当前位置:网站首页>学习基因富集工具DAVID(2)
学习基因富集工具DAVID(2)
2022-08-02 21:51:00 【黄思博呀】
DAVID提供的基因富集功能,主要是GO和KEGG分析:
GO(Gene Ontology GO)分析:
对上传的基因列表进行富集,从而找到和下面三类term相关的基因群:
细胞组分(Cellular Component BP):描述基因产物在细胞中的位置,例如内质网、细胞核、蛋白酶体
分子功能(Molecular Function MF):基因产物的功能,如酶的结合活性或催化活性
生物学过程(Biological Proccess BP):是指具有多个步骤的有序生物过程,细胞生长、分化、维持、凋亡以及信号传导过程。
KEGG Pathways富集分析
DAVID网页:DAVID: Functional Annotation Result Summary
完成了基因ID转换,点击①Start Analysis,返回Step2界面:
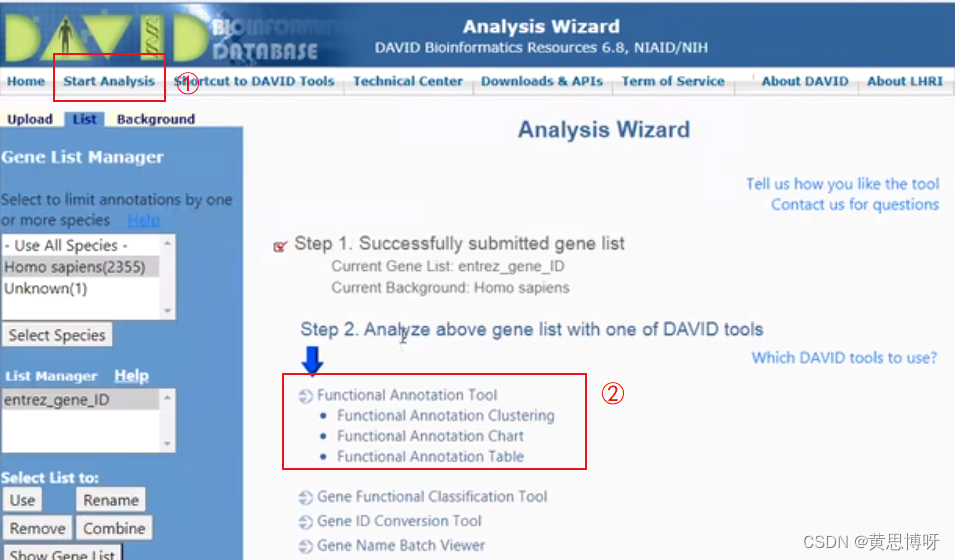
点击 ②Functional Annotation Tool(功能注释工具),进行基因富集分析
等待页面加载完毕,实际上已经完成了基因富集。

①Clear All 按钮,完成基因富集后,会自动勾选一些富集分析选项,例如GO分析会自动勾选BB,MF和BP三个富集分析;同时,Pathways会自动勾选KEGG库得到的通路富集分析,点击clear all 取消这些默认勾选
②Gene_Ontology 点击查看GO分析的富集结果
③Pathways 点击查看通路分析的富集结果(上传列表内的基因参与细胞内代谢、信号转导等通路的富集情况)
