当前位置:网站首页>Tidb's initial experience of ticdc6.0
Tidb's initial experience of ticdc6.0
2022-07-03 21:12:00 【Tidb community dry goods portal】
author : JiekeXu The source of the original :https://tidb.net/blog/2dc4482b
TiCDC Is a TiDB Incremental data synchronization tool , By pulling upstream TiKV Data change log , It has the ability to restore data to be consistent with any time in the upstream , At the same time, it provides open data protocol (TiCDC Open Protocol), Support other systems to subscribe to data changes ,TiCDC The data can be parsed into ordered row level change data and output to the downstream .
TiCDC The system architecture of is shown in the figure below :
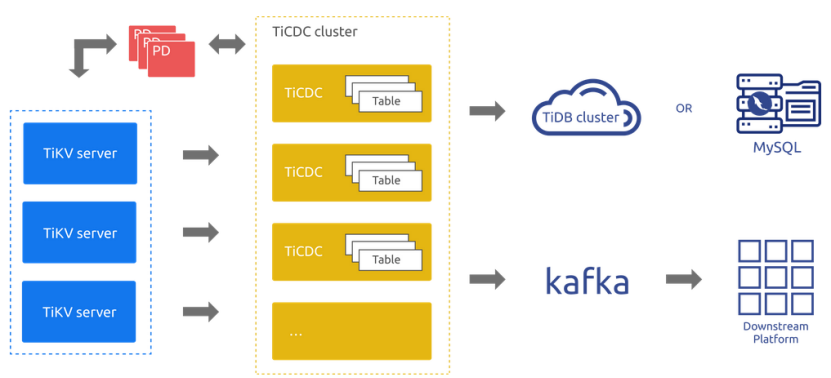
TiCDC Runtime is a stateless node , adopt PD Inside etcd High availability .TiCDC The cluster supports the creation of multiple synchronization tasks , Data synchronization to multiple different downstream .
System roles
TiKV CDC Components : Only the output key-value (KV) change log.
o Internal logic assembly KV change log.
o Provide output KV change log The interface of , Sending data includes real-time change log And incremental scanning change log.
capture:TiCDC Run the process , Multiple capture Form a TiCDC colony , be responsible for KV change log Synchronization of .
o Every capture Be responsible for pulling a part KV change log.
o To pull one or more KV change log Sort .
o Restore transactions downstream or according to TiCDC Open Protocol For the output .
principle

principle :TiDB Server Responsible for receiving SQL, And then call TiKV Each node , Then output the change log of your node , Then send the log to TiCDC colony , Of each cluster Capture It's actually TiCDC node ,TiCDC Assemble the received logs in the internal logic , Provide an interface for outputting logs , Sent to downstream MySQL、Kafka etc. .
Every Capture Be responsible for pulling part of the log , Then sort by yourself , each capture The collaboration sends the received logs to capture Choose out owner,owner Further sort the logs , Send it to the target downstream end .
TiCDC Applicable scenario
TiCDC The suitable source database is TiDB, Target database supports MySQL Compatible with any database and Kafka, meanwhile TiCDC Open Protocol It is a row level data change notification Protocol , For monitoring 、 cache 、 Full-text index 、 Analysis engine 、 The master-slave replication of heterogeneous databases provides data sources .
Database disaster recovery :TiCDC It can be used in disaster recovery scenarios between homogeneous databases , It can ensure the final consistency of the primary and standby cluster data in the event of a disaster , Currently, this scenario only supports TiDB As an active and standby cluster .
Data integration :TiCDC Provide TiCDC Canal-JSON Protocol, Support other systems to subscribe to data changes , Be able to monitor 、 cache 、 Full-text index 、 Data analysis 、 Providing data sources for scenarios such as master-slave replication of heterogeneous databases .
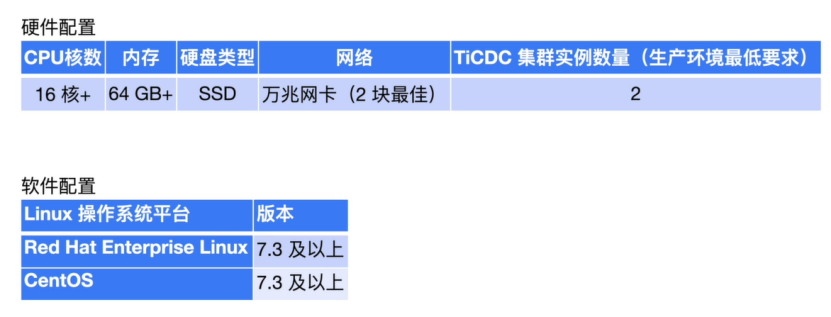
Recommended configuration for production environment
The general production environment requires at least two 16c 64G SSD Hard disk Machine resources of 10 Gigabit network card , If it's a test 、 learning environment , The configuration does not need to be so high , You can also use a node .
