当前位置:网站首页>We made a medical version of the MNIST dataset, and found that the common automl algorithm is not so easy to use
We made a medical version of the MNIST dataset, and found that the common automl algorithm is not so easy to use
2020-11-08 13:02:00 【U4u5y4 assault rifle】

author | Devil 、 Zhang Qian
source | Almost Human
Shanghai Jiaotong University researchers create a new open medical image data set MedMNIST, And Design 「MedMNIST Categorical decathlon 」, To promote AutoML Algorithm in the field of medical image analysis research .
stay AI In the development of Technology , Data sets play an important role . However , There are many difficulties in the creation of medical data sets , Such as data acquisition 、 Data tagging, etc .
In the near future , Researchers at Shanghai Jiaotong University created a medical image dataset MedMNIST, common contain 10 Preprocessing open medical image datasets ( Its data comes from many different data sources , And after pretreatment ).
Project address :
https://medmnist.github.io/
Address of thesis :
https://arxiv.org/pdf/2010.14925v1.pdf
GitHub Address :
https://github.com/MedMNIST/MedMNIST
Dataset download address :
https://www.dropbox.com/sh/upxrsyb5v8jxbso/AADOV0_6pC9Tb3cIACro1uUPa?dl=0
and MNIST The dataset is the same ,MedMNIST Data sets In lightweight 28 × 28 Performing classification tasks on images , The tasks involved cover the main medical image modes and diverse data scales . According to the researchers' design ,MedMNIST Data sets have the following features :
educative nature : The multimodal data in this dataset comes from multiple open medical image datasets with knowledge sharing license , It can be used for educational purposes .
Standardization : The researchers preprocessed the data , Convert it to the same format , therefore Users do not need to have background knowledge to use .
diversity : Multimodal datasets cover multiple data scales ( from 100 To 100,000) And tasks ( Two classification / Many classification 、 Ordered regression and multi label ).
Lightweight : The image size is 28 × 28, It is convenient for rapid prototyping and testing, and multimodal machine learning and AutoML Algorithm .
suffer Medical Segmentation Decathlon( Medical split decathlon ) Inspired by the , The study also designed MedMNIST Classification Decathlon(MedMNIST Categorical decathlon ), As AutoML Benchmark in the field of medical image classification .
It's all about 10 Evaluation on data sets AutoML Performance of the algorithm , The algorithm is not adjusted manually . The researchers compared the performance of several baseline methods , Including early stop ResNet [6]、 Open source AutoML Tools (auto-sklearn [7] and AutoKeras [8]), And commercialization AutoML Tools (Google AutoML Vision). The researchers hope that MedMNIST Classification Decathlon Can promote AutoML Research in the field of medical image analysis .


Ten preprocessed datasets
MedMNIST Data set containing 10 Preprocessing data sets , Covering the main data modes ( Such as X Photo chip 、OCT、 ultrasonic 、CT)、 Diverse classification tasks ( Two classification / Many classification 、 Ordered regression and multi label ) And data scale . As shown in the table 1 Shown , The diversity of data set design leads to the diversity of task difficulty , And that's what AutoML What benchmarks need . The researchers preprocessed each data set , Divide it into training - verification - Test subsets .
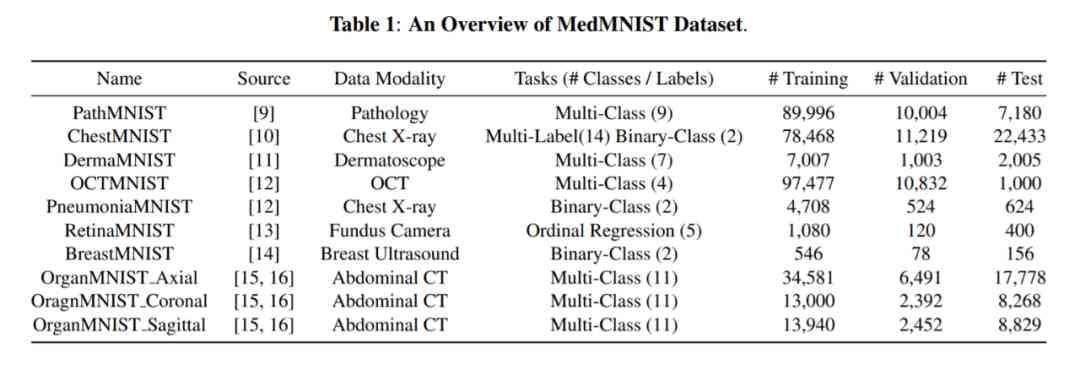
surface 1:MedMNIST Data set Overview , Covers the name of the dataset 、 source 、 Data mode 、 Task and dataset segmentation .
The data sets of these modes cover X Photo chip 、OCT、 ultrasonic 、CT、 Pathological section 、 Dermoscopy, etc , It's about colorectal cancer 、 Retinal diseases 、 Breast disease 、 Liver tumor and many other medical fields .

