当前位置:网站首页>主成分分析(PCA)
主成分分析(PCA)
2022-08-02 20:38:00 【梁小憨憨】
最近看共空间分析(CSP)算法,用到了PCA,就在这里整理一下,以下内容来自大佬视频和文章:用最直观的方式告诉你:什么是主成分分析PCA, https://gitee.com/ni1o1/pygeo-tutorial/blob/master/12-.ipynb。
主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA)是一种多变量统计方法,它是最常用的降维方法之一,通过正交变换将一组可能存在相关性的变量数据转换为一组线性不相关的变量,转换后的变量被称为主成分。
可以使用两种方法进行 PCA,分别是特征分解或奇异值分解(SVD)。
先从协方差说起
在这篇文章中也有相关介绍,如有兴趣请跳转:【协方差】【相关系数】【协方差矩阵】【散度矩阵】
协方差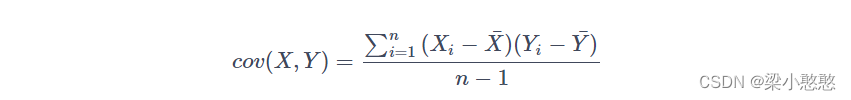
协方差其意义: 度量各个维度偏离其均值的程度。协方差的值如果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),结果为负值就说明负相关的,如果为0,也是就是统计上说的“相互独立”。
协方差矩阵: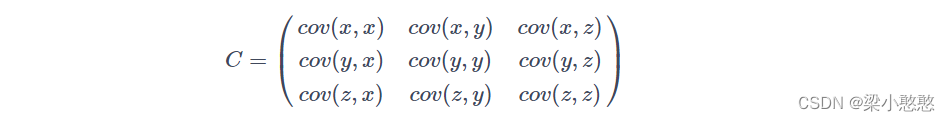
从协方差矩阵上,可以得到变量之间两两的相关性
import numpy as np
#设置一下np的输出格式
np.set_printoptions(threshold=100,precision= 4,suppress=True)
# 计算以下数据的协方差矩阵
np.random.seed(0)
data = np.random.uniform(1,10,(10,2))
# print(data)
data[:,1:] = 0.5*data[:,0:1]+np.random.uniform(-2,2,(10,1))
# print(data)
# 去中心化
data_norm = data-data.mean(axis = 0)
# print(data_norm)
X = data_norm[:,0]
Y = data_norm[:,1]
# print(X,Y)
# 定义一个函数,输入X,Y能得到X,Y之间的协方差
def getcov(X,Y):
covxy = ((X-X.mean())*(Y-Y.mean())).sum()/(len(X)-1)
return covxy
# print(getcov(X,X))
7.332530886964573
numpy自带了协方差矩阵的计算方法,验证一下
# numpy自带了协方差矩阵的计算方法,验证一下
C = np.cov(data_norm.T)
print(C)
[[7.3325 2.2168]
[2.2168 1.8633]]
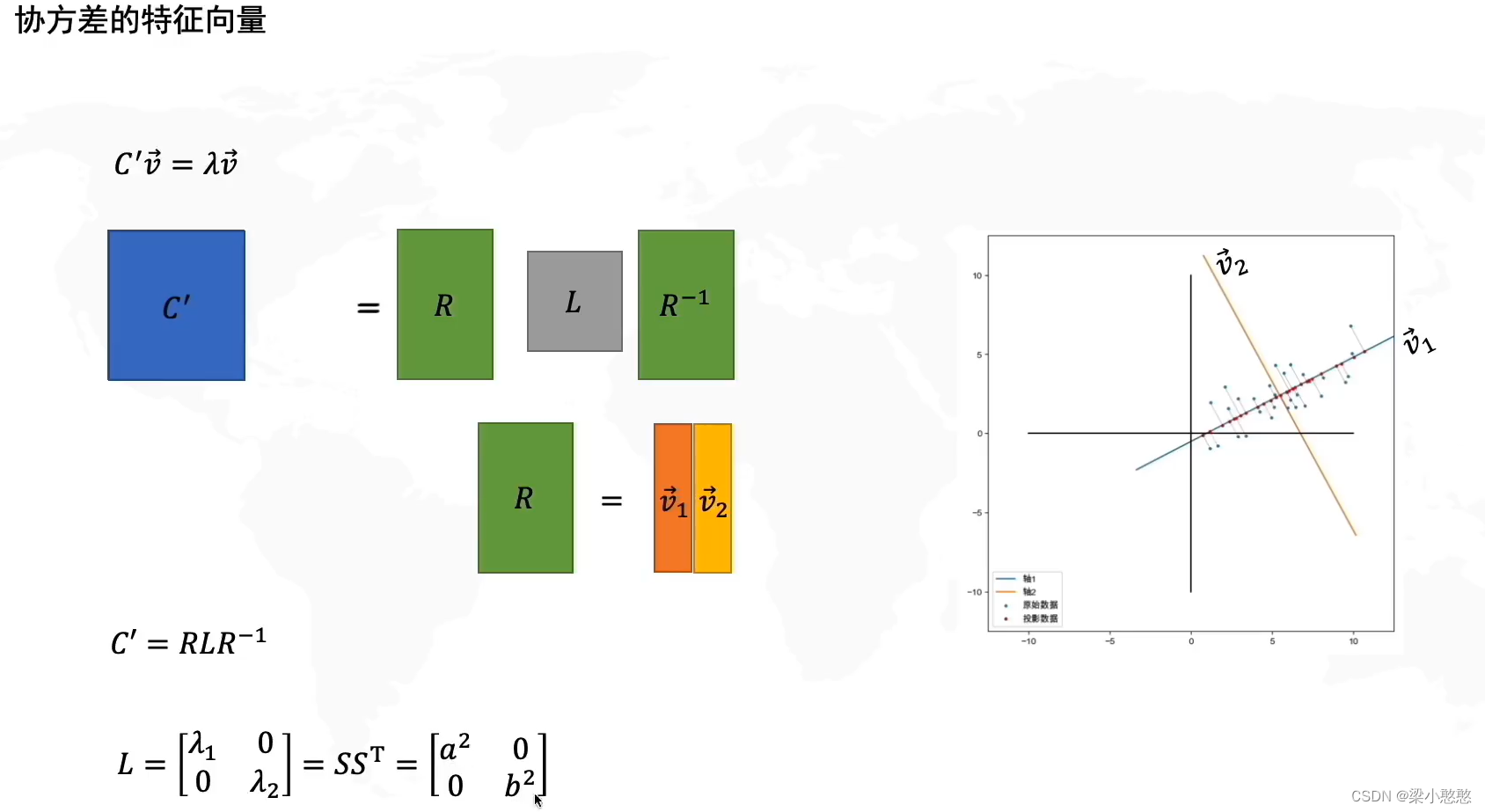
计算协方差矩阵的特征向量和特征值
由矩阵特征值特征向量的定义: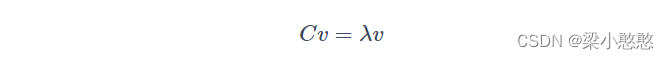
其中, λ λ λ是特征向量 v v v对应的特征值,一个矩阵的一组特征向量是一组正交向量。
特征值分解矩阵
对于矩阵 C C C,有一组特征向量 V V V,将这组向量进行正交化单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵 C C C分解为如下式: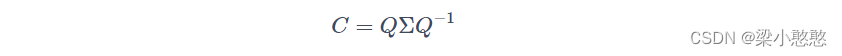
其中, Q Q Q是矩阵 C C C的特征向量组成的矩阵, Σ Σ Σ则是一个对角阵,对角线上的元素就是特征值。
#计算特征值和特征向量
vals, vecs = np.linalg.eig(C)
# print(vals)
# print(vecs)
#重新排序,从大到小
vecs = vecs[:,np.argsort(-vals)]
vals = vals[np.argsort(-vals)]
print(vals)
print(vecs)
[8.1182 1.0777]