TiCDC The deployment environment
There are two kinds of situations : You can follow TiDB Deploy together , You can also expand and deploy later .
Pre use tiup Deploy
Can be in topology.yaml Add to file
tiup cluster deploy jiekexu-tidb v6.0.0 ./topology.yaml --user root -pcdc_servers Agreed to TiCDC On which machines are the services deployed , At the same time, you can specify the service configuration on each machine .
gc-ttl:TiCDC stay PD Set the service level GC safepoint Of TTL (Time To Live) Duration , The unit is in seconds , The default value is 86400, namely 24 Hours .
port:TiCDC The listening port of the service , Default 8300
Later expansion TiCDC
according to Nanny level distributed database TiDB 6.0 Cluster installation manual
Check cluster status tiup cluster status jiekexu-tidb
If the cluster is not started , You have to start tiup cluster start jiekexu-tidb
Edit the expansion configuration file , Prepare to TiCDC node 192.168.75.15/16 Join the cluster .
vim scale-out.yaml cdc_servers: - host: 192.168.75.15 gc-ttl: 86400 data_dir: /tidb-data/cdc-data/cdc-8300 - host: 192.168.75.16 gc-ttl: 86400 data_dir: /tidb-data/cdc-data/cdc-8300Join in 2 individual TiCDC node ,IP by 192.168.75.15/16, Port default 8300, Software deployment defaults to /tidb-deploy/cdc-8300 in , Logs are deployed in /tidb-deploy/cdc-8300/log in , The data directory is in /tidb-data/cdc-data/cdc-8300 in 。
Use tiup For the original TiDB Database cluster expansion TiCDC node .
tiup cluster scale-out jiekexu-tidb scale-out.yaml -uroot -p
[[email protected] ~]# tiup cluster scale-out jiekexu-tidb scale-out.yaml -uroot -ptiup is checking updates for component cluster ...Starting component `cluster`: /root/.tiup/components/cluster/v1.10.2/tiup-cluster scale-out jiekexu-tidb scale-out.yaml -uroot -pInput SSH password: + Detect CPU Arch Name - Detecting node 192.168.75.15 Arch info ... Done - Detecting node 192.168.75.16 Arch info ... Done+ Detect CPU OS Name - Detecting node 192.168.75.15 OS info ... Done - Detecting node 192.168.75.16 OS info ... DonePlease confirm your topology:Cluster type: tidbCluster name: jiekexu-tidbCluster version: v6.0.0Role Host Ports OS/Arch Directories---- ---- ----- ------- -----------cdc 192.168.75.15 8300 linux/x86_64 /tidb-deploy/cdc-8300,/tidb-data/cdc-data/cdc-8300cdc 192.168.75.16 8300 linux/x86_64 /tidb-deploy/cdc-8300,/tidb-data/cdc-data/cdc-8300Attention: 1. If the topology is not what you expected, check your yaml file. 2. Please confirm there is no port/directory conflicts in same host.Do you want to continue? [y/N]: (default=N) y+ [ Serial ] - SSHKeySet: privateKey=/root/.tiup/storage/cluster/clusters/jiekexu-tidb/ssh/id_rsa, publicKey=/root/.tiup/storage/cluster/clusters/jiekexu-tidb/ssh/id_rsa.pub+ [Parallel] - UserSSH: user=tidb, host=192.168.75.16+ [Parallel] - UserSSH: