当前位置:网站首页>漫画|讲解一下如何写简历&项目
漫画|讲解一下如何写简历&项目
2020-11-08 11:21:00 【osc_ewph0o9p】







star法写项目的案例:
深圳浪尖聊大数据有限公司 2018.3-至今
日志中心建设 项目周期2020.2.10-2020.4.20
成就经历简述
2020.2.10-2020.5.20,在深圳浪尖聊大数据有限公司与团队一起完成了日志中心建设,提升了公司日志的查询,故障发现及处理的效率。
Situation:
1.深圳浪尖聊大数据有限公司有包括官网,游戏app,电商app,公众号后台,redis等存储系统及服务后台,日志需要采集及统一处理。
2.需要提供一个便于部署的日志采集agent,实时采集日志。支持8w+条/s数据量。
3.要设计提供一个统一的日志检索中心,方便用户查询日志,避免登陆机器查询。
4.需要设计一个规则引擎,用户便捷的编写规则,然后实时对日志数据执行规则,及时发现日志异常,以便及时处理。
5.需要建设告警系统,实现同比,环比,频率等功能,相同告警的统计及合并告警,减少无效告警次数。
6.采集系统部署,规则配置,告警配置,日志检索,需要设计一个统一的UI,增加用户权限管理功能。
Task:
团队的任务与目标:
1.设计一个日志采集器,实时采集应用日志,上报到kafka。
2.调研设计规则引擎,规则编写要简单,支持语法要多样,要利用现有实时计算平台,如flink。
3.调研设计告警系统,支持同比,环比,循环,频率,固定间隔及告警聚合统计功能,减少无效告警,并且告警要实时。
4.设计web UI及相应后台,方便用户一键部署采集系统,下发日志规则及告警规则和便捷的查询日志定位问题。
我的任务及目标
1.调研用户规则编写的需求。
2.调研现有的规则引擎,根据用户的需求选择最恰当的作为基础规则引擎。
3.设计规则引擎的实现内核架构,整合实时计算引擎。
4.部署,测试,压测规则引擎,针对性能优化,使其满足性能需求。
5.编写脚本实现规则引擎故障自动拉起。
Action:
我的工作及任务:
1.用了两天时间,调研,收集用户的日志规则需求。
2.花了一周时间,调研,对比现有的规则引擎,easyrules,groovy,drools等。最后根据语法编写复杂度,性能等,确定利用groovy来实现自己的规则引擎。
3.用三天时间,实现对groovy作为规则引擎细致调研,设计groovy作为规则引擎的整体架构及确定与flink整合的方案。
4.花一周时间,完成规则引擎的核心代码,成功整合flink。
5.花三天时间,进行初步的测试,压测及调优,同时完成监控脚本的编写。
6.花一天时间,完成与其他同事联调。
Result:
项目整体成果:
经过两个月的努力,完成了公司的日志中心的全部功能,有了规则引擎及告警系统,应用的异常能够及时发现并告警,提升了处理异常的效率,利用日志中心大大提升了用户日志检索排查的效率。
我的成果:
1.独立调研,设计,实现了实时规则引擎系统。
2.规则下发实时生效。
3.目前以及支持2k+规则,每秒钟处理数据量 1w条。
4.辅助公司发现应用异常若干,避免了巨大故障带来的损失。
5.过程中进一步掌握的技术有订阅发布系统Apollo,flink,多线程,groovy内核,并发集合等等。

项目简介
公司服务多,比如存储系统,app后台等,需要提供日志查询系统,便于检索日志;日志规则引擎 便于不同应用配置不同规则,以找出日志中的异常;日志异常告警系统,以便即使发现任务异常,方便排查服务故障。
项目职责:
主要负责规则引擎这一环,主要内容及成就如下:
1.调研常见的规则引擎,easyrules,drools,qlexpress,groovy引擎等等,通过性能,易用性,易维护性等对比,最终决定用groovy。
2.设计基于groovy规则引擎的内核架构,主要设计内容:
规则订阅发布发布系统,Apollo。
规则并发处理模型,多线程及并发集合。
GroovyClassloader内核及规则加载机制,及对内存的优化,预编译等。
整合flink。
3.独立完成,功能测试,压测,部署,及自动故障处理脚本的编写。
4.结果:截止目前上线规则1k+,处理1w条/s,可以很简单横向扩展。

