当前位置:网站首页>关于联邦学习和激励的相关概念(1)
关于联邦学习和激励的相关概念(1)
2022-07-04 18:37:00 【白速龙王的回眸】
论文标题:Incentive Mechanisms for Federated Learning: From Economic and Game Theoretic Perspective
联邦学习的激励机制设计:概念定义和动机
在FL的场景中,参与者可能不情愿参与没有补偿的训练因为这会导致它白白损失资源来训练模型以及承受隐私泄露的风险。同时,激励机制还可以减少信息不对称(server和worker)造成的负面影响。一个优秀的激励机制可能有以下特征:
激励可协调、可信:每个worker都可以获得最优的补偿,只要他们诚实地工作;也就是说,他们作恶的话是不会提高收益的
个人的合理性:也就是说worker参与FL的收益是非负的
账单平衡:对workers的总支付不会大于给定的预算
计算有效:在多项式时间内,激励机制可以完成worker的选举和奖励的分配
公平性:当预定义的公平方程(贡献公平)达到最值的时候,激励机制就可以达到公平。公平的激励机制可以最优地分配奖励
关于FL中激励机制的一些定义:
(p,c,r)
p:参与方,他们提供有用的训练资源
c:用来衡量每个worker的贡献的一个方法
r:基于c的,对每个worker给与奖励的方法
特别地,设计激励机制的目的就是worker的最优参与程度和最优的奖励来维系FL的可持续性
所以说,激励机制最为关键的就是贡献评估和奖励分配
贡献的评估
在FL中,如果能获取更高的奖励,自利的DO将会有更高的意愿加入FL;然而,这从另外一个角度来说,是对MO造成更大的财力消耗。因此,需要设计贡献评估来平衡一下。文献22展示了关于诚实DO的贡献、恶意DO的行为以及面向攻击的防御机制的分析;文献23采用了注意力机制来评估纵向FL中的DO的梯度贡献。这个方法,可以对每个DO进行实时贡献的衡量,拥有对数据数量和质量的高敏感度。文献24提出了一种基于逐步贡献计算的直觉贡献评价方法。文献25中,作者提出了一种基于强化学习的贡献评价方法。特别地,文献26提出了一种称作“基于peer预测的成对相关协议”在没有测试集的情况下评估FL中的用户贡献,它通过使用用户上传的**关于模型参数的统计相关性“来进行具体评估。
然而,22-24的方法都假设了一个前提,那就是有可信的中心server会诚实的计算每个DO的贡献,这个假设会缺失透明性然后会阻碍实际中FL的成功。为了解决这个问题,基于区块链的p2p支付系统(27-28)提出来支持通过共识协议并基于SV的利益分配来取代传统的第三方。同时,为了阻止恶意行为,29的作者提出了一种基于框架的评分规则来促使DO可信地上传他们地模型。
目前FL中贡献评估的主流策略可以分为以下几种:
- 基于贡献评估的自我报告:这是最直白的方式,这个就是DO主动地向MO报告自己贡献的资源。在这个场景下,有很多优势,例如计算资源的规模和数据规模(我认为是指DO自己统计会方便得多,但它本身仍有虚假报告的可能)
- 基于贡献评估的Shapley Value:这是一种考虑边缘的方法,它将DO的加入顺序的影响纳入考虑的范围,从而公平地统计它们的边缘影响。这个方法通常使用与”cooperatetive game” sv的定义如下:

