当前位置:网站首页>Compiling principle on computer -- function drawing language (II): lexical analyzer
Compiling principle on computer -- function drawing language (II): lexical analyzer
2022-06-12 07:50:00 【FishPotatoChen】
Catalog
Related articles
Compiling principle on the computer —— Functional drawing language ( One )
Compiling principle on the computer —— Functional drawing language ( 3、 ... and ): parsers
Compiling principle on the computer —— Functional drawing language ( Four ): semantic analyzer
Compiling principle on the computer —— Functional drawing language ( 5、 ... and ): Compiler and interpreter
Lexical analyzer
Generate symbol table
This is a table driven lexical analyzer , The symbol table will be saved in the file TOKEN.npy in .
# -*- coding: utf-8 -*-
""" Created on Mon Nov 23 20:05:45 2020 @author: FishPotatoChen Copyright (c) 2020 FishPotatoChen All rights reserved. """
import numpy as np
import math
TOKEN = {
# Constant
'PI': {
'TYPE': 'CONST_ID', 'VALUE': math.pi, 'FUNCTION': None},
'E': {
'TYPE': 'CONST_ID', 'VALUE': math.e, 'FUNCTION': None},
# Variable
'T': {
'TYPE': 'SYMBOL', 'VALUE': None, 'FUNCTION': None},
# function
'SIN': {
'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': math.sin},
'COS': {
'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': math.cos},
'TAN': {
'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': math.tan},
# log(x,a) If you don't specify a, Default to e Cardinal number
'LOG': {
'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': math.log},
'EXP': {
'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': math.exp},
'SQRT': {
'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': math.sqrt},
# Reserved words
'ORIGIN': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'SCALE': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'ROT': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'IS': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'FOR': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'FROM': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'TO': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'STEP': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
'DRAW': {
'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None},
# Operator
'+': {
'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None},
'-': {
'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None},
'*': {
'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None},
'/': {
'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None},
'**': {
'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None},
# mark
'(': {
'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None},
')': {
'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None},
',': {
'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None},
# Terminator
';': {
'TYPE': 'END', 'VALUE': None, 'FUNCTION': None},
# empty
'': {
'TYPE': 'EMPTY', 'VALUE': None, 'FUNCTION': None},
# Numbers
'0': {
'TYPE': 'NUMBER', 'VALUE': 0.0, 'FUNCTION': None},
'1': {
'TYPE': 'NUMBER', 'VALUE': 1.0, 'FUNCTION': None},
'2': {
'TYPE': 'NUMBER', 'VALUE': 2.0, 'FUNCTION': None},
'3': {
'TYPE': 'NUMBER', 'VALUE': 3.0, 'FUNCTION': None},
'4': {
'TYPE': 'NUMBER', 'VALUE': 4.0, 'FUNCTION': None},
'5': {
'TYPE': 'NUMBER', 'VALUE': 5.0, 'FUNCTION': None},
'6': {
'TYPE': 'NUMBER', 'VALUE': 6.0, 'FUNCTION': None},
'7': {
'TYPE': 'NUMBER', 'VALUE': 7.0, 'FUNCTION': None},
'8': {
'TYPE': 'NUMBER', 'VALUE': 8.0, 'FUNCTION': None},
'9': {
'TYPE': 'NUMBER', 'VALUE': 9.0, 'FUNCTION': None},
'.': {
'TYPE': 'NUMBER', 'VALUE': None, 'FUNCTION': None},
}
np.save('TOKEN.npy', TOKEN)
Lexical analyzer body
The file named lexer.py
# -*- coding: utf-8 -*-
""" Created on Mon Nov 23 20:05:45 2020 @author: FishPotatoChen Copyright (c) 2020 FishPotatoChen All rights reserved. """
# Lexical analyzer
import math
import re
import numpy as np
class Lexer:
def __init__(self):
# Read the tick table from the file
self.TOKEN = np.load('TOKEN.npy', allow_pickle=True).item()
def getToken(self, sentence):
if sentence:
tokens = sentence.split()
for token in tokens:
try:
# No.0
# First, identify the directly identifiable marks
# The normal form is ORIGIN|SCALE|ROT|IS|FOR|FROM|TO|STEP|DRAW|ε
self.output_token(token)
# No.0 End of identification
except:
# If you can't find it, go to a higher level DFA To identify
self.argument_lexer(token)
self.output_token(';')
# The structure is more complex 、 advanced 、 A variety of recognition expressions
def argument_lexer(self, argument):
# Scanning position
i = 0
# String length
length = len(argument)
while(i < length):
# Temporary string , That's buffer
temp = ''
