当前位置:网站首页>Spark基础【介绍、入门WordCount案例】
Spark基础【介绍、入门WordCount案例】
2022-08-05 03:27:00 【hike76】
文章目录
一 概述
0 Spark和Hadoop的关系
(1)从时间节点上来看
Hadoop
- 2006年1月,Doug Cutting加入Yahoo,领导Hadoop的开发
- 2008年1月,Hadoop成为Apache顶级项目
- 2011年1.0正式发布
- 2012年3月稳定版发布
- 2013年10月发布2.X (Yarn)版本
Spark
- 2009年,Spark诞生于伯克利大学的AMPLab实验室
- 2010年,伯克利大学正式开源了Spark项目
- 2013年6月,Spark成为了Apache基金会下的项目
- 2014年2月,Spark以飞快的速度成为了Apache的顶级项目
- 2015年至今,Spark变得愈发火爆,大量的国内公司开始重点部署或者使用Spark
(2)从功能上来看
Hadoop
- Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架
- 作为Hadoop分布式文件系统,HDFS处于Hadoop生态圈的最下层,存储着所有的数据,支持着Hadoop的所有服务。它的理论基础源于Google的TheGoogleFileSystem这篇论文,它是GFS的开源实现
- MapReduce是一种编程模型,Hadoop根据Google的MapReduce论文将其实现,作为Hadoop的分布式计算模型,是Hadoop的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了HDFS的分布式存储和MapReduce的分布式计算,Hadoop在处理海量数据时,性能横向扩展变得非常容易
- HBase是对Google的Bigtable的开源实现,但又和Bigtable存在许多不同之处。HBase是一个基于HDFS的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是Hadoop非常重要的组件
Spark
- Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core中提供了Spark最基础与最核心的功能
- Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据
- Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API
由上面的信息可以获知,Spark出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实Spark一直被认为是Hadoop框架的升级版,但其实不是
1 Hadoop 0.x 1.x的问题
NameNode是单点的,容易出现单点故障,制约了集群的发展
NameNode是单点的,受到了硬件的制约,制约了集群的发展
MapReduce运行速度太慢,主要因为设计理念的问题,MR早期就是用于单一数据计算,在当前数据挖掘和数据迭代计算情景中不适用
单一数据计算:MR主要应用于数据的一次性计算,从存储介质中读取数据,经过处理后,再存储回介质中
迭代计算:计算得出的结果传递给下一次计算,也就是上一次的输出是下一次的输入
为什么慢:如果MR想进行迭代计算,它的每一次计算结果都需要落盘,是基于文件运算的
MR框架和Hadoop耦合性非常强,无法分离
2 Hadoop 2.x
增加了一个资源调度框架,将计算和资源解耦合,Yarn,也将Hadoop 2.x 称为Yarn版本
解决了
NameNode单点问题,使其变为了高可用的
将资源调度和计算解耦合,耦合性低意味着扩展性强
RM,NM(MRAppMaster),NM(MRTask)
可以替换MR计算框架,但MR自己的计算速度并没有提升
3 Spark
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark是基于MR框架的,但是优化了其中的计算过程,使用内存代替了计算结果的传输
Spark是基于Scala语言开发的,函数式编程语言,更适合迭代计算和数据挖掘计算
Spark中计算模型十分丰富
MR中的计算模型只有两个:Mapper和Reducer,这时对于一些复杂需求,一个job完成不了,就需要作业的调度
Scala中的计算模型:map,filter,groupBy,sortBy,在一个job中就可以完成
Yarn中的RM,NM(MRAppMaster),NM(MRTask)在Spark中分别称为
Master,Worker(Driver),Worker(Executor)
实际情况下,Spark和Yarn是共同使用的,Spark(计算) On Yarn(资源),主要使用到以下几个组件
RM,NM(container(Driver)),NM(container(Executor))
将NM理解为当前使用的电脑,container理解为VMWare,Driver理解为虚拟机内部的操作系统,通过container解耦合
4 Spark 和 Hadoop
- Hadoop MapReduce由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以Spark应运而生,Spark就是在传统的MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型
- 机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。而Spark所基于的scala语言恰恰擅长函数的处理
- Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法
- Spark和Hadoop的根本差异是多个作业之间的数据通信问题 : Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘
- Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式
- Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互
- Spark的缓存机制比HDFS的缓存机制高效
经过上面的比较,可以看出在绝大多数的数据计算场景中,Spark确实会比MapReduce更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR
