Aiming at the "amnesia" of deep learning, scientists proposed that based on similarity weighted interleaved learning, they can board PNAS
2022-07-04 20:26:00
【Zhiyuan community】

Different from human beings , When learning new things, artificial neural network will quickly forget the previously learned information , We must retrain through the intersection of old and new information ; however , Interleaving all old information is time-consuming , And it may not be necessary . It may be enough to interleave old information that is substantially similar to new information .
In recent days, , The proceedings of the American Academy of Sciences (PNAS) Published a paper ,“Learning in deep neural networks and brains with similarity-weighted interleaved learning”, By members of the Royal Society of Canada 、 Well known neuroscientists Bruce McNaughton Published by the team of . Their work found , Through the similarity weighted staggered training of old information and new information , Deep network can quickly learn new things , It not only reduces the forgetting rate , And the amount of data used is greatly reduced .
The author also makes a hypothesis : By tracking recently active neurons and neurodynamic attractors (attractor dynamics) Continuous excitability track , Similarity weighted interleaving can be achieved in the brain . These findings may promote the further development of neuroscience and machine learning .
author | Rajat Saxena et al. from :AI Technology Review
Understanding how the brain learns for life remains a long-term challenge . In artificial neural networks (ANN) in , Integrating new information too quickly can cause catastrophic interference , That is, the previously acquired knowledge is suddenly lost . Complementary learning system theory (Complementary Learning Systems Theory,CLST) indicate , By interlacing new memories with existing knowledge , New memories can gradually integrate into the neocortex .CLST Pointed out that , The brain depends on complementary learning systems : The hippocampus, (HC) For quick access to new memories , Neocortex (NC) It is used to gradually integrate new data into context free structured knowledge . stay “ While offline ”, For example, during sleep and quiet waking rest ,HC Trigger playback recently in NC Experience in , and NC Spontaneously retrieve and interleave representations of existing categories . Interleaved playback allows gradual adjustment in a gradient descent NC Synaptic weight , To create context independent category representations , So as to integrate new memories gracefully and overcome catastrophic interference . Many studies have successfully used interleaved playback to realize lifelong learning of Neural Networks . However , Application in practice CLST when , Yes Two important problems need to be solved . First , When the brain cannot access all old data , How to carry out comprehensive information interleaving ? One possible solution is “ Fake rehearsal ”, Random input can trigger generative playback of internal representation , There is no need to explicitly access the previously learned examples . Attractor like dynamics may enable the brain to complete “ Fake rehearsal ”, but “ Fake rehearsal ” The content of is not clear . therefore , The second question is , After each new learning activity , Does the brain have enough time to interweave all the previously learned information . Similarity weighted interlaced learning (Similarity-Weighted Interleaved Learning,SWIL) Algorithm is considered as the solution of the second problem , This indicates that it may be sufficient to interleave only the old information that has substantial representational similarity with the new information . Empirical behavior research shows , Highly consistent new information can be quickly integrated into NC Structured knowledge , There's almost no interference . This shows that the speed of integrating new information depends on its consistency with prior knowledge . Inspired by the results of this behavior , And by re examining the distribution of catastrophic interference between previously obtained categories ,McClelland Wait for someone to prove SWIL It can have two categories of semantic words ( for example ,“ Fruits ” yes “ Apple ” and “ Banana ” The semantic word of ) Simple data set , Every epoch Use less than 2.5 Times the amount of data to learn new information , It achieves the same performance as training the network on all data . However , Researchers have not found similar effects when using more complex data sets , This raises concerns about the scalability of the algorithm . Experiments show that , Deep nonlinear artificial neural networks can learn new information by only interleaving and sharing a large number of old information subsets representing similarity with new information . By using SWIL Algorithm ,ANN It can quickly learn new information with similar accuracy level and minimum interference , The amount of old information presented in each period of simultaneous use is very small , This means high data utilization and fast learning . meanwhile ,SWIL It can also be applied to sequence learning framework . Besides , Learning a new category can greatly improve data utilization . If the old information has very little similarity with the previously learned categories , Then the amount of old information presented will be much less , This is probably the actual situation of human learning . Last , The author puts forward a question about SWIL A theoretical model of how to implement in the brain , Its excitability deviation and new information Is proportional to the overlap of .
