当前位置:网站首页>BSN:Boundary-Sensitive Network for Temporal Action Proposal Generation论文阅读笔记
BSN:Boundary-Sensitive Network for Temporal Action Proposal Generation论文阅读笔记
2022-08-02 03:28:00 【Encounter84】
论文链接:http://arxiv.org/abs/1806.02964
论文源码:https://github.com/wzmsltw/BSN-boundary-sensitive-network
原作者解析:https://zhuanlan.zhihu.com/p/39327364
简介
BSN使用local to global局部到全局的方式生成高质量的proposal,首先通过局部连接的方式组合具有高置信度的开始和结束位置,构成可能的proposal,然后使用proposal-level特征全局检索过滤高置信度的proposal,BSN算法一共有三步:
1:BSN在视频片段的每个时间位置都预测输出当前时间点属于一个动作的开始概率、结束概率,以及当前时间点属于某个动作的概率,生成一个<start prob, end prob, action prob>的时间序列作为局部信息。
2:使用自下而上的方式直接组合具有高预测概率值的开始点(如下图中红色实线的2个峰值点)和结束点(如下图中蓝色虚线的1个峰值点),从而可以生成不同长度不同边界准确性的proposal(如下图中2个开始点和1个结束点组成2个可能的proposal)。
3:BSN利用proposal内部和周围的action prob组成的特征,通过评估proposal是否包含action的置信度来进一步从step 2的输出结果中检索具有高置信度的proposal。这些proposal-level的特征为更好的评估提供了全局信息。
问题描述
视频定义为: X = { x n } n = 1 l v X=\left\{x_{n}\right\}_{n=1}^{l_{v}} X={ xn}n=1lv, x n x_n xn表示视频某一帧, l v l_v lv表示视频的帧数。
视频中动作的GT定义为: Ψ g = { φ n = ( t s , n , t e , n ) } n = 1 N g \Psi_{g}=\left\{\varphi_{n}=\left(t_{s, n}, t_{e, n}\right)\right\}_{n=1}^{N_{g}} Ψg={ φn=(ts,n,te,n)}n=1Ng,其中 φ n \varphi_{n} φn 表示视频中的一个动作片段, t s , n , t e , n t_{s, n}, t_{e, n} ts,n,te,n 分别表示动作片段的开始位置和结束位置, N a N_{a} Na 表示视频中包含的标注动作GT的数量。
视频特征提取
BSN算法中使用Two-Stream双流网络提取视频特征,双流网络一路提取图像的空间特征,一路提取光流的时序运动特征。在视频片段的每个位置提取图像特征和光流特征,表示如下:
s n = { x t n , o t n } n = 1 l v s_{n}=\left\{x_{t_{n}}, o_{t_{n}}\right\}_{n=1}^{l_{v}} sn={ xtn,otn}n=1lv
其中, x t n x_{t_{n}} xtn 表示视频中的第 t \mathrm{t} t 帧图像, o t n o_{t_{n}} otn 表示以视频第 t \mathrm{t} t 帧图像为中心的连续图像计算的光流,然后将 x t n x_{t_{n}} xtn 和 o t n o_{t_{n}} otn 分别输入到Two-stream双流网络提取特征,然后将双流网络的两路输出特征进行concat融合得到 f t n f_{t_{n}} ftn ,对视频的每个时间位置都计算得到 x t n x_{t_{n}} xtn 和 o t n o_{t_{n}} otn ,并提取特征 f t n , f_{t_{n} \text { , }} ftn , 从而得到视频的时序特征 F = { f t n } n = 1 l v F=\left\{f_{t_{n}}\right\}_{n=1}^{l_{v}} F={ ftn}n=1lv算法在进行视频特征提取时,为了降低计算量,采用步长为 σ \sigma σ 的间隔采样,所以采样的特征序列总帧数为 l s = l v / σ l_{s}=l_{v} / \sigma ls=lv/σ 。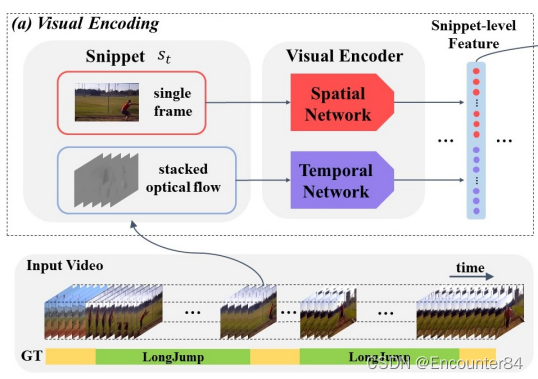
论文代码整体采用分阶段训练的方法,运行顺序如下:
python main.py --module TEM --mode train
python main.py --module TEM --mode inference
python main.py --module PGM
python main.py --module PEM --mode train
python main.py --module PEM --mode inference --pem_batch_size 1
python main.py --module Post_processing
