当前位置:网站首页>sqoop ETL tool
sqoop ETL tool
2022-08-04 02:35:00 【boy picking up gold】
目录
6、MySQLImport of incremental data toHDFS中
The first incremental import is implemented using the options above
第二种、Incremental import passed--where条件来实现
概述
- Sqoop是apache旗下的一款 ”Hadoop和关系数据库之间传输数据”的工具
导入数据:将MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统
导出数据:从Hadoop的文件系统中导出数据到关系数据库(mysql中)
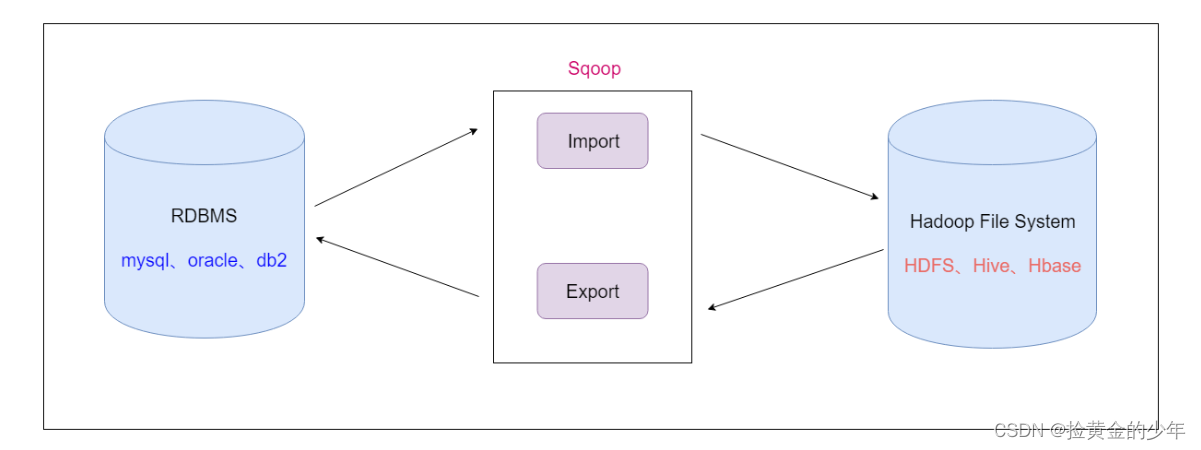
1、sqoop的安装
1、上传并解压
Upload the downloaded installation package to ==node03==服务器的/kkb/soft路径下,然后进行解压
cd /kkb/soft/
tar -zxf sqoop-1.4.6-cdh5.14.2.tar.gz -C /kkb/install/
2、修改配置文件
更改sqoop的配置文件
cd /kkb/install/sqoop-1.4.6-cdh5.14.2/conf
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2#set the path to where bin/hbase is available
export HBASE_HOME=/kkb/install/hbase-1.2.0-cdh5.14.2#Set the path to where bin/hive is available
export HIVE_HOME=/kkb/install/hive-1.1.0-cdh5.14.2
3、sqoopTwo additional dependencies are requiredjar包,Put two of the datajar包添加到sqoop的lib目录下

4、配置sqoop的环境变量
sudo vim /etc/profile
export SQOOP_HOME=/kkb/install/sqoop-1.4.6-cdh5.14.2
export PATH=:$SQOOP_HOME/bin:$PATH
source /etc/profile
5、Because to be involvedhive数据导入导出,所以要引入hive的lib下面的包
将我们mysql表当中的数据直接导入到hive表中的话,我们需要将hive的一个叫做hive-exec-1.1.0-cdh5.14.0.jar的jar包拷贝到sqoop的lib目录下
cp /kkb/install/hive-1.1.0-cdh5.14.2/lib/hive-exec-1.1.0-cdh5.14.2.jar /kkb/install/sqoop-1.4.6-cdh5.14.2/lib/
cp /kkb/install/hive-1.1.0-cdh5.14.2/lib/hive-shims* /kkb/install/sqoop-1.4.6-cdh5.14.2/lib/
2、sqoop的使用
1、查看sqoop帮助文档
sqoop list-databases --help
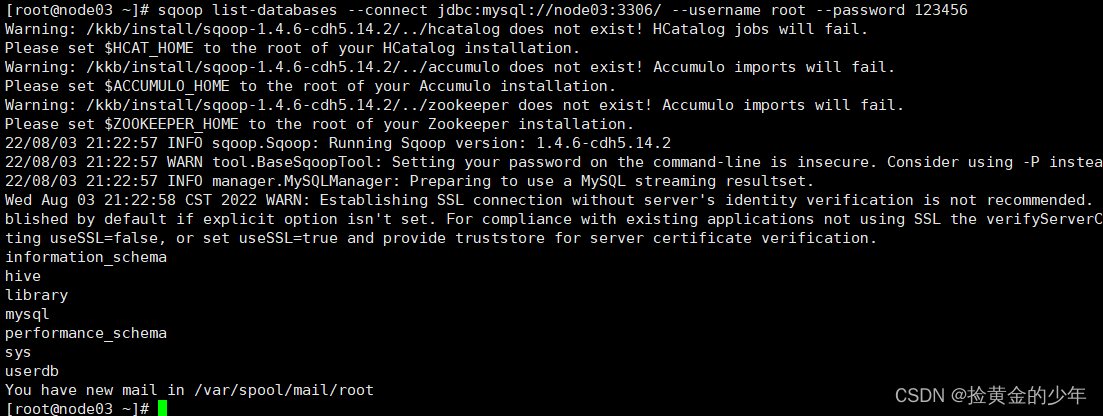
2、查看MySQL中所有的数据库
