当前位置:网站首页>Spark数据读取和创建
Spark数据读取和创建
2022-08-02 03:28:00 【Code_LT】
ss表示sparksession
sc表示sparkContext
//Spark 配置代码(2.0 之前的版本):
import org.apache.spark._
val conf = new SparkConf().setAppName("applicationName").setMaster("local") // 本地环境运行
val sc = new SparkContext(conf)
val sq= new org.apache.spark.sql.SQLContext(sc)
//2.0之后
import org.apache.spark.sql.SparkSession
val ss = SparkSession.builder().enableHiveSupport().getOrCreate()
val sc = ss.sparkContext
val sq=ss.sqlContext
从简单数据创建
创建rdd
//parallelize[T](seq : scala.Seq[T], numSlices : scala.Int): RDD[T] = { /* compiled code */ }
//numSlices 为分区数,如果不填,Spark会尝试根据集群的状况,来自动设定slices的数目
val ar=Array( (8, "bat"),(64, "mouse"),(-27, "horse"))
val r1=sc.parallelize(ar)
创建dataframe
//引入隐式转换,使toDF()函数生效
import sq.implicits._
//从Seq创建
val someDF = ar.toSeq.toDF("number", "word")
//从RDD创建
r1.toDF()
//RDD+case class创建,这种方法的好处在于可以指定数据类型
// Define the schema using a case class.
// Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit,