5 Spark核心模块

Spark Core
Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib都是在Spark Core的基础上进行扩展的
Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据
Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API
Spark MLlib
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语
Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库
二 WordCount
1 创建项目
创建一个Maven项目WordCount,包名为com.hike.spark
2 导入依赖
Spark是一个计算框架,需要通过导入依赖找到它
2.12为scala版本
3.0.0为spark版本
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
3 获取Spark的连接(环境)
//创建SparkConf并设置App名称
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
//创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//关闭连接
sc.stop()
4 编写代码
(1)简单实现
//读取指定位置文件
val lines = sc.textFile("data/word.txt")
//将文件中的数据进行分词
val words = lines.flatMap(_.split(" "))
//将分词后的数据进行分组
val wordGroup = words.gropuBy(word => word)
//将分词后的数据进行统计分析
val wordCount = wordGroup.mapValues(_.size)
//7.将统计结果采集到控制台打印
wordCount.collect().foreach(println)
(2)基于scala的优化
统计分析部分并没有体现出数据运算的过程,修改统计分析部分代码
// 读取指定位置文件
val lines = sc.textFile("data/word.txt")
// 将文件中的数据进行分词
// 将word改变形式:word => (word,1)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_,1))
// 将分词后的数据进行分组
// word => list((word,1),(word,1) => List((word,2)))
val wordGroup = wordToOne.gropuBy(word => word)
// 将分词后的数据进行统计分析
val wordCount = wordGroup.mapValues(
list => {
list.reduce(
(t1,t2) => {
(t1._1,t1._2 + t2._2)
}
)._2
}
)
// 将统计结果采集到控制台打印
wordCount.collect().foreach(println)
(3)基于spark的优化
使用Spark框架内的功能,修改分组,统计分析部分代码
// 读取指定位置文件
val lines = sc.textFile("data/word.txt")
// 将文件中的数据进行分词
// 将word改变形式:word => (word,1)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_,1))
// reduceByKey:按照key分组,对象同key的V进行reduce
// (word,1)(word,1)(word,1)(word,1)(word,1)
// reduce(1,1,1,1,1)
val wordCount = wordToOne.reduceByKey(_+_)
// 将统计结果采集到控制台打印
wordCount.collect().foreach(println)
框架的核心就是封装
(4)添加日志配置
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项目的resources目录中创建log4j.properties文件,并添加日志配置信息:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
边栏推荐
- Getting Started with Kubernetes Networking
- 沃谈小知识 |“远程透传”那点事儿
- 【滤波跟踪】基于matlab无迹卡尔曼滤波惯性导航+DVL组合导航【含Matlab源码 2019期】
- Solana NFT开发指南
- Native js realizes the effect of selecting and canceling all the multi-select boxes
- 为什么pca分量没有关联
- 21天学习挑战赛(2)图解设备树的使用
- [Paper Notes] MapReduce: Simplified Data Processing on Large Clusters
- 【已解决】Unity Coroutinue 协程未有效执行的问题
- 高项 02 信息系统项目管理基础
猜你喜欢
![[Software testing] unittest framework for automated testing](/img/80/caedd5cf6dd61c9d75475866613cac.png)
[Software testing] unittest framework for automated testing
Principle and Technology of Virtual Memory

Use SuperMap iDesktopX data migration tool to migrate map documents and symbols

Everyone in China said data, you need to focus on core characteristic is what?