sqoop list-databases --connect jdbc:mysql://node03:3306/ --username root --password 123456
3、查看hiveAll tables below the database
sqoop list-tables --connect jdbc:mysql://node03:3306/hive --username root --password 123456
准备表数据
在mysql中有一个库userdb中三个表:emp, emp_add和emp_conn
表emp:
| id | name | deg | salary | dept |
|---|---|---|---|---|
| 1201 | gopal | manager | 50,000 | TP |
| 1202 | manisha | Proof reader | 50,000 | TP |
| 1203 | khalil | php dev | 30,000 | AC |
| 1204 | prasanth | php dev | 30,000 | AC |
| 1205 | kranthi | admin | 20,000 | TP |
表emp_add:
| id | hno | street | city |
|---|---|---|---|
| 1201 | 288A | vgiri | jublee |
| 1202 | 108I | aoc | sec-bad |
| 1203 | 144Z | pgutta | hyd |
| 1204 | 78B | old city | sec-bad |
| 1205 | 720X | hitec | sec-bad |
表emp_conn:
| id | phno | |
|---|---|---|
| 1201 | 2356742 | [email protected] |
| 1202 | 1661663 | [email protected] |
| 1203 | 8887776 | [email protected] |
| 1204 | 9988774 | [email protected] |
| 1205 | 1231231 | [email protected] |
建表,And the statement to insert data is as follows:
CREATE DATABASE /*!32312 IF NOT EXISTS*/`userdb` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `userdb`;
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` INT(11) DEFAULT NULL,
`name` VARCHAR(100) DEFAULT NULL,
`deg` VARCHAR(100) DEFAULT NULL,
`salary` INT(11) DEFAULT NULL,
`dept` VARCHAR(10) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;INSERT INTO `emp`(`id`,`name`,`deg`,`salary`,`dept`) VALUES (1201,'gopal','manager',50000,'TP'),(1202,'manisha','Proof reader',50000,'TP'),(1203,'khalil','php dev',30000,'AC'),(1204,'prasanth','php dev',30000,'AC'),(1205,'kranthi','admin',20000,'TP');
