当前位置:网站首页>004:aws data Lake solution
004:aws data Lake solution
2022-06-12 09:36:00 【YoungerChina】
Data Lake as a current tuyere , Major cloud manufacturers have launched their own data Lake solutions and related products . This section will analyze AWS The data Lake solution launched , And map it to the data Lake reference architecture , Help people understand the advantages and disadvantages of their solutions .
One . Scheme structure
Amazon AWS Count as “ Data Lake ” The originator of technology , As early as 2006 year 3 month , Amazon launched the world's first public cloud service Amazon S3, Its powerful data storage capability , Laid down AWS The foundation of data Lake leadership .

Above, AWS A typical structure of data Lake , We see that data lake is not a product 、 It's not a technology , It's made up of multiple big data components 、 A solution made up of cloud services .
Of course , The core component is Amazon S3, It can store any binary based information , Contains structured and unstructured data , for example : Enterprise information system ERP、CRM And so on , From cell phones 、 Photos from the camera 、 Audio and video files , From the car 、 Data files from wind turbines and other equipment .
Data source connection ,AWS A name is provided AWS Glue product ,Glue It means glue , Support the connection between different database services .Glue There are two main functions , One is ETL, namely , Data extraction 、 Transform and load . Another function , yes Data directory service The function of , Because these data are stored in the data lake , In the process , Label the data , Classify it .Glue It's like a reptile to the massive data in the data lake , Carry out automatic crawling , The function of generating data directory .
Big data processing ,AWS The data lake can be divided into three stages to process the data .
- The first stage is batch processing : By loading various types of raw data into Amazon S3 On , And then through AWS Glue Data processing for the data in the data lake , You can also use Amazon EMR Carry out advanced data processing and Analysis .
- The second stage is flow processing and analysis , This task is based on Amazon EMR、Amazon Kinesis To complete .
- The third level is machine learning , Data is passed through Amazon Machine Learning、Amazon Lex、Amazon Rekognition Carry out deep processing , Form available data services .
Data services :AWS The data lake can provide different data services for users with different roles , Data scientists can explore and mine data based on data lake , Data analysts can model data based on data 、 Data analysis, etc ; Business personnel can query 、 Browse the analysis results of the data analyst , It also performs self-service data analysis based on the data directory . Based on the data lake, various kinds of SaaS application , At the same time, the data Lake provides data openness , Support the data to API The interface is open to external applications .
Safety and operation and maintenance : because AWS The data Lake runs in the cloud , Data security is the focus of attention . Amazon's Amazon VPC It provides management and monitoring functions for cloud data lake , VPC Support specifying IP Address range 、 Add subnet 、 Associate security groups and configure routing tables ,AWS IAM、AWS KMS Escort the safety of the data lake , Provide support for building a secure cloud data lake .
Two . How to build a data lake
The data lake is also a big data platform from the technical level , Traditionally, a set of data storage is built 、 Data processing 、 machine learning 、 A big data platform integrating data analysis and other applications requires a dozen or even dozens of big data components , You also need to build clusters for related components , To meet mass data processing 、 The need for computing and storage . This process is often very complicated , It may take months to complete .
2018 year ,AWS Launched LakeFormation, Excerpt from AWS Website :
AWS Lake Formation It's a service , It's easy to build a secure data Lake in a few days . Data Lake Is a secure, centralized, policy managed Repository , It stores all data in its original form and in a form that can be used for analysis . Using data Lake , You can decompose data islands and combine different types of analysis , To gain insight and guide better business decisions .
Set up and manage the data lake Involves a large number of complex manual tasks that are extremely time-consuming . This work involves loading data from different sources 、 Monitor these data flows 、 Set up zones 、 Turn on encryption and management key 、 Define transformation tasks and monitor their operations 、 Reorganize data into column formats 、 Delete redundant data, duplicate data and matching link records . After the data is loaded into the data Lake , You need to authorize fine-grained access to the dataset , And for all kinds of analysis and machine learning (ML) Long term access to tools and services .