user=tidb, host=192.168.75.14+ [Parallel] - UserSSH: user=tidb, host=192.168.75.15+ [Parallel] - UserSSH: user=tidb, host=192.168.75.13+ [Parallel] - UserSSH: user=tidb, host=192.168.75.12+ [Parallel] - UserSSH: user=tidb, host=192.168.75.11+ [Parallel] - UserSSH: user=tidb, host=192.168.75.17+ [Parallel] - UserSSH: user=tidb, host=192.168.75.17+ [Parallel] - UserSSH: user=tidb, host=192.168.75.17+ [Parallel] - UserSSH: user=tidb, host=192.168.75.17+ Download TiDB components - Download cdc:v6.0.0 (linux/amd64) ... Done+ Initialize target host environments+ Deploy TiDB instance - Deploy instance cdc -> 192.168.75.15:8300 ... Done - Deploy instance cdc -> 192.168.75.16:8300 ... Done+ Copy certificate to remote host…………………… Omit intermediate information ……………………+ Refresh components conifgs - Generate config pd -> 192.168.75.12:2379 ... Done - Generate config pd -> 192.168.75.13:2379 ... Done - Generate config pd -> 192.168.75.14:2379 ... Done - Generate config tikv -> 192.168.75.15:20160 ... Done - Generate config tikv -> 192.168.75.16:20160 ... Done - Generate config tikv -> 192.168.75.17:20160 ... Done - Generate config tidb -> 192.168.75.11:4000 ... Done - Generate config cdc -> 192.168.75.15:8300 ... Done - Generate config cdc -> 192.168.75.16:8300 ... Done - Generate config prometheus -> 192.168.75.17:9090 ... Done - Generate config grafana -> 192.168.75.17:3000 ... Done - Generate config alertmanager -> 192.168.75.17:9093 ... Done+ Reload prometheus and grafana - Reload prometheus -> 192.168.75.17:9090 ... Done - Reload grafana -> 192.168.75.17:3000 ... Done+ [ Serial ] - UpdateTopology: cluster=jiekexu-tidbScaled cluster `jiekexu-tidb` out successfully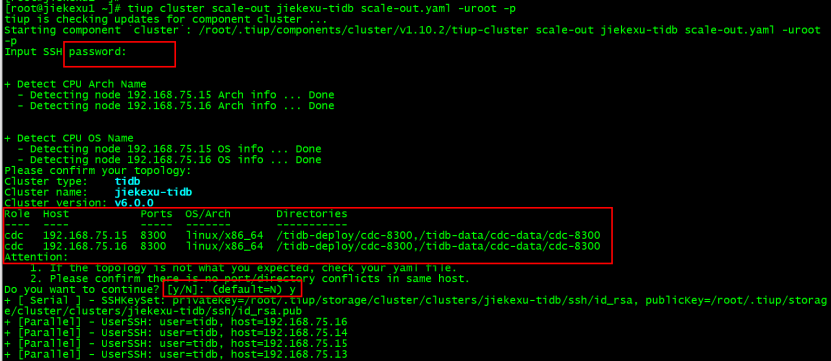
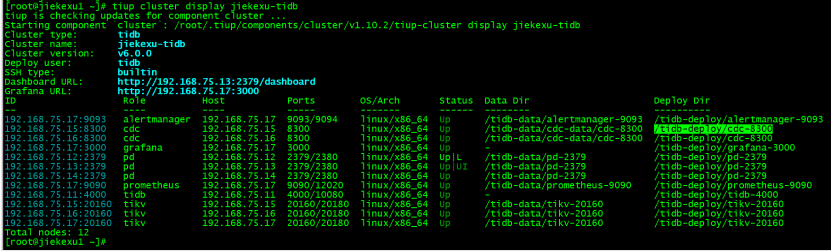
Check the cluster status after deployment , Find out TiCDC It has been deployed to two nodes . We see TiCDC Clustered ID by 192.168.75.15:8300, 192.168.75.16:8300,Status( state ) by UP, Express TiCDC Deployment success 。
Perform volume reduction
tiup cluster scale-in jiekexu-tidb --node 192.168.75.15:8300It only falls here 75.15 among --node The parameter is ID. Expected output Scaled cluster jiekexu-tidb in successfully Information , Indicates that the volume reduction operation is successful .
TiCDC First try of management tools
cdc cli It means passing through cdc binary perform cli Sons command , In the following interface description , adopt cdc binary Direct execution cli command ,PD Listening in IP The address is 192.168.75.12, port 2379.
Use tiup ctl:v6.0.0 cdc Check TiCDC The state of , as follows :
tiup ctl:v6.0.0 cdc capture list --pd=http://192.168.75.12:2379In command --pd==http://192.168.75.12:2379, It can be any one of them PD node ,“is-owner”: true Representative as TiCDC The node is owner node 。 by false Represents the standby node .
