unique key
index key
Be careful foreign key It is not used to speed up the query
The three above key, In addition to increasing the query speed, the first two have constraints , and index key There are no constraints , Just to help you quickly query data
The essence
Constantly narrow the desired data range and filter out the final results , At the same time, random events ( Turn page by page ) Become sequential events ( Find the directory first 、 To find the data )
That is to say, with index data , We can always find data in a fixed way
There can be multiple indexes in a table ( Multiple directories ), For example, Xinhua dictionary can be looked up with radicals , You can also use pinyin to check .
Although indexing can help you speed up your query , There are also shortcomings
1. When there is a large amount of data in the table , Index creation will be slow
2. After the index is created , The query performance of tables is greatly improved , But the performance of writing will also be greatly reduced
Don't create indexes randomly !!!
b+ Trees
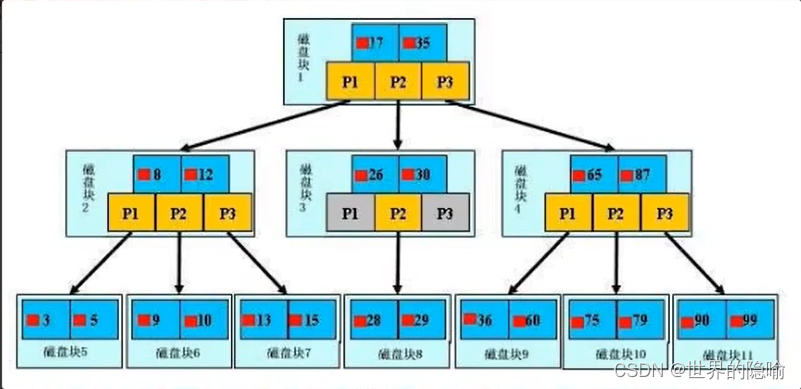
Only leaf nodes are real data , The data stored in other nodes is virtual data , It's only used to show the way
The higher the tree level, the more steps it takes to query data ( There are several layers in the tree , It takes several layers to query data )
A disk block storage is limited , When storing, I hope that the larger the data stored, the better , So recommend id A primary key , because Integer takes up less space, and a disk block stores more data , Lowered the height of the tree , Thus reducing the number of queries
Clustered index (primary key)
# A clustered index is Primary key
''' innodb There are only two documents Directly set the primary key Stored in data table (idb) MyIsam Three files There will be a file to search for alone '''
Secondary index (unique key)
''' Can't you use the primary key all the time when querying data , Other fields may also be used , There is no way to use clustered indexes , At this time, you can set the auxiliary index for other fields according to ( It's also b+ Trees ) The secondary index leaf node stores the primary key value corresponding to the data First get the primary key value of the data according to the auxiliary index After that, you still need to query the data in the clustered index of the primary key '''
Overlay index
The leaf node of the secondary index has obtained the required data
# to name Set secondary index
select name from user where name = "aoteman";
# Non coverage index
select age from user where name = "aoteman"
边栏推荐
猜你喜欢
Complete code of C language neural network and its meaning
Safe landing practice of software supply chain under salesforce containerized ISV scenario

漏电继电器LLJ-100FS
SQL injection cookie injection
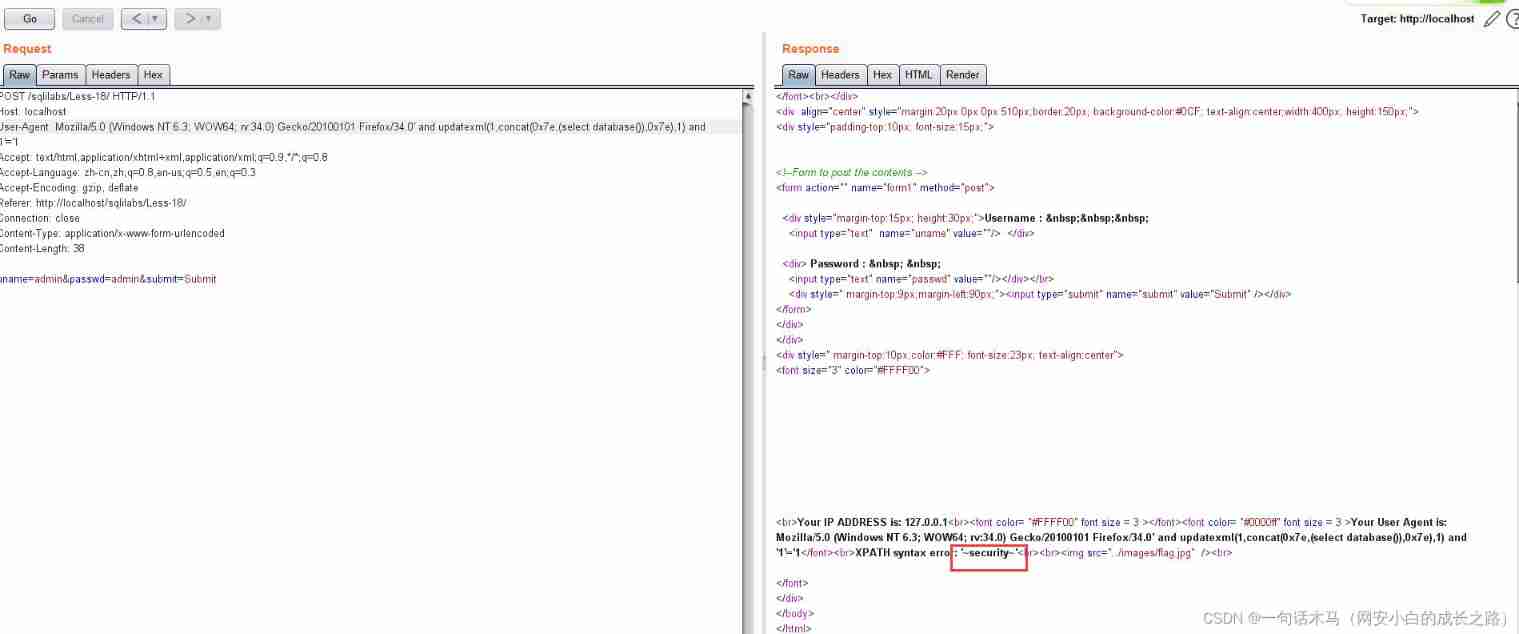
SQL injection HTTP header injection