// you can use custom classes that implement the Product interface.
case class Book(word: String, number: Int)
// Create an RDD of Person objects and register it as a table.
val people = r1.map(p => Book(p(0), p(1)))//转为元素为Person的RDD
.toDF()//转换为Dataframe
通过 creatDataFrame()函数创建,主要好处在于可定制schema,包括nullable标志
creatDataFrame()共有7种重载方式:
def createDataFrame[A<: scala.Product](rdd : RDD[A]):DataFrame
def createDataFrame[A<: scala.Product](data : scala.Seq[A]): DataFrame
//多了一个StructType参数指定Schema,要求输入为RDD[Row]
def createDataFrame(rowRDD : RDD[Row], schema : StructType) : DataFrame
//另外还有以下几种方法,少用,省略。
private[sql] def createDataFrame(rowRDD : org.apache.spark.rdd.RDD[org.apache.spark.sql.Row], schema : StructType, needsConversion : scala.Boolean) : DataFrame
def createDataFrame(rowRDD : JavaRDD[Row], schema : StructType) : DataFrame
def createDataFrame(rdd : RDD[_], beanClass : scala.Predef.Class[_]) :DataFrame
def createDataFrame(rdd : JavaRDD[_], beanClass : scala.Predef.Class[_]) :DataFrame