python main.py --module Evaluation
对特征进行缩放:
def resizeFeature(inputData,newSize):
# inputX: (temporal_length,feature_dimension) #
originalSize=len(inputData)
#print originalSize
if originalSize==1:
inputData=np.reshape(inputData,[-1])
return np.stack([inputData]*newSize)
x=numpy.array(range(originalSize))
f=scipy.interpolate.interp1d(x,inputData,axis=0)
x_new=[i*float(originalSize-1)/(newSize-1) for i in range(newSize)]
y_new=f(x_new)
return y_new
BSN算法主要模块
1.Temporal Evaluation Module(TEM)
TEM是一个三层的时序卷积网络,网络的输入是上一步视频特征编码中使用双流网络提取的时序特征,然后TEM预测输入的时序特征每个时序位置是一个动作开始点的概率,结束点的概率,以及这个时序位置属于一个动作的概率,从而输出starting开始点的时序概率,ending结束点的时序概率,以及每个点是否属于一个动作的时序概率,starting、ending以及action的概率预测都是二分类问题。网络结构是Conv(512; 3; Relu) -> Conv(512; 3; Relu) -> Conv(3; 1; Sigmoid),最终输出3通道表示计算3个概率值。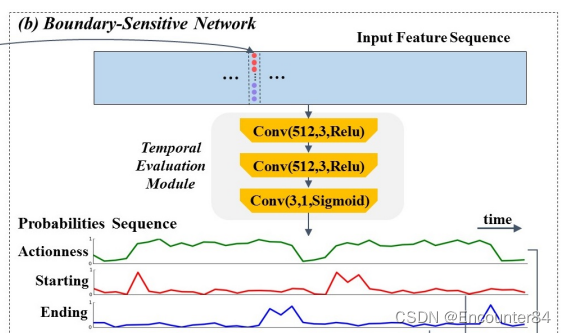
输入:通过Visual Encoding得到的特征序列如上图蓝色矩形框所示,每个窗口提取到的特征大小为(100,400),记作 F w F_w Fw。对于ActivityNet数据集而言,可以认为每个视频包含一个窗口;而对于THUMOS14,每个视频包含多个窗口。
结构:Temporal Evaluation Module(TEM)由三个卷积和Sigmoid组成
class TEM(torch.nn.Module):
def __init__(self, opt):
super(TEM, self).__init__()
self.feat_dim = opt["tem_feat_dim"]
self.temporal_dim = opt["temporal_scale"]
self.batch_size= opt["tem_batch_size"]
self.c_hidden = opt["tem_hidden_dim"]
self.tem_best_loss = 10000000
self.output_dim = 3
self.conv1 = torch.nn.Conv1d(self.feat_dim,self.c_hidden,
kernel_size=3,stride=1,padding=1,groups=1)
self.conv2 = torch.nn.Conv1d(self.c_hidden,self.c_hidden,
kernel_size=3,stride=1,padding=1,groups=1)
self.conv3 = torch.nn.Conv1d(self.c_hidden,self.output_dim,
kernel_size=1,stride=1,padding=0)
self.reset_params()
@staticmethod
def weight_init(m):
if isinstance(m, nn.Conv2d):
init.xavier_normal(m.weight)
init.constant(m.bias, 0)
def reset_params(self):
for i, m in enumerate(self.modules()):
self.weight_init(m)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = torch.sigmoid(0.01*self.conv3(x))
return x
loss函数:
def bi_loss(scores,anchors,opt):
scores = scores.view(-1).cuda()
anchors = anchors.contiguous().view(-1)
pmask = (scores>opt["tem_match_thres"]).float().cuda()
num_positive = torch.sum(pmask)
num_entries = len(scores)
ratio=num_entries/num_positive
coef_0=0.5*(ratio)/(ratio-1) # 负样本系数
coef_1=coef_0*(ratio-1) # 正样本系数
loss = coef_1*pmask*torch.log(anchors+0.00001) + coef_0*(1.0-pmask)*torch.log(1.0- anchors+0.00001)
