当前位置:网站首页>MapReduce编程基础
MapReduce编程基础
2022-07-01 09:05:00 【半濠春水】
(一)实现词频统计的基本的
MapReduce编程。①在
/user/hadoop/input文件夹(该文件夹为空),创建文件wordfile1.txt和wordfile2.txt上传到HDFS中的input文件夹下。
文件wordfile1.txt的内容如下:I love SparkI love Hadoop
文件wordfile2.txt的内容如下:Hadoop is goodSpark is fast
②启动Eclipse,启动以后会弹出如下图所示界面,提示设置工作空间(workspace)。可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
③Eclipse启动以后,选择“File–>New–>Java Project”菜单,开始创建一个Java工程。
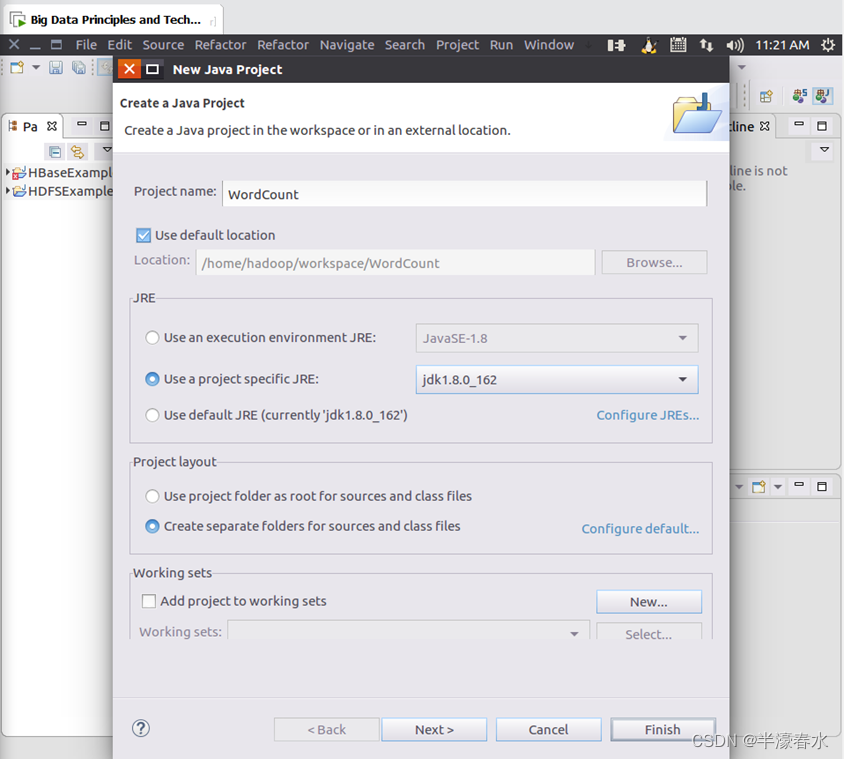
④在“Project name”后面输入工程名称“WordCount”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/WordCount”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如jdk1.8.0_162。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
⑤进入下一步的设置以后,需要在该界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了与Hadoop相关的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,弹出如下图所示界面。
⑥在该界面中,上面有一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce”和“lib”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个MapReduce程序,一般需要向Java工程中添加以下JAR包:
a.“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar;
b.“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
