当前位置:网站首页>Yolov6 practice: teach you to use yolov6 for object detection (with data set)
Yolov6 practice: teach you to use yolov6 for object detection (with data set)
2022-07-04 04:50:00 【AI Hao】
Abstract
YOLOv6 Mainly in the BackBone、Neck、Head And the training strategy :
- Unified design of more efficient Backbone and Neck : Inspired by the design idea of hardware aware neural network , be based on RepVGG style[4] Design the re parameterization 、 More efficient backbone network EfficientRep Backbone and Rep-PAN Neck.
- Optimized the design of more concise and effective Efficient Decoupled Head, While maintaining accuracy , It further reduces the additional delay overhead caused by the general decoupling head .
- In training strategy , use Anchor-free Anchor free paradigm , At the same time with SimOTA[2] Tag allocation strategy and SIoU[9] Boundary box regression loss to further improve the detection accuracy .
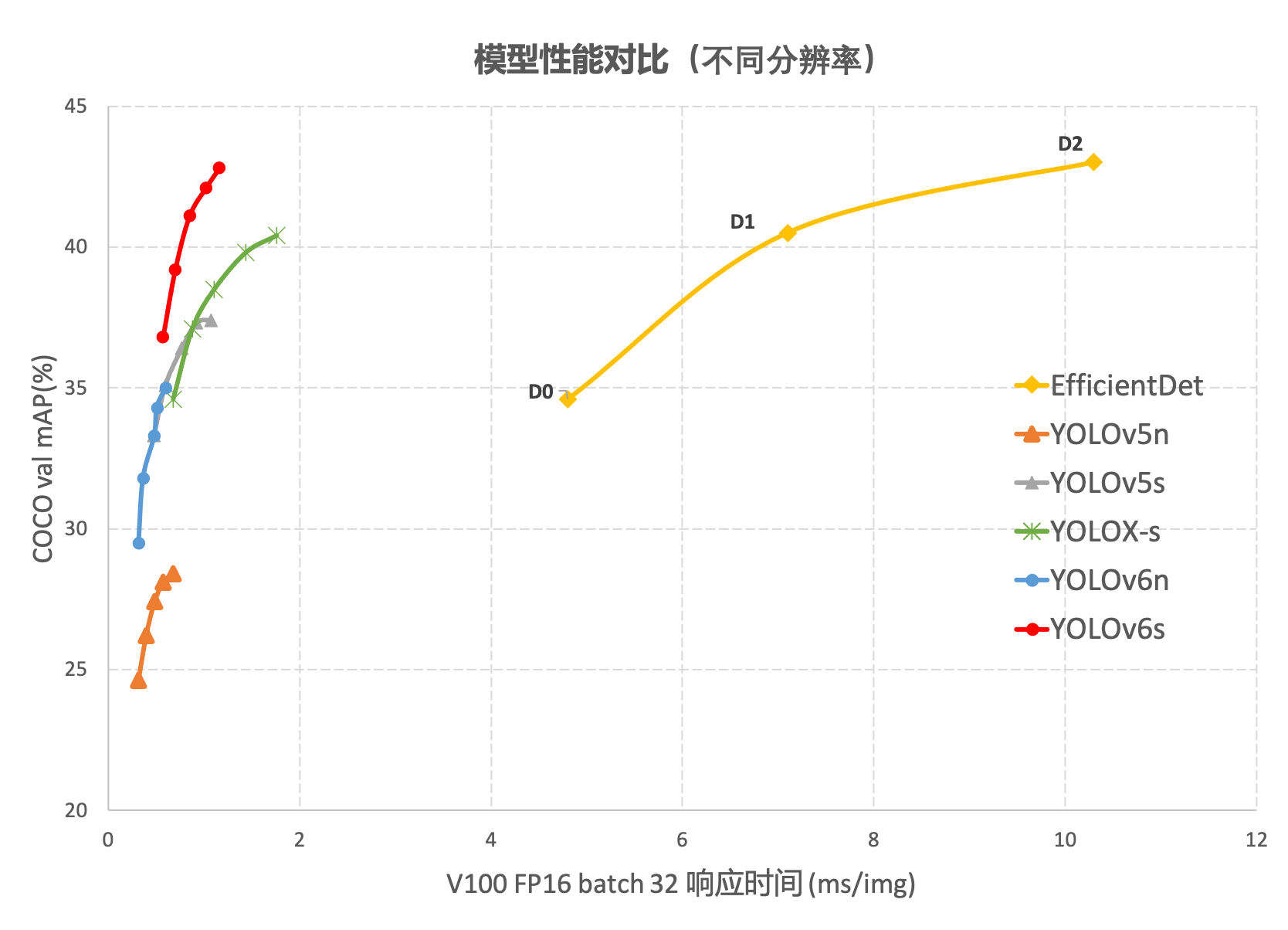
stay COCO On dataset ,YOLOv6 In terms of accuracy and speed, it surpasses YOLOv5、YOLOX and PP-YOLOE Wait for such a representative algorithm , The relevant results are shown in the figure below Shown :
There is no paper in this article , Only a paper by meituan introduces and github Code for , Links are as follows :
github Address :https://github.com/meituan/YOLOv6
See :
https://tech.meituan.com/2022/06/23/yolov6-a-fast-and-accurate-target-detection-framework-is-opening-source.html
Today's article mainly demonstrates how to run through the code .