Applied to image classification dataset
McClelland The experiments of et al , In a deep linear network with a hidden layer ,SWIL You can learn a new category , It is similar to complete interlaced learning (Fully Interleaved Learning,FIL), namely Stagger the entire old category with the new category , But the amount of data used is reduced 40%. However , The network is trained on a very simple data set , There are only two semantic word categories , This raises questions about the scalability of the algorithm . First, for more complex data sets ( Such as Fashion-MNIST), Explore how different kinds of learning evolve in a deep linear neural network with a hidden layer . Moved out of “boot”(“ Boots ”) and “bag”(“ paper bag ”) After category , The model is in the rest 8 The accuracy of the test on the categories has reached 87%. Then the author team retrained the model , Study under two different conditions ( new )“boot” class , Repeat each condition 10 Time :1) Concentrated learning (Focused Learning ,FoL), That is, only new “boot” class ;2) Completely staggered learning (FIL), That is, all categories ( New category + Categories learned before ) Present with equal probability . In both cases , Every epoch In all 180 Zhang image , Every epoch The image in is the same . The network is in total 9000 Zhang has tested on an image he has never seen , The test data set consists of each class 1000 It's made up of images , barring “bag” Category . When the performance of the network reaches asymptote , Training stopped . It is as expected ,FoL It interferes with the old category , and FIL Overcome this ( chart 1 The first 2 Column ). As mentioned above ,FoL Interference with old data varies by category , This is a SWIL Part of the original inspiration , And show the new “boot” There is a hierarchical similarity relationship between categories and old categories . for example ,“sneaker”(“ Sports shoes ”) and “sandals”(“ Sandals ”) The recall rate is higher than “trouser”(“ The trousers ”) Falling faster ( chart 1 The first 2 Column ), It may be because of the integration of new “boot” Classes will selectively change the representation “sneaker” and “sandals” Synaptic weight of class , Thus causing more interference .
chart 1: The pre training network learns new in two cases “boot” Performance comparison and analysis of class :FoL( On ) and FIL( Next ). From left to right, there are predicted new “boot” Recall rate of categories ( Olive )、 Recall rate of existing categories ( Draw with different colors )、 Total accuracy ( High score means low error ) And cross entropy loss ( Measurement of total error ) curve , Is reserved on the test data set with epoch Number related functions .
Calculate the similarity between different categories
FoL When learning new categories , The classification performance of similar old categories will be greatly reduced . The relationship between multi category attribute similarity and learning has been discussed before , And it shows that the deep linear network can quickly obtain the known consistent attributes . by comparison , Add inconsistent attributes of new branches to the existing category hierarchy , Need to be slow 、 gradual 、 Staggered learning . In the present work , The author team uses the proposed method to calculate the similarity at the feature level . in short , Calculate the target hidden layer ( It is usually the penultimate layer ) Cosine similarity between the average activation vectors of each class of the existing class and the new class . chart 2A Show based on Fashion MNIST New data set “boot” Categories and old categories , The similarity matrix calculated by the author's team according to the penultimate activation function of the pre training network . The similarity between categories is consistent with our visual perception of objects . for example , In hierarchical clustering graph ( chart 2B) in , We can observe that “boot” Class and “sneaker” and “sandal” Between classes 、 as well as “shirt”(“ shirt ”) and “t-shirt”(“T T-shirt ”) There is high similarity between classes . Similarity matrix ( chart 2A) And confusion matrix ( chart 2C) Exactly the same . The higher the similarity , The easier it is to confuse , for example ,“ shirt ” Class and “T T-shirt ”、“ Pullover ” and “ coat ” Class images are easily confused , This shows that the similarity measure predicts the learning dynamics of Neural Networks . In the last section FoL Result chart ( chart 1) in , There is a similar class similarity curve in the recall rate curve of the old class . Different from the old category (“trouser” etc. ) comparison ,FoL Learning new “boot” Class will quickly forget similar old categories (“sneaker” and “sandal”).
chart 2:( A ) According to the penultimate activation function of the pre training network , Calculate the existing categories and new “boot” Class similarity matrix , Where the diagonal value ( The similarity of the same category is drawn in white ) Be deleted .( B ) Yes A Hierarchical clustering based on the similarity matrix in .( C ) FIL The algorithm is training and learning “boot” Confusion matrix generated after class . For zoom clarity , Diagonal value deleted .