loss=-torch.mean(loss)
num_sample=[torch.sum(pmask),ratio]
return loss, num_sample
2.Proposal Generation Module(PGM)
PGM组合TEM模块输出的具有高置信度概率值的starting开始点和ending结束点,生成可能的proposal片段,然后基于各个proposal中各个时间序列位置的动作概率构造BSP特征。根据starting序列概率选择开始时间点:选择 p t n s > 0.9 p_{t_{n}}^{s}>0.9 ptns>0.9 的点或者峰值点 p t n s > p t n − 1 s p_{t_{n}}^{s}>p_{t_{n-1}}^{s} ptns>ptn−1s and p t n s > p t n + 1 s p_{t_{n}}^{s}>p_{t_{n+1}}^{s} ptns>ptn+1s (比两边都大的凸起点)。Ending时间点采用同样的方式选择。将上一步选择出的开始时间点和结束时间点进行两两组合,并且组合的 [ t s , t e ] \left[t_{s}, t_{e}\right] [ts,te] 时间点满足设置的视频最大和最小参数, d = t e − t s ∈ [ d min , d max ] 其中 d min , d max d=t_{e}-t_{s} \in\left[d_{\min }, d_{\max }\right] 其中 d_{\min }, d_{\max } d=te−ts∈[dmin,dmax]其中dmin,dmax是训练集中标注的动作GT的最大和最小长度大小。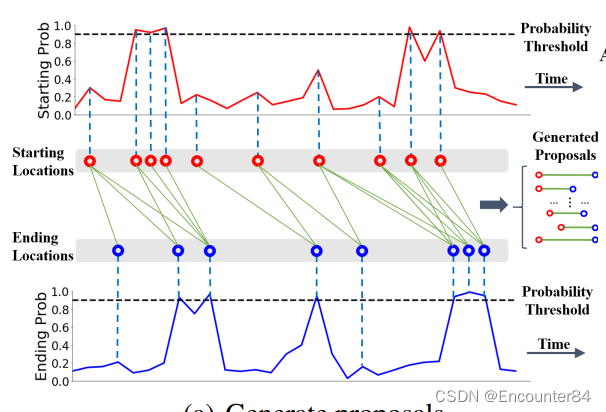
tscale = opt["temporal_scale"] # 100
tgap = 1./tscale # 0.01
peak_thres= opt["pgm_threshold"]
max_start = max(start_scores)
start_bins=numpy.zeros(len(start_scores))
start_bins[[0,-1]]=1
for idx in range(1,tscale-1):
if start_scores[idx]>start_scores[idx+1] and start_scores[idx]>start_scores[idx-1]:
tart_bins[idx]=1
elif start_scores[idx]>(peak_thres*max_start):
start_bins[idx]=1
for j in range(tscale):
if start_bins[j]==1:
xmin_list.append(tgap/2+tgap*j)
xmin_score_list.append(start_scores[j])
new_props=[]
for ii in range(len(xmax_list)):
tmp_xmax=xmax_list[ii]
tmp_xmax_score=xmax_score_list[ii]
for ij in range(len(xmin_list)):
tmp_xmin=xmin_list[ij]
tmp_xmin_score=xmin_score_list[ij]
if tmp_xmin>=tmp_xmax:
break
new_props.append([tmp_xmin,tmp_xmax,tmp_xmin_score,tmp_xmax_score])
new_props=numpy.stack(new_props)
3.Proposal特征提取
上一步提取的候选proposal表示为 [ t s , t e ] \left[t_{s}, t_{e}\right] [ts,te] ,将 t s , t e t_{s}, t_{e} ts,te 之间的片段定义为中间区域 r C r_{C} rC ,将以 t s t_{s} ts 为中心的 [ t s − d / 5 , t s + d / 5 ] \left[t_{s}-d / 5, t_{s}+d / 5\right] [ts−d/5,ts+d/5] 片段定义为 r S r_{S} rS ,将以 t e t_{e} te 为中心的 [ t e − d / 5 , t e + d / 5 ] \left[t_{e}-d / 5, t_{e}+d / 5\right] [te−d/5,te+d/5] 片段定义为 r E r_{E} rE 。在 r C r_{C} rC 片段内的动作概率序列 P A P_{A} PA 上采用线型插值方式均匀采样16个特征点得到 f C A f_{C}{ }^{A} fCA ,在 r S r_{S} rS 和 r E r_{E} rE 片段内的动作概率序列 P A P_{A} PA 上采用线型插值方式分别均匀采样8个特征点得到 f S A f_{S}^{A} fSA 和 f E A f_{E}^{A} fEA 。将采样的特征点进行 concat得到这个proposal的BSP特征 f B S P A = ( f S A , f C A , f E A ) f_{B S P}^{A}=\left(f_{S}^{A}, f_{C}^{A}, f_{E}^{A}\right) fBSPA=(fSA,fCA,fEA).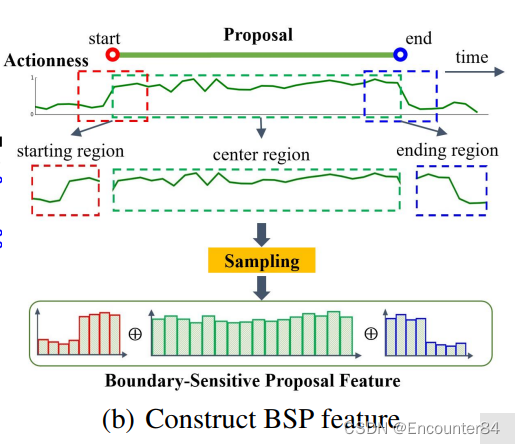