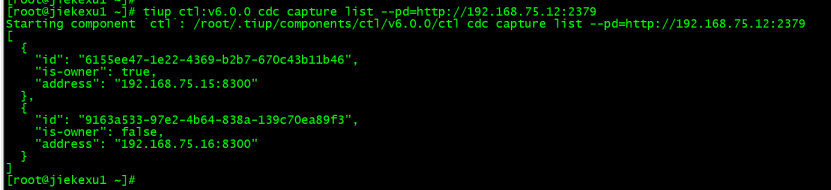
If you use TiUP Tool deployment TiCDC, So use TiUP management , The command can be written as tiup cdc cli
Data synchronization preparation
First, the downstream needs MySQL database , And for MySQL database ( The port number is 3306 ) Add time zone information , Create database jiekexu, And create tables T1 , Be careful not to insert data , Do the following :
192.168.75.12 Installed MySQL5.7.38 Database instance .
su – mysqlmysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root -p mysql -S /mysql/data/mysql3306/socket/mysql3306.sockmysql -uroot -p -P 3306 -S /mysql/data/mysql3306/socket/mysql3306.sockcreate database jiekexu;use jiekexu;create table T1(id int primary key, name varchar(20));select * from T1;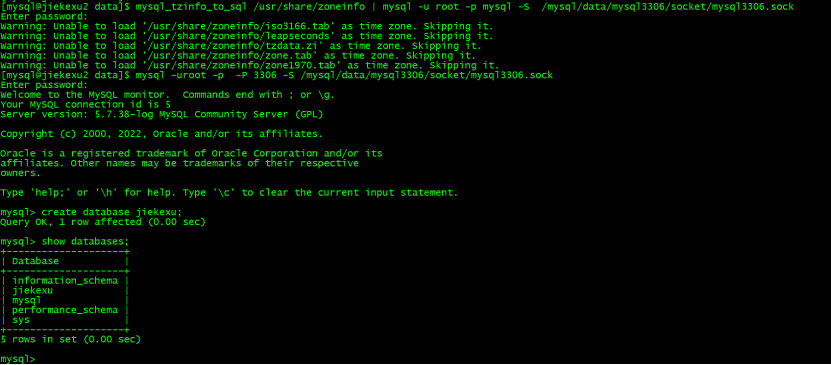
then TiDB End database preparation
create database jiekexu;use jiekexu;create table T1(id int primary key, name varchar(20));select * from T1;
Create synchronization tasks
cd /tidb-deploy/cdc-8300/bin./cdc cli changefeed create --pd=http://192.168.75.12:2379 --sink-uri="mysql://root:[email protected]:3306/" --changefeed-id="simple-replication-task" --sort-engine="unified"[WARN] some tables are not eligible to replicate, []model.TableName{model.TableName{Schema:"test", Table:"t1", TableID:0, IsPartition:false}}Could you agree to ignore those tables, and continue to replicate [Y/N]YCreate changefeed successfully!ID: simple-replication-taskInfo: {"sink-uri":"mysql://root:[email protected]:3306/","opts":{"_changefeed_id":"sink-verify"},"create-time":"2022-06-30T00:14:25.821140534+08:00","start-ts":434246584426037251,"target-ts":0,"admin-job-type":0,"sort-engine":"unified","sort-dir":"","config":{"case-sensitive":true,"enable-old-value":true,"force-replicate":false,"check-gc-safe-point":true,"filter":{"rules":["*.*"],"ignore-txn-start-ts":null},"mounter":{"worker-num":16},"sink":{"dispatchers":null,"protocol":"","column-selectors":null},"cyclic-replication":{"enable":false,"replica-id":0,"filter-replica-ids":null,"id-buckets":0,"sync-ddl":false},"scheduler":{"type":"table-number","polling-time":-1},"consistent":{"level":"none","max-log-size":64,"flush-interval":1000,"storage":""}},"state":"normal","error":null,"sync-point-enabled":false,"sync-point-interval":600000000000,"creator-version":"v6.0.0"}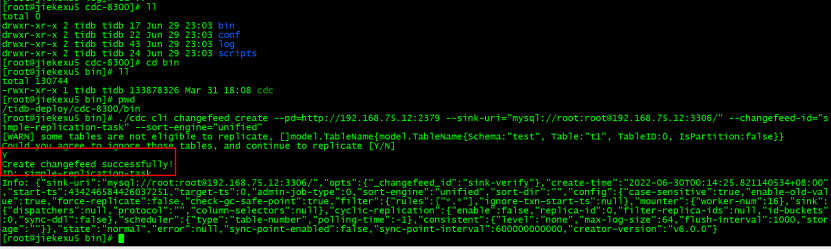
explain :
- –changefeed-id: Syncing tasks ID, The format needs to conform to regular expressions [1]+(-[a-zA-Z0-9]+)*$. If you do not specify this ID,TiCDC It will automatically generate a UUID(version 4 Format ) As ID.