Deep linear neural network realizes fast and
Learn new things efficiently
Next, on the basis of the first two conditions 3 New conditions , Research on new classification learning dynamics , Each of these conditions repeats 10 Time :1)FoL( total n=6000 Zhang image /epoch);2) FIL( total n=54000 Zhang image /epoch,6000 Zhang image / class );3) Partial interlaced learning (Partial Interleaved Learning,PIL) A small subset of images is used ( total n=350 Zhang image /epoch, about 39 Zhang image / class ), Each category ( New category + Existing categories ) The image of is presented with equal probability ;4) SWIL, Every epoch Use with PIL Retrain with the same total number of images , But according to and ( new )“boot” Category similarity weights existing category images ;5) Equal rights staggered learning (Equally Weighted Interleaved Learning,EqWIL), Use with SWIL The same number of “boot” Class image retraining , But the weight of existing category images is the same ( chart 3A). The author team used the same test data set mentioned above ( share n=9000 Zhang image ). When the performance of neural network reaches asymptote under each condition , Stop training . Although each epoch Less training data is used , New prediction “boot” Class accuracy takes longer to reach asymptote , And FIL(H=7.27,P<0.05) comparison ,PIL The recall rate of is lower ( chart 3B The first 1 Columns and tables 1“New class” Column ). about SWIL, Similarity calculation is used to determine the proportion of existing old category images to be interleaved . On this basis , The author team Input images with weighted probability are randomly selected from each old category . Compared with other categories ,“sneaker” and “sandal” Class is the most similar , This leads to a higher proportion of being staggered ( chart 3A). According to the tree view ( chart 2B), The author team will “sneaker” and “sandal” Classes are called similar old classes , The rest are called different old classes . And PIL(H=5.44,P<0.05) comparison , Use SWIL when , Model learning new “boot” Class is faster , Interference to existing categories is also similar . Besides ,SWIL(H=0.056,P>0.05) Recall rate of new categories ( chart 3B The first 1 Columns and tables 1“New class” Column )、 The total accuracy and loss are compared with FIL Quite a .EqWIL(H=10.99,P<0.05) The new “boot” Class learning and SWIL identical , But there is a greater degree of interference with similar old categories ( chart 3B The first 2 Columns and tables 1“Similar old class” Column ). The author team used the following two methods to compare SWIL and FIL:1) Memory ratio , namely FIL and SWIL The ratio of the number of images stored in , Indicates that the amount of stored data is reduced ;2) Speedup ratio , That is to say FIL and SWIL The ratio of the total content rendered in , To achieve the saturation accuracy of new category recall , It shows that the time required to learn new categories is reduced .SWIL You can learn new content with reduced data requirements , Memory ratio =154.3x (54000/350), And faster , Speedup ratio =77.1x (54000/(350×2)). Even if the number of images related to new content is small , The model can also be used SWIL, Using the hierarchical structure of model prior knowledge to achieve the same performance .SWIL stay PIL and EqWIL An intermediate buffer is provided between , Allow integration of a new category , And minimize the interference to existing categories .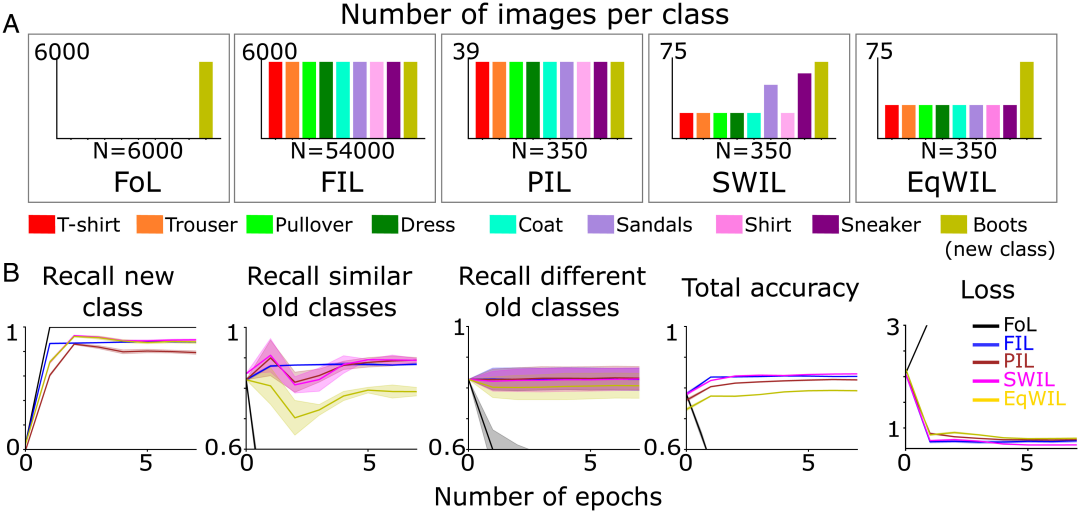