Is the human body sensor easy to use? How to use it? Which do you buy between aqara green rice and Xiaomi

Under the trend of Micah, orebo and apple homekit, how does zhiting stand out?
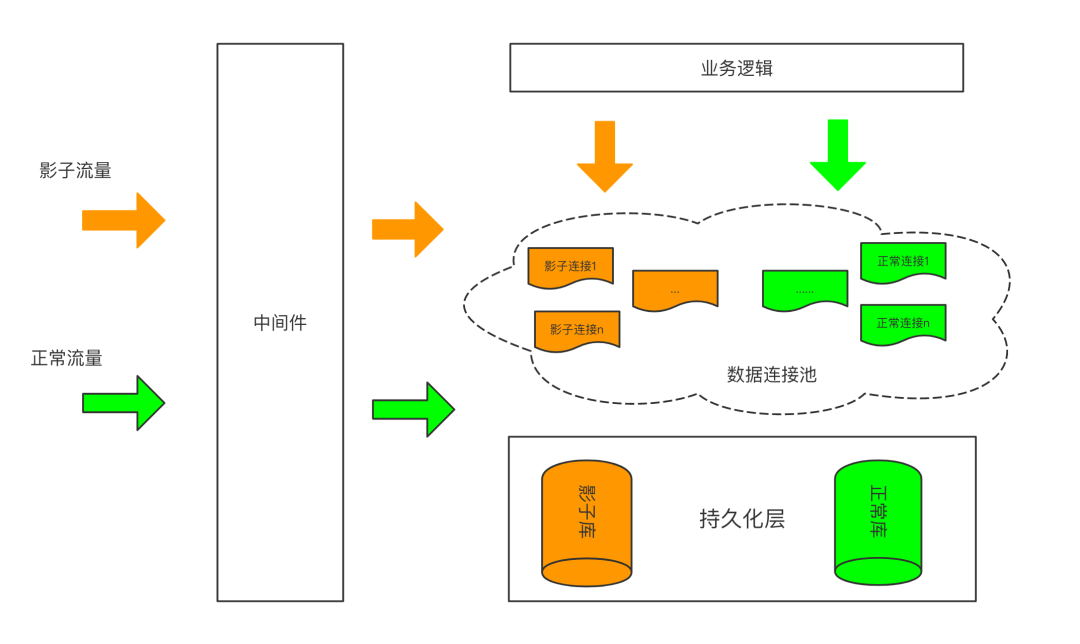
全链路压测:影子库与影子表之争
Error: No named parameter with the name ‘foregroundColor‘
【问道】编译原理
随机推荐
Leetcode (46) - Full Permutation
If you want to choose some departments to give priority to OKR, how should you choose pilot departments?
Longest palindrome substring (dynamic programming)
Techniques d'utilisation de sublime
ThinkPHP关联预载入with
最长公共子序列(LCS)(动态规划,递归)
Auto.js 获取手机所有app名字
【QT】自定义控件-Loading
Full link voltage test: the dispute between shadow database and shadow table
If you‘re running pod install manually, make sure flutter pub get is executed first.
照片选择器CollectionView
DBSync新增对MongoDB、ES的支持
Error: No named parameter with the name ‘foregroundColor‘
What changes will PMP certification bring?
Under the trend of Micah, orebo and apple homekit, how does zhiting stand out?
AOSP ~Binder 通信原理 (一) - 概要
SQL injection HTTP header injection
【最佳网页宽度及其实现】「建议收藏」
Is it necessary to renew the PMP certificate?
Simulate thread communication