- –sink-uri: Address downstream of synchronization task , It needs to be configured in the following format , at present scheme Support mysql/tidb/kafka/pulsar.
- –sort-engine: Appoint changefeed The sorting engine used . because TiDB and TiKV Using a distributed architecture ,TiCDC Data change records need to be sorted before output . This support unified( Default )/memory/file:
- unified: Prioritize memory sorting , When the memory is insufficient, the hard disk is automatically used to temporarily store data . This option is on by default .
- memory: Sort in memory . Not recommended , When synchronizing a large amount of data, it is easy to cause OOM.
- file: Use disk to stage data completely . Abandoned , It is not recommended to use .
View synchronization task
./cdc cli changefeed list --pd=http://192.168.75.12:2379 [ { "id": "simple-replication-task", "summary": { "state": "normal", "tso": 434246659203137537, "checkpoint": "2022-06-30 00:19:03.469", "error": null } }]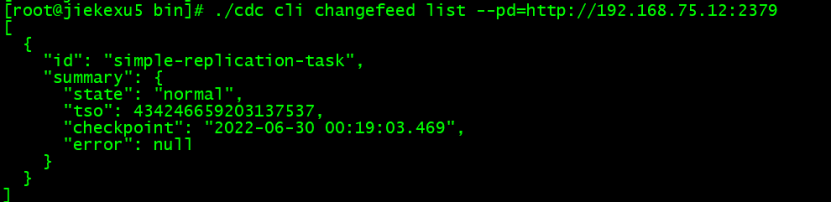
Be careful :“state”: “normal” : Indicates that the task status is normal 。
“tso”: 434246659203137537: Indicates the timestamp information of the synchronization task 。
“checkpoint”: “2022-06-30 00:19:03.469” : Indicates the time of the synchronization task 。
Query the replication task information in detail
{ "info": { "sink-uri": "mysql://root:[email protected]:3306/", "opts": { "_changefeed_id": "sink-verify" }, "create-time": "2022-06-30T00:14:25.821140534+08:00", "start-ts": 434246584426037251, "target-ts": 0, "admin-job-type": 0, "sort-engine": "unified", "sort-dir": "", "config": { "case-sensitive": true, "enable-old-value": true, "force-replicate": false, "check-gc-safe-point": true, "filter": { "rules": [ "*.*" ], "ignore-txn-start-ts": null }, "mounter": { "worker-num": 16 }, "sink": { "dispatchers": null, "protocol": "", "column-selectors": null }, "cyclic-replication": { "enable": false, "replica-id": 0, "filter-replica-ids": null, "id-buckets": 0, "sync-ddl": false }, "scheduler": { "type": "table-number", "polling-time": -1 }, "consistent": { "level": "none", "max-log-size": 64, "flush-interval": 1000, "storage": "" } }, "state": "normal", "error": null, "sync-point-enabled": false, "sync-point-interval": 600000000000, "creator-version": "v6.0.0" }, "status": { "resolved-ts": 434246739838369793, "checkpoint-ts": 434246739313819649, "admin-job-type": 0 }, "count": 0, "task-status": [ { "capture-id": "9163a533-97e2-4b64-838a-139c70ea89f3", "status": { "tables": null, "operation": null, "admin-job-type": 0 } }, { "capture-id": "6155ee47-1e22-4369-b2b7-670c43b11b46", "status": { "tables": null, "operation": null, "admin-job-type": 0 } } ]}Data synchronization test