chart 3 ( A ) The author's team pre trained the neural network to learn new under five different learning conditions “boot” class ( Olive green ), Until the performance is stable :1)FoL( total n=6000 Zhang image /epoch);2)FIL( total n=54000 Zhang image /epoch);3) PIL( total n=350 Zhang image /epoch);4) SWIL( total n=350 Zhang image /epoch) and 5) EqWIL( total n=350 Zhang image /epoch).(B)FoL( black )、FIL( Blue )、PIL( Brown )、SWIL( Magenta ) and EqWIL( golden ) Predict new categories 、 Similar to the old category (“sneaker” and “sandals”) And the recall rate of different old categories , Predict the total accuracy of all categories , And the cross entropy loss on the test data set , The abscissa is epoch Count .
be based on CIFAR10 Use SWIL
stay CNN Learn new categories in Middle School
Next , In order to test SWIL Whether you can work in a more complex environment , The author team Trained a with a fully connected output layer 6 Layer nonlinearity CNN( chart 4A), To identify CIFAR10 Remaining in the dataset 8 Different categories (“cat” and “car” With the exception of ) Image . They also retrained the model , Defined before 5 Different training conditions (FoL、FIL、PIL、SWIL and EqWIL) Lower learning “cat”(“ cat ”) class . chart 4C Shows 5 In this case, the distribution of each type of image . about SWIL、PIL and EqWIL Conditions , Every epoch The total number of images is 2400, And for FIL and FoL, Every epoch The total number of images is 45000 and 5000. The author's team trains the network for each situation , Until the performance tends to stabilize . They haven't seen a total of 9000 Zhang image (1000 Zhang image / class , barring “car”(“ Sedan ”) class ) The model is tested on . chart 4B The author team is based on CIFAR10 Similarity matrix of data set calculation .“cat” Classes and “dog”(“ Dog ”) Class is more similar , Other animals belong to the same branch ( chart 4B Left ). According to the tree view ( chart 4B), take “truck” (“ truck ”)、“ship”(“ ship ”) and “plane”(“ The plane ”) Categories are called different old categories , except “cat” The other animal categories outside the category are called similar old categories . about FoL, The model learns new “cat” class , But forget the old category . And Fashion-MNIST The dataset results are similar ,“dog” class ( And “cat” Class similarity is the greatest ) and “truck” class ( And “cat” Class similarity is minimal ) There are interference gradients , among “dog” Class has the highest forgetting rate , and “truck” The class forgetting rate is the lowest . Pictured 4D Shown ,FIL Algorithm learning new “cat” Class time overcomes catastrophic interference . about PIL Algorithm , The model is in each epoch Use 18.75 Times the amount of data to learn new “cat” class , but “cat” Recall ratio of class FIL(H=5.72,P<0.05) low . about SWIL, In the new category 、 Recall rates on similar and different old categories 、 The total accuracy and loss are compared with FIL Quite a (H=0.42,P>0.05; See table 2 Sum graph 4D).SWIL To the new “cat” The recall rate of class is higher than PIL(H=7.89,P<0.05). Use EqWIL When the algorithm , new “cat” Class learning and SWIL and FIL be similar , But the interference to similar old categories is large (H=24.77,P<0.05; See table 2).FIL、PIL、SWIL and EqWIL this 4 The performance of these algorithms in predicting different old classes is similar (H=0.6,P>0.05).SWI Than PIL Better integrate the new “cat” class , And help overcome EqWIL Observation interference in . And FIL comparison , Use SWIL Learning new categories is faster , Speedup ratio =31.25x (45000×10/(2400×6)), Use less data at the same time ( Memory ratio =18.75x). These results prove that , Even in nonlinear CNN And more realistic data sets ,SWIL It can also effectively learn new categories of things .