错误的写法:
为人诚实谦虚,勤奋,吃苦耐劳,有团队意识,责任心强,善于沟通,具有良好的团队合作意识;技术功底扎实,具有较强的钻研精神和学习能力;性格比较乐观外向,喜欢打篮球,台球。
正确的写法:
热爱运动,爬山,篮球,桌球。
极客、热爱技术、热爱开源
编程语言:掌握java,scala,shell,并且对多线程,高并发,jvm调优有一定经验。
基础框架:掌握netty,dubbo,mysql,redis,mongodb等。
Spark:精通。精读过spark core ,spark sql spark streaming的源码,做过二次开发。
Flink:精通。阅读过flink源码,使用flink做过实时OLAP平台,DDL语法解析,实图,虚拟列均支持。
Hadoop:掌握。
Hbase:掌握。熟悉hbase存储结构,rowkey设计经验足,使用过hbase存储百TB级别的表。。
Hive:掌握。hive做数仓的经验,对hive的数据倾斜处理经验丰富,处理过百TB以上级别的数据。
Kafka:精通。精读过kafka源码,对底层存储设计,生产消费原理及模型理解比较深入,处理过100w/s数据量。
Clickhouse:掌握。使用clickhouse作为指标存储的底层,加速展示。
ElasticSearch:掌握。




版权声明
本文为[osc_ewph0o9p]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4395239/blog/4708049
边栏推荐
- 2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
- Second assignment
- How does spotify drive data-driven decision making?
- 【计算机网络】学习笔记,第三篇:数据链路层(谢希仁版)
- Dogs can also operate drones! You're right, but it's actually an autonomous drone - you know
- Introduction to mongodb foundation of distributed document storage database
- 解析Istio访问控制
- Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
- 糟糕,系统又被攻击了
- 笔试面试题目:求缺失的最小正整数
猜你喜欢