new type AutoML Medical image benchmark
As mentioned earlier , The researchers were inspired by the medical split decathlon , Designed 「MedMNIST Categorical decathlon 」, Designed to create lightweight... For medical image analysis AutoML The benchmark . It's all about 10 Evaluation on data sets AutoML Performance of the algorithm , The algorithm is not adjusted manually . The researchers compared the performance of several baseline methods , See the table below 2:
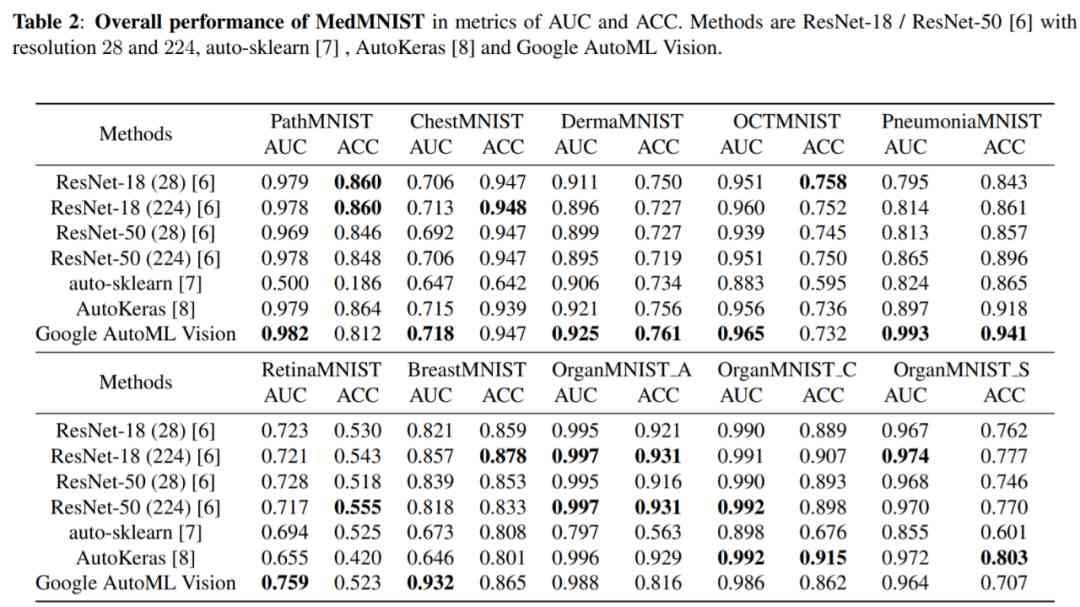
From the table 2 It can be seen that ,Google AutoML Vision The overall performance is good , But it's not always the best , Sometimes even lose to ResNet-18 and ResNet-50.auto-sklearn It doesn't perform well on most datasets , This shows that the performance of the typical statistical machine learning algorithm on the medical image data set is poor .AutoKeras Good performance on large data sets , Relatively poor performance on small data sets . No algorithm can achieve good generalization performance on these ten datasets , It helps to explore AutoML The algorithm is in different data modes 、 Generalization effects on task and scale datasets .
Next , Let's look at different methods in the training set 、 Performance on verification set and test set . Here's the picture 2 Shown , The algorithm is easy to over fit on small data sets .
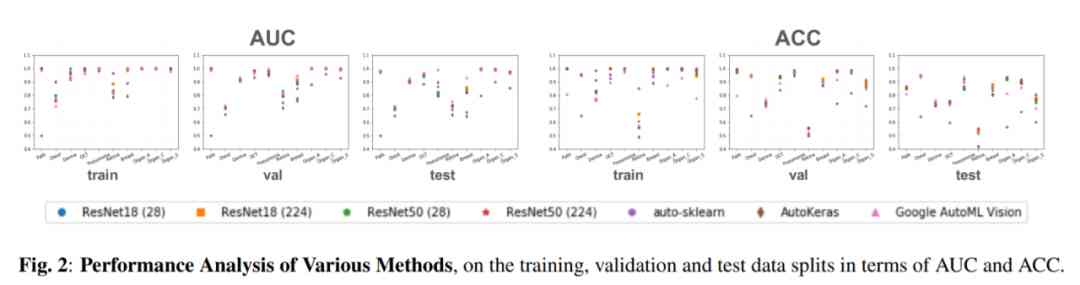
Google AutoML Vision It can better control the over fitting problem , and auto-sklearn There is a serious over fitting . It can be inferred from this that , For learning algorithms , Appropriate reductive bias It's very important . We can still do that MedMNIST Explore different regularization techniques on datasets , Such as data enhancement 、 Model integration 、 Optimization algorithm, etc .