DROP TABLE IF EXISTS `emp_add`;
CREATE TABLE `emp_add` (
`id` INT(11) DEFAULT NULL,
`hno` VARCHAR(100) DEFAULT NULL,
`street` VARCHAR(100) DEFAULT NULL,
`city` VARCHAR(100) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;INSERT INTO `emp_add`(`id`,`hno`,`street`,`city`) VALUES (1201,'288A','vgiri','jublee'),(1202,'108I','aoc','sec-bad'),(1203,'144Z','pgutta','hyd'),(1204,'78B','old city','sec-bad'),(1205,'720X','hitec','sec-bad');
DROP TABLE IF EXISTS `emp_conn`;
CREATE TABLE `emp_conn` (
`id` INT(100) DEFAULT NULL,
`phno` VARCHAR(100) DEFAULT NULL,
`email` VARCHAR(100) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;INSERT INTO `emp_conn`(`id`,`phno`,`email`) VALUES (1201,'2356742','[email protected]'),(1202,'1661663','[email protected]'),(1203,'8887776','[email protected]'),(1204,'9988774','[email protected]'),(1205,'1231231','[email protected]');
3、MySQL数据导入到HDFS中
1、不指定HDFS目录导入
使用sqoop命令导入、before exporting data,要先启动hadoop集群
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS.
sqoop import --connect jdbc:mysql://node03:3306/userdb --password 123456 --username root --table emp --m 1
hdfs dfs -ls /user/root/emp
2、指定HDFS目录导入
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录.
使用参数 --target-dir来指定导出目的地,
使用参数--delete-target-dir来判断导出目录是否存在,如果存在就删掉
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --delete-target-dir --table emp --target-dir /sqoop/emp --m 1
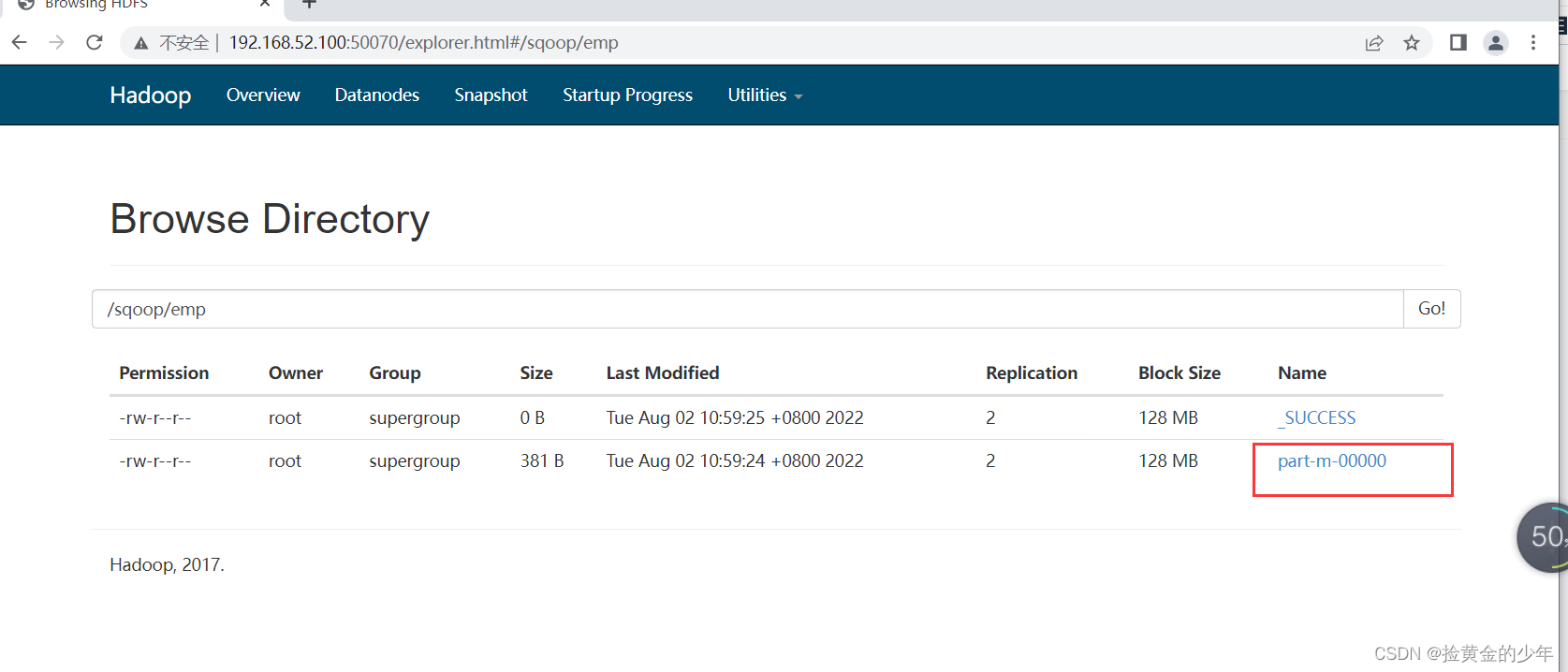
查看数据
hdfs dfs -text /sqoop/emp/part-m-00000

它会用逗号(,)分隔emp_add表的数据和字段.
3、导入到HDFS指定目录,并指定字段之间的分隔符
指定分隔符