10 years of testing experience, worthless in the face of the biological age of 35

How to sort multiple fields and multiple values in sql statement
public static
List asList(T... a) What is the prototype? 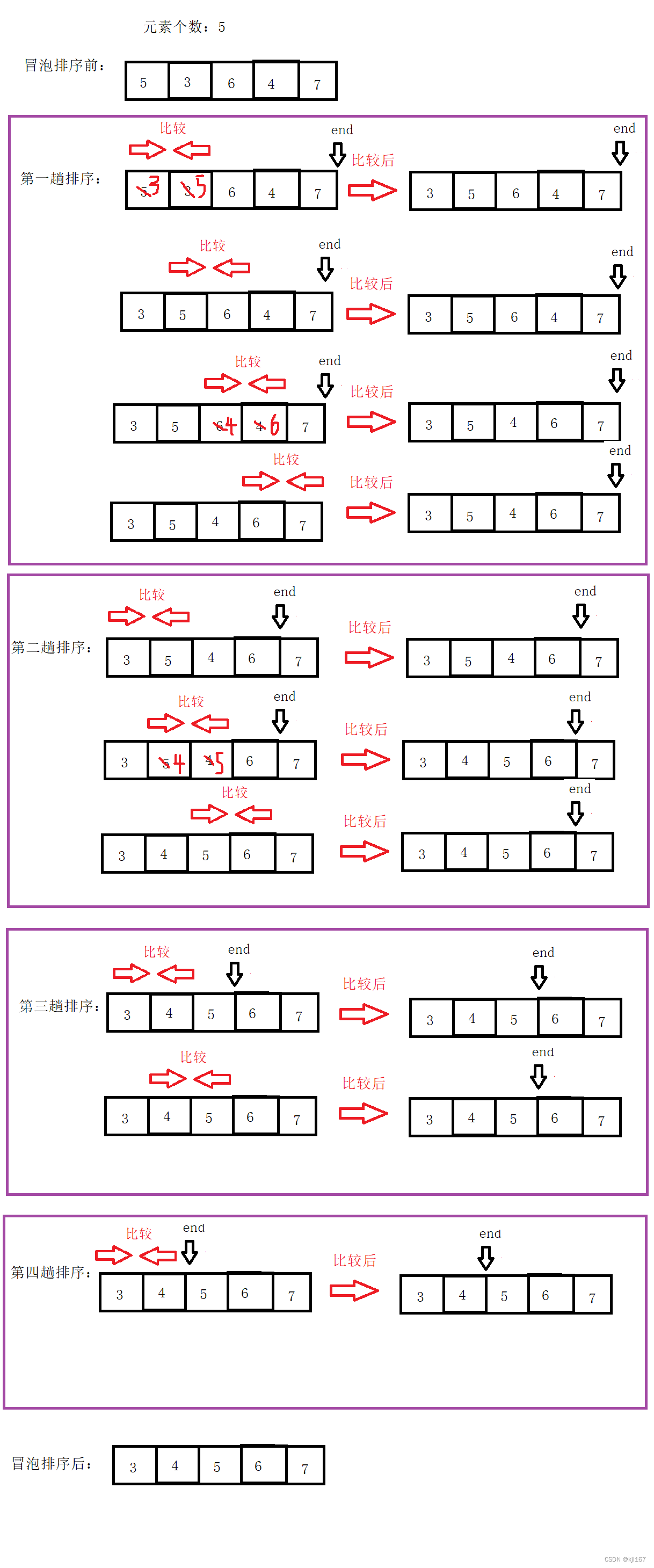
Bubble Sort and Quick Sort
冒泡排序与快速排序
Flink 1.15.1 Cluster Construction (StandaloneSession)
随机推荐
Thinking (88): Use protobuf custom options for multi-version management of data
Defect detection (image processing part)
调用阿里云oss和sms服务
sql server installation prompts that the username does not exist
引领数字医学高地,中山医院探索打造未来医院“新范式”
token、jwt、oauth2、session解析
Never put off till tomorrow what you can put - house lease management system based on the SSM
leetcode-每日一题1403. 非递增顺序的最小子序列(贪心)
21天学习挑战赛(2)图解设备树的使用
【软件测试】自动化测试之unittest框架
.NET Application -- Helloworld (C#)
Slapped in the face: there are so many testers in a certain department of byte
How to simulate the background API call scene, very detailed!
[Paper Notes] MapReduce: Simplified Data Processing on Large Clusters
为什么pca分量没有关联
The sword refers to Offer--find the repeated numbers in the array (three solutions)
Distributed systems revisited: there will never be a perfect consistency scheme...
Fifteen. Actual combat - MySQL database building table character set and collation
How to discover a valuable GameFi?
IJCAI2022 | DictBert: Pre-trained Language Models with Contrastive Learning for Dictionary Description Knowledge Augmentation