How to find data sets ?
Besides the medical field , Data sets from other fields are sometimes difficult to access , This requires us to master some common data collection methods and common resources . lately ,Medium A blogger on introduced several commonly used data collection sources :
1. Awesome Data
This is a GitHub The repository , Contains multiple different categories of datasets .
link :
https://github.com/awesomedata/awesome-public-datasets
2. Data Is Plural
This is a dataset resource presented in spreadsheet form , from 2015 It's been updated regularly since , The latest issue is 2020 year 10 month 28 The resources of the day , So some of the resources are very new .
link :https://docs.google.com/spreadsheets/d/1wZhPLMCHKJvwOkP4juclhjFgqIY8fQFMemwKL2c64vk/edit#gid=0
3. Kaggle Datasets
Kaggle Datasets Provides preview and summary information about many datasets , Very suitable for retrieving data sets for specific topics .
link :
https://www.kaggle.com/datasets
4. Data.world
and Kaggle equally ,Data.world Provides a series of user contributed datasets , It also provides a platform for companies to store and organize their own data .
link :
https://data.world/
5. Google Dataset Search
Dataset search It's Google 2018 A new search function launched in . If you're looking for data from a particular topic or source , This tool is worth trying .
link :
https://datasetsearch.research.google.com/
6. OpenDaL
OpenDal It's also a dataset search tool , You can search in many ways , For example, according to the creation time or frame a certain area on the map .
link :
https://opendatalibrary.com/
7. Pandas Data Reader
Pandas Data Reader It can help you pull data from online resources , And then apply it to Python pandas DataFrame in . Most of this is financial data .
link :
https://pandas-datareader.readthedocs.io/en/latest/remote_data.html
8. from API get data
utilize Python from API Data acquisition is also a common method used by data scientists , Please refer to the following tutorial for specific operation steps .
link :
https://towardsdatascience.com/how-to-get-data-from-apis-with-python-dfb83fdc5b5b
Reference link :https://towardsdatascience.com/the-top-10-best-places-to-find-datasets-8d3b4e31c442
????
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
About PaperWeekly
PaperWeekly It's a recommendation 、 Reading 、 Discuss 、 An academic platform for reporting the achievements of the frontier papers on artificial intelligence . If you study or engage in AI field , Welcome to clicking on the official account 「 Communication group 」, The little assistant will take you into PaperWeekly In the communication group .


版权声明
本文为[U4u5y4 assault rifle]所创,转载请带上原文链接,感谢
边栏推荐
- 用科技赋能教育创新与重构 华为将教育信息化落到实处
- Ali teaches you how to use the Internet of things platform! (Internet disk link attached)
- Windows下快递投递柜、寄存柜的软件初探
- Get PMP certificate at 51CTO College
- Flink从入门到真香(3、从集合和文件中读取数据)
- Istio traffic management -- progress gateway
- Adobe Lightroom /Lr 2021软件安装包(附安装教程)
- What is SVG?
- 2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
- Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
猜你喜欢

Hematemesis! Alibaba Android Development Manual! (Internet disk link attached)
![[Python 1-6] Python tutorial 1 -- number](/img/3b/00bc81122d330c9d59909994e61027.jpg)
[Python 1-6] Python tutorial 1 -- number
Returning to the third place in the world, what did Xiaomi do right?

Major changes in Huawei's cloud: Cloud & AI rises to Huawei's fourth largest BG with full fire
Bccoin tells you: what is the most reliable investment project at the end of the year!
PMP experience sharing
wanxin finance
AQS analysis
nat转换的ip跟端口ip不相同的解决方法
Eight ways to optimize if else code
随机推荐
Hematemesis! Alibaba Android Development Manual! (Internet disk link attached)
华为在5G手机市场占据绝对优势,市调机构对小米的市占出现分歧
Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
阿里云视频云技术专家 LVS 演讲全文:《“云端一体”的智能媒体生产制作演进之路》
WLAN 直连(对等连接或 P2P)调研及iOS跨平台调研
A scheme to improve the memory utilization of flutter
AQS解析
供货紧张!苹果被曝 iPhone 12 电源芯片产能不足
2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
Q & A and book giving activities of harbor project experts
笔试面试题目:盛水最多的容器
重返全球第三,小米做对了什么?
Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
Google's AI model, which can translate 101 languages, is only one more than Facebook
Ubuntu20.04下访问FTP服务器乱码问题+上传文件
2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
Share the experience of passing the PMP examination
分布式文档存储数据库之MongoDB基础入门
How to write a resume and project
Why is Schnorr Signature known as the biggest technology update after bitcoin segwit