Use Lake Formation Creating a data lake is simple , Just define the data source , Just make the access and security policies you want to apply . then ,Lake Formation Will help you collect and categorize data from databases and object stores by directory , Move data to new Amazon Simple Storage Service (S3) Data Lake , Use machine learning (ML) Algorithm cleaning and classifying data , Merge columns 、 Fine control of rows and cells for secure access to sensitive data . Your users can access the centralized data directories that describe the available data sets and their appropriate usage . then , The user can combine the selected analysis and machine learning (ML) Services work with these datasets , for example Amazon Redshift、Amazon Athena、Amazon EMR for Apache Spark and Amazon QuickSight.Lake Formation Based on the AWS Glue On top of the functions available in .
Then based on AWS Data service component , How to build a “ Data Lake ”?AWS The official website gives “ Data Lake ” Five steps from creation to application , As shown in the figure below :
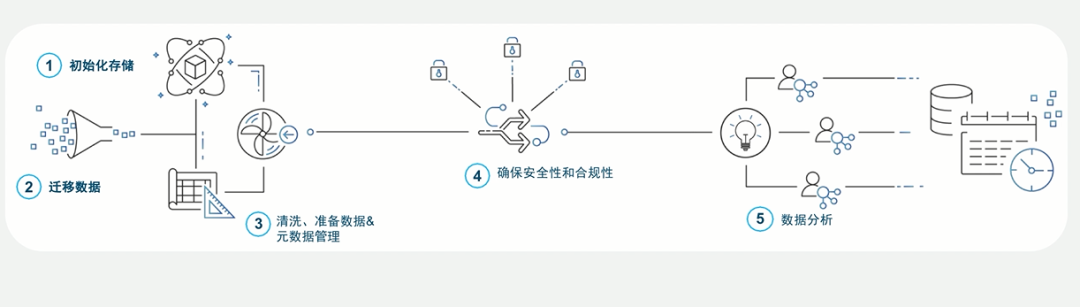
The author sums up these five steps as “ Jianhu 、 Aggregate number 、 Governing number 、 Usage ” Eight words : To build a lake is to initialize the storage , Aggregating data means migrating data , Data cleaning means data cleaning 、 Data preparation 、 Metadata management 、 Data security and compliance management , Using numbers is data analysis 、 Data services .
2.1 Jianhu -- Stroll around the court and build several lakes
First , be based on AWS Identity、IAM The service creates a data lake to run the required administrator of the workflow and the role required by the permission policy , namely : Create administrators and specify user groups for the data Lake .
then , Register data Lake , Specify the data Lake storage center Amazon S3 The path of , And set up “ Data Lake ” jurisdiction , To allow others to manage “ Data directory ” And the data in the data lake .
Last , Set up Amazon Athena So that the query can be imported into Amazon S3 Data in the data Lake .
thus , A simple data lake is built . Of course, we need to set up different services in different application scenarios , For those who want to store in the data lake and Redshift Users who perform cross fusion analysis on data in the data warehouse , Can be set by Amazon Redshift Spectrum, bring Redshift Can query stored in Amazon S3 Data in , So as to realize the data fusion analysis of data warehouse and data lake .
2.2 Aggregate number -- A hundred rivers will eventually return to the sea
With the coming of big data Era , A significant surge in the volume of enterprise data , All kinds of data are pouring in . There is data from the enterprise's internal information system , for example :ERP System 、CRM Systems, etc , After years of precipitation , A large amount of historical data accumulated by enterprises , It is the main source of enterprise data analysis . It comes from all kinds of IoT Real time data generated by the device , And these data are often generated in mixed data formats , Including structured data 、 Semi-structured and unstructured data . There is Internet data from enterprises , Including data generated by Internet business , And the data of other websites collected by web crawlers ……, These new large-scale massive amounts of data , Not only a large amount 、 A wide variety , And it came very hard , like “ great scourges ”.
AWS To realize data collection of different data types 、 Processing provides a variety of tools , for example :AWS Glue、Database Migration、Kinesis、Internet of Things etc. , Support easy migration of various types of data to Amazon S3 Unified management in . This process , Just like “ Data Lake ” Literally , We will look for a large wetland (S3), And then these come like floods “ from all sides ” The data is stored in the lake first , Form data “ all rivers flow to the sea ” Trend , Then we are using some tools to manage it 、 Query and analysis .
2.3 Governing number -- Dredge the river and lead the stagnant flow on demand
The data lake has excellent data storage capacity , Support a large number of 、 Various types of big data are stored uniformly . However , The business of an enterprise is changing in real time , This represents the definition of the data deposited in the data lake 、 Data formats are changing in real time , If not managed , Enterprise “ Data Lake ” It could become “ The garbage ” Stacked “ Data swamp ”, It can not support the data analysis and use of the enterprise .
“ A rolling stone gathers no moss , on ”, We can only let “ Data Lake ” Medium “ water ” Flow up , To make “ Data Lake ” Don't become “ Data swamp ”.AWS Glue Provide ETL And data catalog capability , When the data is migrated from the data source, certain data conversion can be done , And form a clear data directory .Amazon EMR、Amazon Glue The data in the data lake can be divided into regions 、 Clean and treat in stages , Further purify the lake “ Source of water ”. after , Data is passed through Amazon Machine Learning、Amazon Lex、Amazon Rekognition Carry out deep processing , Form available data services , This goes on and on , Continue to improve... In the data lake “ The water quality ”.
meanwhile ,Amazon S3、DynamoDB、Redshift Good data security mechanism , Data transmission and storage are encrypted , The encryption key is only owned by the customer , Prevent the risk of data leakage . in addition , also Amazon VPC The security policy 、AWS IAM、AWS KMS The safety components are AWS Data Lake escort , For the storage of enterprise data 、 Handle 、 Use to provide a secure 、 Compliant data environment .