示例:
val someData = Seq(
Row(8, "bat"),
Row(64, "mouse"),
Row(-27, "horse")
)
val someSchema = List(
StructField("number", IntegerType, true),
StructField("word", StringType, true)
)
val someDF = spark.createDataFrame(
spark.sparkContext.parallelize(someData),
StructType(someSchema)
)
df的schema展示:
df.printSchema()
df.schema.printTreeString() //等效
从外部数据创建
创建rdd
/** * Read a text file from HDFS, a local file system (available on all nodes), or any * Hadoop-supported file system URI, and return it as an RDD of Strings. */
def textFile(path: String,minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],minPartitions).map(pair => pair._2.toString).setName(path)
}
分析参数:
path: String 是一个URI,這个URI可以是HDFS、本地文件(全部的节点都可以),或者其他Hadoop支持的文件系统URI返回的是一个字符串类型的RDD,也就是是RDD的内部形式是Iterator[(String)]
minPartitions= math.min(defaultParallelism, 2) 是指定数据的分区,如果不指定分区,当你的核数大于2的时候,不指定分区数那么就是 2。当你的数据大于128M时候,Spark是为每一个快(block)创建一个分片(Hadoop-2.X之后为128M一个block)
val rdd = sc.textFile(“/home/hadoop/data.txt”)
//SparkSession版本 Spark 2.0及以上
val dataRDD1 = ss.read.csv("path/of/csv/file").rdd //读取csv 文件
val dataRDD2 = ss.read.json("path/of/json/file").rdd //读取json 文件
val dataRDD3 = ss.read.textFile("path/of/text/file").rdd//读取text文件
创建DataFrame
//SparkSession版本 Spark 2.0及以上
val df1 = ss.read.csv("path/of/csv/file")//读取csv 文件
val df2 = ss.read.json("path/of/json/file")//读取json 文件
val df3 = ss.read.textFile("path/of/text/file")//读取text文件
边栏推荐
- Two-Stream Convolutional Networks for Action Recognition in Videos双流网络论文精读
- 深入了解为何面试官常说:你还没准备好,我不会录用你
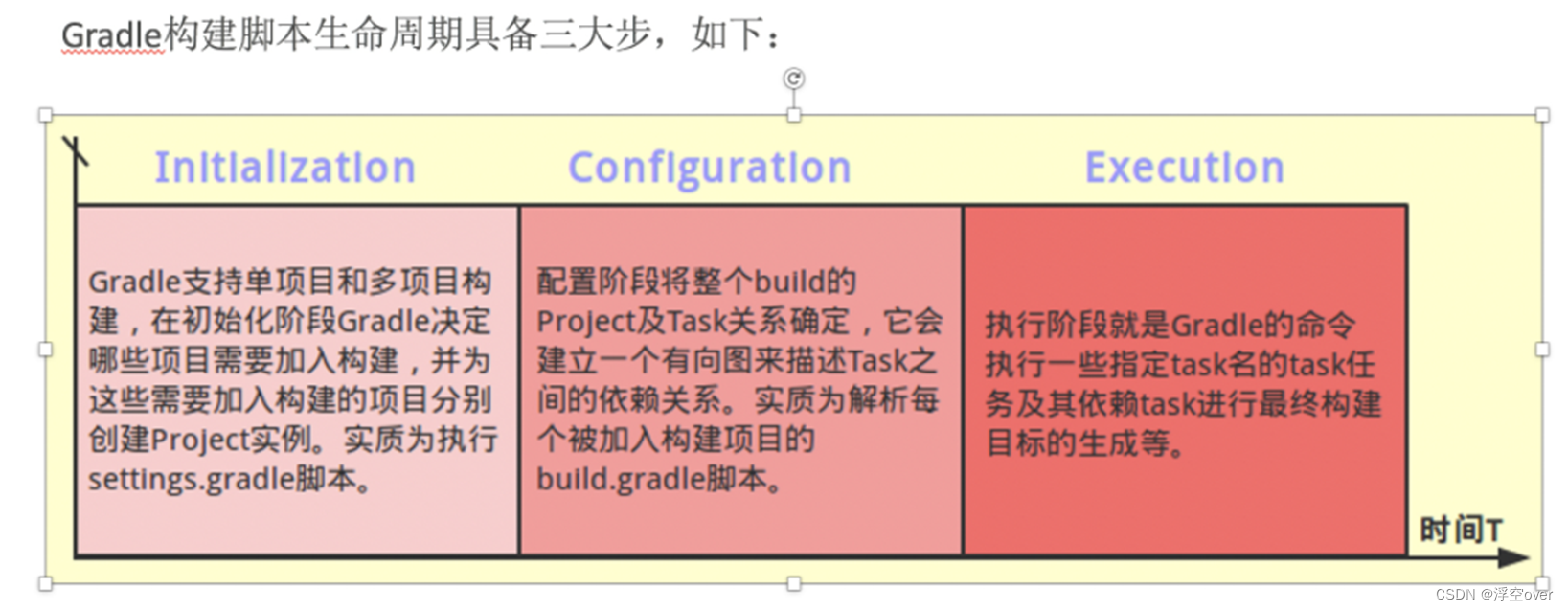
- gradle脚本中groovy语法讲解
- 【opencv】error: (-215:Assertion failed) ssize.empty() in function ‘cv::resize‘报错原因
- 属性动画的使用和原理解析
- PAT甲级:1020 Tree Traversals
- 对账、结账、错账更正方法、划线更正法、红字更正法、补充登记法
- 蓝桥杯:国二选手经验贴 附蓝桥杯历年真题
- 从Attention到Self-Attention和Multi-Head Attention
- Binder机制详解(二)
猜你喜欢

zsh: command not found: xxx 解决方法

浅谈性能优化:APP的启动流程分析与优化
深入了解为何面试官常说:你还没准备好,我不会录用你