点击clear all -->点击Pathways-->勾选KEGG pathways-->点击下方的Functional Annotation Clustering 查看分析结果
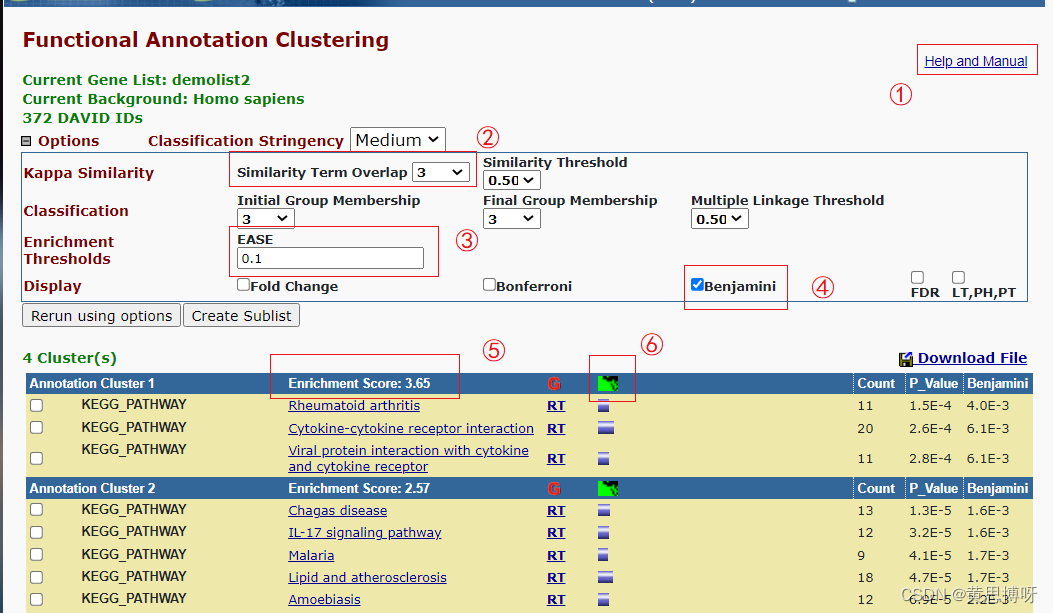
①help and Manual 点击查看详细的说明(比如ease 是如何计算的)
②Similarity Term Overlap 3 挑选出Count > 3的条目
③ EASE 0.1 选择EASE得分大于0.1的条目(EASE score 就是列表中的P Value)
④ Bebjamini 勾选后,在列表中显示结果Bebjamini算法校正后的P Value,勾选其他如FDR显示相关的校正P Value
⑤ Enrichment Score 富集倍数,由基因比率/背景比率得到
⑥ 点击查看该簇基因和相关通路相关性的热图,绿色表示被报道过相关性,黑色表示尚未被报道相关性
点击右上方的download file 可以下载该列表的txt格式
在Help and manual里讲解的EASE score的算法:
2.2. EASE Score, a Modified Fisher Exact P-value
计算原始P Value的算法:
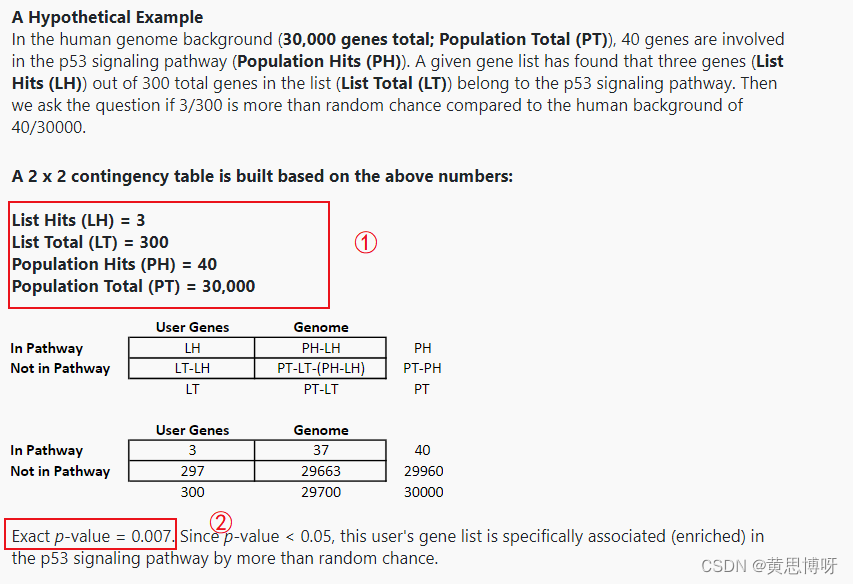
① List Total 是上传的list中带有功能注释的基因总数,Population Total是DAVID数据库内存储的带有功能注释的基因总数,List Hits 是在List Total中和这条Pathways有关的基因数目,Population Hits是在Population Total内和这条Pathways有关的基因数目。
用ease score算法计算校正后的P Value:
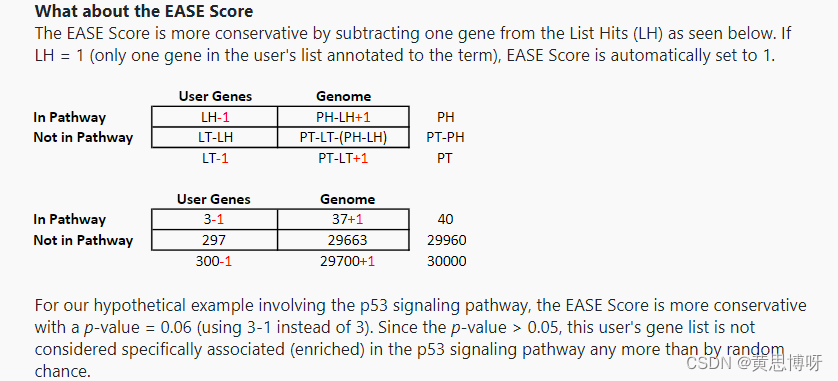