--fields-terminated-by '\t'
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --delete-target-dir --table emp --target-dir /sqoop/emp2 --m 1 --fields-terminated-by '\t'
查看导出的数据
hdfs dfs -text /sqoop/emp2/part-m-00000

4、--where,通过条件过滤MySQL,再导入hdfs
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集.它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录.
where子句的语法如下.
--where <condition>
按照条件进行查找,通过--where参数来查找表emp_add当中city字段的值为sec-bad的所有数据导入到hdfs上面去
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root --password 123456 --table emp_add \
--target-dir /sqoop/emp_add -m 1 --delete-target-dir \
--where "city = 'sec-bad'"
查看导出的数据
hdfs dfs -text /sqoop/emp_add/part-m-00000


5、通过SQLfilter import toHDFS中
我们还可以通过 –query参数来指定我们的sql语句,通过sql语句来过滤我们的数据进行导入
sqoop import \
--connect jdbc:mysql://node03:3306/userdb --username root --password 123456 \
--delete-target-dir -m 1 \
--query 'select phno from emp_conn where 1=1 and $CONDITIONS' \
--target-dir /sqoop/emp_conn
hdfs dfs -text /sqoop/emp_conn/part*
注意:
使用sql语句来进行查找是不能加参数--table
并且必须要添加where条件,
并且where条件后面必须带一个$CONDITIONS 这个字符串,
并且这个sql语句必须用单引号,不能用双引号
6、MySQLImport of incremental data toHDFS中
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,It is not necessary to import all the data in the table tohive或者hdfs当中去,There will definitely be duplicate data situations,Therefore, we generally choose some fields for incremental import,To support incremental imports,sqoopIt also takes us into account and supports incremental import data
增量导入是仅导入新添加的表中的行的技术.
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入.
下面的语法用于Sqoop导入命令增量选项.