All in all , Through the design of the data Lake 、 Add powerful data processing to the loading and maintenance process 、 Metadata management 、 Components related to data quality check and data security , With the active participation of experienced professionals in all these fields , Can significantly increase the value of the data Lake . otherwise , Your data lake may become a data swamp .
2.4 Usage -- As it happens, the value increases
The emergence of data Lake , At first, it is to supplement the defects and deficiencies of data warehouse , To solve the long development cycle of data warehouse , High development costs , Detail data is lost 、 Information islands cannot be completely solved 、 When problems occur, the source cannot be traced . But with the development of big data technology , The data lake is evolving , A collection of technologies , Including data warehouse 、 Real time and high speed data stream technology 、 machine learning 、 Distributed storage and other technologies . The data lake has gradually developed into a system that can store all structured data 、 Unstructured data , Big data processing of data 、 A unified data management platform for real-time analysis and machine learning , Provide data for enterprises “ collection 、 Storage 、 government 、 analysis 、 mining 、 service ” The complete solution , So as to achieve “ When water flows, a channel is formed ” Data value insight .
AWS Provides the widest range of 、 The most cost-effective collection of analytical services , Each analysis service is built specifically for a wide range of analysis use cases :
utilize AmazonAthena, Use standards SQL Direct queries are stored in S3 Data in , Realize interactive analysis ;
utilize AmazonEMR Meet the requirements for using Spark and Hadoop Big data processing of the framework ,Amazon EMR Provides a managed service , It's easy 、 Process massive amounts of data quickly and cost effectively ;
utilize AmazonRedshift Can be built quickly PB Level structured data runs 、 Data warehouse with complex analysis and query function ;
utilize AmazonKinesis, Easy collection 、 Process and analyze real-time streaming data , Such as IoT Telemetry data 、 Application logs and website click streams ;
utilize AmazonQuickSight Easily build sophisticated visualizations and content rich control panels that can be accessed from any browser or mobile device ;
meanwhile ,AWS Provides a wide range of machine learning services and tools , Support in AWS Running machine learning algorithm on data Lake , Deep mining data value .
These tools and services , It can be used by users with different roles , For example, data scientists 、 Data Analyst 、 Business people 、 Data administrators provide powerful functional support , So as to help enterprises achieve “ Data driven ” Digital transformation of .
Four 、 summary
Traditional information systems are process driven , All businesses of the enterprise are carried out around the process , The data at this stage did not attract people's attention . To the data warehouse stage , The application of data by enterprises is only at the auxiliary level , Enterprise management decision 、 Business innovation mainly depends on people's experience , The data is just a reference . But with the advent of the digital age , Big data technology continues to be deeply applied , People have the ability to discover big data problems 、 The ability to predict is far greater than people's experience . More and more enterprises choose to make business decisions based on data , Improve organizational performance based on data , Product innovation based on data . Enterprises are moving from “ Process driven ” The information age , trend “ Data driven ” The digital age of .
“ Data Lake ” It is a product of the times , Its value lies not only in the fact that it can convert a large number of 、 Different types of data are stored uniformly , And provide data catalog and query services . The digital age , More data 、 More real time 、 More for the future , machine learning 、 Artificial intelligence has become a key factor in the digital transformation of an enterprise . The data Lake supports a large number of 、 Real time data processing and analysis , Even this data processing and analysis does not require a predefined data model , Enhanced data insight , It makes these massive data more valuable than before , Help people find more rules in local data , so to speak “ Data Lake ” It's for “ machine learning ” born .
Make effective use of “ Data Lake ”, Fully tap the potential value of data , Can help enterprises better segment the market , To help enterprises to provide decision support for enterprise development , Better grasp the market trend , Better response to the market to generate new insights , Better design planning or product improvement , Better service for customers , So as to enhance the competitiveness of enterprises , Even innovate the business model of the enterprise .
边栏推荐
- Semaphore flow control semaphore
- What are the software testing requirements analysis methods? Let's have a look
- [cloud native] what exactly does it mean? This article shares the answer with you
- ADB命令集锦,一起来学吧
- Do you know how to improve software testing ability?
- 《第五项修炼》读书笔记
- Golandidea 2020.01 cracked version
- Countdownlatch example
- Is it necessary to separate databases and tables for MySQL single table data of 5million?
- L1-019 who goes first
猜你喜欢
Common omissions in software test reports, give yourself a wake-up call