chart 4:( A ) The author team uses 6 Layer nonlinearity CNN Study CIFAR10 In dataset 8 Class things .( B ) Similarity matrix ( Right ) Is presenting a new “cat” After the class , The author's team calculated according to the activation function of the last convolution layer . Apply hierarchical clustering to similar matrices ( Left ), Show animals in the tree view ( Olive green ) And transportation ( Blue ) The grouping of two semantic word categories .( C ) The author team is 5 Pre training under different conditions CNN Learn new “cat” class ( Olive green ), Until the performance is stable :1)FoL( total n=5000 Zhang image /epoch);2)FIL( total n=45000 Zhang image /epoch);3) PIL( total n=2400 Zhang image /epoch);4) SWIL( total n=2400 Zhang image /epoch);5) EqWIL( total n=2400 Zhang image /epoch). Repeat each condition 10 Time .(D)FoL( black )、FIL( Blue )、PIL( Brown )、SWIL( Magenta ) and EqWIL( golden ) Predict new categories 、 Similar to the old category (CIFAR10 Other animals in the dataset ) And different old categories (“plane” 、“ship” and “truck”) The recall rate , Predict the total accuracy of all categories , And the cross entropy loss on the test data set , The abscissa is epoch Count .
Consistency between new content and old categories
Impact on learning time and required data
If a new content can be added to the previously learned category , There is no need to make major changes to the network , said The two are consistent . Based on this framework , Interfere with multiple existing categories ( Low consistency ) Compared with the new category , There is less interference in learning existing categories ( High consistency ) New categories of can be more easily integrated into the network . To test the above inference , The author team uses the pre trained CNN, All described above 5 Under three learning conditions , Learned a new “car” Category . chart 5A Shows “car” Similarity matrix of categories , Compared with other existing categories ,“car” and “truck”、“ship” and “plane” Under the same level node , It means they are more similar . To further confirm , The author's team carried out t-SNE Dimension reduction and visualization analysis ( chart 5B). The study found that “car” Class and other vehicles (“truck”、“ship” and “plane”) There is significant overlap , and “cat” And other animals (“dog”、 “frog”(“ frog ”)、“horse”(“ Horse ”)、“bird”(“ bird ”) and “deer”(“ deer ”)) There is overlap . In line with the expectations of the author team ,FoL Study “car” Category will cause disastrous interference , It is more disturbing to similar old categories , While using FIL Overcome this ( chart 5D). about PIL、SWIL and EqWIL, Every epoch All in all n=2000 Zhang image ( chart 5C). Use SWIL Algorithm , Model learning new “car” Categories can reach and FIL(H=0.79,P>0.05) Similar precision , For existing categories ( Including similar and different categories ) Minimum interference . Pictured 5D The first 2 Column , Use EqWIL, Model learning new “car” Class in the same way as SWIL identical , But for other similar categories ( for example “truck”) The degree of interference is higher (H=53.81,P<0.05). And FIL comparison ,SWIL You can learn new content faster , Speedup ratio =48.75x(45000×12/(2000×6)), Reduced memory requirements , Memory ratio =22.5x. And “cat”(48.75x vs.31.25x) comparison ,“car” By interleaving fewer classes ( Such as “truck”、“ship” and “plane”) Learn faster , and “cat” With more categories ( Such as “dog” 、“frog” 、“horse” 、“frog” and “deer”) overlap . These simulation experiments show , The amount of old category data needed to cross and accelerate learning new categories , It depends on the consistency of new information and prior knowledge .
