当前位置:网站首页>Crawler (III) crawling house prices in Tianjin
Crawler (III) crawling house prices in Tianjin
2022-07-04 06:51:00 【wei2023】
One 、 Basic concepts
Web crawler (Crawler): Also known as web spider , Or cyber robots (Robots). It's a rule of thumb , A program or script that automatically grabs information from the world wide web . In other words , It can automatically obtain the web content according to the link address of the web page . If the Internet is compared to a big spider web , There are many web pages in it , Web spiders can get the content of all web pages .
Crawler is a simulated human behavior of requesting websites , A program or automated script that downloads Web resources in batches .Reptiles : Use any technical means , A way to get information about a website in bulk . The key is volume .
The crawler : Use any technical means , A way to prevent others from obtaining their own website information in bulk . The key is also volume .Accidental injury : In the process of anti crawler , Wrong identification of ordinary users as reptiles . Anti crawler strategy with high injury rate , No matter how good the effect is .
Intercept : Successfully blocked crawler access . Here's the concept of interception rate . Generally speaking , Anti crawler strategy with higher interception rate , The more likely it is to be injured by mistake . So there's a trade-off .
Two 、 Basic steps
(1) Request web page :
adopt HTTP The library makes a request to the target site , Send a Request, The request can contain additional headers etc.
Information , Wait for the server to respond !
(2) Get the corresponding content :
If the server can respond normally , You'll get one Response,Response The content of is the content of the page , There may be HTML,Json character string , binary data ( Like picture video ) Other types .
(3) Parsing content :
What you get may be HTML, You can use regular expressions 、 Web page parsing library for parsing . May be Json, Sure
Go straight to Json Object parsing , It could be binary data , It can be preserved or further processed .
(4) Store parsed data :
There are various forms of preservation , Can be saved as text , It can also be saved to a database , Or save a file in a specific format
#========== guide package =============
import requests
#=====step_1 : finger set url=========
url = 'https://gy.fang.lianjia.com/ /'
#=====step_2 : Hair rise please seek :======
# send use get Fang Law Hair rise get please seek , The Fang Law Meeting return return One individual ring Should be Yes like . ginseng Count url surface in please seek Yes Should be Of url
response = requests . get ( url = url )
#=====step_3 : a take ring Should be Count According to the :===
# through too transfer use ring Should be Yes like Of text Belong to sex , return return ring Should be Yes like in save Store Of word operator strand shape type Of ring Should be Count According to the ( page Noodles Source Code number According to the )
page_text = response . text
#====step_4 : a For a long time turn save Store =======
with open (' House prices in Tianjin . html ','w', encoding ='utf -8') as fp:
fp.write ( page_text )
print (' climb take Count According to the End BI !!!')
3、 ... and 、 practice : Crawl data
# ================== Import related libraries ==================================
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
# ============= Read the web page =========================================
def craw(url, page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers, timeout=10)
html1.encoding = 'utf-8' # Add code , important ! Convert to string encoding ,read() Get is byte Format
html = html1.text
return html
except RequestException: # Other questions
print(' The first {0} Failed to read page '.format(page))
return None
# ========== Parse the web page and save the data to the table ======================
def pase_page(url, page):
html = craw(url, page)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"-- First determine the house information , namely li Tag list --"
houses = soup.select('.resblock-list-wrapper li') # List of houses
"-- Then determine the information of each house --"
for j in range(len(houses)): # Traverse every house
house = houses[j]
" name "
recommend_project = house.select('.resblock-name a.name')
recommend_project = [i.get_text() for i in recommend_project] # name Yinghua Tianyuan , Binxin Jiangnan imperial residence ...
recommend_project = ' '.join(recommend_project)
# print(recommend_project)
" type "
house_type = house.select('.resblock-name span.resblock-type')
house_type = [i.get_text() for i in house_type] # Office buildings , commercial real estate under residential buildings ...
house_type = ' '.join(house_type)
# print(house_type)
" Room shape "
house_com = house.select('.resblock-room span')
house_com = [i.get_text() for i in house_com] # 2 room 3 room
house_com = ' '.join(house_com)
# print(house_com)
" area "
house_area = house.select('.resblock-area span')
house_area = [i.get_text() for i in house_area] # 2 room 3 room
house_area = ' '.join(house_area)
# print(house_area)
" Sales status "
sale_status = house.select('.resblock-name span.sale-status')
sale_status = [i.get_text() for i in sale_status] # On sale , On sale , sell out , On sale ...
sale_status = ' '.join(sale_status)
# print(sale_status)
" Large address "
big_address = house.select('.resblock-location span')
big_address = [i.get_text() for i in big_address] #
big_address = ''.join(big_address)
# print(big_address)
" Specific address "
small_address = house.select('.resblock-location a')
small_address = [i.get_text() for i in small_address] #
small_address = ' '.join(small_address)
# print(small_address)
" advantage ."
advantage = house.select('.resblock-tag span')
advantage = [i.get_text() for i in advantage] #
advantage = ' '.join(advantage)
# print(advantage)
" Average price : How many? 1 flat "
average_price = house.select('.resblock-price .main-price .number')
average_price = [i.get_text() for i in average_price] # 16000,25000, The price is to be determined ..
average_price = ' '.join(average_price)
# print(average_price)
" The total price , Ten thousand units "
total_price = house.select('.resblock-price .second')
total_price = [i.get_text() for i in total_price] # The total price 400 ten thousand / set , The total price 100 ten thousand / set '...
total_price = ' '.join(total_price)
# print(total_price)
# ===================== Write table =================================================
information = [recommend_project, house_type, house_com, house_area, sale_status, big_address,
small_address, advantage,
average_price, total_price]
information = np.array(information)
information = information.reshape(-1, 10)
information = pd.DataFrame(information,
columns=[' name ', ' type ', ' size ', ' Main area ', ' Sales status ', ' Large address ', ' Specific address ', ' advantage ', ' Average price ',
' The total price '])
information.to_csv(' House prices in Tianjin .csv', mode='a+', index=False, header=False) # mode='a+' Append write
print(' The first {0} Page storage data succeeded '.format(page))
else:
print(' Parse failure ')
# ================== Two threads =====================================
import threading
for i in range(1, 100, 2): # Traverse the web 1-101
url1 = "https://tj.fang.lianjia.com/loupan/pg" + str(i) + "/"
url2 = "https://tj.fang.lianjia.com/loupan/pg" + str(i + 1) + "/"
pase_page(url1, i)
t1 = threading.Thread(target=pase_page, args=(url1, i)) # Threads 1
t2 = threading.Thread(target=pase_page, args=(url2, i + 1)) # Threads 2
t1.start()
t2.start()
Crawled data : House prices in Tianjin .csv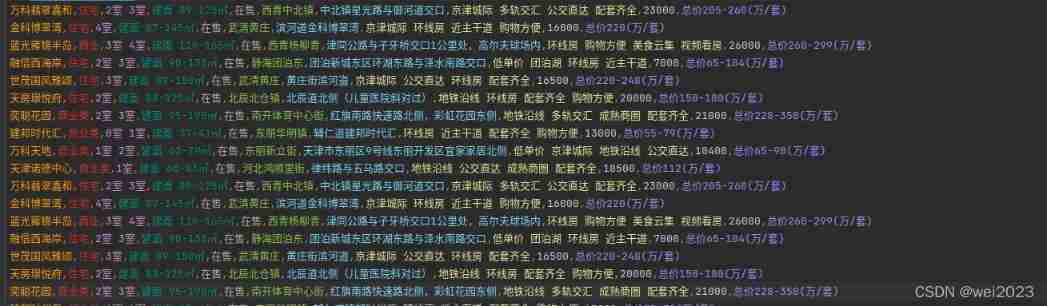
Four 、 Data analysis
边栏推荐
- uniapp 自定義環境變量
- MySQL 45 lecture learning notes (VI) global lock
- 金盾视频播放器拦截的软件关键词和进程信息
- 响应式移动Web测试题
- [MySQL] introduction, function, creation, view, deletion and modification of database view (with exercises)
- About how idea sets up shortcut key sets
- Bottom problem of figure
- Redis面试题集
- 1、 Relevant theories and tools of network security penetration testing
- Mysql 45讲学习笔记(十)force index
猜你喜欢
The solution of win11 taskbar right click without Task Manager - add win11 taskbar right click function