# num_sample_start: 8
# num_sample_interpld: 3
for video_name in video_list:
adf=pandas.read_csv("./output/TEM_results/"+video_name+".csv")
score_action=adf.action.values[:]
seg_xmins = adf.xmin.values[:]
seg_xmaxs = adf.xmax.values[:]
video_scale = len(adf) # video_scale: 100
video_gap = seg_xmaxs[0] - seg_xmins[0] # video_gap: 0.01
video_extend = video_scale / 4 + 10 # video_extend: (100/4)+10 = 35
pdf=pandas.read_csv("./output/PGM_proposals/"+video_name+".csv")
video_subset = video_dict[video_name]['subset']
# 取分数前top_k的proposals
if video_subset == "training":
pdf=pdf[:opt["pem_top_K"]]
else:
pdf=pdf[:opt["pem_top_K_inference"]]
# 对于每个window,原有100个时间位置,每个位置的值为动作发生的概率score_action
# 现再在左右两边各再取35个时间位置,这些位置的值设为0
# 每两个位置之间的距离为video_gap: 0.01
tmp_zeros=numpy.zeros([video_extend])
score_action=numpy.concatenate((tmp_zeros,score_action,tmp_zeros))
tmp_cell = video_gap
tmp_x = [-tmp_cell/2-(video_extend-1-ii)*tmp_cell for ii in range(video_extend)]\
+ [tmp_cell/2+ii*tmp_cell for ii in range(video_scale)] \
+ [tmp_cell/2+seg_xmaxs[-1] +ii*tmp_cell for ii in range(video_extend)]
`# 利用得到的170(35+100+35)个时间位置的值,来生成插值函数
f_action=interp1d(tmp_x,score_action,axis=0)
feature_bsp=[]
# 以Start为例
for idx in range(len(pdf)):
xmin=pdf.xmin.values[idx]
xlen=xmax-xmin
xmin_0=xmin-xlen * opt["bsp_boundary_ratio"] # 往前5/d
xmin_1=xmin+xlen * opt["bsp_boundary_ratio"] # 往后5/d
plen_start= (xmin_1-xmin_0)/(num_sample_start-1)
plen_sample = plen_start / num_sample_interpld
# 取25(2+21+2)个位置,应用于插值函数
tmp_x_new = [xmin_0 - plen_start/2 + plen_sample * ii for ii in \
range(num_sample_start*num_sample_interpld +1 )]
tmp_y_new_start_action=f_action(tmp_x_new)
# 最后得到8个位置的值:由邻近4个位置的值平均而来
tmp_y_new_start = [numpy.mean(tmp_y_new_start_action[ii*num_sample_interpld: \
: (ii+1)*num_sample_interpld+1]) for ii in range(num_sample_start) ]
4.Porposal Evaluation Module(PEM)
PEM使用多层感知机(多个全连接层)对PGM中每个候选proposal提取的BSP特征进行处理,得到候选proposal与GT的重合置信度。到目前为止,一个候选proposal就可以被表示为下式:
φ = ( [ t s , t e , p conf , p t s S , p t e E ) \varphi=\left(\left[t_{s}, t_{e}, p_{\text {conf }}, p_{t_{s}}^{S}, p_{t_{e}}^{E}\right)\right. φ=([ts,te,pconf ,ptsS,pteE)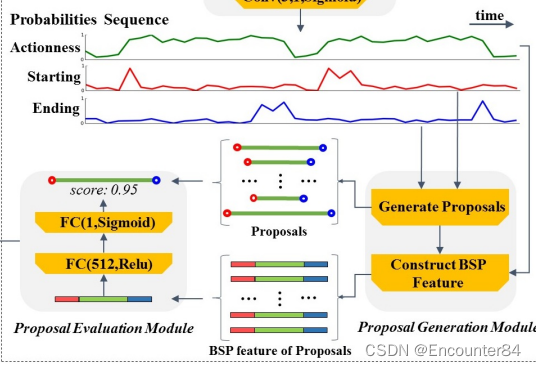
class PEM(torch.nn.Module):
def __init__(self,opt):
super(PEM, self).__init__()
self.feat_dim = opt["pem_feat_dim"]
