当前位置:网站首页>Voice assistant - potential skills and uncalled call technique mining
Voice assistant - potential skills and uncalled call technique mining
2022-06-12 07:33:00 【Turned_ MZ】
This section mainly summarizes the content related to the mining of potential skills and uncalled calls in the voice assistant , It is mainly divided into the following points :1、 Why do you dig for potential skills ;2、 How to dig .
Why do you dig for potential skills
With the voice assistant's daily life increasing , The scenarios required by users are also increasing , The product defines scenarios , In addition to user group analysis and competitive product analysis , You can also quickly find the scenarios with the most user needs based on big data mining . This is also called hot topic mining , For example, through log analysis , It can be found that users' demand for train tickets increases suddenly during the Spring Festival , At this point, you can quickly respond to the ability to set up the corresponding scenario .
besides , You can also use this technique to find the types of scripts that are not covered by the previously defined scenarios . For example, in the schedule scenario , Some users may express when setting the schedule :“ evening 8 The point is 305 Hold an event ”, This direct “ Time + action ” The scheduling method of is not covered in the previous definition of scenarios , Through the excavation of this script , It can effectively improve the daily life and retention of the schedule scene .
The long tail skill has the following characteristics :
- The pool to be excavated is large , everyday query The magnitude is 400w about , After the coarse screening of strategies, there are still 50w about .
- There's a lot of noise , There is a large amount of invalid data in the pool , Including misreception 、 noise 、 Meaningless scripts, etc .
- The intentions are numerous and miscellaneous , Effective intentions that can be found in the pool , It can reach thousands every day , And don't repeat .
How to dig
Because it is an undefined scene , Or a script statement that has been defined but not covered , So through the existing classification model or intention model , It is very difficult to mine directly and effectively , So it is generally used here clustering The way to do it . Since clustering is involved , It involves the following issues :1、 Encoding selection .2、 Clustering method .3、 Feature scaling and distance selection .4、 Clustering stability .5、 The evaluation index .
1、 Encoding selection
seeing the name of a thing one thinks of its function , Code choice is choice query Code type of , Common ways are :TF-IDF, Tencent word vector ,bert Vector, etc . After our experiments , Find the domain adapted bert The output vector is the best for clustering , stay ARI( Adjusted Rand coefficient ) The index can be higher than TF-IDF 20 A p.m. . When use , Can be bert Yes query The coding vectors of the are averaged , Get a fixed length vector and use it as a sentence vector .
2、 Clustering method
The clustering method can select the common k-means, Hierarchical clustering ,dbscan etc. , Here we choose k-means, This is mainly due to the high performance and memory consumption of hierarchical clustering , Resulting in low efficiency , There is no need to compare the differences of these clustering methods . Use k-means when , The elbow method can be used to determine k Value .
3、 The evaluation index
In clustering , The evaluation index used to measure the clustering effect , Generally speaking, there are : Rand coefficient 、 Adjusted Rand coefficient 、 Contour coefficient, etc .
3.1 The RAND index RI And adjust the RAND index ARI
Rand Index Calculate the similarity between the predicted value and the real value of the sample ,RI The value range is [0,1], The higher the value is, the more consistent the clustering result is with the real situation .

among C Represents the actual category information ,K Represents the clustering result ,a It means that C And K All of them are logarithms of elements of the same category ,b It means that C And K There are logarithms of different types of elements in , Since each sample pair can only appear in one set , So there is TP+FP+TN+FN=C2m=m(m-1)/2 Represents the logarithm of samples that can be composed in the dataset .
For random results ,RI There is no guarantee that the score will be close to 0, Therefore, it has a higher degree of differentiation Adjusted Rand Index Proposed , The value range is [-1,1], The higher the value is, the more consistent the clustering result is with the real situation .
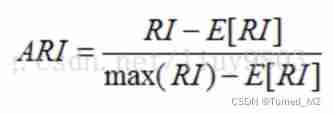
3.2 Profile factor

Where Rand coefficient & The advantage of the adjusted Rand coefficient is that it can be explained , Can evaluate different query The sentence vector of the expression , But the disadvantage is that you need to know the category label in advance . The advantage of the contour coefficient is that you do not need to know the category label , The disadvantage is that for data with convex cluster structure, the contour coefficient is high , For the cluster structure, the non convex contour coefficient is low , This leads to the contour coefficient can not be compared between different algorithms , Such as unified data , Probably KMeans The result is better than DBSCAN It is better to .
In this task , We use the adjusted Rand coefficient (ARI), Mainly through experiments , This indicator is applicable to query The best distinction is .
4、 Feature scaling and cluster selection
With evaluation indicators , Next, we need to express the distance , Generally speaking, the distance between two vectors is mainly cosine distance and Euclidean distance . For the explanation of the two, please refer to the contents in Zhihu :