if argument[i] in ['P', 'S', 'C', 'L', 'E', 'T', '*']:
# No.1
# distinguish "*" still "**" The process is a context sensitive grammar
if argument[i] == '*':
i += 1
if i >= length:
self.output_token(argument[i])
break
elif argument[i] == '*':
self.output_token('**')
else:
i -= 1
self.output_token(argument[i])
# No.1 End of identification
else:
# No.2
# DFA Determine the character string that is all letters
# The normal form is PI|E|T|SIN|COS|TAN|LOG|EXP|SQRT
temp = re.findall(r"[A-Z]+", argument[i:])[0]
# See if the string accepts
self.output_token(temp)
i += len(temp)-1
if i >= length:
break
# No.2 End of identification
elif argument[i] in ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '.']:
# No.3
# Identification Numbers
if argument[i] == '.':
# Identification begins with "." The number of
# The normal form is .[0-9]+
# Such as :.52=>0.52
i += 1
temp = re.findall(r"\d+", argument[i:])[0]
i += len(temp)-1
temp = '0.' + temp
self.output_token(temp, False)
else:
# Identify general numbers
# The normal form is [0-9]+.?[0-9]*
# Such as :5.52=>5.52;12=>12
temp = re.findall(r"\d+\.?\d*", argument[i:])[0]
i += len(temp)-1
self.output_token(temp, False)
if i >= length:
break
# No.3 End of identification
else:
# No.4
# Recognize other characters
# The normal form is +|-|/|(|)|,|ε
self.output_token(argument[i])
i += 1
# Output function
# Because the interpreter doesn't have to output to the screen , But the title requires output to the screen
# So I especially wrote a function to output , It is convenient for the next parser to call the grammar parser
# When the output is not a screen , Embedding the output into the code makes it hard to change
# If you write it as an independent function , Directly change the output function
def output_token(self, token, NotNumber=True):
if NotNumber:
print(token, self.TOKEN[token])
else:
tempdic = {
token: {
'TYPE': 'NUMBER', 'VALUE': float(token), 'FUNCTION': None}}
print(token, tempdic[token])
Scanner
The file named scanner.py
# -*- coding: utf-8 -*-
""" Created on Mon Nov 23 20:05:45 2020 @author: FishPotatoChen Copyright (c) 2020 FishPotatoChen All rights reserved. """
# Input processor
import re
import lexer
class Scanner():
def __init__(self, path="test.txt"):
# Read in file location
self.path = path
# Set buffer
self.text = ""
with open(self.path, "r") as f:
lines = f.readlines()
for line in lines:
# Remove comments from the file
self.text = self.text + \
line.split("//")[0].split("--")[0].split("\n")[0]
self.text = self.text.upper().strip()
self.lexer = lexer.Lexer()
def analyze(self):
sentences = re.split("(;)", self.text)
# No.0
# distinguish
# E->E;|ε
# Used to record the state machine state , When state == True when , It means you can read in a E, When state == False when , It means you can read in a ;
state = True
for sentence in sentences:
if state and sentence != ";":
state = False
self.lexer.getToken(sentence)
elif sentence == ";":
state = True
else:
raise SyntaxError()
if state:
raise SyntaxError()
# No.0 End of identification
The main function
The file named main.py
# -*- coding: utf-8 -*-
""" Created on Mon Nov 23 20:05:45 2020 @author: FishPotatoChen Copyright (c) 2020 FishPotatoChen All rights reserved. """
import scanner
if __name__ == "__main__":
# print(" Input \t type \t\t\t value \t\t function ")
scan = scanner.Scanner()
scan.analyze()
test
The test file
The file named test.txt
for t from 0.5.6.7 to 2*E step e/10 draw (5*T *T *T * cos( T ),sin(T));;;;origin is (100,100); //ksdjfksdjkl
//dsfsdfdsf
origin is --ksdjfksdjkl
(0,0);
origin is //kssdfj
(10,10);
origin is (0,0); --ksdjfksdjkl
origin is (10,10); //kssdfj
ROT is E/4;
ROT is pi ** 4;
ROT is pi /4*5;
ROT is sin( 4.5)*cos(3.5);
ROT is pi/4;
Output results
FOR {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
T {'TYPE': 'SYMBOL', 'VALUE': None, 'FUNCTION': None}
FROM {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
0.5 {'TYPE': 'NUMBER', 'VALUE': 0.5, 'FUNCTION': None}
0.6 {'TYPE': 'NUMBER', 'VALUE': 0.6, 'FUNCTION': None}
0.7 {'TYPE': 'NUMBER', 'VALUE': 0.7, 'FUNCTION': None}
TO {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
2 {'TYPE': 'NUMBER', 'VALUE': 2.0, 'FUNCTION': None}
* {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
E {'TYPE': 'CONST_ID', 'VALUE': 2.718281828459045, 'FUNCTION': None}
STEP {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
E {'TYPE': 'CONST_ID', 'VALUE': 2.718281828459045, 'FUNCTION': None}
/ {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
10 {'TYPE': 'NUMBER', 'VALUE': 10.0, 'FUNCTION': None}
DRAW {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
5 {'TYPE': 'NUMBER', 'VALUE': 5.0, 'FUNCTION': None}