--incremental <mode>
--check-column <column name>
--last value <last check column value>
The first incremental import is implemented using the options above
导入emp表当中id大于1202的所有数据
注意:增量导入的时候,一定不能加参数--delete-target-dir否则会报错
sqoop import \ --connect jdbc:mysql://node03:3306/userdb \ --username root \ --password 123456 \ --table emp \ --incremental append \ --check-column id \ --last-value 1202 \ -m 1 \ --target-dir /sqoop/increment
查看数据内容
hdfs dfs -text /sqoop/increment/part*

第二种、Incremental import passed--where条件来实现
或者我们使用--whereThe selection of control data will be more precise
sqoop import \ --connect jdbc:mysql://node03:3306/userdb \ --username root \ --password 123456 \ --table emp \ --incremental append \ --where "create_time > '2018-06-17 00:00:00' and is_delete='1' and create_time < '2018-06-17 23:59:59'" \ --target-dir /sqoop/incement4\ --check-column id \ --m 1
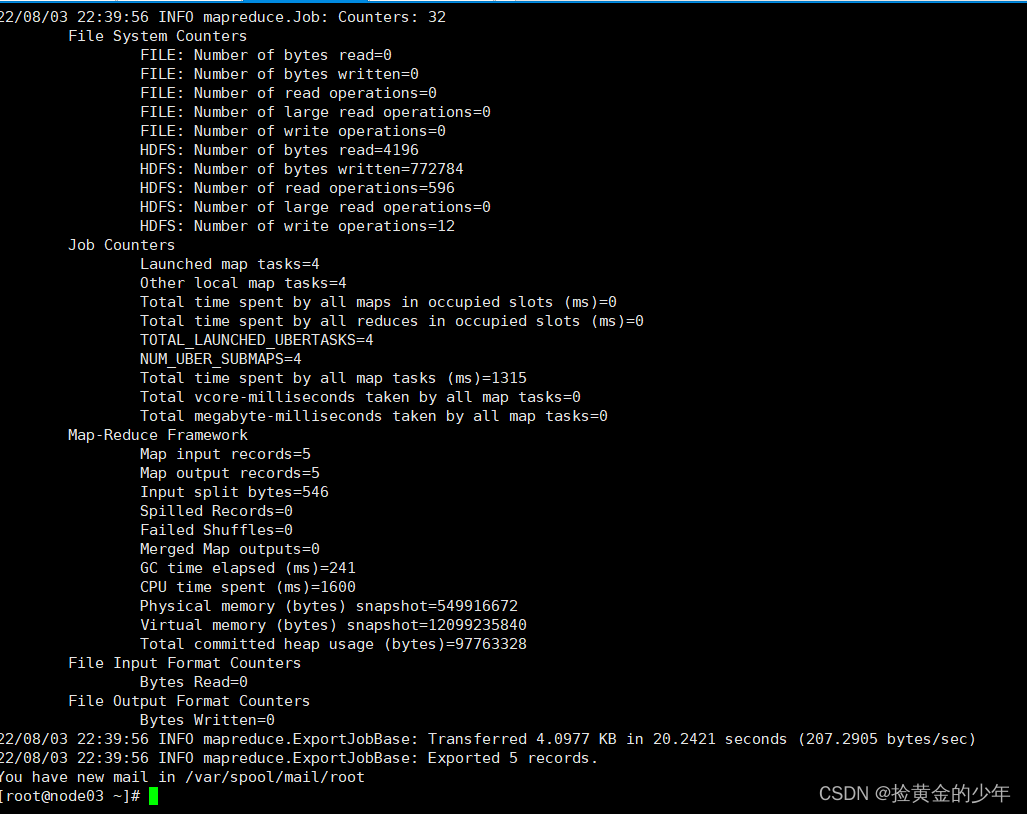
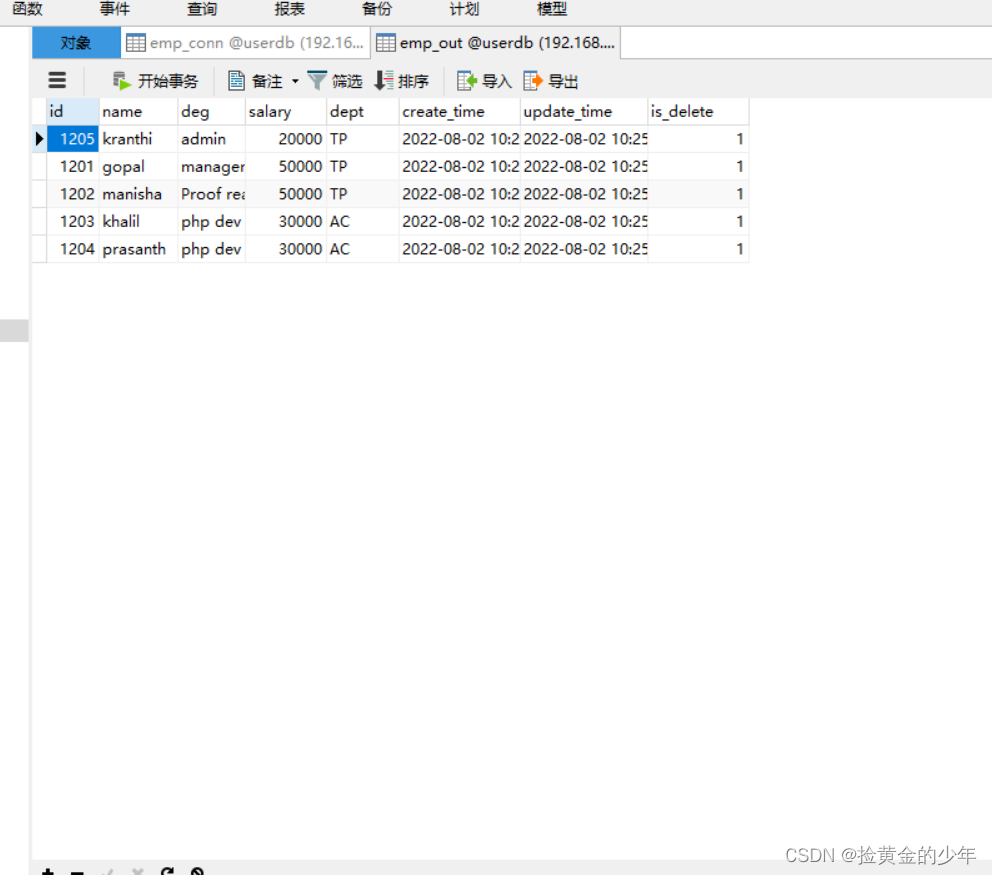
7、HDFS中数据导入到MYSQL中
sqoop export 为导出 导出到MySQL
sqoop import为导入,MySQL中导入
sqoop export \
--connect jdbc:mysql://node03:3306/userdb \
--username root --password 123456 \
--table emp_out \
--export-dir /sqoop/emp \
--input-fields-terminated-by ","
导入前
 导入后
导入后
4、MySQL数据导入到hive中
1、导入到hive指定表(自己建表)
1、在hive中创建一个emp_hive表,
hive (default)> create database sqooptohive;
hive (default)> use sqooptohive;
hive (sqooptohive)> create external table emp_hive(id int,name string,deg string,salary int ,dept string) row format delimited fields terminated by '\001';
2、MySQL导出数据到emp_hive表中
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --fields-terminated-by '\001' --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite --delete-target-dir --m 1
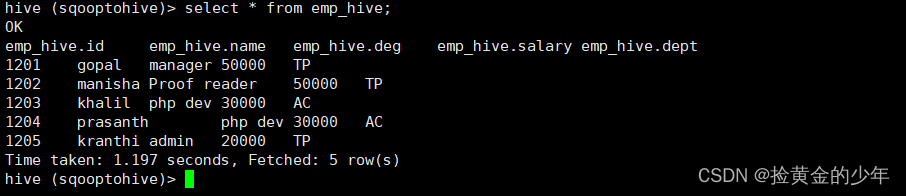