[[ 0.9426 -0.334 ]
[ 0.334 0.9426]]
这时候,相当于已经在数据中定义了两个轴,第一个轴的方向是第一个特征向量 v 1 v_1 v1,第二个轴的方向是第二个特征向量 v 2 v_2 v2
import matplotlib.pyplot as plt
#设置图大小
size = 15
plt.figure(1,(8,8))
plt.scatter(data[:,0],data[:,1],label='origin data')
i=0 #变换后的X轴
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size #按照绘制图形的大小进行缩放
ev = (ev+data.mean(0)) #将坐标系的原点放到数据的中心
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
i=1 #变换后的Y轴
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size #按照绘制图形的大小进行缩放
ev = (ev+data.mean(0)) #将坐标系的原点放到数据的中心
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
#画一下x轴y轴
plt.plot([-size,size],[0,0],c='black')
plt.plot([0,0],[-size,size],c='black')
plt.xlim(-size,size)
plt.ylim(-size,size)
plt.legend()
plt.show()
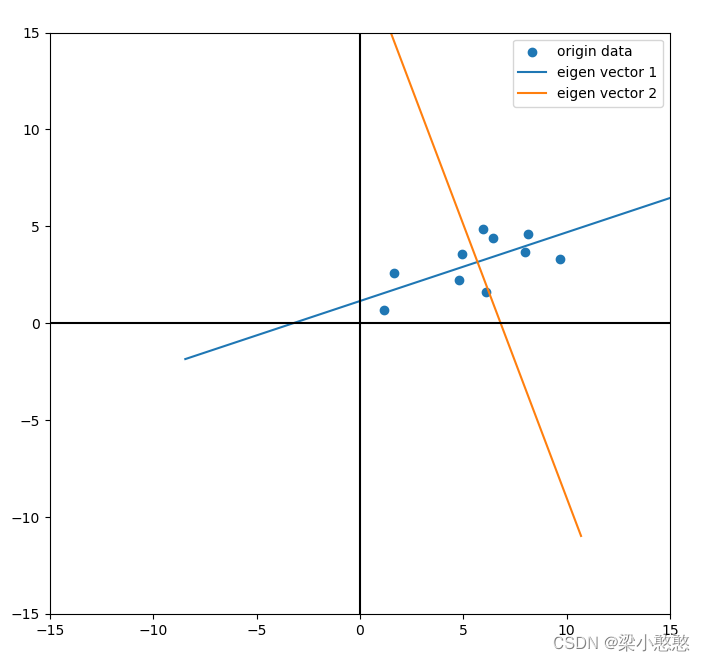
如果用PCA把m个维度的数据降维成k个维度,即只用前k个主成分来表示,那么数据在主成分上的投影坐标是
Y n k = X n m Q m ∗ k Y_{nk} = X_{nm}Q_{m*k} Ynk=XnmQm∗k Q Q Q为特征向量组成的矩阵
#数据在主成分1上的投影坐标是Y
k=1
Q = vecs[:,:k]
Y = np.matmul(data_norm,Q)
print(Y)
[ [-0.561 ]
[ 3.8076]
[ 2.7876]
[-0.1097]
[-4.0022]
[-5.0746]
[2.3511]]
这个时候我们相当于只需要存储前k个主成分的特征向量 Q m k Q_{mk} Qmk和数据在前k个主成分上的投影坐标 Y n k Y_{nk} Ynk,就可以还原数据 Y n k Q m k T = X n m Y_{nk}{Q_{mk}}^T=X_{nm} YnkQmkT=Xnm 其中,由于 Q Q Q已经正交化, Q m k T Q m k = I k k {Q_{mk}}^T{Q_{mk}}=I_{kk} QmkTQmk=Ikk
#得到去中心化的还原数据
X_ = np.matmul(Y,Q.T)
print(X_)
[[ 0.7676 0.272 ]
[ 1.0494 0.3719]
[-1.0618 -0.3763]
[-0.5288 -0.1874]
[ 3.5888 1.2719]
[ 2.6275 0.9312]
[-0.1034 -0.0366]
[-3.7723 -1.3369]
[-4.7831 -1.6952]
[ 2.216 0.7854]]
#加上均值,还原数据
data_ = np.matmul(Y,Q.T)+data.mean(0)
print(data_)
[[6.4527 3.4356]
[6.7345 3.5355]
[4.6233 2.7873]
[5.1563 2.9761]
[9.2739 4.4355]
[8.3125 4.0947]
[5.5817 3.1269]
[1.9128 1.8266]
[0.902 1.4684]
[7.9011 3.9489]]
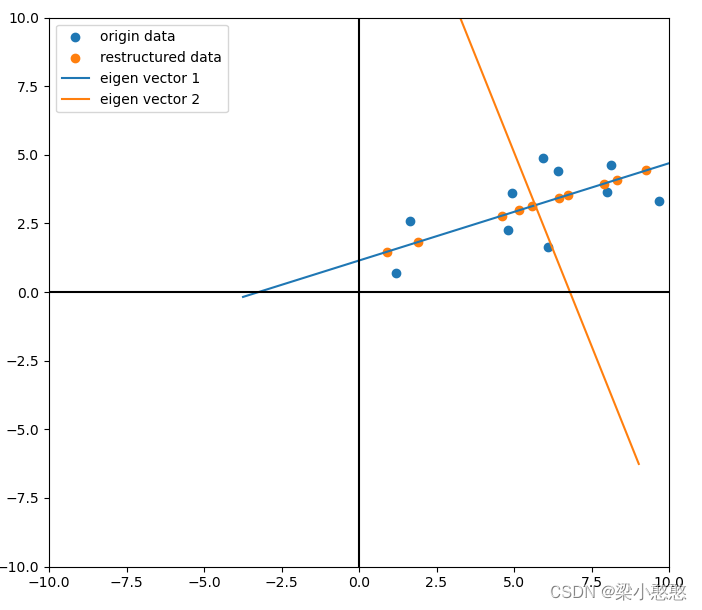
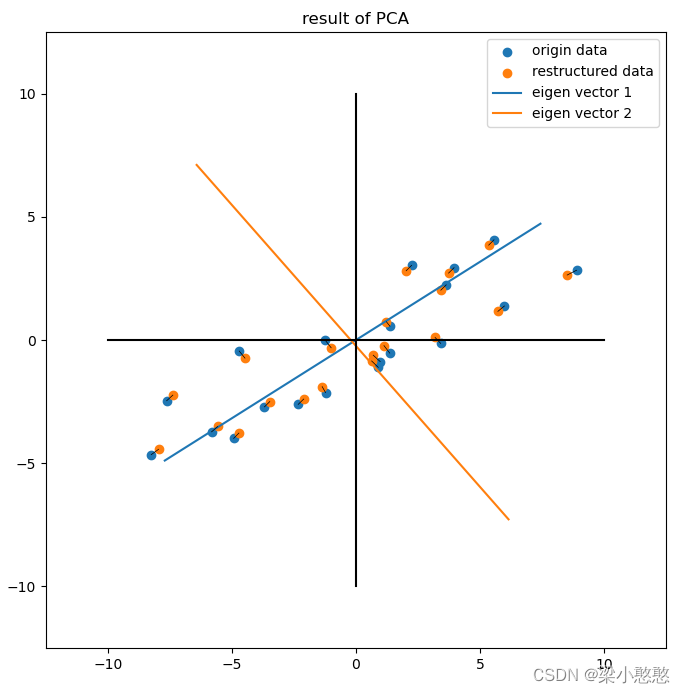
降维重构的数据与原数据对比
用我们刚刚的方法