Data sets
The dataset is Labelme Annotated datasets , Download address :
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/14003627
The data set is made by me for adjusting the object detection model , There are two categories of datasets , Namely :aircraft,oiltank.
If someone wants to try something else , You can also choose another data set I made , It's also Labelme Format of dimensions , Links are as follows :
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/63242994.
in total 32 Grow a plane :
[‘c17’, ‘c5’, ‘helicopter’, ‘c130’, ‘f16’, ‘b2’, ‘other’, ‘b52’, ‘kc10’, ‘command’, ‘f15’, ‘kc135’, ‘a10’, ‘b1’, ‘aew’, ‘f22’, ‘p3’, ‘p8’, ‘f35’, ‘f18’, ‘v22’, ‘f4’, ‘globalhawk’, ‘u2’, ‘su-27’, ‘il-38’, ‘tu-134’, ‘su-33’, ‘an-70’, ‘su-24’, ‘tu-22’, ‘il-76’]
Next is how to make yolov6 Data sets ,yolov6 Data set format used and yolov5 equally . Pictured :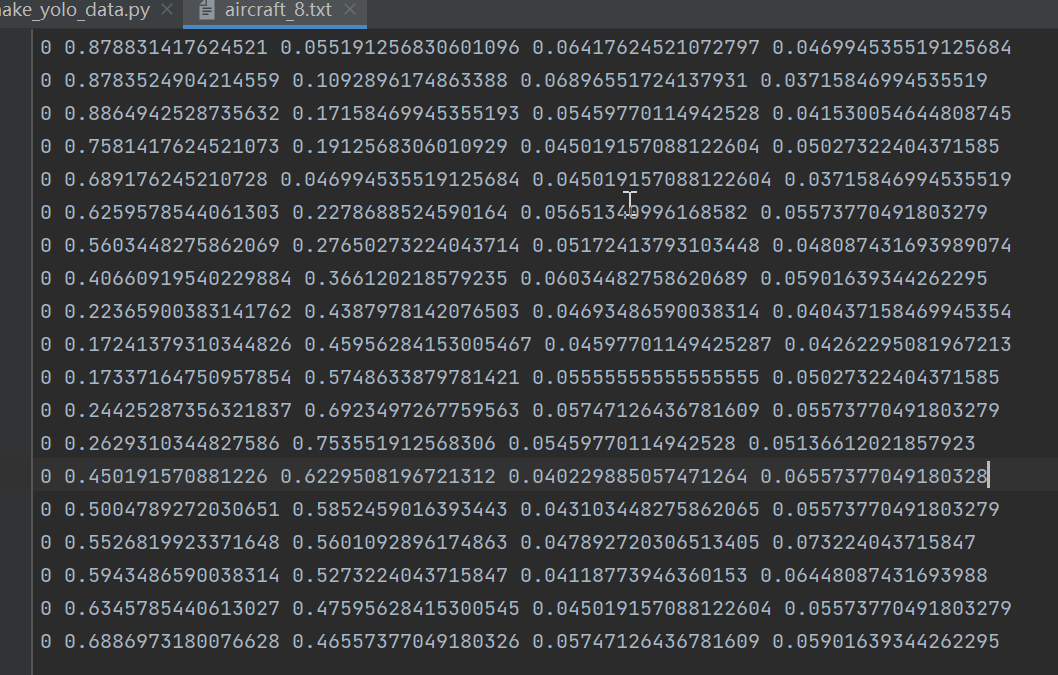
Format : Category , Center point x, Center point y,w,h.