How TCP protocol ensures reliable transmission
Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
学习小结(关于深度学习、视觉和学习体会)
推荐一部经济科普视频,很有价值!
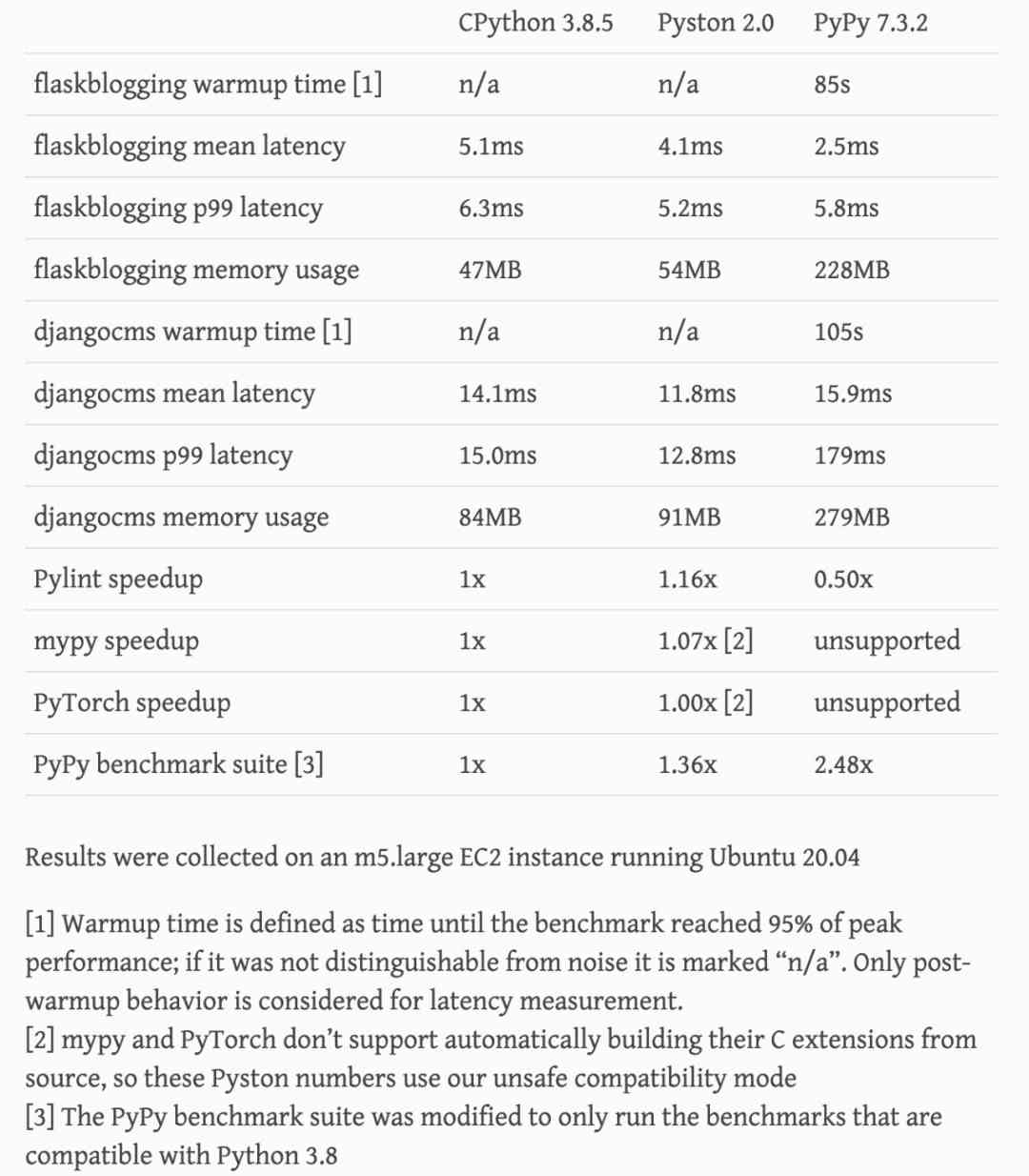
It's 20% faster than python. Are you excited?
狗狗也能操作无人机!你没看错,不过这其实是架自动驾驶无人机 - 知乎
笔试面试题目:盛水最多的容器

C语言I博客作业03
vivoS7e和vivoS7的区别 哪个更值得入手
为 Docsify 自动生成 RSS 订阅
随机推荐
计算机网络基本概念(五)局域网基本原理
413【毕设课设】基于51单片机无线zigbee无线智能家居光照温湿度传输监测系统
How to deploy pytorch lightning model to production
Windows10关机问题----只有“睡眠”、“更新并重启”、“更新并关机”,但是又不想更新,解决办法
比Python快20%,就问你兴不兴奋?
蘑菇街电商交易平台服务架构及改造优化历程(含PPT)
Rust:命令行参数与环境变量操作
The difference between vivoy 73s and glory 30 Youth Edition
当Kubernetes遇到机密计算,看阿里巴巴如何保护容器内数据的安全!(附网盘链接)
Flink的sink实战之一:初探
Mate 40系列发布 搭载华为运动健康服务带来健康数字生活
Python basic syntax variables
11 server monitoring tools commonly used by operation and maintenance personnel
VC + + specified directory file output by time
Written interview topic: looking for the lost pig
We interviewed the product manager of SQL server of Alibaba cloud database, and he said that it is enough to understand these four problems
Japan PSE certification
Adobe media encoder /Me 2021软件安装包(附安装教程)
Xamarin deploys IOS from scratch Walterlv.CloudKeyboard application
ArrayList源码分析