import matplotlib.pyplot as plt
#设置图大小
size = 10
plt.figure(1,(8,8))
plt.scatter(data[:,0],data[:,1],label='origin data')
plt.scatter(data_[:,0],data_[:,1],label='restructured data')
i=0
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
i=1
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
#画一下x轴y轴
plt.plot([-size,size],[0,0],c='black')
plt.plot([0,0],[-size,size],c='black')
plt.xlim(-size,size)
plt.ylim(-size,size)
plt.legend()
plt.show()
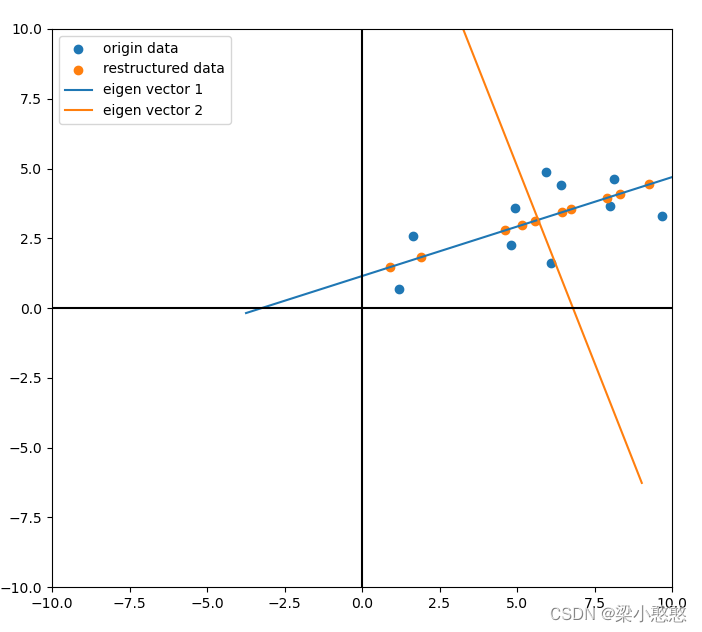
用sklearn的PCA
import matplotlib.pyplot as plt
#sklearn PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(data)
Y = pca.fit_transform(data)
vecs = pca.components_.T #每一列是一个特征向量
data_ = np.dot(Y[:,:1],vecs[:,:1].T)+data.mean(0)
#设置图大小
size = 10
plt.figure(1,(8,8))
plt.scatter(data[:,0],data[:,1],label='origin data')
plt.scatter(data_[:,0],data_[:,1],label='restructured data')
i=0
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
i=1
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
#画一下x轴y轴
plt.plot([-size,size],[0,0],c='black')
plt.plot([0,0],[-size,size],c='black')
plt.xlim(-size,size)
plt.ylim(-size,size)
plt.legend()
plt.show()
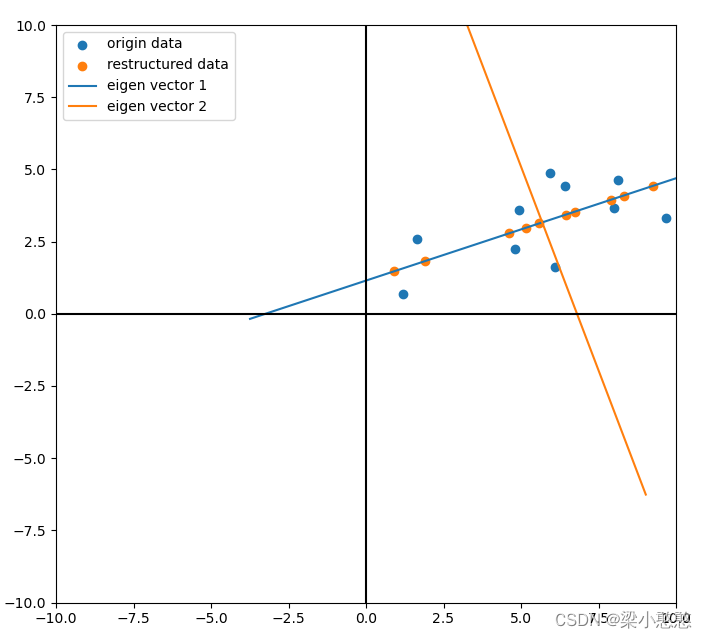
用SVD


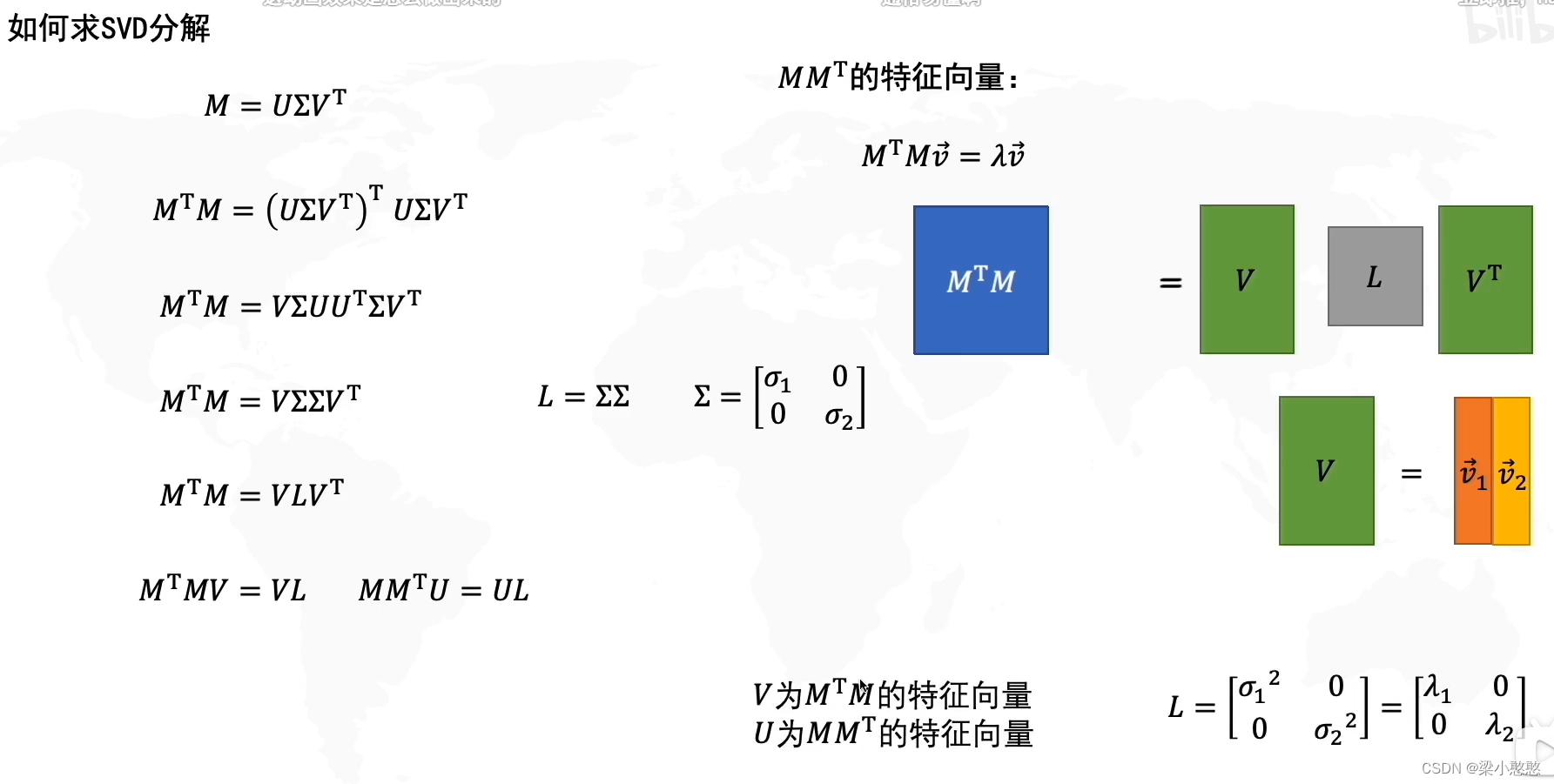

#用SVD主要是想用SVD求出主成分的方向向量
U,vals,V = np.linalg.svd(data_norm)
vecs = V.T
#数据在主成分1上的投影坐标是Y
Y = np.matmul(data_norm,vecs[:,:1])
#得到去中心化的还原数据
data_ = np.matmul(Y,vecs[:,:1].T)+data.mean(0)
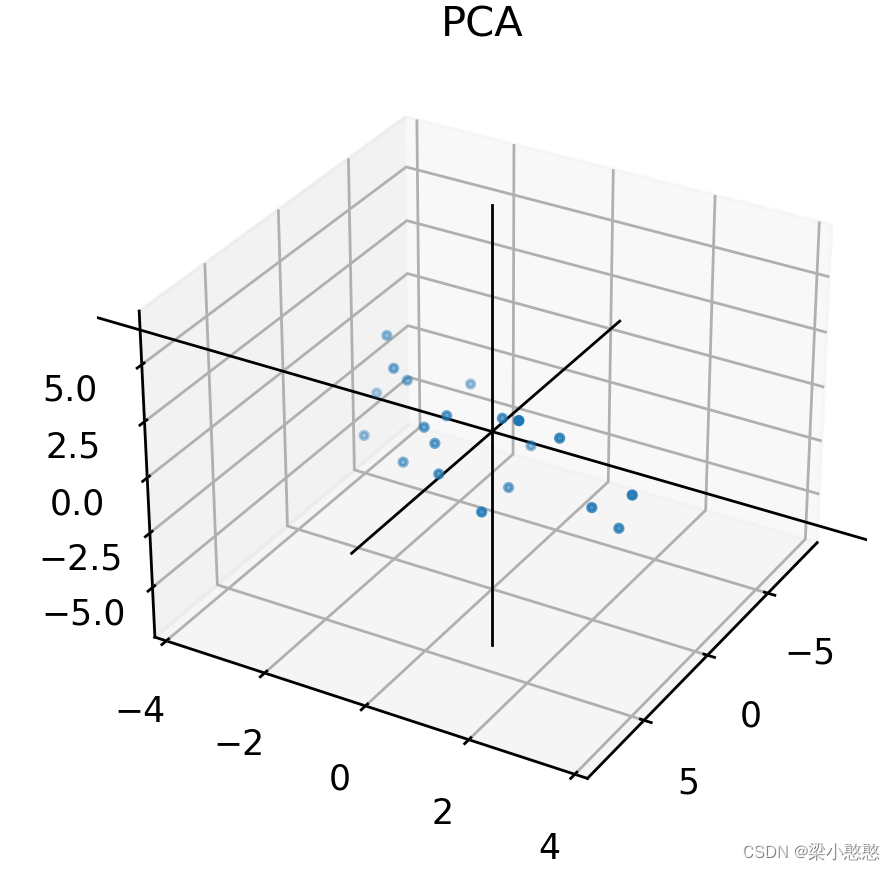
三维数据的测试
import matplotlib.pyplot as plt
X = data[:,0]
Y = data[:,1]
Z = data[:,2]
for i in range(0,90):
fig = plt.figure(1,(6,4),dpi = 250)
ax = fig.gca(projection='3d')
plt.cla()
#绘制散点
ax.scatter(X,Y,Z,s=5)
#绘制xyz轴
ax.plot([0,0],[0,0],[-10,10],c = 'black',linewidth = 0.8)
ax.plot([0,0],[-10,10],[0,0],c = 'black',linewidth = 0.8)
ax.plot([-10,10],[0,0],[0,0],c = 'black',linewidth = 0.8)