New script make_yolo_data.py, Insert code :
import os
import shutil
import numpy as np
import json
from glob import glob
import cv2
from sklearn.model_selection import train_test_split
from os import getcwd
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def change_2_yolo5(files, txt_Name):
imag_name=[]
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w')
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
# image_path = labelme_path + json_file['imagePath']
imag_name.append(json_file['imagePath'])
height, width, channels = cv2.imread(labelme_path + json_file_ + ".jpg").shape
for multi in json_file["shapes"]:
points = np.array(multi["points"])
xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0
xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0
ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0
ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
cls_id = classes.index(label)
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
#print(json_filename, xmin, ymin, xmax, ymax, cls_id)
return imag_name
def image_txt_copy(files,scr_path,dst_img_path,dst_txt_path):
""" :param files: Picture name list :param scr_path: Path to picture :param dst_img_path: The path where the picture is copied :param dst_txt_path: The picture corresponds to txt Path copied to :return: """
for file in files:
img_path=scr_path+file
shutil.copy(img_path, dst_img_path+file)
scr_txt_path=scr_path+file.split('.')[0]+'.txt'
shutil.copy(scr_txt_path, dst_txt_path + file.split('.')[0]+'.txt')
if __name__ == '__main__':
classes = ["aircraft", "oiltank"]
# 1. Tag path
labelme_path = "LabelmeData/"
isUseTest = True # Whether to create test Set
# 3. Get the pending file
files = glob(labelme_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55)
# split
train_files, val_files = train_test_split(trainval_files, test_size=0.1, random_state=55)
train_name_list=change_2_yolo5(train_files, "train")
print(train_name_list)
val_name_list=change_2_yolo5(val_files, "val")
test_name_list=change_2_yolo5(test_files, "test")
# Create dataset folder .
file_List = ["train", "val", "test"]
for file in file_List:
if not os.path.exists('./VOC/images/%s' % file):
os.makedirs('./VOC/images/%s' % file)
if not os.path.exists('./VOC/labels/%s' % file):
os.makedirs('./VOC/labels/%s' % file)
image_txt_copy(train_name_list,labelme_path,'./VOC/images/train/','./VOC/labels/train/')
image_txt_copy(val_name_list, labelme_path, './VOC/images/val/', './VOC/labels/val/')
image_txt_copy(test_name_list, labelme_path, './VOC/images/test/', './VOC/labels/test/')
Ideas :
First step Use train_test_split Methods cut out the training set 、 Validation set and test set .
The second step call change_2_yolo5 Methods will json The data in it turns into yolov5 Format txt data , Return to the training set 、 Pictures of validation set and test set list.
The third step Create dataset folder , Then put the picture and txt file copy Go to the corresponding directory .
The structure of the data set is shown in the figure below :
Yolodata_demo
└─VOC
├─images
│ ├─test
│ ├─train
│ └─val
└─labels
├─test
├─train
└─val
Training
With the data set, you can start training . download yolov6 Code for , Unzip it to the specified location , Then copy the data set to yolov6 Root directory . Here's the picture :
open requirements.txt, Check which libraries are missing in the local environment , Then install .
torch>=1.8.0
torchvision>=0.9.0
numpy>=1.18.5
opencv-python>=4.1.2
PyYAML>=5.3.1
scipy>=1.4.1
tqdm>=4.41.0
addict>=2.4.0
tensorboard>=2.7.0
pycocotools>=2.0
onnx>=1.10.0 # ONNX export
onnx-simplifier>=0.3.6 # ONNX simplifier
thop # FLOPs computation
stay tools New under the folder __init__.py, There is nothing in it .