* {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
T {'TYPE': 'SYMBOL', 'VALUE': None, 'FUNCTION': None}
* {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
T {'TYPE': 'SYMBOL', 'VALUE': None, 'FUNCTION': None}
* {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
T {'TYPE': 'SYMBOL', 'VALUE': None, 'FUNCTION': None}
* {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
COS {'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': <built-in function cos>}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
T {'TYPE': 'SYMBOL', 'VALUE': None, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
, {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
SIN {'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': <built-in function sin>}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
T {'TYPE': 'SYMBOL', 'VALUE': None, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ORIGIN {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
100 {'TYPE': 'NUMBER', 'VALUE': 100.0, 'FUNCTION': None}
, {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
100 {'TYPE': 'NUMBER', 'VALUE': 100.0, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ORIGIN {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
0 {'TYPE': 'NUMBER', 'VALUE': 0.0, 'FUNCTION': None}
, {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
0 {'TYPE': 'NUMBER', 'VALUE': 0.0, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ORIGIN {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
10 {'TYPE': 'NUMBER', 'VALUE': 10.0, 'FUNCTION': None}
, {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
10 {'TYPE': 'NUMBER', 'VALUE': 10.0, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ORIGIN {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
0 {'TYPE': 'NUMBER', 'VALUE': 0.0, 'FUNCTION': None}
, {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
0 {'TYPE': 'NUMBER', 'VALUE': 0.0, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ORIGIN {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
10 {'TYPE': 'NUMBER', 'VALUE': 10.0, 'FUNCTION': None}
, {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
10 {'TYPE': 'NUMBER', 'VALUE': 10.0, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ROT {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
E {'TYPE': 'CONST_ID', 'VALUE': 2.718281828459045, 'FUNCTION': None}
/ {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
4 {'TYPE': 'NUMBER', 'VALUE': 4.0, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ROT {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
PI {'TYPE': 'CONST_ID', 'VALUE': 3.141592653589793, 'FUNCTION': None}
** {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
4 {'TYPE': 'NUMBER', 'VALUE': 4.0, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ROT {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
PI {'TYPE': 'CONST_ID', 'VALUE': 3.141592653589793, 'FUNCTION': None}
/ {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
4 {'TYPE': 'NUMBER', 'VALUE': 4.0, 'FUNCTION': None}
* {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
5 {'TYPE': 'NUMBER', 'VALUE': 5.0, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ROT {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
SIN {'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': <built-in function sin>}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
4.5 {'TYPE': 'NUMBER', 'VALUE': 4.5, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
* {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
COS {'TYPE': 'FUNC', 'VALUE': None, 'FUNCTION': <built-in function cos>}
( {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
3.5 {'TYPE': 'NUMBER', 'VALUE': 3.5, 'FUNCTION': None}
) {'TYPE': 'MARK', 'VALUE': None, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
ROT {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
IS {'TYPE': 'KEYWORD', 'VALUE': None, 'FUNCTION': None}
PI {'TYPE': 'CONST_ID', 'VALUE': 3.141592653589793, 'FUNCTION': None}
/ {'TYPE': 'OP', 'VALUE': None, 'FUNCTION': None}
4 {'TYPE': 'NUMBER', 'VALUE': 4.0, 'FUNCTION': None}
; {'TYPE': 'END', 'VALUE': None, 'FUNCTION': None}
边栏推荐
- Modelants II
- AcWing——4268. Sexy element
- 移动端、安卓、IOS兼容性面试题
- Meter Reading Instrument(MRI) Remote Terminal Unit electric gas water
- Summary of machine learning + pattern recognition learning (IV) -- decision tree
- 二、八、十、十六进制相互转换
- R语言glm函数构建泊松回归模型(possion)、epiDisplay包的poisgof函数对拟合的泊松回归模型进行拟合优度检验、即模型拟合的效果、验证模型是否有过度离散overdispersion
- Exposure compensation, white increase and black decrease theory
- Process terminated
- 解决上传SFTPorg.apache.commons.net.MalformedServerReplyException: Could not parse respon
猜你喜欢