ax.view_init(azim=i)
plt.xlim(-X.max(), X.max())
plt.ylim(-Y.max(), Y.max())
ax.set_zlim(-Z.max(),Z.max())
plt.title('PCA')
plt.pause(0.1)
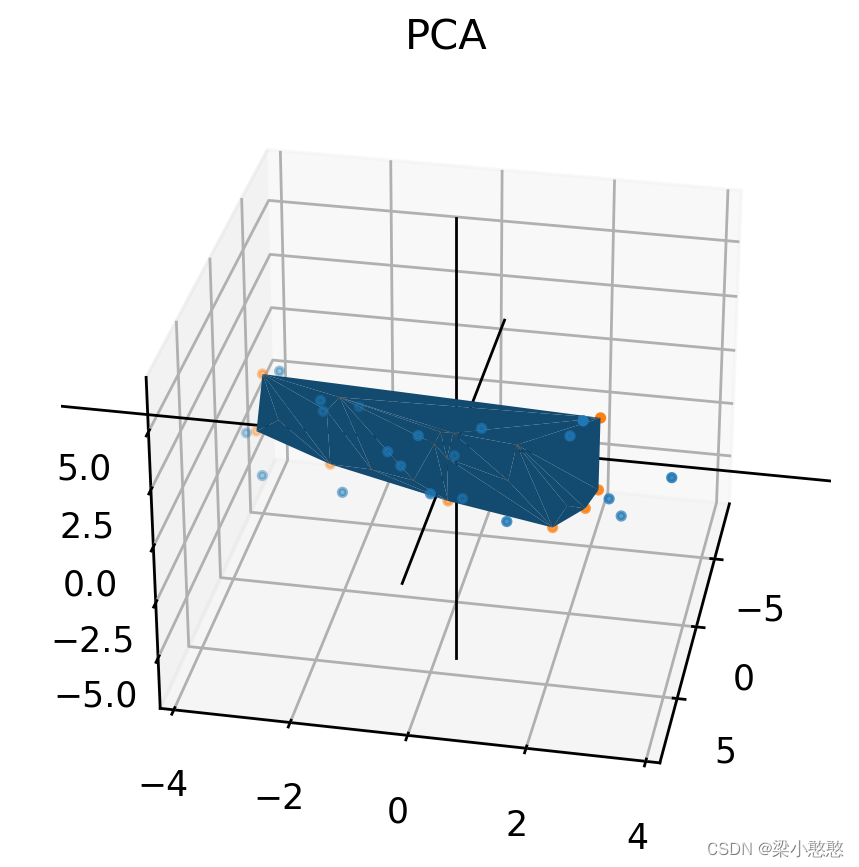
#数据在主成分1上的投影坐标是
zcf = np.matmul(data_normal,vecs[:,:2])
data_ = np.matmul(zcf,vecs[:,:2].T)+data.mean(0)
data_
import matplotlib.pyplot as plt
X = data[:,0]
Y = data[:,1]
Z = data[:,2]
X_ = data_[:,0]
Y_ = data_[:,1]
Z_ = data_[:,2]
for i in range(0,180):
fig = plt.figure(1,(6,4),dpi = 250)
ax = fig.gca(projection='3d')
plt.cla()
#绘制散点
ax.scatter(X,Y,Z,s=5,label='origin data')
ax.scatter(X_,Y_,Z_,s=5,label='restructured data')
ax.plot_trisurf(X_, Y_, Z_)
#绘制xyz轴
ax.plot([0,0],[0,0],[-10,10],c = 'black',linewidth = 0.8)
ax.plot([0,0],[-10,10],[0,0],c = 'black',linewidth = 0.8)
ax.plot([-10,10],[0,0],[0,0],c = 'black',linewidth = 0.8)
ax.view_init(azim=i)
plt.xlim(-X.max(), X.max())
plt.ylim(-Y.max(), Y.max())
ax.set_zlim(-Z.max(),Z.max())
plt.title('PCA')
plt.pause(0.1)
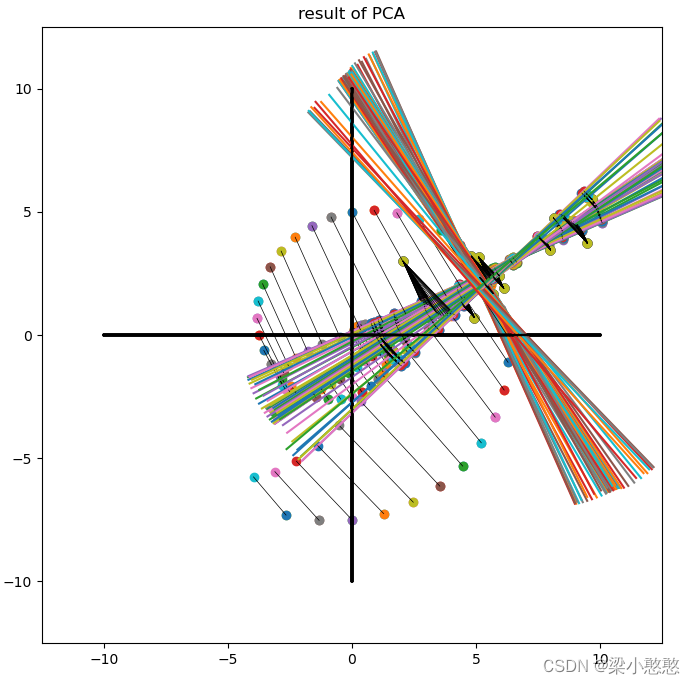
PCA的缺陷
如果加入异常值,PCA的结果会发生什么变化?
import matplotlib.pyplot as plt
import numpy as np
for i in range(0,720,10):
np.random.seed(0)
data = np.random.uniform(1,10,(20,2))
data[:,1:] = 0.5*data[:,0:1]+np.random.uniform(-2,2,(20,1))
#如果我们在数据中加入异常值,定义一个角度放入异常值
i = 2*i/360*np.pi
data_outsider=[np.sin(i)*5*i/(2*np.pi),np.cos(i)*5*i/(2*np.pi)]
data = np.vstack((data,data_outsider))
#去中心化
data_normal = data-data.mean(0)
X = data_normal[:,0]
Y = data_normal[:,1]
#协方差矩阵
C = np.cov(data_normal.T)
#计算特征值和特征向量
vals, vecs = np.linalg.eig(C)
#重新排序,从大到小
vecs = vecs[:,np.argsort(-vals)]
vals = vals[np.argsort(-vals)]
#数据在主成分1上的投影坐标是
zcf1 = np.matmul(data_normal,vecs[:,0])
#只用主成分1重构数据
data_ = np.matmul(zcf1.reshape(len(data),1),vecs[:,0].reshape(1,2))+data.mean(0)
#设置图大小
size = 10
plt.figure(1,(8,8))
plt.scatter(data[:,0],data[:,1],label='origin data')