Microservice gateway

Combat tactics based on CEPH object storage

TAP 系列文章3 | Tanzu Application Platform 部署参考架构介绍
Selenium面试题分享
软件测试面试题精选

Is it necessary to separate databases and tables for MySQL single table data of 5million?

Auto.js调试:使用雷电模拟器的网络模式进行调试

I Regular expression to finite state automata: regular expression to NFA

Do you know the meaning behind these questions?



随机推荐
The onbindviewholder of recyclerview is called twice at the same time
榜样访谈——董宇航:在俱乐部中收获爱情
MySQL优化之慢日志查询
Implementation of hotspot synchronized
What are the design principles of an automated test framework? I'll sum it up for you. Come and see
ADB command collection, let's learn together
Thread deadlock and its solution
7-13 地下迷宫探索(邻接表)
List、Set、Map的区别
软件定义存储概览(一篇就够)
MySQL index
JVM virtual machine
APP测试面试题汇总,面试必考一定要看
链式哈希表
Dazzle the "library" action - award solicitation from the golden warehouse of the National People's Congress - high availability failover and recovery of kingbasees cluster
Mycat的使用
存储研发工程师招聘
数据库常见面试题都给你准备好了
Auto.js学习笔记5:autojs的UI界面基础篇1
++ problems in C language