chart 5:( A ) The author team calculated the similarity matrix according to the penultimate activation function ( Left ), And present new “car” The result graph after hierarchical clustering of the similarity matrix after classification ( Right ).( B ) Models learn new “car” Categories and “cat” Category , After the last convolution layer over activation function , The author team conducted t-SNE The result diagram of dimension reduction visualization .( C ) The author team is 5 Pre training under different conditions CNN Learn new “car” class ( Olive green ), Until the performance is stable :1)FoL( total n=5000 Zhang image /epoch);2)FIL( total n=45000 Zhang image /epoch);3) PIL( total n=2000 Zhang image /epoch);4) SWIL( total n=2000 Zhang image /epoch);5) EqWIL( total n=2000 Zhang image /epoch).(D)FoL( black )、FIL( Blue )、PIL( Brown )、SWIL( Magenta ) and EqWIL( golden ) Predict new categories 、 Similar to the old category (“plane” 、“ship” and “truck”) And different old categories (CIFAR10 Other animals in the dataset ) The recall rate , Predict the total accuracy of all categories , And the cross entropy loss on the test data set , The abscissa is epoch Count . Each picture shows repetition 10 Average after times , The shaded area is ±1 SEM.
utilize SWIL Sequence learning
Next , The author team tests whether it can be used SWIL Learn new content presented in serialized form ( Sequence learning framework ). For this reason, they adopted figure 4 Trained in CNN Model , stay FIL and SWIL Study under conditions CIFAR10 In dataset “cat” class ( Mission 1), Only in CIFAR10 The rest of 9 Training in categories , Then train the model to learn new under each condition “car” class ( Mission 2). chart 6 The first 1 Column shows SWIL Study under conditions “car” When category , The distribution of the number of images in other categories ( total n=2500 Zhang image /epoch). It should be noted that , forecast “cat” Class time also cross learns new “car” class . Because in FIL The performance of the model is the best under ,SWIL Only with FIL The results are compared . Pictured 6 Shown ,SWIL New prediction 、 The ability of the old category is similar to FIL Quite a (H=14.3,P>0.05). Model USES SWIL Algorithm can learn new faster “car” Category , The speedup is 45x(50000×20/(2500×8)), Every epoch Memory occupancy ratio of FIL Less 20 times . Model learning “cat” and “car” When category , stay SWIL Under the condition of each epoch Number of images used ( The memory ratio and acceleration ratio are 18.75x and 20x), Less than in FIL Under the condition of each epoch The entire data set used ( The memory ratio and acceleration ratio are 31.25x and 45x), And you can still learn new categories quickly . Expand this idea , As the number of categories learned increases , The author team expects that the learning time and data storage of the model will be reduced exponentially , So as to learn new categories more efficiently , This may reflect the actual learning of the human brain . Experimental results show that ,SWIL Multiple new classes can be integrated in the sequence learning framework , So that the neural network can continue to learn without interference .![]() chart 6: Author team training 6 layer CNN Learn new “cat” class ( Mission 1), Then learn “car” class ( Mission 2), Until the performance tends to stabilize in the following two cases :1)FIL: Include all old categories ( Draw in different colors ) And new categories presented with the same probability (“cat”/“car”) Images ;2) SWIL: According to the new category (“cat”/“car”) Weight the similarity of and use the old category examples proportionally . At the same time, the task 1 Learning from “cat” Classes are included , And according to the task 2 Middle school learning “car” Class similarity is weighted . The first 1 A sub graph represents each epoch Distribution of the number of images used , Other subgraphs represent FIL( Blue ) and SWIL( Magenta ) Predict new categories 、 Recall rates of similar old categories and different old categories , Predict the total accuracy of all categories , And the cross entropy loss on the test data set , The abscissa is epoch Count .
