当前位置:网站首页>'virtue and art' in the field of recurrent+transformer video recovery
'virtue and art' in the field of recurrent+transformer video recovery
2022-06-12 16:23:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This article shares papers 『Recurrent Video Restoration Transformer with Guided Deformable Attention』, yes Jingyun Dailaoji SwinIR,VRT Then another masterpiece , stay Transformer The circular architecture is applied in the structure ( The author has been research This point , But the boss is too fierce ) And from frame level alignment to segment alignment .RVRT stay VID4 More than a VRT, stay REDS4 More than a Basicvsr++!
The details are as follows :

Author's unit : Zurich Federal Institute of technology 、Meta、 University of wirtzburg
Thesis link :https://arxiv.org/pdf/2206.02146.pdf
Project links :https://github.com/JingyunLiang/RVRT
01
Watch it
There are two main methods of video restoration :
Recover all frames in parallel , It has the advantage of time information fusion , But the model size is big , Memory consumption is large
Cycle frame by frame , It shares parameters across frames, so the model size is small , But it lacks long-term modeling ability and parallelism
In this paper, we propose a cyclic video restoration transformer(RVRT) To combine these advantages , It processes local adjacent frames in parallel in the framework of global loop, so as to achieve a good trade-off between model size and efficiency , The main contributions are as follows :
RVRT Break the video into multiple clips , The previous segment features are used to estimate the subsequent segment features . By reducing the length of the video sequence and passing information in a larger hidden state , It alleviates the information loss and noise amplification in the cyclic network , You can also partially parallelize the model .
Use guided deformation caution (GDA) Predict multiple related positions from the entire inferred segment , Then we use the attention mechanism to aggregate their features to align the fragments .
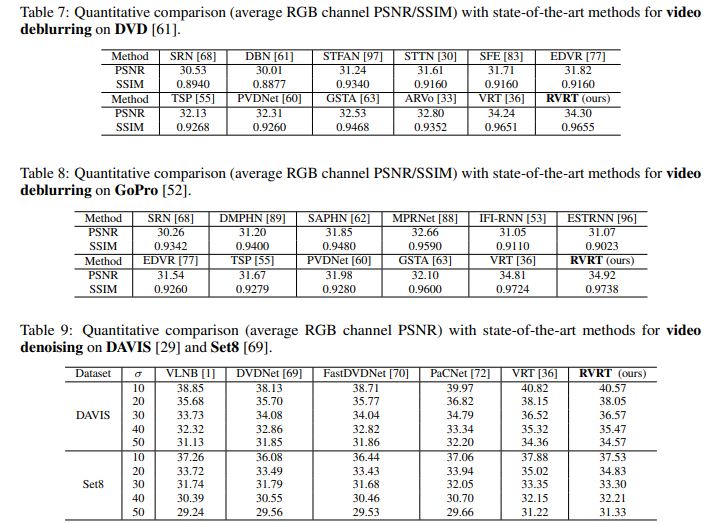
It is realized on the multi benchmark data set of super division de-noising and de blurring SOTA.
02
Method
Overview
The frame is shown in the following figure , The model consists of three parts : Shallow feature extraction , Cyclic feature refinement and frame reconstruction . Shallow feature extraction uses convolution layer and multiple SwinIR Medium RSTB Block to low quality video LQ Feature extraction , Then we use the cycle feature refinement module to model the time , And use the guided deformation to pay attention to the video alignment , Finally, multiple RSTB The block generates the final feature and passes pixelShuffle Conduct HQ The reconstruction .

Loop feature refinement
This article stacks L A cyclic feature refinement module , The video features are refined by using the temporal correlation between different frames . Given layer video characteristics , First, it is divided into segment features , Each fragment feature contains N Adjacent frame features
402 Payment Required
. The aligned segment features are calculated as :Where is optical flow , The current clip feature is calculated as :
Where is the output of shallow feature extraction ,RFR(·) Refine the module for cyclic features , Like the picture on the right , It consists of a convolution layer for feature fusion and several layers for feature refinement RSTB The improved MRSTB form .MRSTB The original two-dimensional h × w Notice that the window is upgraded to 3D N × h × w, This enables each frame in the clip to focus on itself and other frames at the same time to achieve implicit feature aggregation . Besides , Reverse the video sequence to obtain backward information .