plt.scatter(data_[:,0],data_[:,1],label='restructured data')
plt.scatter(data[-1,0],data[-1,1],label='outsider')
#绘制两个主成分的方向
i=0
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
i=1
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
#绘制一下原始数据和重构数据的连线
for j in range(len(data)):
plt.plot([data[j,0],data_[j,0]],[data[j,1],data_[j,1]],c='black',linewidth = 0.5)
#画一下x轴y轴
plt.plot([-size,size],[0,0],c='black')
plt.plot([0,0],[-size,size],c='black')
plt.xlim(-12.5,12.5)
plt.ylim(-12.5,12.5)
plt.title('result of PCA')
plt.legend()
plt.pause(0.1)
plt.clf()
Stable Principle Component Pursuit (SPCP)
PCA方法鲁棒性不佳是由于矩阵的噪声并不完全是高斯噪声。对应到视频序列中就是,长时间的静止视频中每帧的图片相关性极高,而在有物体运动时,往往是部分像素有极大的变化,但是变化的像素较少。这也就是说,视频中图像可以分成相关性极高的背景以及少量像素的前景图像。即低秩部分以及稀疏部分。这是优于PCA的部分,即前景图像对矩阵的分解影响较小。
Stable Principle Component Pursuit (SPCP)是PCA的改进版本,它把问题变成:
min L , S ∥ L ∥ ∗ + λ ∥ S ∥ 1 \min_{L,S}{ { \left\Vert {L} \right\Vert }_*+\lambda{ \left\Vert {S} \right\Vert }_1} L,Smin∥L∥∗+λ∥S∥1 s . t . M = L + S s.t. M=L+S s.t.M=L+S
其中:
M M M为原始矩阵 L L L为低秩矩阵。
∥ L ∥ { \left\Vert {L} \right\Vert } ∥L∥为 L L L矩阵核范数NuclearNorm,为矩阵奇异值的和(用于表示低秩矩阵)。
S S S为稀疏矩阵。
∥ S ∥ 1 { \left\Vert {S} \right\Vert }_1 ∥S∥1为矩阵 L 1 L1 L1范数(列模):表示矩阵中非零元素的绝对值之和 λ = 1 / m a x ( m , n ) \lambda=1/\sqrt{max(m,n)} λ=1/max(m,n)
即,把原始矩阵分解为低秩矩阵与稀疏矩阵的和,这样子稀疏矩阵代表的就是矩阵的异常值
为了方便求解,引入拉格朗日乘数,把问题变成: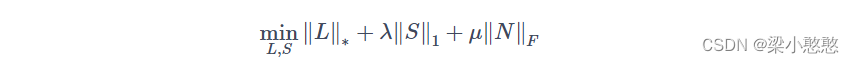
其中:噪声矩阵 N = M − L − S N=M−L−S N=M−L−S
建议的 μ μ μ取值为 μ = 2 m a x ( m , n ) δ , δ = ∥ N ∥ F μ=\sqrt{2max(m,n)δ},δ=∥N∥_F μ=2max(m,n)δ,δ=∥N∥F,这样子的取值足够大能够排除数据噪声,也足够小不会导致原始矩阵被过分缩小
用pytorch实现spcp
import numpy as np
import torch
import matplotlib.pyplot as plt
def spcp(data):
m,n = data.shape
LR = 0.01
L = torch.zeros([m,n],dtype=torch.float ,requires_grad=True)
S = torch.zeros([m,n],dtype=torch.float ,requires_grad=True)