c.“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib、lib-examples和sources目录。
⑦编写一个Java应用程序,即WordCount.java。在Eclipse工作界面左侧的“Package Explorer”面板中(如下图所示),找到刚才创建好的工程名称“WordCount”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New–>Class”菜单。
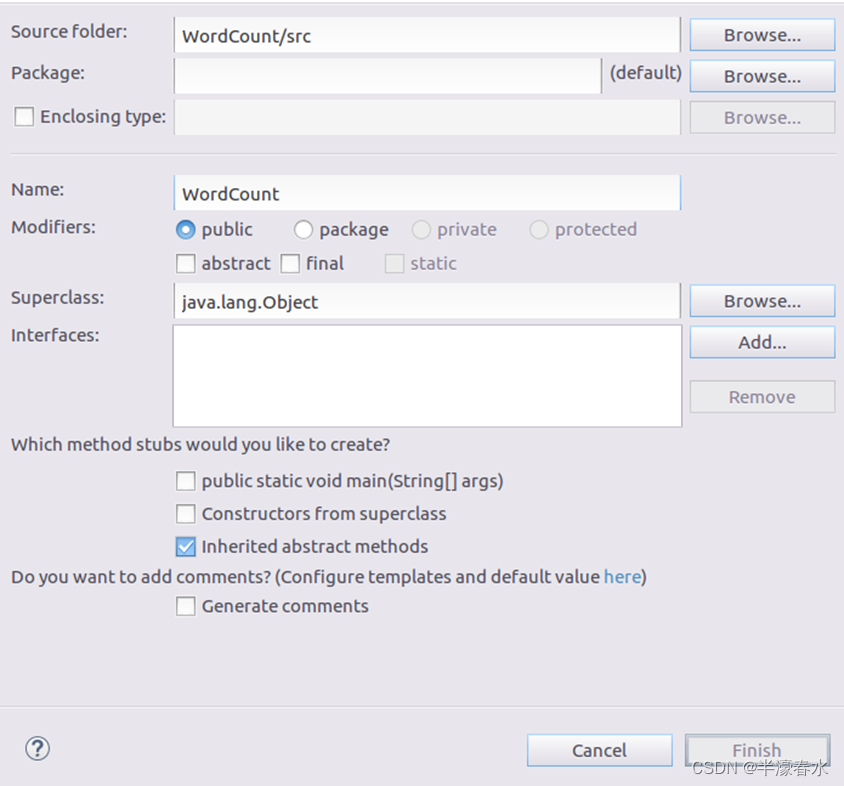
⑧选择“New–>Class”菜单以后会出现如下图所示界面,在该界面中只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“WordCount”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮。
⑨可以看出Eclipse自动创建了一个名为“WordCount.java”的源代码文件,并且包含了代码“public class WordCount{}”,清空该文件里面的代码,然后在该文件中输入完整的词频统计程序代码。(二)配置
eclipse环境,跑词频统计的程序。(1)编译打包程序
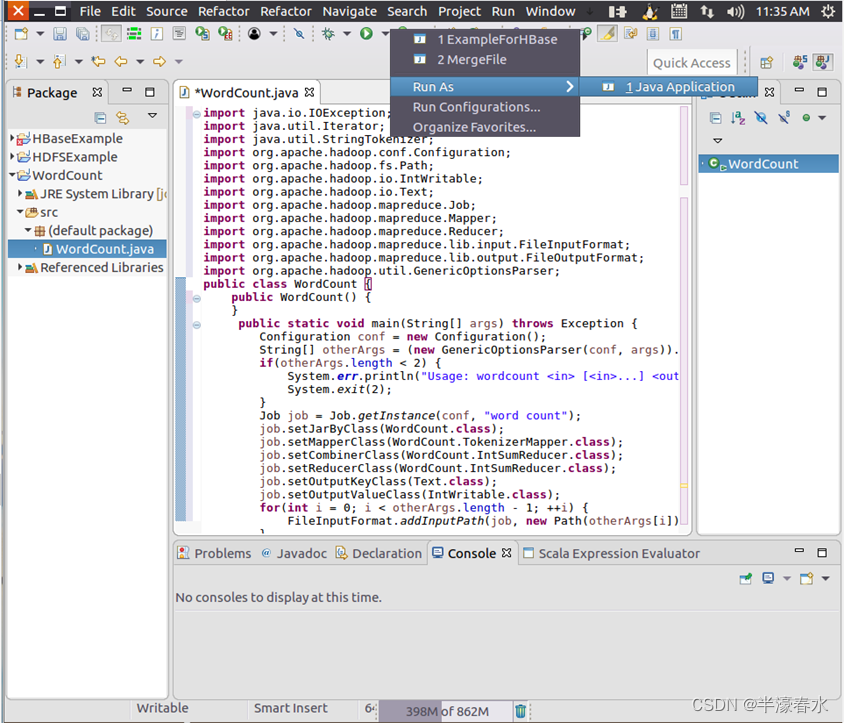
①编译上面编写的代码,直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”,如下图所示。②然后,会弹出如下图所示界面,点击界面右下角的“
OK”按钮,开始运行程序。
③程序运行结束后,会在底部的“Console”面板中显示运行结果信息(如下图所示)。
④下面就可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。如果该目录不存在,可以使用如下命令创建。cd /usr/local/hadoopmkdir myapp
⑤在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount”上点击鼠标右键,在弹出的菜单中选择“Export”,如下图所示。
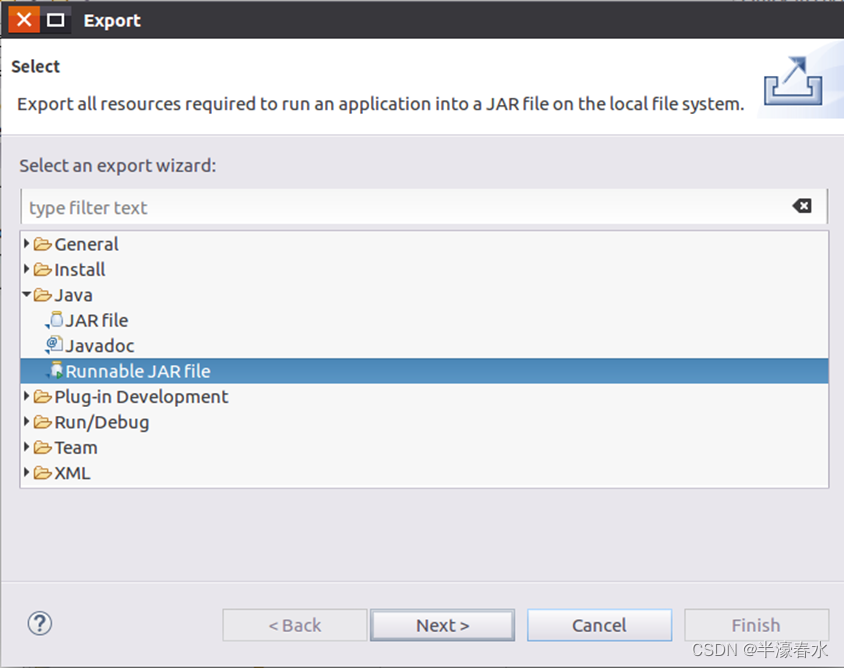
⑥然后会弹出如下图所示界面,在该界面中选择“Runnable JAR file”。
