当前位置:网站首页>Style conversion model style_ Transformer project instance pytorch implementation
Style conversion model style_ Transformer project instance pytorch implementation
2022-07-28 12:00:00 【Mr. Xiaocai】
Style transformation model style_transformer Project instance pytorch Realization
Have you ever thought about it , Use machine learning to draw , today , I will take you hand in hand into the deep learning model neural style Code practice .
neural-style Model is a model of style transfer , yes GitHub Last great project , So what is style transfer , Let's take a simple example :
The theoretical guidance of this project comes from the thesis :Perceptual Losses for Real-Time Style Transfer and Super-Resolution
One . Related work
Related neural network architecture : The relevant feedforward neural network architecture of this paper is based on “Deep residual learning for image recognition. ” as well as “Training and investigating residual nets.” Two papers .
Relevant image generation method : The method of image generation in this paper is based on the paper “Inverting visual representations with convolutional networks”, But it is not used Pixel-Loss Function, Instead, the perceptual loss function is used to replace the loss function of the pixel by pixel gap . This method applies feedforward neural network , And Gatys Used in the paper “Understanding deep image representations by inverting them” The method has the same effect but faster .
Two . Implementation details
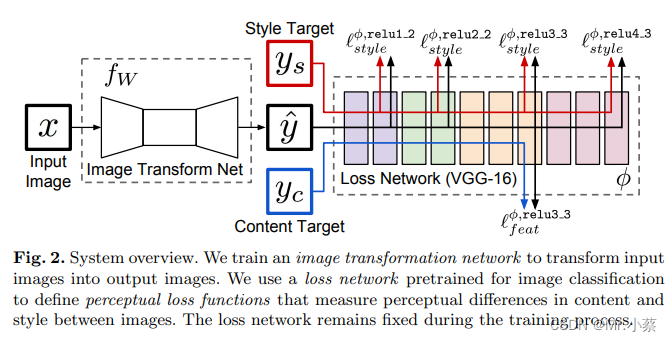
Image map 2 It's shown in , Our system consists of two parts : A picture conversion network f w fw fw And a loss network ϕ \phi ϕ( Used to define a series of loss functions l 1 , l 2 , l 3 l_1, l_2, l_3 l1,l2,l3), Image conversion network is a deep residual network , The parameter is weight W W W, It puts the input picture x x x By mapping y ^ = f w ( x ) \hat y=fw(x) y^=fw(x) Convert to output picture y ^ \hat y y^, Each loss function calculates a scalar value l i ( y ^ , y i ) l_i(\hat y,y_i) li(y^,yi), Measuring output y ^ \hat y y^ And the target image y i y_i yi The gap between . Image conversion network is used SGD Training ( Code implementation adopts Adam), Make the weighted sum of a series of loss functions keep decreasing .
chart 2: System Overview . On the left is Generator, The right side is pre trained vgg16 The Internet ( Always fixed ).
Loss network ϕ \phi ϕ Is able to define a feature ( Content ) Loss l f e a t ϕ l_{feat}^{\phi} lfeatϕ And a loss of style l s t y l e ϕ l_{style}^{\phi} lstyleϕ, Measure the gap between content and style . For each input image x x x We have a content goal y c y_c yc A style goal y s y_s ys, For style conversion , Content target y c y_c yc It's the input image x x x, Output image y y y, The output image should be y s y_s ys Combine content with x = y c x=y_c x=yc On . We train a network for each target style . For single image super-resolution reconstruction , The input image x x x Is a low resolution input , The target content is a real high-resolution image , Style reconstruction does not use . We train a network for each super-resolution factor .
3、 ... and . Image conversion network
Bright spot : Use residual network down sampling input image, Then a new one is generated by up sampling interpolation output image.
1. Use the residual network as follows :