M = torch.tensor(data,dtype=torch.float ,requires_grad=False)
N = M-L-S
lambda1 = 1/(max(m,n)**0.5)
mu = 1/20 * torch.norm(M,p = 'nuc')
optimizer = torch.optim.Adam([L,S],lr = LR,betas = (0.9,0.99))
t = 1
steps = []
losses = []
while torch.norm(N) > mu:
steps.append(t)
N = M-L-S
loss = torch.norm(L,p = 'nuc')+lambda1 * torch.norm(S,p =1) + mu * torch.norm(N)
losses.append(loss)
optimizer.zero_grad() #初始化梯度
loss.backward() #计算梯度
optimizer.step()
''' if t%10 == 0: import IPython IPython.display.clear_output(wait=True) plt.plot(steps,losses,label = 'loss') plt.plot(steps,losses,label = 'loss') plt.pause(0.1) '''
t+=1
dataL = L.data.numpy()
dataS = S.data.numpy()
dataN = N.data.numpy()
return dataL,dataS,dataN
dataL,dataS,dataN = spcp(data)
import numpy as np
import matplotlib.pyplot as plt
#设置图大小
size = 10
plt.figure(1,(8,8))
plt.scatter(data[:,0],data[:,1],label='origin data')
plt.scatter(data_[:,0],data_[:,1],label='restructured data')
vals,vecs = np.linalg.eig(np.cov(dataL.T))
#绘制两个主成分的方向
i=0
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+dataL.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
i=1
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+dataL.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
#绘制一下原始数据和重构数据的连线
for j in range(len(data)):
plt.plot([data[j,0],data_[j,0]],[data[j,1],data_[j,1]],c='black',linewidth = 0.5)
#画一下x轴y轴
plt.plot([-size,size],[0,0],c='black')
plt.plot([0,0],[-size,size],c='black')
plt.xlim(-12.5,12.5)
plt.ylim(-12.5,12.5)
plt.title('result of PCA')
plt.legend()
plt.show()
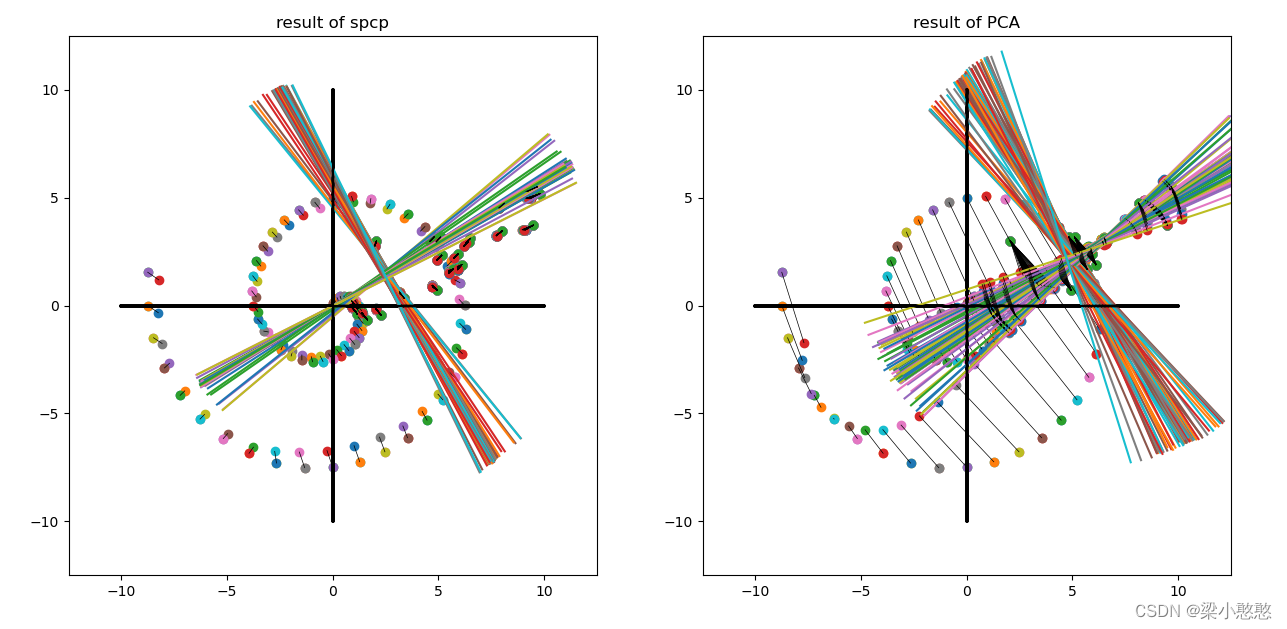
对比一下异常值对spcp和pca的反应
# 观察异常值对spcp的影响
for i in range(0,720,10):
import matplotlib.pyplot as plt
#设置图大小
size = 10
plt.figure(1,(15,7))
ax1=plt.subplot(121)
ax2=plt.subplot(122)
#造数据
np.random.seed(0)
data = np.random.uniform(1,10,(20,2))
data[:,1:] = 0.5*data[:,0:1]+np.random.uniform(-2,2,(20,1))