⑦然后,点击“Next>”按钮,弹出如下图所示界面。在该界面中,“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“WordCount-WordCount”。在“Export destination”中需要设置JAR包要输出保存到哪个目录,比如这里设置为“/usr/local/hadoop/myapp/WordCount.jar”。在“Library handling”下面选择“Extract required libraries into generated JAR”。
⑧然后点击“Finish”按钮,会出现如下图所示界面。
⑨可以忽略该界面的信息,直接点击界面右下角的“OK”按钮,启动打包过程。打包过程结束后,会出现一个警告信息界面,如下图所示。
⑩可以忽略该界面的信息,直接点击界面右下角的“OK”按钮。至此,已经顺利把WordCount工程打包生成了WordCount.jar。可以到Linux系统中查看一下生成的WordCount.jar文件,可以在Linux的终端中执行如下命令,可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个WordCount.jar文件。
(2)运行程序
①在运行程序之前,需要启动Hadoop。
②在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录(即HDFS中的“/user/hadoop/input”和“/user/hadoop/output”目录),这样确保后面程序运行不会出现问题。
③然后,再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录。
④然后把之前在Linux本地文件系统中新建的两个文件wordfile1.txt和wordfile2.txt(两个文件位于“/usr/local/hadoop”目录下,并且里面包含了一些英文语句),上传到HDFS中的“/user/hadoop/input”目录下。
⑤如果HDFS中已经存在目录“/user/hadoop/output”,则使用如下命令删除该目录。
⑥现在就可以在Linux系统中使用hadoop jar命令运行程序。命令执行以后,当运行顺利结束时,屏幕上会显示类似如下的信息。
⑦此时词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,执行如下命令会在屏幕上显示如下词频统计结果。
至此,词频统计程序顺利运行结束。需要注意的是,如果要再次运行WordCount.jar,需要首先删除HDFS中的output目录,否则会报错。(三)编写MapReduce程序,实现计算平均成绩的程序。




