chart 6: Author team training 6 layer CNN Learn new “cat” class ( Mission 1), Then learn “car” class ( Mission 2), Until the performance tends to stabilize in the following two cases :1)FIL: Include all old categories ( Draw in different colors ) And new categories presented with the same probability (“cat”/“car”) Images ;2) SWIL: According to the new category (“cat”/“car”) Weight the similarity of and use the old category examples proportionally . At the same time, the task 1 Learning from “cat” Classes are included , And according to the task 2 Middle school learning “car” Class similarity is weighted . The first 1 A sub graph represents each epoch Distribution of the number of images used , Other subgraphs represent FIL( Blue ) and SWIL( Magenta ) Predict new categories 、 Recall rates of similar old categories and different old categories , Predict the total accuracy of all categories , And the cross entropy loss on the test data set , The abscissa is epoch Count .
utilize SWIL Expand the distance between categories ,
Reduce learning time and data volume
The author team finally tested SWIL Generalization of the algorithm , Verify whether it can learn to include more categories of data sets , And whether it is suitable for more complex network architecture . They are CIFAR100 Data sets ( Training set 500 Zhang image / class , Test set 100 Zhang image / class ) I trained a complex CNN Model -VGG19( share 19 layer ), Learned one of them 90 Categories . Then retrain the network , Learn new categories . chart 7A Show based on CIFAR100 Data sets , The similarity matrix calculated by the author's team according to the activation function of the penultimate layer . Pictured 7B Shown , new “train”(“ train ”) Class and many existing vehicle categories ( Such as “bus” (“ The bus ”)、“streetcar” (“ tram ”) and “tractor”(“ Tractor ”) etc. ) Very similar . And FIL comparison ,SWIL You can learn new things faster ( Speedup ratio =95.45x (45500×6/(1430×2))) And the amount of data used ( Memory ratio =31.8x) Significant reduction , And the performance is basically the same (H=8.21, P>0.05) . Pictured 7C Shown , stay PIL(H=10.34,P<0.05) and EqWIL(H=24.77,P<0.05) Under the condition of , The model predicts that the recall rate of new categories is low and the interference is large , and SWIL Overcome the above shortcomings . meanwhile , In order to explore whether the large distance between different category representations constitutes the basic condition for accelerating model learning , The author's team trained two other neural network models :1)6 layer CNN( And based on CIFAR10 Graph 4 Sum graph 5 identical );2)VGG11(11 layer ) Study CIFAR100 In dataset 90 Categories , Only in FIL and SWIL Two conditions for new “train” Class for training . Pictured 7B Shown , For the above two network models , new “train” The overlap between class and vehicle class is higher , But with VGG19 The model compares , The separation degree of each category is low . And FIL comparison ,SWIL The speed of learning new things is roughly linear with the increase of layers ( Slope =0.84). The result shows that , Increasing the representation distance between categories can speed up learning and reduce memory load .