用R实现两个P value的计算:
 计算的LH=11,LT=215,PH=93,PT=8156
计算的LH=11,LT=215,PH=93,PT=8156
#计算原始的P Value
> a=matrix(c(11,82,204,8156-215-82),nrow=2,byrow=T)
> a
[,1] [,2]
[1,] 11 82
[2,] 204 7859
> fisher.test(a)
Fisher's Exact Test for Count Data
data: a
p-value = 3.025e-05#计算 EASE score
> a=matrix(c(11-1,82+1,204,8156-215-82),nrow=2,byrow=T)
> a
[,1] [,2]
[1,] 10 83
[2,] 204 7859
> fisher.test(a)
Fisher's Exact Test for Count Data
data: a
p-value = 0.0001513明显,列表内的结果是这个p value的保留小数点后5位
计算 Enrichment score:

富集倍数由Fold Change列显示
list_ratio <-11/215 #计算列表基因比率
bg_ratio <- 93/8156 #计算背景比率
enrichment_score <- list_ratio/bg_ratio #计算富集倍数
> enrichment_score
[1] 4.486922列表中的Fold change 是计算后结果的保留一位小数。
介绍Functional Annotation Chart

① clear all 去除所有的默认勾选
② 勾选 KEGG_PATHWAY,只查看KEGG PATHWAY的基因富集结果