import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Score {
public static class Map extends
Mapper<LongWritable, Text, Text, IntWritable> {
// 实现map函数
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 将输入的纯文本文件的数据转化成String
String line = value.toString();
// 将输入的数据首先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\n");
// 分别对每一行进行处理
while (tokenizerArticle.hasMoreElements()) {
// 每行按空格划分
StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken());
String strName = tokenizerLine.nextToken();// 学生姓名部分
String strScore = tokenizerLine.nextToken();// 成绩部分
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
// 输出姓名和成绩
context.write(name, new IntWritable(scoreInt));
}
}
}
public static class Reduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
// 实现reduce函数
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
sum += iterator.next().get();// 计算总分
count++;// 统计总的科目数
}
int average = (int) sum / count;// 计算平均成绩
context.write(key, new IntWritable(average));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// "localhost:9000" 需要根据实际情况设置一下
conf.set("mapred.job.tracker", "localhost:9000");
// 一个hdfs文件系统中的 输入目录 及 输出目录
String[] ioArgs = new String[] {
"input/score", "output" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Score Average <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Score Average");
job.setJarByClass(Score.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(四)MapReduce的工作原理是什么?
通过
Client、JobTracker和TaskTracker的角度来分析MapReduce的工作原理。
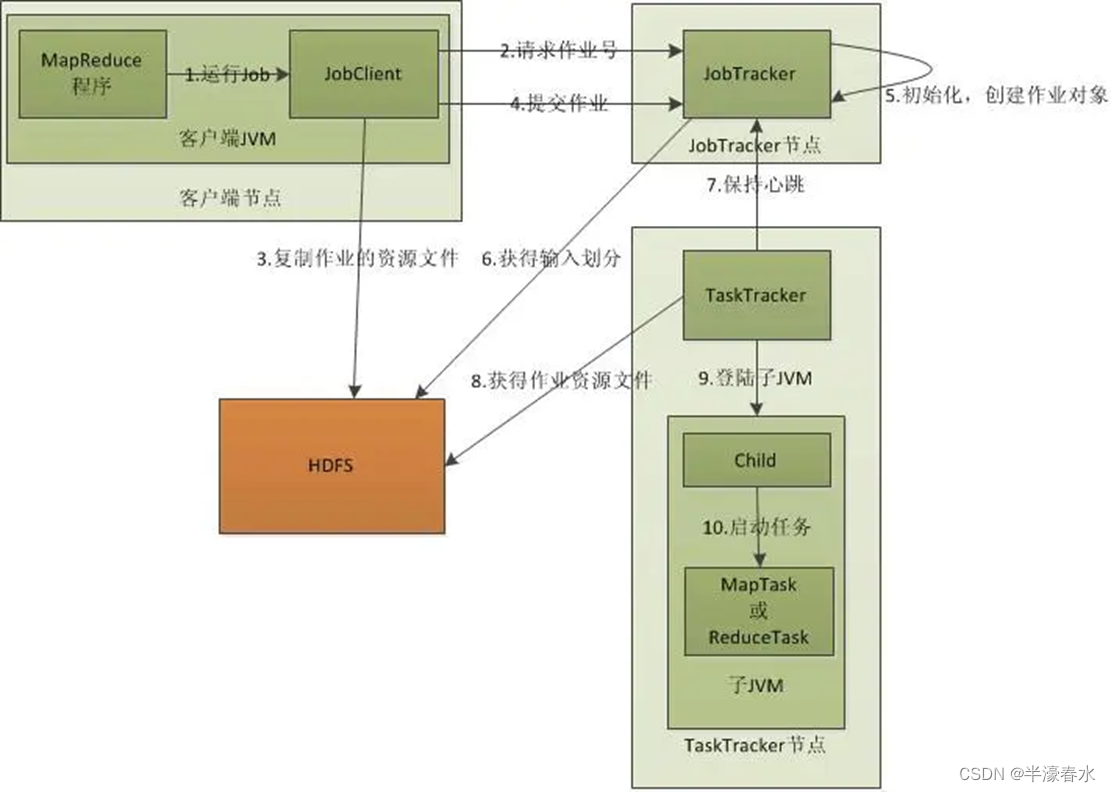
首先是客户端client要编写好
mapreduce程序,配置好mapreduce的作业也就是job,接下来就是启动job了,启动job是告知JobTracker上要运行作业,这个时候JobTracker就会返回给客户端一个新的job任务的ID值,接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,这些都做好了JobTracker就会配置Job需要的资源了。拿到jobID后,将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和计算所得的输入分片信息。这些文件都存放在jobTracker专门为该作业创建的文件夹中,文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入分片信息告诉JobTracker应该为这个作业启动多少个map任务等信息。当资源文件夹创建完毕后,客户端会提交job告知jobTracker我已将所需资源写入hdfs上,接下来请你帮我真正去执行job。
分配好资源后,JobTracker接收提交job请求后就会初始化作业,初始化主要做的是将Job放入一个内部的队列,等待作业调度器对其进行调度。当作业调度器根据自己的调度算法调度到该作业时,作业调度器会创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程。创建job对象时作业调度器会获取hdfs文件夹中的输入分片信息,根据分片信息为每个input split创建一个map任务,并将map任务分配给tasktracker执行。对于map和reduce任务,tasktracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个tasktracker的,这里涉及到后面要讲的数据本地化。
接下来就是任务分配了,这个时候tasktracker会运行一个简单的循环机制定期发送心跳给jobtracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是jobtracker和tasktracker沟通的桥梁,通过心跳,jobtracker可以监控tasktracker是否存活,也可以获取tasktracker处理的状态和问题,同时tasktracker也可以通过心跳里的返回值获取jobtracker给它的操作指令。tasktracker会获取运行job所需的资源,比如代码等,为真正执行做准备。任务分配好后就是执行任务了。在任务执行时候jobtracker可以通过心跳机制监控tasktracker的状态和进度,同时也能计算出整个job的状态和进度,而tasktracker也可以本地监控自己的状态和进度。TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带者很多的信息,比如当前map任务完成的进度等信息。当jobtracker获得了最后一个完成指定任务的tasktracker操作成功的通知时候,jobtracker会把整个job状态置为成功,然后当客户端查询job运行状态时候(注意:这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理,一般而言如果不是程序员程序本身有bug,mapreduce错误处理机制都能保证提交的job能正常完成。(五)
Hadoop是如何运行MapReduce程序的?①将编译软件与
hadoop相连(如Eclipse去链接hadoop),直接运行程序。
②将mapreduce程序打包成jar文件。
边栏推荐
- Jetson Nano 安装TensorFlow GPU及问题解决
- Shell脚本-read命令:读取从键盘输入的数据
- Redis source code learning (29), compressed list learning, ziplist C (II)
- Interrupt sharing variables with other functions and protection of critical resources
- Shell script -for loop and for int loop
- Shell脚本-if else语句
- pcl_ Viewer command
- Shell脚本-for循环和for int循环
- 猿人学第20题(题目会不定时更新)
- The jar package embedded with SQLite database is deployed by changing directories on the same machine, and the newly added database records are gone
猜你喜欢