chart 7:( A ) VGG19 Learn new “train” After the class , The similarity matrix calculated by the author's team according to the penultimate activation function .“truck” 、“streetcar” 、“bus” 、“house” and “tractor”5 The type is different from “train” The most similar . Exclude diagonal elements from the similarity matrix ( Similarity degree =1).(B, Left ) The author team aims at 6 layer CNN、VGG11 and VGG19 The Internet , After the penultimate activation function , Conduct t-SNE The result diagram of dimension reduction visualization .(B, Right ) The vertical axis represents the acceleration ratio (FIL/SWIL), The horizontal axis indicates 3 The number of layers of different networks is relative to 6 layer CNN Ratio of . Black dotted line 、 The red dotted line and the blue solid line represent the slope respectively =1 The standard line of 、 Best fit line and simulation results .( C ) VGG19 Model learning :FoL( black )、FIL( Blue )、PIL( Brown )、SWIL( Magenta ) and EqWIL( golden ) New prediction “train” class 、 Similar to the old category ( Vehicle category ) And different old categories ( In addition to the vehicle category ) The recall rate , Predict the total accuracy of all categories , And the cross entropy loss on the test data set , The abscissa is epoch Count . Each picture shows repetition 10 Average after times , The shaded area is ±1 SEM.( D ) From left to right, it indicates the model prediction Fashion-MNIST“boot” class ( chart 3)、CIFAR10“cat” class ( chart 4)、CIFAR10“car” class ( chart 5) and CIFAR100“train” Class recall rate , yes SWIL( Magenta ) and FIL( Blue ) Total number of images used ( Logarithmic scale ) Function of .“N” Means each under each learning condition epoch Total number of images used ( Including new 、 Old category ). If the network is trained on more non overlapping classes , And the distance between the representations is larger , Will the speed be further improved ? So , The author team adopted a Deep linear network ( For Graphs 1-3 Medium Fashion-MNIST Example ), And train them , Learn from 8 individual Fashion-MNIST Category ( barring “bags” and “boot” class ) and 10 individual Digit-MNIST Combined data set formed by categories , Then train the network to learn new “boot” Category . In line with the expectations of the author team ,“boot” With the old category “sandals” and “sneaker” Higher similarity , The second is the rest Fashion-MNIST class ( Mainly including clothing images ), Last Digit-MNIST class ( It mainly includes digital images ). Based on this , The author team first interwoven more similar samples of old categories , Then interweave Fashion-MNIST and Digit-MNIST Class sample ( total n=350 Zhang image /epoch). Experimental results show that , And FIL similar ,SWIL Can quickly learn new categories of content without interference , But the subset of data used is much smaller , The memory ratio is 325.7x (114000/350) , The speedup is 162.85x (228000/1400). The acceleration ratio observed by the author team in the current results is 2.1x (162.85/77.1), And Fashion-MNIST Data set comparison , The number of categories has increased 2.25 times (18/8). The experimental results in this section help to determine SWIL It can be applied to more complex data sets (CIFAR100) And neural network model (VGG19), The generalization of the algorithm is proved . At the same time, it is proved that expanding the internal distance between categories or increasing the number of non overlapping categories , It may further improve the learning speed and reduce the memory load .
Artificial neural networks face major challenges in continuous learning , Usually shows catastrophic interference . In order to overcome this problem , Many studies have used complete interlaced learning (FIL), That is, new and old content cross learning , Joint training network .FIL You need to interweave all existing information every time you learn new information , Make it a biologically implausible and time-consuming process . lately , There are studies that show that FIL It may not be necessary , Only interleave the old content that has substantial representational similarity with the new content , That is, using similarity weighted interlaced learning (SWIL) Methods can achieve the same learning effect . However , Someone is right. SWIL Has expressed concern about the scalability of . This paper extends SWIL Algorithm , And based on different data sets (Fashion-MNIST、CIFAR10 and CIFAR100) And neural network model ( Deep linear networks and CNN) It was tested . Under all conditions , Interlace learning with parts (PIL) comparison , Similarity weighted interlaced learning (SWIL) Staggered learning with equal rights (EqWIL) Better performance in learning new categories . This is in line with the expectations of the author team , Because compared with the old category ,SWIL and EqWIL Added the relative frequency of the new category . This paper also proves , Existing categories with equal subsampling ( namely EqWIL Method ) comparison , Careful selection and interweaving of similar content reduces catastrophic interference with similar old categories . In predicting new and existing categories ,SWIL Performance and FIL similar , But it significantly accelerates the speed of learning new content ( chart 7D), At the same time, the required training data is greatly reduced .SWIL You can learn new categories in the sequence learning framework , Its generalization ability is further proved . Last , Compared with many new categories that have similarities with old categories , If it overlaps less with the previously learned categories ( More distance ), It can shorten the integration time , And data efficiency is higher . On the whole , The experimental results provide a possible insight , That is, the brain actually reduces unrealistic training time , Overcome the primitive CLST A major weakness of the model . Link to the original text :原网站版权声明
本文为[Zhiyuan community]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/185/202207041840466031.html