3、在hive中查看数据
select * from emp_hive;
2、hive不创建表,sqoop自动创建
但是要指定hive数据库,This automatically creates the table,hiveCreate with the table name and MySQL的一致
--hive-database sqooptohive;
完整语句如下
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp_conn --hive-import -m 1 --hive-database sqooptohive;
5、MySQL中的数据导入到hbase中
1、MySQL中的数据导入到hbase
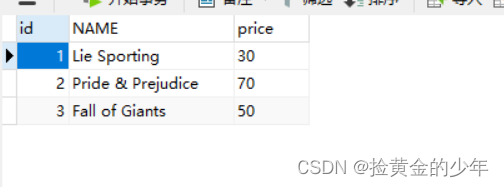
1、MySQLCreate display data in
CREATE DATABASE IF NOT EXISTS library;
USE library;
CREATE TABLE book(
id INT(4) PRIMARY KEY NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
price VARCHAR(255) NOT NULL);
INSERT INTO book(NAME, price) VALUES('Lie Sporting', '30');
INSERT INTO book (NAME, price) VALUES('Pride & Prejudice', '70');
INSERT INTO book (NAME, price) VALUES('Fall of Giants', '50');
2、执行以下命令,将mysqlThe data in the table is imported intoHBase当中去
指定hbase中的行键rowkey,列族column-family等
sqoop import \
--connect jdbc:mysql://node03:3306/library \
--username root \
--password 123456 \
--table book \
--columns "id,name,price" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_book" \
--num-mappers 1 \
--split-by id
scan 'hbase_book'

2、hbase中的数据导出到MySQL
sqoopWe will not support directlyHBasedata export,So we can export through the following transformation
Hbase→hive外部表→hive内部表→通过sqoop→mysql逻辑,
1、创建外部hive表与hbase映射
2、创建hive内部表,Import the build external table tohive内部表
3、Export the data of the internal table toMySQL中
先将MySQL中的bookThe table is emptied for backup
use library;
TRUNCATE TABLE book;
进入hive客户端,创建hive外部表,映射hbase当中的hbase_book表
CREATE EXTERNAL TABLE course.hbase2mysql (id int,name string,price int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" =
":key,info:name, info:price"
)
TBLPROPERTIES( "hbase.table.name" = "hbase_book",