Principles of Microcomputer - Introduction

Dynamic proxy
![[MFC development (16)] tree control](/img/b9/1de4330c0bd186cfe062b02478c058.png)
[MFC development (16)] tree control

Nacos - gestion de la configuration

Bird recognition app

An overview of the design of royalties and service fees of mainstream NFT market platforms

Personal decoration notes

中小企业固定资产管理办法哪种好?

集团公司固定资产管理的痛点和解决方案

Embedded Engineer Interview Question 3 Hardware
随机推荐
How to solve the problem of fixed assets management and inventory?
Mysql8.0 learning record 17 -create table
【电赛训练】红外光通信装置 2013年电赛真题
Installing Oracle EE
Flink interview questions
2.3 [kaggle dataset - dog feed example] data preprocessing, rewriting dataset, dataloader reading data
Why is the Ltd independent station a Web3.0 website!
又到年中,固定资产管理该何去何从?
Naoqi robot summary 28
【ESP 保姆级教程】疯狂毕设篇 —— 案例:基于阿里云、小程序、Arduino的温湿度监控系统
TV size and viewing distance
如何一站式高效管理固定资产?
[ESP nanny level tutorial] crazy completion chapter - Case: temperature and humidity monitoring system based on Alibaba cloud, applet and Arduino
Shell script - definition, assignment and deletion of variables
小鸟识别APP
Shell脚本-数组定义以及获取数组元素
Mysql 优化
Pain points and solutions of fixed assets management of group companies
[MFC development (17)] advanced list control list control
【pytorch】softmax函数