self.batch_size = opt["pem_batch_size"]
self.hidden_dim = opt["pem_hidden_dim"]
self.u_ratio_m = opt["pem_u_ratio_m"]
self.u_ratio_l = opt["pem_u_ratio_l"]
self.output_dim = 1
self.pem_best_loss = 1000000
self.fc1 = torch.nn.Linear(self.feat_dim,self.hidden_dim,bias =True)
self.fc2 = torch.nn.Linear(self.hidden_dim,self.output_dim,bias =True)
self.reset_params()
@staticmethod
def weight_init(m):
if isinstance(m, nn.Conv2d):
init.xavier_uniform_(m.weight)
#init.xavier_normal(m.weight)
init.constant(m.bias, 0)
def reset_params(self):
for i, m in enumerate(self.modules()):
self.weight_init(m)
def forward(self, x):
x = F.relu(0.1*self.fc1(x))
x = torch.sigmoid(0.1*self.fc2(x))
return x
loss函数:
# pem_high_iou_thres: 0.6
# pem_low_iou_thres: 0.2
# u_ratio_m: 1
# u_ratio_l: 2
def PEM_loss_function(anchors_iou,match_iou,model,opt):
# 以match_iou=[0.4890, 0.0153, 0.5374, 0.8511, 0.9382,
# 0.1263, 0.4237, 0.0066, 0.3167, 0.3318]为例
match_iou = match_iou.cuda()
anchors_iou = anchors_iou.view(-1)
# u_hmask = [0., 0., 0., 1., 1., 0., 0., 0., 0., 0.]
u_hmask = (match_iou>opt["pem_high_iou_thres"]).float() # 正样本
# u_mmask = [1., 0., 1., 0., 0., 0., 1., 0., 1., 1.]
u_mmask = ((match_iou<=opt["pem_high_iou_thres"]) &
(match_iou>opt["pem_low_iou_thres"])).float() # 中间样本
# u_lmask = [0., 1., 0., 0., 0., 1., 0., 1., 0., 0.]
u_lmask = (match_iou<opt["pem_low_iou_thres"]).float() # 负样本
num_h=torch.sum(u_hmask) # 正样本数目:num_h=2
num_m=torch.sum(u_mmask) # 中间样本数目:num_m=5
num_l=torch.sum(u_lmask) # 负样本数目:num_l=3
# 以r_m为概率采样中间样本:
r_m= model.module.u_ratio_m * num_h/(num_m) # r_m=2*(2/5)=0.8
# 当正样本超过一定数目时,不再对中间样本进行采样,直接使用全部(r_m=1)。
r_m = torch.min(r_m, torch.Tensor([1.0]).cuda())[0] # r_m=min(0.8, 1)=0.8
# u_smmask=[0.8191, 0.8104, 0.0694, 0.7527, 0.4372,
# 0.1732, 0.1638, 0.4316, 0.4844, 0.9130]
u_smmask = torch.Tensor(np.random.rand(u_hmask.size()[0])).cuda()
# u_smmask=[0.8191, 0.0000, 0.0694, 0.0000, 0.0000,
# 0.0000, 0.1638, 0.0000, 0.4844, 0.9130]
u_smmask=u_smmask*u_mmask
# u_smmask=[1., 0., 0., 0., 0., 0., 0., 0., 1., 1.]
u_smmask = (u_smmask > (1. -r_m)).float()
# 同理,以r_l为概率采样负样本(过程略)
r_l= model.module.u_ratio_l * num_h/(num_l)
r_l=torch.min(r_l, torch.Tensor([1.0]).cuda())[0]
u_slmask = torch.Tensor(np.random.rand(u_hmask.size()[0])).cuda()
u_slmask=u_slmask*u_lmask
u_slmask=(u_slmask > (1. -r_l)).float()