"hbase.mapred.output.outputtable" = "hbase2mysql");
进入hive客户端,执行以下命令,创建hive内部表,and insert data from the external table intohivefrom the internal table
CREATE TABLE course.hbase2mysqlin(id int,name string,price int);
insert overwrite table course.hbase2mysqlin select * from course.hbase2mysql;
将hive中的数据导入到MySQL中
sqoop export --connect jdbc:mysql://node03:3306/library --username root --password 123456 --table book --export-dir /user/hive/warehouse/course.db/hbase2mysqlin --input-fields-terminated-by '\001' --input-null-string '\\N' --input-null-non-string '\\N';
边栏推荐
- Intranet penetration - application
- In a more general sense, calculating the displacement distance and assumptions
- 云开发旅游打卡广场微信小程序源码(含视频教程)
- 【学习笔记之菜Dog学C】动态内存管理
- v-model
- 2022焊工(初级)上岗证题目模拟考试平台操作
- Kubernetes:(十一)KubeSphere的介绍和安装(华丽的篇章)
- Dong mingzhu live cold face away, when employees frequency low-level mistakes, no one can understand their products
- C语言--环形缓存区
- flinkcdc 消费 mysql binlog 没有 sqltype=delete 的数据是什么原
猜你喜欢

随机推荐
Example 040: Reverse List
(cf)Codeforces Round #811 (Div. 3)A--E详细题解
esp32 releases robot battery voltage to ros2 (micro-ros+CoCube)
0.1 前言
Flink原理流程图简单记录
The idea of the diagram
一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
C program compilation and predefined detailed explanation
实例038:矩阵对角线之和
Example 041: Methods and variables of a class
Presto中broadcast join和partition join执行计划的处理过程
flask框架初学-06-对数据库的增删改查
返回字符串中的最大回文数
Big guys, it takes a long time to read mysql3 million single tables, what parameters can be discounted, or is there any way to hurry up
2022.8.3-----leetcode.899
2022.8.3-----leetcode.899
【Playwright测试教程】5分钟上手
DHCP服务详解
Taurus.MVC WebAPI 入门开发教程1:框架下载环境配置与运行(含系列目录)。
第08章 索引的创建与设计原则【2.索引及调优篇】【MySQL高级】