当前位置:网站首页>Spark RDD案例:统计每日新增用户
Spark RDD案例:统计每日新增用户
2022-06-29 06:38:00 【Yushijuj】
文章目录
一、提出任务
有以下用户访问历史数据,第一列为用户访问网站的日期,第二列为用户名:
2022-02-07,Mike
2022-02-07,Alice
2022-02-27,Brown
2022-04-02,Mike
2022-04-02,Alice
2022-04-02,Green
2022-07-12,Alice
2022-07-12,Smith
2022-07-12,Brian

通过上述数据统计每日新增的用户数量,得到以下统计结果:
2022-02-07新增了3个用户(分别为mike、alice、brown)
2022-04-02新增了1个用户(green)
2022-07-12新增了2个用户(分别为smith、brian)
二、实现思路
使用倒排索引法,如果同一个用户对应多个访问日期,则最小的日期为该用户的注册日期,即新增日期,其他日期为重复访问日期,不应统计在内。因此每个用户应该只计算用户访问的最小日期即可。如下图所示,将每个用户访问的最小日期都移到第一列,第一列为有效数据,只统计第一列中每个日期的出现次数,即为对应日期的新增用户数。

- 启动集群的HDFS与Spark

- 在HDFS上准备数据 - users.txt
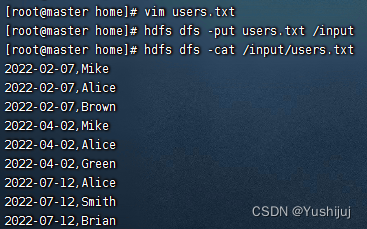
三、完成任务
(一)读取文件,得到RDD
val rdd1 = sc.textFile("hdfs://master:9000/input/users.txt")

(二)倒排,互换RDD中元组的元素顺序
val rdd2 = rdd1.map(
line => {
val fields = line.split(",")
(fields(1), fields(0))
}
)

(三)倒排后的RDD按键分组
val rdd3 = rdd2.groupByKey()

(四)取分组后的日期集合最小值,计数为1
val rdd4 = rdd3.map(line => (line._2.min, 1))

(五)按键计数,得到每日新增用户数
val result = rdd4.countByKey()
result.keys.foreach(key => println(key + "," + result(key)))

四、完成任务
(一)新建Maven项目 – CountNewUsers


将JAVA 目录改为scala

(二)添加相关依赖和构建插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.cb.rdd</groupId>
<artifactId>CountNewUsers</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 并刷新下载依赖

(三)创建日志属性文件
- 在资源文件夹里创建日志属性文件 - log4j.properties
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n

(四)创建计算平均分单例对象
- 在net.cb.sql包里创建CountNewUsersBySQL单例对象
package net.cb.rdd
import org.apache.spark.{
SparkConf, SparkContext}
/** * 功能: 统计每日新增用户 * 作者: 陈标 * 时间: 2022年06月18日 */
object CountNewUsersBySQL {
def main(args: Array[String]): Unit = {
// 创建Spark conf容器
val spark: SparkConf = new SparkConf()
.setAppName("CalculusAverageByRDD")
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(spark)
val lines = sc.textFile("hdfs://master:9000/input/users.txt")
//lines.collect.foreach(println)
//互换RDD中的元素顺序
val value = lines.map(
line =>{
val fields = line.split(",")
val name = fields(1)
val time = fields(0)
(name,time)
}
)
// 对姓名分组
val nameGB = value.groupByKey().map(
line => {
val time = line._2.min
val name = line._1
(time,name)
}
)
// 按键计数,得到每日新增数
val CB = nameGB.countByKey()
CB.keys.foreach(key => println(key + "," + CB(key)))
// 关闭容器
sc.stop()
}
}
(五)本地运行程序,查看结果