note: The author compares the use of residual block and normal convolutional network The performance of the , Such as Fig1 Shown , Results show residual block It will converge faster , But the end result is similar . The author speculates that the possible residual network may perform better in deeper Networks .
Four . Loss Functions details
1. Content Loss Function
We do not recommend pixel by pixel comparison , It's about using VGG Calculate advanced features ( Content ) Express , This method is different from that artistic style Use VGG-19 Extracting style features is the same , The formula :
Find an image y ^ \hat y y^ Minimize the feature loss of the lower layer , Can often be produced visually and y y y Indistinguishable images , If high-rise buildings are used to rebuild , The content and global structure will be preserved , But color, texture and precise shape no longer exist . Using a feature loss to train our image conversion network can make the output very close to the target image y, But it's not to let them make a perfect match .
2. Style Reconstruction Loss
features ( Content ) The loss penalizes the output image ( When it deviates from its goal y y y when ), So we also hope to punish the deviation in style : Color , texture , A common pattern , Other aspects . In order to achieve this effect Gatys Et al. Proposed the loss function of the following style reconstruction .
among ϕ j ( x ) \phi_j(x) ϕj(x) On behalf of the Internet ϕ \phi ϕ Of the j j j layer , Input is x x x. The shape of the feature map is C j × H j × W j C_j × H_j × W_j Cj×Hj×Wj、 Definition Gram matrix G j ϕ ( x ) G^{\phi}_j(x) Gjϕ(x) by C j × C j C_j × C_j Cj×Cj matrix ( Characteristic matrix ) The elements come from :
If we put ϕ j ( x ) \phi_j(x) ϕj(x) Understand as a C j C_j Cj The characteristics of dimensions , The size of each feature is H j × W j H_j × W_j Hj×Wj, Then the left side of the above formula G j ( x ) G_j(x) Gj(x) Even with C j C_j Cj The eccentricity of the dimension is proportional to the covariance . Each grid location can be regarded as an independent sample . Therefore, it can grasp which feature can drive other information .
The style loss function is to output pictures y ^ \hat y y^ And target pictures y y y Between gram matrix :
5、 ... and . Code implementation
1. Style change network :
# Obviously, it is the style conversion module
class TransformerNet(nn.Module):
def __init__(self):
super(TransformerNet, self).__init__()
# Initial convolution layers
self.conv1 = ConvLayer(3, 32, kernel_size=9, stride=1)
self.in1 = nn.InstanceNorm2d(32, affine=True)
self.conv2 = ConvLayer(32, 64, kernel_size=3, stride=2)
self.in2 = nn.InstanceNorm2d(64, affine=True)
self.conv3 = ConvLayer(64, 128, kernel_size=3, stride=2)
self.in3 = nn.InstanceNorm2d(128, affine=True)
# Residual layers
self.res1 = ResidualBlock(128)
self.res2 = ResidualBlock(128)
self.res3 = ResidualBlock(128)
self.res4 = ResidualBlock(128)
self.res5 = ResidualBlock(128)
# Upsampling Layers
self.deconv1 = UpsampleConvLayer(128, 64, kernel_size=3, stride=1, upsample=2)
self.in4 = nn.InstanceNorm2d(64, affine=True)
self.deconv2 = UpsampleConvLayer(64, 32, kernel_size=3, stride=1, upsample=2)
self.in5 = nn.InstanceNorm2d(32, affine=True)
self.deconv3 = ConvLayer(32, 3, kernel_size=9, stride=1)
# Non-linearities
self.relu = nn.ReLU()
def forward(self, x):
y = self.relu(self.in1(self.conv1(x)))
y = self.relu(self.in2(self.conv2(y)))
y = self.relu(self.in3(self.conv3(y)))
y = self.res1(y)
y = self.res2(y)
y = self.res3(y)
y = self.res4(y)
y = self.res5(y)
y = self.relu(self.in4(self.deconv1(y)))
y = self.relu(self.in5(self.deconv2(y)))
y = self.deconv3(y)
return y
2. Residual module
class ResidualBlock(nn.Module):
"""ResidualBlock introduced in: https://arxiv.org/abs/1512.03385 recommended architecture: http://torch.ch/blog/2016/02/04/resnets.html """
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in1 = nn.InstanceNorm2d(channels, affine=True)
self.conv2 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in2 = nn.InstanceNorm2d(channels, affine=True)
self.relu = nn.ReLU()
def forward(self, x):
residual = x
out = self.relu(self.in1(self.conv1(x)))
out = self.in2(self.conv2(out))
out = out + residual
return out
3. Up sampling module
# Obviously, it is the upper sampling module
class UpsampleConvLayer(nn.Module):
"""UpsampleConvLayer Upsamples the input and then does a convolution. This method gives better results compared to ConvTranspose2d. ref: http://distill.pub/2016/deconv-checkerboard/ """
def __init__(self, in_channels, out_channels, kernel_size, stride, upsample=None):
super(UpsampleConvLayer, self).__init__()
self.upsample = upsample
reflection_padding = kernel_size // 2
self.reflection_pad = nn.ReflectionPad2d(reflection_padding)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
x_in = x
if self.upsample:
x_in = nn.functional.interpolate(x_in, mode='nearest', scale_factor=self.upsample)
out = self.reflection_pad(x_in)
out = self.conv2d(out)
return out
4. Basic network module
# Convolution module
class ConvLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride):
super(ConvLayer, self).__init__()
reflection_padding = kernel_size // 2
self.reflection_pad = nn.ReflectionPad2d(reflection_padding)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
out = self.reflection_pad(x)
out = self.conv2d(out)
return out
# It is obviously a residual module
class ResidualBlock(nn.Module):
"""ResidualBlock introduced in: https://arxiv.org/abs/1512.03385 recommended architecture: http://torch.ch/blog/2016/02/04/resnets.html """
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.conv1 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in1 = nn.InstanceNorm2d(channels, affine=True)
self.conv2 = ConvLayer(channels, channels, kernel_size=3, stride=1)
self.in2 = nn.InstanceNorm2d(channels, affine=True)
self.relu = nn.ReLU()
def forward(self, x):
residual = x
out = self.relu(self.in1(self.conv1(x)))
out = self.in2(self.conv2(out))
out = out + residual
return out
My project link :Style_Transformer
边栏推荐
- Database advanced learning notes - storage structure
- Object stream of i/o operation (serialization and deserialization)
- Embrace open source guidelines
- Article summary of MinGW installation and use
- 15. User web layer services (III)
- Hcip (PAP authentication and chap authentication of PPP)
- 简单选择排序与堆排序
- Understand how to prevent tampering and hijacking of device fingerprints
- tolua之wrap文件的原理与使用
- ES6知识点补充
猜你喜欢