# 经过这样处理后,样本基本平衡
# u_hmask = [0., 0., 0., 1., 1., 0., 0., 0., 0., 0.]
# u_ssmask = [1., 0., 0., 0., 0., 0., 0., 0., 1., 1.]
# u_smmask = [0., 1., 0., 0., 0., 0., 0., 1., 0., 0.]
# iou_weights = [1., 1., 0., 1., 1., 0., 0., 1., 1., 1.]
iou_weights=u_hmask+u_smmask+u_slmask
# 使用smooth_l1_loss
iou_loss = F.smooth_l1_loss(anchors_iou, match_iou)
# 只考虑被采样到的样本的loss
iou_loss = torch.sum(iou_loss * iou_weights) / torch.sum(iou_weights)
return iou_loss
5.结果后处理(Soft-NMS)
最后,作者需要对结果进行非极大化抑制,从而去除重叠的结果。具体而言,作者采用了soft-nms算法来通过降低分数的方式来抑制重叠的结果。处理后的结果即为BSN算法最终生成的时序动作提名。
while len(tscore)>0 and len(rscore)<=opt["post_process_top_K"]: # 保留前K个结果
# 选择当前分数最高的proposal
max_index=np.argmax(tscore)
tmp_width = tend[max_index] -tstart[max_index]
# 将当前分数最高的proposal与其他所有proposal一一计算IoU:
iou_list = iou_with_anchors(tstart[max_index],tend[max_index],
tmp_width,np.array(tstart),np.array(tend))
# 采用高斯函数形式计算衰减系数
iou_exp_list = np.exp(-np.square(iou_list)/opt["soft_nms_alpha"])
for idx in range(0,len(tscore)):
if idx!=max_index:
tmp_iou = iou_list[idx]
# 但IoU满足一定的阈值条件时才将分数乘上衰减系数,否则不变。
if tmp_iou>opt["soft_nms_low_thres"] +
(opt["soft_nms_high_thres"] - opt["soft_nms_low_thres"]) * tmp_width:
tscore[idx]=tscore[idx]*iou_exp_list[idx]
# 将当前分数最高的proposal添加到新集合中,并从旧集合中删除,完成一次循环。
rstart.append(tstart[max_index])
rend.append(tend[max_index])
rscore.append(tscore[max_index])
tstart.pop(max_index)
tend.pop(max_index)
tscore.pop(max_index)
参考网址:
1.https://zhuanlan.zhihu.com/p/442708903
2.https://blog.csdn.net/cxx654/article/details
边栏推荐
猜你喜欢
张量乘积—实验作业

The first time to tear the code by hand, how to solve the problem of full arrangement

树莓派4b安装win11/10过程全教程(附蓝屏inaccessible boot device解决办法)
![[Hello World教程] 使用HBuilder和Uni-app 生成一个简单的微信小程序DEMO](/img/98/7ad7fcee0deaaa92446098d1d99dc3.png)
[Hello World教程] 使用HBuilder和Uni-app 生成一个简单的微信小程序DEMO

深度学习理论:测试集与验证集的区别及各自用途
关于我的数学建模~

解密:链动2+1的商业模式

ontop-vkg 学习1

CSRF (Cross Site Request Forgery)
十大实用的办公工具网站,可以解决你日常100%的问题
随机推荐
SGDP(1)——猜数字游戏
uniapp发布到微信小程序:分包、删减代码全过程
重点考:从债劵的角度来看交易性金融资产
元宇宙是一个炒作的科幻概念,还是互联网发展的下半场?
修复APP的BUG,热修复的知识点和大厂的相关资料汇总
自定义ViewGroup实现搜索栏历史记录流式布局
laravel-admin FROM表单同行展示问题
The CTF introductory notes of SQL injection
2022年中高级 Android 大厂面试秘籍,为你保驾护航金九银十,直通大厂
Binder机制详解(一)
View的滑动
功能强大的黑科技网站--10连
php的curl函数模拟post数据提交,速度非常慢
VS2017报错:LNK1120 1 个无法解析的外部命令
同时安装VirtualBox和VMware,虚拟机如何上网
聊聊MySQL的10大经典错误
元宇宙:为何互联网大佬纷纷涉足?元宇宙跟NFT是什么关系?
RecyclerView使用和原理解析
pytorch:保存和加载模型
【泰山众筹】模式为什么一直都这么火热?是有原因的