③ 点击Functional Annotation Chart 查看KEGG数据库内匹配到的通路图表
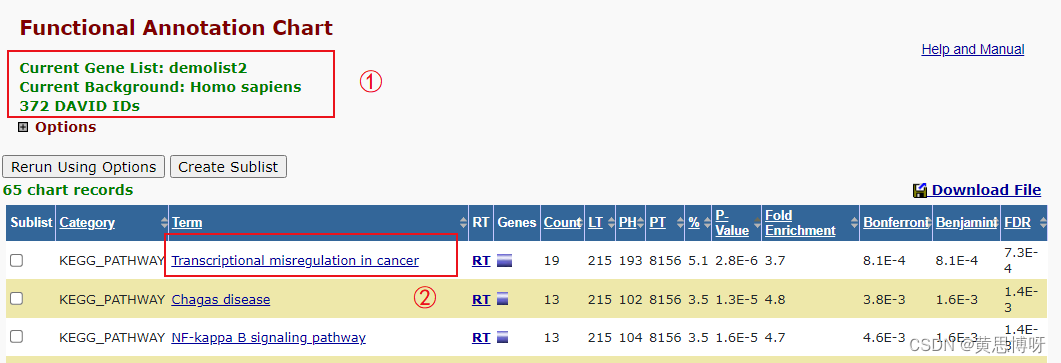
① 上传的基因列表是网页提供的demolist2,所属的物质是人类,上传基因列表中,在david内匹配到的有372个
② 列表内在KEGG分析中匹配的所有基因数有215,和条目(term) transcriptional misregulation in cancer(癌症的转录失调通路)相关的基因有19个,点击term查看图表
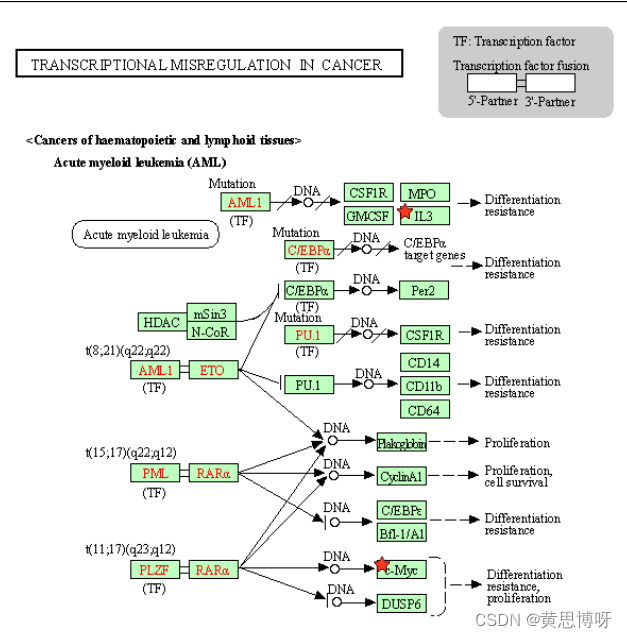
图表内红色的表示我们上传基因内,和该通路transcriptional misregulation in cancer(癌症的转录失调通路)相关的基因。

图表下是一个展示参与该通路所有基因的表格,红色的是即参与通路由出现在上传列表内的基因。
KEGG分析结果可视化:
分析基因产物在细胞中活动的通路。
一般是选取前十多条更显著的数据进行可视化,太多的会导致图形较拥挤
Excel中处理kegg pathways分析数据文件:
1.将Term列的物种号码~基因注释劈开,取后面的基因注释组成新的一列description:
1.右键插入新建一列C
2.C1输入description
3.C2输入=right(B2,len(B2)-9) #B是term列
4.下拉C2列2.筛选出PValue小于0.05的:
选中【PValue】列-->【排序和筛选】-->【筛选】-->点击【PValue】列上出现的 \
按钮【数字筛选】-->【小于】,输入0.053.计算PVlaue的负对数值-log10(PValue):
1.新建一列G
2.将G1输入为'-log10(PValue)' #不加''会变成#NAME?