Unity遇坑记之 ab包卸载失败
![[pyGame practice] the super interesting bubble game is coming - may you be childlike and always happy and simple~](/img/3b/c06c140cd107b1158056e41b954e2e.png)
[pyGame practice] the super interesting bubble game is coming - may you be childlike and always happy and simple~

Hcip (condition matching and OSPF packet related knowledge)

The game process and the underlying implementation are gradually completed

How to effectively implement a rapid and reasonable safety evacuation system in hospitals

Consumer installation and configuration

可视化大型时间序列的技巧。

Untiy中控制Animation的播放速度

AlexNet—论文分析及复现
Training mode and practice of digital applied talents in Colleges and Universities under the integration of industry and education
随机推荐
R language uses dplyr package group_ By function and summarize function calculate the mean value of all covariates involved in the analysis based on grouped variables (difference in means of covariate
The reflect mechanism obtains the attribute and method information of class
Lua对table进行深拷贝
Lua 中 __index、__newindex、rawget、rawset的理解
AlexNet—论文分析及复现
Hcip (PAP authentication and chap authentication of PPP)
Will PFP be the future of digital collections?
Globalthis is not defined solution
业务可视化-让你的流程图'Run'起来(4.实际业务场景测试)
Alexnet - paper analysis and reproduction
Unity one key replacement of objects in the scene
从0开发一个自己的npm包
Opencv notes sorting [Hough transform]
Interfaces and abstract classes
Router firmware decryption idea
R language ggplot2 visualization: ggdensity function of ggpubr package visualizes density graph and uses stat_ overlay_ normal_ Density function superimposes positive distribution curve, custom config
Excel shortcut keys (letters + numbers) Encyclopedia
Has samesite cookies ever occurred when using identityserver?
STL の 概念及其应用
一些多参数函数的具体作用