Because it is quoted elsewhere tools The documents inside , If this script is not added, an error will be reported .
modify yaml file
open data/dataset.yaml, Here's the picture :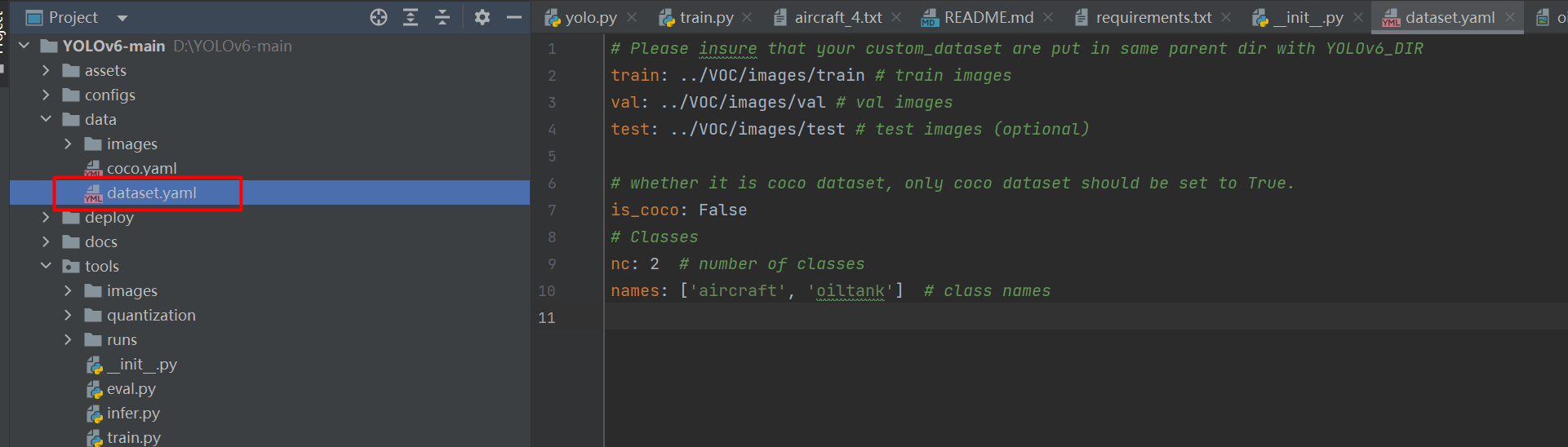
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR
train: ../VOC/images/train # train images
val: ../VOC/images/val # val images
test: ../VOC/images/test # test images (optional)
# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False
# Classes
nc: 2 # number of classes
names: ['aircraft', 'oiltank'] # class names
train、val、test: representative image route .
If we use the command python tools/train.py Training , Then set the directory to :
train: ./VOC/images/train # train images
val: ./VOC/images/val # val images
test: ./VOC/images/test # test images (optional)
If in tools Use... In the directory python train.py Or directly run, Then set the directory to :
train: ../VOC/images/train # train images
val: ../VOC/images/val # val images
test: ../VOC/images/test # test images (optional)
Pay attention to this detail , Different directories to start , The corresponding paths are also different .
modify train.py
def get_args_parser(add_help=True):
parser = argparse.ArgumentParser(description='YOLOv6 PyTorch Training', add_help=add_help)
parser.add_argument('--data-path', default='../data/dataset.yaml', type=str, help='path of dataset')
parser.add_argument('--conf-file', default='../configs/yolov6s.py', type=str, help='experiments description file')
parser.add_argument('--img-size', default=640, type=int, help='train, val image size (pixels)')
parser.add_argument('--batch-size', default=16, type=int, help='total batch size for all GPUs')
parser.add_argument('--epochs', default=400, type=int, help='number of total epochs to run')
parser.add_argument('--workers', default=0, type=int, help='number of data loading workers (default: 8)')
parser.add_argument('--device', default='0', type=str, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--eval-interval', default=20, type=int, help='evaluate at every interval epochs')
parser.add_argument('--eval-final-only', action='store_true', help='only evaluate at the final epoch')
parser.add_argument('--heavy-eval-range', default=50, type=int,
help='evaluating every epoch for last such epochs (can be jointly used with --eval-interval)')
data-path: The path to the dataset configuration file .
conf-file: Path to the model configuration file .
img-size: Enter the size of the picture , The picture resize This dimension is input into the model .yolo Generally, the size of the model of the series is 32 Multiple .
batch-size:BatchSize Size . According to the video memory settings of the graphics card , Generally, you can fill the video memory .
epochs:epoch Size .
workers:cpu Setting of audit number , stay win System set to 0.
workers: Interval between verifications .
Then you can start training , I run directly here train.py Script .