Guide the deformation attention
Different from the previous frame level alignment ,GDA Need to align adjacent related but unaligned video clips , As shown in the figure below . The order means that it is made up of t-1 Frames to in clips t The... In the clip n Frame alignment feature of a frame . suffer Basicvsr Inspired by the , First, use optical flow to obtain pre aligned features , And then offset ( A lowercase letter o) Calculated as :
Middle mining CNN It consists of multiple convolution layers and ReLU form , Each frame of optical flow has M It's an offset , The optical flow is then updated to :
402 Payment Required
For the sake of simplicity , This article will K、Q、V The definition is as follows :
402 Payment Required
First, the feature is projected , Then samples are taken to reduce redundant calculations . The alignment feature is then computed by an attention mechanism :
402 Payment Required
Where is the sampling factor . Last , Since the above operations only aggregate information in space , To this end, this article adds a MLP( Two fully connected and one GELU) Interact with channels in the form of residuals . Besides , Channels can be divided into deformable groups , Operate in parallel . The deformable group can be further divided into multiple attention heads , And pay attention to different heads .

It is worth noting that , Deformable convolution uses the learned weights to aggregate features , This can be seen as GDA A special case of , That is, different projection matrices are used for different positions , Then the obtained features are averaged . The number of parameters and computational complexity are and respectively . by comparison ,GDA Use the same projection matrix for all positions , But generate dynamic weights to aggregate them . The number of parameters and computational complexity are and , In choosing the right M and R Time is similar to deformable convolution .
03
experimentAblation Experiment
Ablation study of different video alignment techniques

Different GDA Ablation study of components

Quantitative assessment
stay BD Vid4 Up to 29.54dB, stay BI REDS4 Up to 32.75dB

Parameter quantity , Time is better than VRT, And CNN Architecture is still no better than

Deblurring and denoising
Qualitative assessment
Details are visible to the naked eye


END
Welcome to join 「 Video recovery 」 Exchange group notes : Repair

边栏推荐
- In 2021, China's lottery sales generally maintained a rapid growth, and the monthly sales generally tended to be stable [figure]
- Global and Chinese markets for air sampling calibration pumps 2022-2028: Research Report on technology, participants, trends, market size and share
- 【DSP视频教程】DSP视频教程第8期:DSP库三角函数,C库三角函数和硬件三角函数的性能比较,以及与Matlab的精度比较(2022-06-04)
- 读取mhd、raw图像并切片、归一化、保存
- The C Programming Language(第 2 版) 笔记 / 8 UNIX 系统接口 / 8.6 实例(目录列表)
- 你的下一台电脑何必是电脑,探索不一样的远程操作
- 批量--04---移动构件
- Global and Chinese market for material injection 2022-2028: Research Report on technology, participants, trends, market size and share
- Analysis of China's cargo transport volume, cargo transport turnover and port cargo in 2021 [figure]
- acwing788. 逆序对的数量
猜你喜欢
![Development status of China's pig breeding industry in 2021 and comparative analysis of key enterprises: 671million pigs were sold [figure]](/img/fd/5462c8c6deafeb7d7728716eb4db74.jpg)
Development status of China's pig breeding industry in 2021 and comparative analysis of key enterprises: 671million pigs were sold [figure]

Multimix: small amount of supervision from medical images, interpretable multi task learning
![Analysis of global and Chinese shipbuilding market in 2021: the global shipbuilding new orders reached 119.85 million dwt, with China, Japan and South Korea accounting for 96.58%[figure]](/img/3e/b54b7f15c4a6326d8c7c4433388a3a.jpg)
Analysis of global and Chinese shipbuilding market in 2021: the global shipbuilding new orders reached 119.85 million dwt, with China, Japan and South Korea accounting for 96.58%[figure]

Acwing788. number of reverse order pairs

acwing 800. Target and of array elements

RTOS RT thread bare metal system and multi thread system

Batch --04--- moving components

Analysis on the development status and direction of China's cultural tourism real estate industry in 2021: the average transaction price has increased, and cultural tourism projects continue to innova

批量--03---CmdUtil

Thinking about the probability of drawing cards in the duel link of game king
随机推荐
MySQL面试整理
如何基于CCS_V11新建TMS320F28035的工程
acwing796 子矩阵的和
Global and Chinese market of medical ECG telemetry equipment 2022-2028: Research Report on technology, participants, trends, market size and share
acwing 790. 数的三次方根(浮点数二分)
[tool recommendation] personal local markdown knowledge map software
d结构用作多维数组的索引
Recurrent+Transformer 视频恢复领域的‘德艺双馨’
generate pivot data 1
面试:hashCode()和equals()
leetcode-54. Spiral matrix JS
acwing 高精度乘法
Acwing 797 differential
calibration of sth
[weekly replay] game 80 of leetcode
acwing 803. Interval merging
The C Programming Language(第 2 版) 笔记 / 8 UNIX 系统接口 / 8.4 随机访问(lseek)
Thread pool execution process
(四)GoogleNet複現
【摸鱼神器】UI库秒变LowCode工具——列表篇(一)设计与实现