#如果我们在数据中加入异常值,定义一个角度放入异常值
i = 2*i/360*np.pi
data_outsider=[np.sin(i)*5*i/(2*np.pi),np.cos(i)*5*i/(2*np.pi)]
data = np.vstack((data,data_outsider))
#SPCP
dataL,dataS,dataN = spcp(data)
data_ = dataL+dataS
import numpy as np
plt.sca(ax1)
plt.scatter(data[:,0],data[:,1],label='origin data')
plt.scatter(data_[:,0],data_[:,1],label='restructured data')
plt.scatter(data[-1,0],data[-1,1],label='outsider')
vals,vecs = np.linalg.eig(np.cov(dataL.T))
#绘制两个主成分的方向
i=0
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+dataL.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
i=1
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+dataL.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
#绘制一下原始数据和重构数据的连线
for j in range(len(data)):
plt.plot([data[j,0],data_[j,0]],[data[j,1],data_[j,1]],c='black',linewidth = 0.5)
#画一下x轴y轴
plt.plot([-size,size],[0,0],c='black')
plt.plot([0,0],[-size,size],c='black')
plt.xlim(-12.5,12.5)
plt.ylim(-12.5,12.5)
plt.title('result of spcp')
# plt.legend()
#PCA
plt.sca(ax2)
#去中心化
data_normal = data-data.mean(0)
X = data_normal[:,0]
Y = data_normal[:,1]
#协方差矩阵
C = np.cov(data_normal.T)
#计算特征值和特征向量
vals, vecs = np.linalg.eig(C)
#数据在主成分1上的投影坐标是
zcf1 = np.matmul(data_normal,vecs[:,0])
#只用主成分1重构数据
data_ = np.matmul(zcf1.reshape(len(data),1),vecs[:,0].reshape(1,2))+data.mean(0)
plt.scatter(data[:,0],data[:,1],label='origin data')
plt.scatter(data_[:,0],data_[:,1],label='restructured data')
plt.scatter(data[-1,0],data[-1,1],label='outsider')
i=0
#绘制两个主成分的方向
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
i=1
ev = np.array([vecs[:,i]*-1,vecs[:,i]])*size
ev = (ev+data.mean(0))
plt.plot(ev[:,0],ev[:,1],label = 'eigen vector '+str(i+1))
#绘制一下原始数据和重构数据的连线
for j in range(len(data)):
plt.plot([data[j,0],data_[j,0]],[data[j,1],data_[j,1]],c='black',linewidth = 0.5)