Verify the synchronization task , Sign in TiDB database , Query just created jiekexu The table below the database T1, And insert three rows of data , As shown below :
The source side inserts data
insert into T1 values(1,'jiekexu');insert into T1 values(2,'jiekexu dba');insert into T1 values(2,'jiekexu tidb');select * from T1;Sign in MySQL database , Inquire about jiekexu The table below the database T1, It is found that the database has been synchronized , As shown below :
mysql> select * from T1;+----+--------------+| id | name |+----+--------------+| 1 | jiekexu || 2 | jiekexu dba || 3 | jiekexu tidb |+----+--------------+3 rows in set (0.00 sec)
Source update 、 Delete data
mysql> update T1 set name='jiekexu tidb dba' where id=3;Query OK, 1 row affected (0.01 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from T1;+----+------------------+| id | name |+----+------------------+| 1 | jiekexu || 2 | jiekexu dba || 3 | jiekexu tidb dba |+----+------------------+3 rows in set (0.00 sec)mysql> delete from T1 where id=1;Query OK, 1 row affected (0.01 sec)mysql> select * from T1;+----+------------------+| id | name |+----+------------------+| 2 | jiekexu dba || 3 | jiekexu tidb dba |+----+------------------+2 rows in set (0.01 sec)Target end MySQL End view
mysql> select * from T1;+----+------------------+| id | name |+----+------------------+| 1 | jiekexu || 2 | jiekexu dba || 3 | jiekexu tidb dba |+----+------------------+3 rows in set (0.00 sec)mysql> select * from T1;+----+------------------+| id | name |+----+------------------+| 2 | jiekexu dba || 3 | jiekexu tidb dba |+----+------------------+2 rows in set (0.00 sec)Add at the source 、 modify 、 Delete column
alter table T1 add addr varchar(50);alter table T1 modify name varchar(32);alter table t1 add changeTime datetime default now();Alter table t1 drop column changeTime;The target side can also synchronize normally .
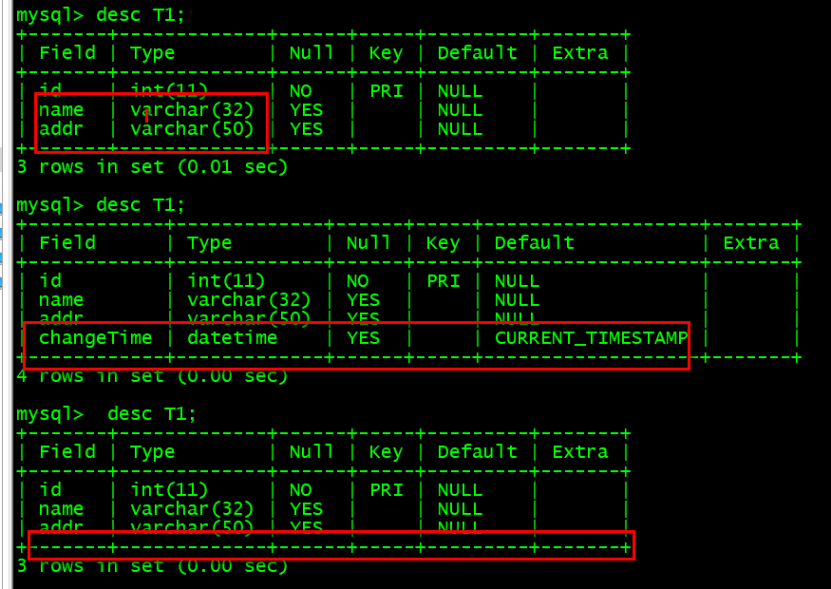
Create a new table data insertion test at the source
CREATE TABLE `Test` ( `id` int(11) NOT NULL, `name` varchar(32) DEFAULT NULL, `addr` varchar(50) DEFAULT NULL, PRIMARY KEY (`id`) );insert into Test values(1,'jiekexu','beijing');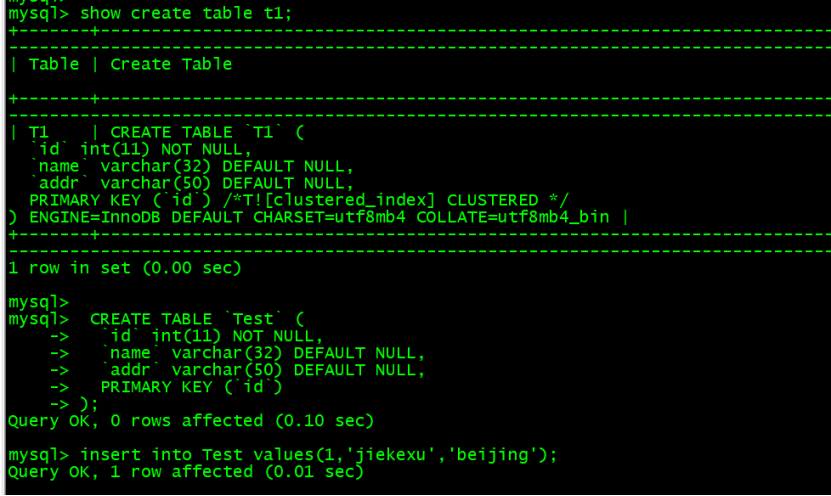
Target end MySQL End view

Stop the synchronization task