边栏推荐
- Mongostat performance analysis
- What is the difference between software engineer and software development? What is the difference between software engineer and software developer?
- Configuring MySQL 5.7 and 8 under CentOS
- Li Kou daily question - day 30 -1281 Difference of sum of bit product of integer
- Redis (V) of NoSQL database: redis_ Jedis_ test
- idea使用
- Multithreading tool class completabilefuture
- How to fix Error: Failed to download metadata for repo ‘appstream‘: Cannot prepare internal mirrorli
- jetson tx2
- 开源二三事|ShardingSphere 与 Database Mesh 之间不得不说的那些事
猜你喜欢
![[C language] flexible array](/img/22/3255740602232abfdf69624762adca.jpg)
[C language] flexible array

jetson tx2

Li Kou today's question -324 Swing sort II

施工企业选择智慧工地的有效方法
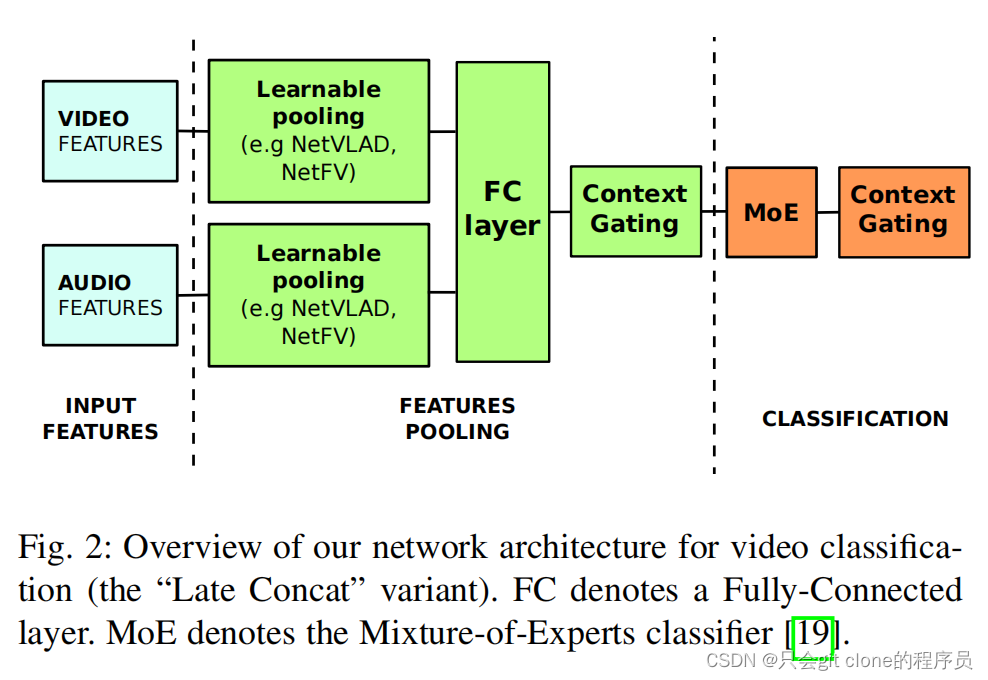
Multimodal learning pooling with context gating for video classification

Uniapp obtains the date implementation of the beginning and end of the previous month and the next month

RPC and RMI

开源二三事|ShardingSphere 与 Database Mesh 之间不得不说的那些事
Qt QLineEdit详解
About DDNS
随机推荐
Open source 23 things shardingsphere and database mesh have to say
Multimodal learning pooling with context gating for video classification
大型化工企业数字化转型建议
GenICam GenTL 标准 ver1.5(3)第四章
About DDNS
Qt QFrame详解
Some thoughts on port forwarding program
把多个ROC曲线画在一张图上
Suggestions on digital transformation of large chemical enterprises
Why should enterprises do more application activities?
Qt foreach关键字
NoSQL數據庫之Redis(五):Redis_Jedis_測試
[translation] [Chapter 2 ②] mindshare PCI Express technology 3.0
Annual inventory review of Alibaba cloud's observable practices in 2021
Vite快速上手
C language pointer to function
Save token get token refresh token send header header
UVM authentication platform
The annual technology inventory of cloud primitives was released, and it was the right time to ride the wind and waves
. NETCORE uses redis to limit the number of interface accesses