#画一下x轴y轴
plt.plot([-size,size],[0,0],c='black')
plt.plot([0,0],[-size,size],c='black')
plt.xlim(-12.5,12.5)
plt.ylim(-12.5,12.5)
plt.title('result of PCA')
# plt.legend()
plt.pause(0.1)
# plt.clf()
内容来源
https://gitee.com/ni1o1/pygeo-tutorial/blob/master/12-.ipynb
用最直观的方式告诉你:什么是主成分分析PCA
【学长小课堂】什么是奇异值分解SVD–SVD如何分解时空矩阵
边栏推荐
- 汇编语言中b和bl关键字的区别
- "Weekly Translate Go" This time we have something different!-- "How to Code in Go" series launched
- HCIP--路由策略实验
- Packages and packages, access modifiers
- y85.第四章 Prometheus大厂监控体系及实战 -- prometheus告警机制进阶、pushgateway和prometheus存储(十六)
- 博客主页rrs代码
- golang source code analysis: uber-go/ratelimit
- sre成长之路
- 包管理工具Chocolate - Win10如何安装Chocolate工具、快速上手、进阶用法
- The software testing process specification is what?Specific what to do?
猜你喜欢
Tencent YunMeng every jie: I experienced by cloud native authors efficiency best practices case
包管理工具Chocolate - Win10如何安装Chocolate工具、快速上手、进阶用法
VisualStudio 制作Dynamic Link Library动态链接库文件
SQL基础练习题(mysql)
华为设备配置BFD多跳检测
"A daily practice, happy water problem" 1374. Generate a string with an odd number of each character

软件测试的流程规范有哪些?具体要怎么做?
ICLR 2022最佳论文:基于对比消歧的偏标签学习

php 单引号 双引号 -> => return echo

Jar包启动通过ClassPathResource获取不到文件路径问题

随机推荐
.NET如何快速比较两个byte数组是否相等
Use the TCP protocol, we won't lost package?
Details in C# you don't know
ALV concept explanation
汉源高科千兆4光4电工业级网管型智能环网冗余以太网交换机防浪涌防雷导轨式安装
[C题目]力扣234. 回文链表
C primer plus学习笔记 —— 9、联合&枚举&typdef
C语言中变量在内存中的保存与访问
callback prototype __proto__
js how to get the browser zoom ratio
第七章 噪声
php 单引号 双引号 -> => return echo
golang 刷leetcode:统计打字方案数
李沐动手学深度学习V2-bert和代码实现
go——内存分配机制
golang 刷leetcode:从栈中取出 K 个硬币的最大面值和
VisualStudio 制作Dynamic Link Library动态链接库文件
一款免费的容器安全 SaaS 平台使用记录
Informatics Olympiad All-in-One (1259: [Example 9.3] Find the longest non-descending sequence)
信息学奥赛一本通(1256:献给阿尔吉侬的花束)