./cdc cli changefeed --helpManage changefeed (changefeed is a replication task)Usage: cdc cli changefeed [flags] cdc cli changefeed [command]Available Commands: create Create a new replication task (changefeed) cyclic (Experimental) Utility about cyclic replication list List all replication tasks (changefeeds) in TiCDC cluster pause Pause a replication task (changefeed) query Query information and status of a replication task (changefeed) remove Remove a replication task (changefeed) resume Resume a paused replication task (changefeed) statistics Periodically check and output the status of a replication task (changefeed) update Update config of an existing replication task (changefeed)./cdc cli changefeed pause --pd=192.168.75.12:2379 --changefeed-id simple-replication-task./cdc cli changefeed pause --pd=http://192.168.75.12:2379 --changefeed-id simple-replication-task
Be careful :pause When you stop a task ,pd You can also not follow http:// agreement , No mistake. .
Resume synchronization task
./cdc cli changefeed resume --pd=http://192.168.75.12:2379 --changefeed-id simple-replication-task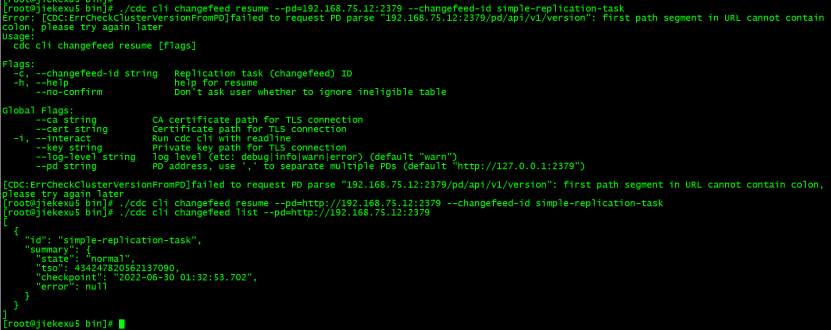
Be careful :Pd You need to follow http agreement , Otherwise, it will report a mistake .
Delete synchronization task
./cdc cli changefeed remove --pd=http://192.168.75.12:2379 --changefeed-id simple-replication-taskTiCDC The limitation of

Requirements for effective indexing
TiCDC Only tables with at least one valid index can be synchronized , The definition of a valid index is as follows :
Primary key (PRIMARY KEY) Is a valid index .
A unique index that meets the following conditions (UNIQUE INDEX) Is a valid index :
- Each column in the index is clearly defined as non empty in the table structure (NOT NULL).
- The virtual build column does not exist in the index (VIRTUAL GENERATED COLUMNS).
TiCDC from 4.0.8 Version start , You can synchronize tables without valid indexes by modifying the task configuration , However, the guarantee of data consistency has been weakened . For specific usage and precautions, refer to synchronizing tables without effective indexes .
Temporarily unsupported scenarios
at present TiCDC The currently unsupported scenarios are as follows :
- It is not supported to use alone RawKV Of TiKV colony .
- Temporarily not supported in TiDB Created in SEQUENCE Of DDL Operation and SEQUENCE function . Upstream TiDB Use SEQUENCE when ,TiCDC The upstream execution will be ignored SEQUENCE DDL operation / function , But use SEQUENCE Functional DML The operation can be synchronized correctly .
- Provide partial support for scenarios with large transactions upstream , See TiCDC Whether the synchronization of large transactions is supported ? Is there any risk ?