Some summaries of mathematical modeling competition in 2022

Topic 1 Single_ Cell_ analysis(4)

vscode 1.68变化与关注点(整理导入语句/实验性新命令中心等)

Summary of machine learning + pattern recognition learning (IV) -- decision tree
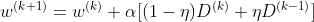
Summary of machine learning + pattern recognition learning (II) -- perceptron and neural network

Chapter 2 - cyber threats and attacks

Seeking for a new situation and promoting development, the head goose effect of Guilin's green digital economy

Chapter 3 - Fundamentals of cryptography

2022 simulated test platform operation of hoisting machinery command test questions

Dynamic simulation method of security class using Matlab based Matpower toolbox
随机推荐
Interview computer network - transport layer
How to stop MySQL service under Linux
20220526 yolov1-v5
Vs 2019 MFC connects and accesses access database class library encapsulation through ace engine
20220525 RCNN--->Faster RCNN
Voice assistant - potential skills and uncalled call technique mining
tar之多线程解压缩
Voice assistant - future trends
Topic 1 Single_ Cell_ analysis(3)
Personalized federated learning with Moreau envelopes
2022 G3 boiler water treatment recurrent training question bank and answers
AcWing——4268. Sexy element
[redistemplate method details]
R语言caTools包进行数据划分、scale函数进行数据缩放、class包的knn函数构建K近邻分类器、比较不同K值超参数下模型准确率(accuracy)
Summary of machine learning + pattern recognition learning (IV) -- decision tree
初步认知Next.js中ISR/RSC/Edge Runtime/Streaming等新概念
L'effet de l'oie sauvage sur l'économie numérique verte de Guilin
Right click the general solution of file rotation jam, refresh, white screen, flash back and desktop crash
20220607. 人脸识别
Voice assistant - Measurement Indicators