3.在G2输入=-log10(E2) #E列是PValue列
4.下拉G2
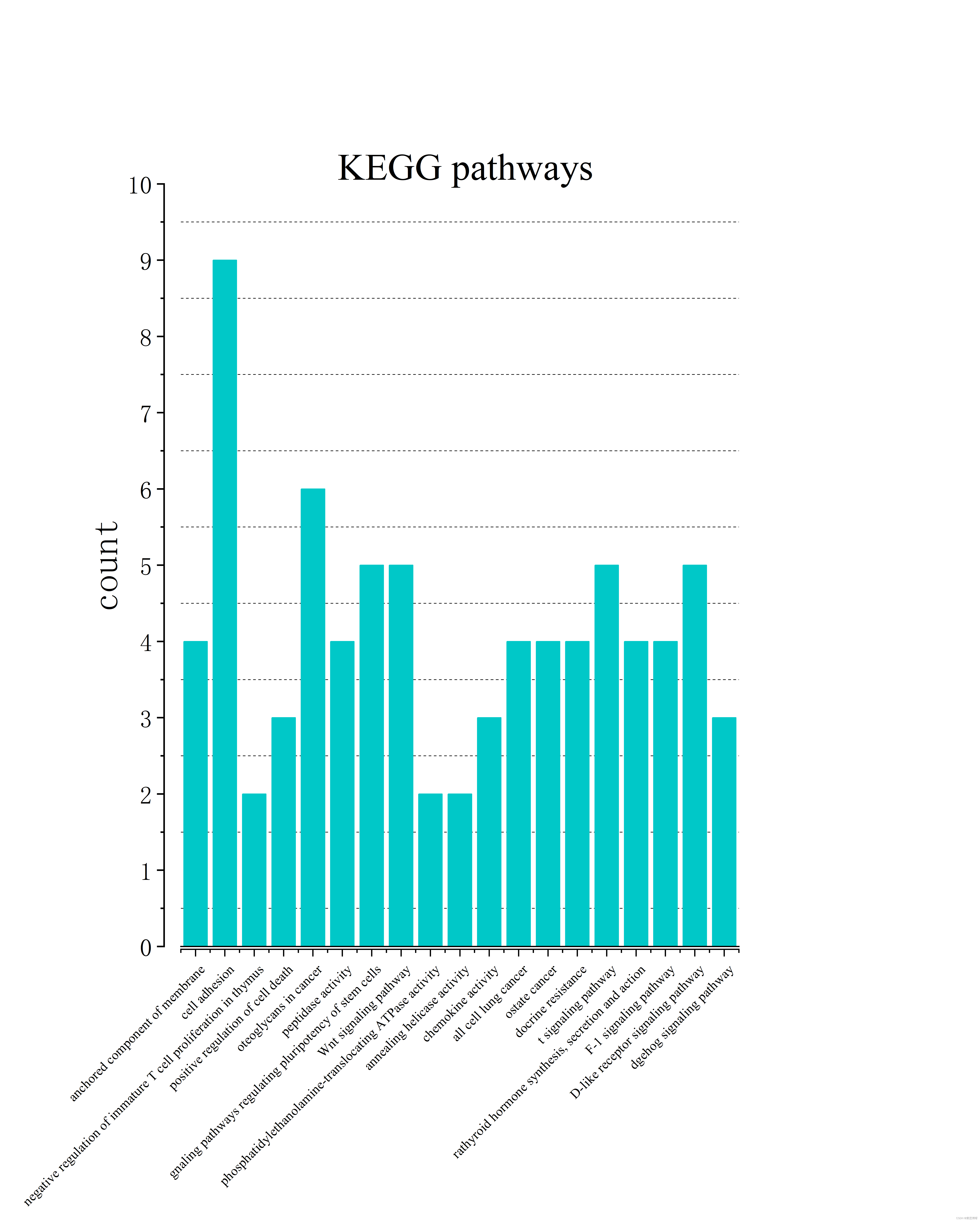
利用前十多行的description列和count列进行绘制条柱图,图片dpi要大于300
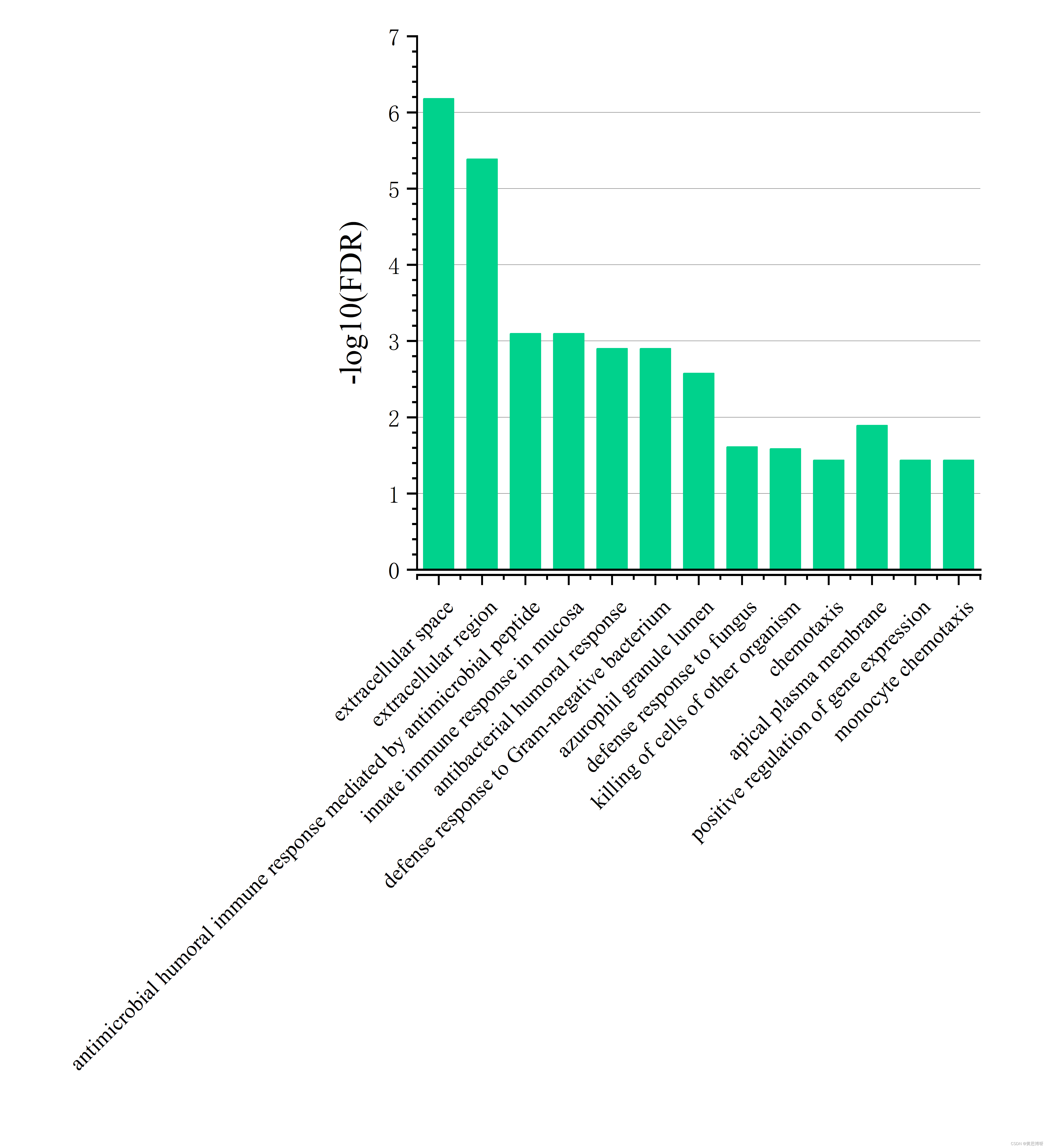
利用前十多行的description列和-log10(FDR)进行绘制条形图,保存为矢量图
参考视频:
边栏推荐
猜你喜欢


随机推荐
万物智联时代,悄然走入生活
LeetCode 2360. 图中的最长环 基环树找环+时间戳
Jmeter二次开发实现rsa加密
一群搞社区的人
若依如何实现添加水印功能
饥荒联机版Mod开发——制作简单的物品(三)
What is the core business model of the "advertising e-commerce" that has recently become popular in the circle of friends, and is the advertising revenue really reliable?
创建型模式 - 单例模式Singleton
网络运维系列:健康检查的方式
七夕到了——属于程序员的浪漫
单例模式你会几种写法?
word操作:单独调整英文字体
TDengine 在中天钢铁 GPS、 AIS 调度中的落地
【c】操作符详解(一)
如何通过开源数据库管理工具 DBeaver 连接 TDengine
Abstract Factory Pattern
UDP(用户数据报协议)
go rand 包
YAML文件格式
终于明白:有了线程,为什么还要有协程?