这个式子表示的是在除去i的所有DO里面的平均边缘贡献,S代表的是在联盟N中不同的合作模式,v(s)是子集s共同训练出来的模型的效用,最近33-36阐述了这种边缘模型的提升 - 基于贡献评估的influence和reputation:一个worker的influence定义为它对FL模型的损失函数的贡献。通过模型或数据的更新,损失函数会得到提高。文献38提出了一个新颖的概念,Fed-Influnce,它主要是用来量化每个个体client的,而不是模型参数的,同时它可以在凸和非凸函数上有不错的表现。reputation机制主要是结合区块链来选举可靠的worker(39-42)。DO的reputation可以划分成直接的reputation和推荐的reputation,然后利用主观逻辑模型来计算。
奖励的分配
在评估完DO的贡献之后,MO应该要对DO分发奖励来留住和提高提供高质量数据DO的数量
- Offered奖励:这个方法考虑的是MO在DO结束训练之前就给予奖励,这里面奖励可以根据提供资源的质量(44),或通过投票(45)来决定
- payoff sharing:这个方法考虑的是Mo在Do完成任务之后再基于奖励。但是呢,这样的延迟支付会降低worker的积极性,19-20文献提出的payoff sharing可以动态分配既定的budget。这个方法的目标是解决一个value减少的regret移动的优化问题,可以达到贡献公平性、regert分布公平性,期望公平性等。
总结
在这一届中,我们对FL的训练过程、基本架构、优势进行介绍。此外,FL激励机制的基础也讨论了。例如,概念定义和动机。下一届我们展示一些基础的经济学和博弈论模型。
边栏推荐
- 上线首月,这家露营地游客好评率高达99.9%!他是怎么做到的?
- 1005 spell it right (20 points) (pat a)
- Creation of JVM family objects
- Functional interface
- Personal thoughts on Architecture Design (this article will be revised and updated continuously later)
- Anhui Zhong'an online culture and tourism channel launched a series of financial media products of "follow the small editor to visit Anhui"
- 为什么最大速度是光速
- kotlin 类和对象
- Huawei Nova 10 series supports the application security detection function to build a strong mobile security firewall
- HMM隐马尔可夫模型最详细讲解与代码实现
猜你喜欢

Pythagorean number law (any three numbers can meet the conditions of Pythagorean theorem)
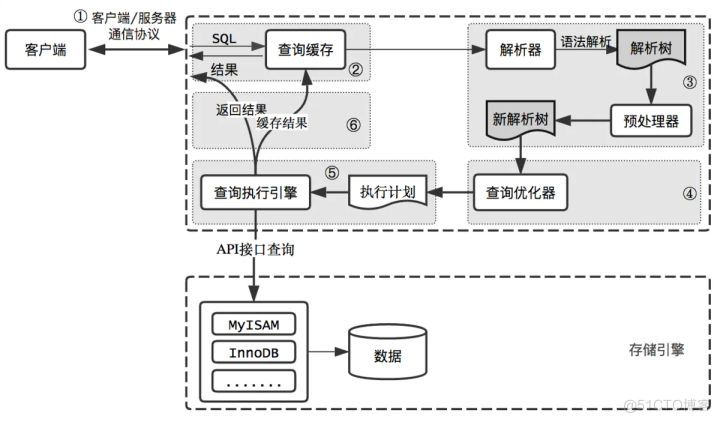
输入的查询SQL语句,是如何执行的?
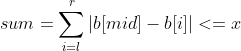
Abc229 summary (connected component count of the longest continuous character graph in the interval)
C # use stopwatch to measure the running time of the program

HMM hidden Markov model and code implementation
应用实践 | 蜀海供应链基于 Apache Doris 的数据中台建设
Niuke Xiaobai month race 7 who is the divine Archer
Cbcgpprogressdlg progress bar used by BCG
Swagger suddenly went crazy

线上数据库迁移的几种方法

随机推荐
1003 emergency (25 points) (PAT class a)
需求开发思考
New wizard effect used by BCG
Educational codeforces round 22 E. Army Creation
为什么最大速度是光速
Double colon function operator and namespace explanation
What does the neural network Internet of things mean? Popular explanation
更强的 JsonPath 兼容性及性能测试之2022版(Snack3,Fastjson2,jayway.jsonpath)
Specify the character set to output
Educational Codeforces Round 22 E. Army Creation
原来这才是 BGP 协议
kotlin 继承
Anhui Zhong'an online culture and tourism channel launched a series of financial media products of "follow the small editor to visit Anhui"
解密函数计算异步任务能力之「任务的状态及生命周期管理」
ACM组合计数入门
华为nova 10系列支持应用安全检测功能 筑牢手机安全防火墙
PHP pseudo original API docking method
Socket programming demo II
Multi table operation inner join query
做社交媒体营销应该注意些什么?Shopline卖家的成功秘笈在这里!