Due to the small amount of data set , You can finish it soon .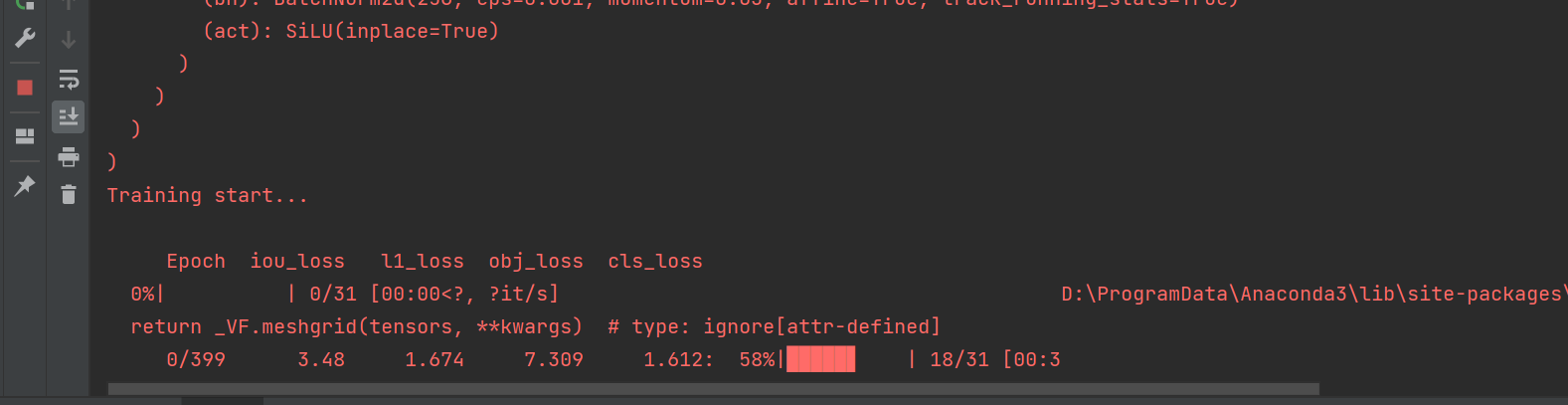
test
After the training, you can start the test . After the training, we are tools/runs find weights, choose best_ckpt.pt.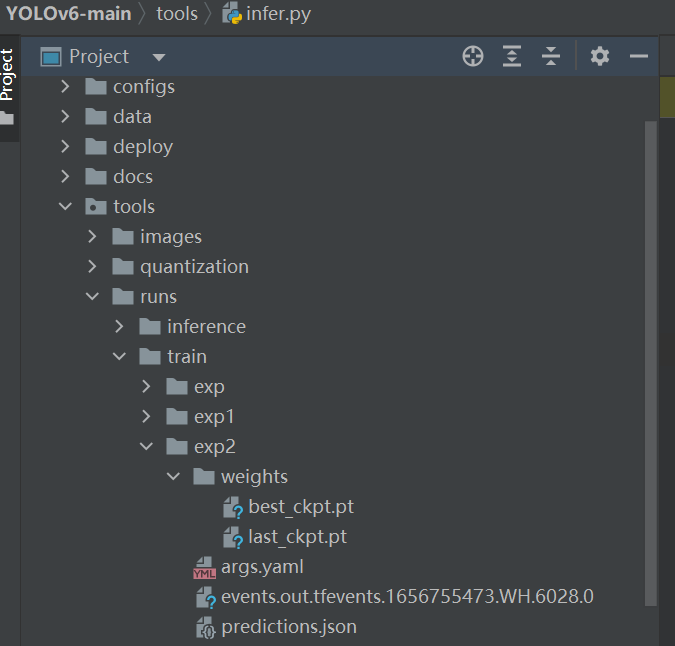
open tools/infer.py, Modify the parameters :
def get_args_parser(add_help=True):
parser = argparse.ArgumentParser(description='YOLOv6 PyTorch Inference.', add_help=add_help)
parser.add_argument('--weights', type=str, default='runs/train/exp2/weights/best_ckpt.pt', help='model path(s) for inference.')
parser.add_argument('--source', type=str, default='images', help='the source path, e.g. image-file/dir.')
parser.add_argument('--yaml', type=str, default='../data/dataset.yaml', help='data yaml file.')
parser.add_argument('--img-size', type=int, default=640, help='the image-size(h,w) in inference size.')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold for inference.')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold for inference.')
parser.add_argument('--max-det', type=int, default=1000, help='maximal
weights: The path of training weight .
source: Test the path of the picture , I put the test pictures here tools/images Under the folder .
img-size: Keep consistent with the training pictures .
conf-thres: The minimum value of confidence .
iou-thres:IoU Value .
max-det: The target detected in a single image cannot exceed this value .
function inter.py test images Picture in .