Understand the measurement methods of two kinds of clustering , Let's take a look at the content related to feature scaling . Time normalization and l2 Regularization , About why to normalize , You can see a paper by he Kaiming : < You may not need BERT-flow: A linear transformation BERT-flow>, Normalization is a feature scaling technique , Change the distribution space of sample characteristics , It's a linear change , It does not change the characteristic distribution type of the sample , For example, it used to be a positive distribution , After normalization, it is still positive distribution . After normalization , Features between different dimensions can be placed in the same space , At the same time, it can accelerate the convergence of the algorithm .
There are many ways to normalize , Including standardization , Maximum - Minimum normalization , Average normalization, etc . Here we use time standardization , namely ![]() , The mean value of the characteristic distribution is 0, The variance of 1.
, The mean value of the characteristic distribution is 0, The variance of 1.
l2 Regularization is l2 Norm normalization , It is different from the normalization mentioned above , Is to change the norm length of the eigenvector of each sample to 1, , after l2 After regularization , Cosine distance and Euclidean distance have a monotonic convertible relationship .
, after l2 After regularization , Cosine distance and Euclidean distance have a monotonic convertible relationship .
In this task , We use standardization +l2 Regularization + Euclidean distance , The effect is the best .
5、 Clustering stability
For the same batch of data , How to find stable clusters after multiple clustering , The main purpose of this is to remove noise data , Improve the quality of clustering results , It's based on the assumption that : The more obvious the boundary is , The stronger the cluster consistency , The noise data will be divided into different clusters in multiple clustering .
The stability of clustering is mainly measured from two aspects :1、 Multiple clustering a center appears frequently ;2、 Some two pair It is predicted to be the same category multiple times . The specific method is : Cluster twice respectively ,1、 If the two clustering centers are close to a certain range of clustering, they are considered to belong to one cluster center ( Hyperparameters ), Count the number of times the center appears ;2、 Limit the number of samples in a cluster category , Discard too few categories ( Hyperparameters );3、 Twice clustered ARI All the indicators are greater than a certain value ( Hyperparameters ). The fused results are counted again ARI To evaluate the effect of fusion .
Through these methods , It can be verified that after multiple fusions , The stability of the algorithm will be stronger and stronger , There will also be more valid data for clustering results .
quote :
What is the difference between Euclidean distance and cosine similarity ? - You know
边栏推荐
- Set up a remote Jupiter notebook
- i. Mx6ul porting openwrt
- 2022 simulated test platform operation of hoisting machinery command test questions
- 面试计算机网络-传输层
- tmux 和 vim 的快捷键修改
- Detailed explanation of coordinate tracking of TF2 operation in ROS (example + code)
- Vs2019 MFC IP address control control inherits cipaddressctrl class redrawing
- @DateTimeFormat @JsonFormat 的区别
- Interview computer network - transport layer
- MySQL索引(一篇文章轻松搞定)
猜你喜欢

Fcpx plug-in: simple line outgoing text title introduction animation call outs with photo placeholders for fcpx

AI狂想|来这场大会,一起盘盘 AI 的新工具!
Hongmeng OS first training

LVDS drive adapter

There is no solid line connection between many devices in Proteus circuit simulation design diagram. How are they realized?

2022年危险化学品经营单位安全管理人员特种作业证考试题库及答案

Exposure compensation, white increase and black decrease theory

Exploring shared representations for personalized federated learning paper notes + code interpretation

Summary of machine learning + pattern recognition learning (I) -- k-nearest neighbor method

Golang quickly generates model and queryset of database tables
随机推荐
Learning to continuously learn paper notes + code interpretation
Arrangement of statistical learning knowledge points -- maximum likelihood estimation (MLE) and maximum a posteriori probability (map)
Golang 快速生成数据库表的 model 和 queryset
Bi skills - beginning of the month
Exploring shared representations for personalized federated learning paper notes + code interpretation
C language queue implementation
Golang quickly generates model and queryset of database tables
Personalized federated learning with exact stochastic gradient descent
R语言将dataframe数据中指定数据列的数据从小数转化为百分比表示、数据转换为百分数
Personalized federated learning using hypernetworks paper reading notes + code interpretation
Detailed explanation of coordinate tracking of TF2 operation in ROS (example + code)
RT thread studio learning summary
鸿蒙os-第一次培训
【WAX链游】发布一个免费开源的Alien Worlds【外星世界】脚本TLM
RT thread studio learning (IX) TF Card File System
Source code learning - [FreeRTOS] privileged_ Understanding of function meaning
2022R2移动式压力容器充装试题模拟考试平台操作
石油储运生产 2D 可视化,组态应用赋能工业智慧发展
i. Mx6ul porting openwrt
[tutorial] deployment process of yolov5 based on tensorflow Lite