what the fuck! If you can't grab it, write it yourself. Use code to realize a Bing Dwen Dwen. It's so beautiful ~!
Uniapp applet subcontracting

Wechat applet scroll view component scrollable view area
Fundamentals of SQL database operation
How notepad++ counts words
Variables d'environnement personnalisées uniapp
MySQL relearn 2- Alibaba cloud server CentOS installation mysql8.0

24 magicaccessorimpl can access the debugging of all methods
![[MySQL] introduction, function, creation, view, deletion and modification of database view (with exercises)](/img/03/2b37e63d0d482d5020b7421ac974cb.jpg)
[MySQL] introduction, function, creation, view, deletion and modification of database view (with exercises)
随机推荐
Displaying currency in Indian numbering format
STM32 单片机ADC 电压计算
what the fuck! If you can't grab it, write it yourself. Use code to realize a Bing Dwen Dwen. It's so beautiful ~!
MySQL 45 lecture learning notes (12) MySQL will "shake" for a while
MySQL 45 learning notes (XI) how to index string fields
由于dms升级为了新版,我之前的sql在老版本的dms中,这种情况下,如何找回我之前的sql呢?
What is the "relative dilemma" in cognitive fallacy?
图的底部问题
tars源码分析之1
[GF (q) + LDPC] regular LDPC coding and decoding design and MATLAB simulation based on the GF (q) field of binary graph
2022 is probably the best year for the economy in the next 10 years. Did you graduate in 2022? What is the plan after graduation?
Redis面试题集
How notepad++ counts words
tars源码分析之3
【GF(q)+LDPC】基于二值图GF(q)域的规则LDPC编译码设计与matlab仿真
【FPGA教程案例8】基于verilog的分频器设计与实现
请问旧版的的常用SQL怎么迁移到新版本里来?
[FPGA tutorial case 8] design and implementation of frequency divider based on Verilog
the input device is not a TTY. If you are using mintty, try prefixing the command with ‘winpty‘
Deep understanding of redis -- a new type of bitmap / hyperloglgo / Geo