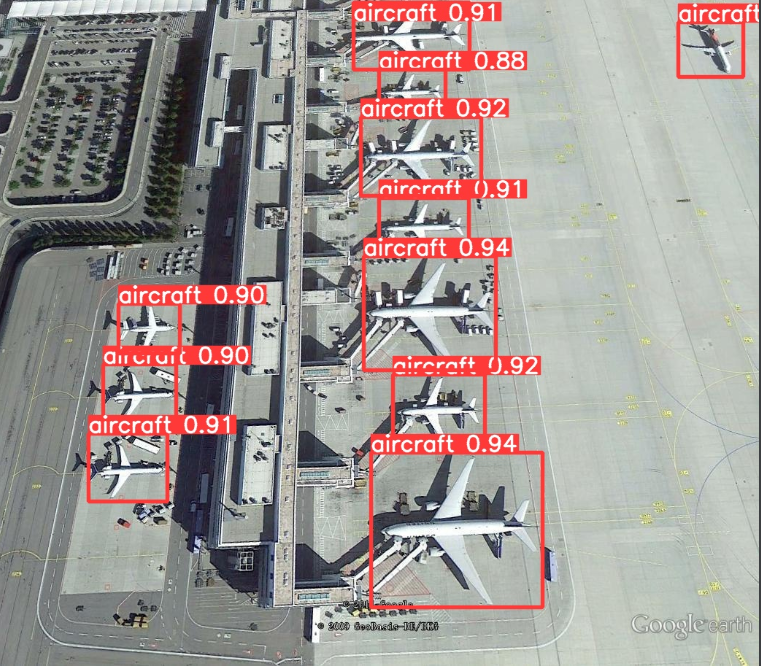

The effect is really good !!!
Complete code
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/85881120?spm=1001.2014.3001.5503
边栏推荐
- 更优雅地远程操作服务器:Paramiko库的实践
- 1. Mx6u-alpha development board (LED drive experiment in C language version)
- Distributed cap theory
- [wechat applet] good looking carousel map component
- 附件四:攻击方评分标准.docx
- Graduation project
- 郑州正清园文化传播有限公司:针对小企业的7种营销技巧
- 牛客小白月赛49
- Modstartblog modern personal blog system v5.2.0 source code download
- Kivy教程之 格式化文本 (教程含源码)
猜你喜欢

Beipiao programmer, 20K monthly salary, 15W a year, normal?

The "functional art" jointly created by Bolang and Virgil abloh in 2021 to commemorate the 100th anniversary of Bolang brand will debut during the exhibition of abloh's works in the museum
Niuke Xiaobai monthly race 49

Statistical genetics: Chapter 3, population genetics

Annex VI: defense work briefing docx

MySQL JDBC编程

Create ASM disk through DD
RPC - gRPC简单的demo - 学习/实践
最长递增子序列问题(你真的会了吗)

疫情远程办公经验分享| 社区征文
随机推荐
A beautiful API document generation tool
Redis: order collection Zset type data operation command
MySQL JDBC programming
Drozer tool
y55.第三章 Kubernetes从入门到精通 -- HPA控制器及metrics-server(二八)
Graduation project
LeetCode136+128+152+148
[cloud native] those lines of code that look awesome but have a very simple principle
Correct the classpath of your application so that it contains a single, compatible version of com. go
EventBridge 在 SaaS 企业集成领域的探索与实践
B. All Distinct
What should a novice pay attention to when looking for an escort
DCDC电源电流定义
Cmake compilation option setting in ros2
Exploration and practice of eventbridge in the field of SaaS enterprise integration
网络设备应急响应指南
Niuke Xiaobai monthly race 49
【Go】数据库框架gorm
在代码中使用度量单位,从而生活更美好
Rhcsa 08 - automount configuration