gradle脚本中groovy语法讲解
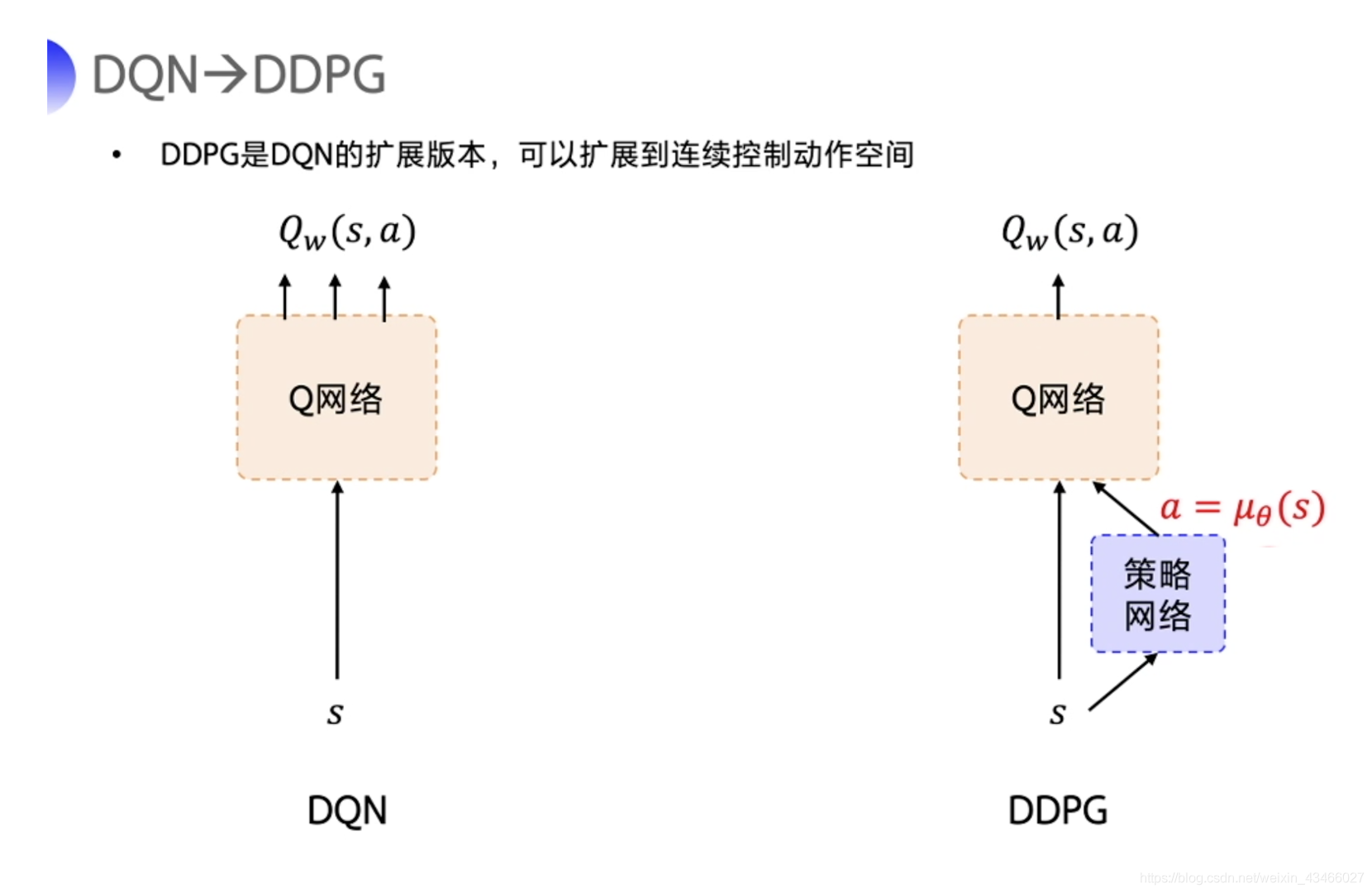
强化学习笔记:DDPG

Two-Stream Convolutional Networks for Action Recognition in Videos双流网络论文精读
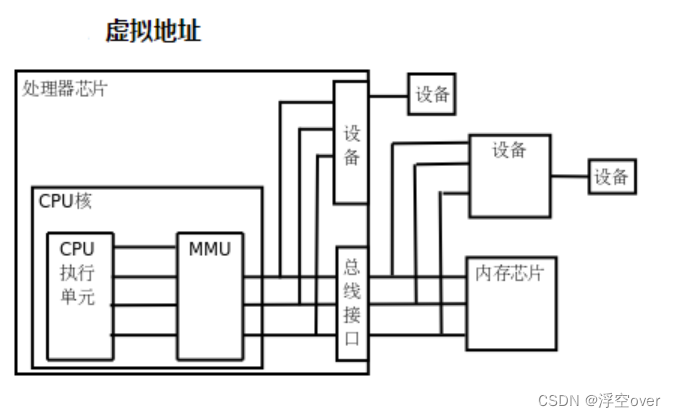
Binder机制详解(二)
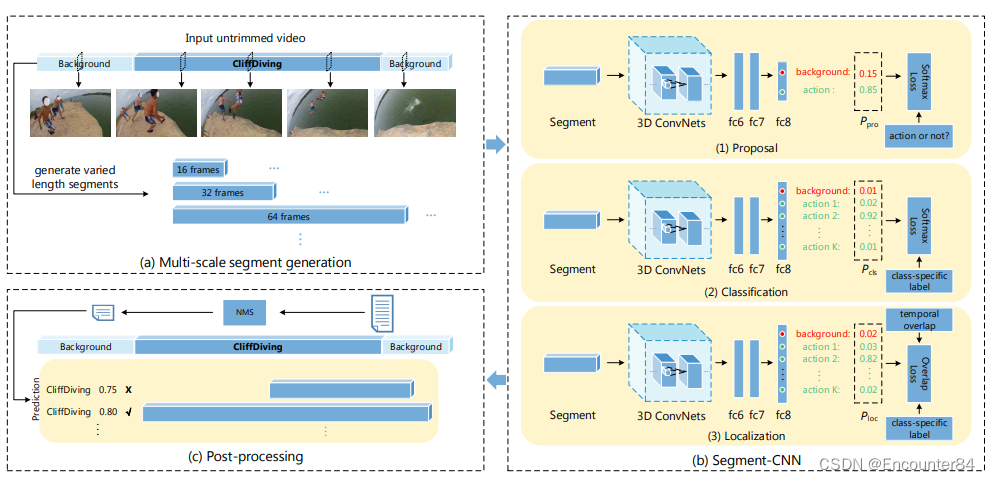
Temporal action localization in untrimmed videos via Multi-stage CNNs SCNN论文阅读笔记
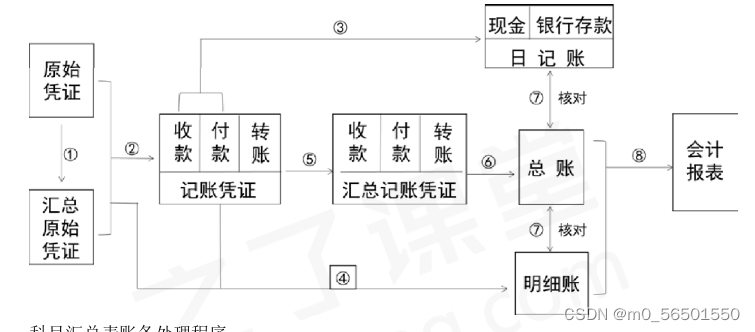
账务处理程序、记账凭证账务处理程序、汇总记账凭证账务处理程序、科目汇总表账务处理程序、会计信息化概述、信息化环境下会计账务处理的基本要求(此章出1道小题)
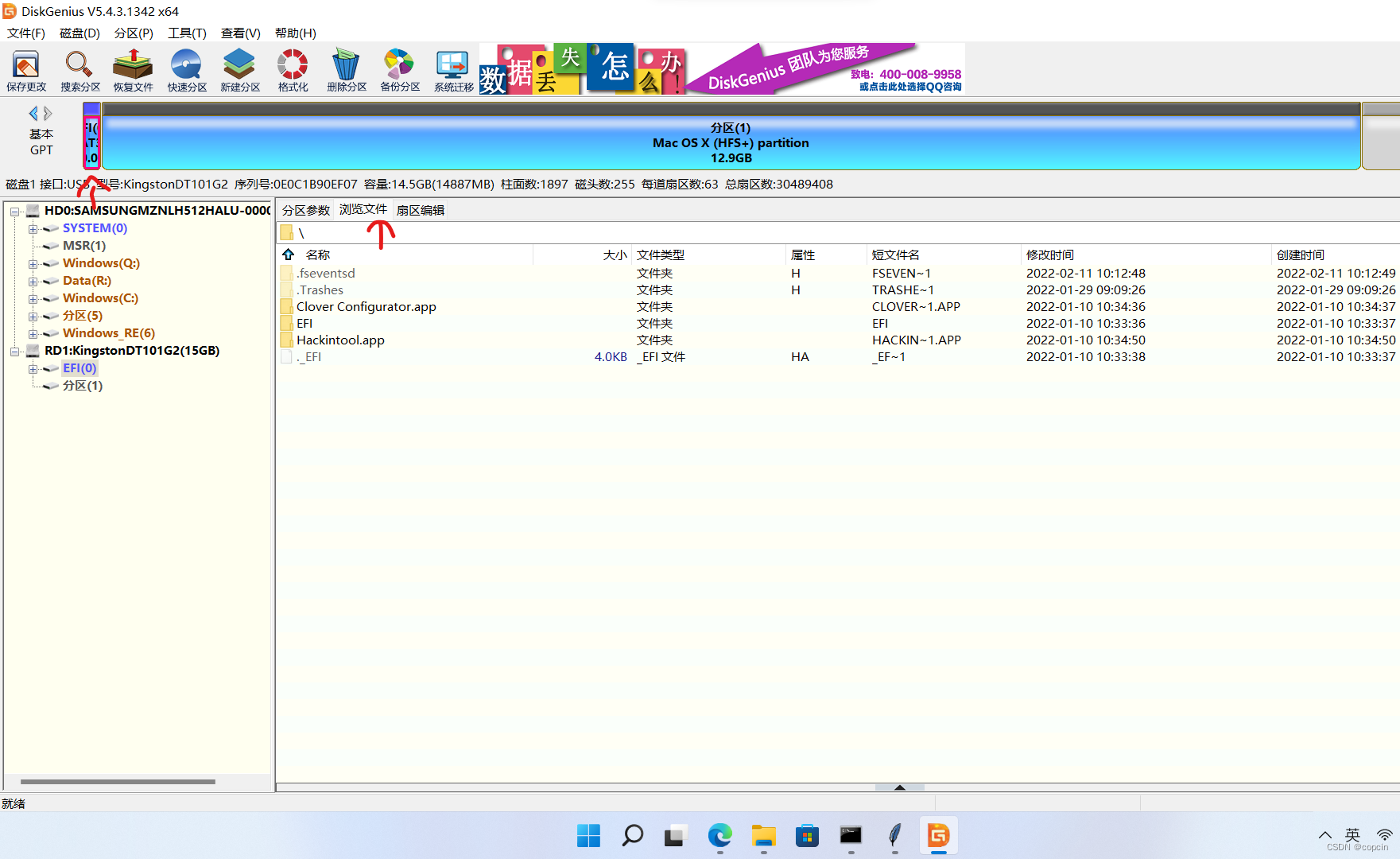
OpenCore 黑苹果安装教程
随机推荐
学IT,找工作——移除链表元素
深度学习理论:model.fit 函数参数详解
VS2017报错:LNK1120 1 个无法解析的外部命令
记账凭证的种类、记账凭证的基本内容、记账凭证的填制要求、记账凭证的审核
借贷记账法下的账户结构、借贷记账法的记账规则、借贷记账法下的账户对应关系与会计分录
功能强大的黑科技网站--10连
帧动画和补间动画的使用
广告电商「私域打工人」职业前景:你离月薪6万,还差多远?
如何在正则表达式里表达可能存在也可能不存在的内容?
还原最真实、最全面的一线大厂面试题
关于我的项目-微信公众号~
云安全笔记:云原生全链路加密
laravel-admin 线上访问项目,一直重定向到登录页面
php的curl函数模拟post数据提交,速度非常慢
如何一步一步的:玩转全民拼购!
一分钟get:缓存穿透、缓存击穿、缓存雪崩
张量乘积—实验作业
electron-builder打包不成功解决方法
centos8 安装搭建php环境
ffmpeg 有声视频合成背景音乐(合成多声音/合成多音轨)