Reference link :
边栏推荐
- Nmap and masscan have their own advantages and disadvantages. The basic commands are often mixed to increase output
- Hcie security Day10: six experiments to understand VRRP and reliability
- Talk about daily newspaper design - how to write a daily newspaper and what is the use of a daily newspaper?
- Qt6 QML Book/Qt Quick 3D/基础知识
- Quickly distinguish slices and arrays
- Is it OK for fresh students to change careers to do software testing? The senior answered with his own experience
- Baohong industry | good habits that Internet finance needs to develop
- Monkey/ auto traverse test, integrate screen recording requirements
- Pytorch sets the weight and bias of the model to zero
- From the behind the scenes arena of the ice and snow event, see how digital builders can ensure large-scale events
猜你喜欢

Hcie security Day11: preliminarily learn the concepts of firewall dual machine hot standby and vgmp
Getting started with postman -- environment variables and global variables
Preliminary practice of niuke.com (11)

String and+

Xai+ network security? Brandon University and others' latest "interpretable artificial intelligence in network security applications" overview, 33 page PDF describes its current situation, challenges,
How to handle wechat circle of friends marketing activities and share production and release skills
JS three families

JVM JNI and PVM pybind11 mass data transmission and optimization

运维各常用命令总结

In 2021, the global foam protection packaging revenue was about $5286.7 million, and it is expected to reach $6615 million in 2028
随机推荐
《ActBERT》百度&悉尼科技大学提出ActBERT,学习全局局部视频文本表示,在五个视频-文本任务中有效!...
Memory analyzer (MAT)
The "boss management manual" that is wildly spread all over the network (turn)
Baohong industry | good habits that Internet finance needs to develop
How to choose cache read / write strategies in different business scenarios?
MySQL——索引
Gauss elimination solves linear equations (floating-point Gauss elimination template)
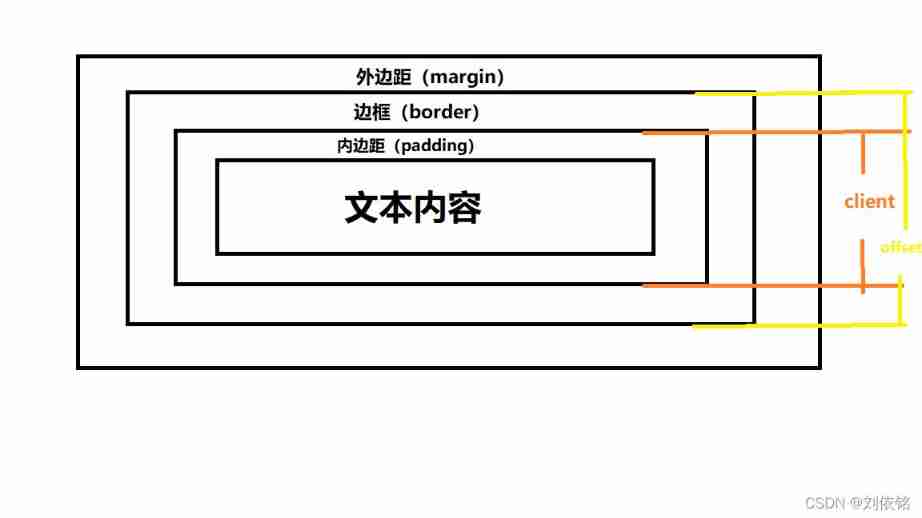
Offset related concepts + drag modal box case
XAI+网络安全?布兰登大学等最新《可解释人工智能在网络安全应用》综述,33页pdf阐述其现状、挑战、开放问题和未来方向
Getting started with postman -- built-in dynamic parameters, custom parameters and assertions
Xai+ network security? Brandon University and others' latest "interpretable artificial intelligence in network security applications" overview, 33 page PDF describes its current situation, challenges,
Transformation between yaml, Jason and Dict
Haven't expressed the artifact yet? Valentine's Day is coming. Please send her a special gift~
Kubernetes 通信异常网络故障 解决思路
Gee calculated area
Interval product of zhinai sauce (prefix product + inverse element)
Qualcomm platform WiFi -- P2P issue
2022 melting welding and thermal cutting examination materials and free melting welding and thermal cutting examination questions
The global industrial design revenue in 2021 was about $44360 million, and it is expected to reach $62720 million in 2028. From 2022 to 2028, the CAGR was 5.5%
MySQL - SQL injection problem